New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Toward a Functional Programming Analogy for Microservices
Microservices are all the rage these days. Passionate, thoughtful advocates and detractors present compelling arguments for and against the architectural style. Usually, these arguments boil down to whether organizations should adopt, refrain from, or abandon microservices architecture based on an assessment of the costs and benefits of the style for the size and technical culture maturity of those organizations.
However, such an adopt-or-abandon premise overlooks an important dimension of the microservices conversation: what style of microservices would map most closely to the needs of the organization? Perhaps considered in this light, the costs that would deter certain organizations might be mitigated and the benefits retained by a better style of microservices.
(at least) Two styles of microservices
Perhaps the most common shared understanding of microservices is represented by the Death Star diagram, which describes a network of services and their synchronous, run-time dependencies on other services. Much of the microservices mindshare—writing, diagramming and designing, libraries and tooling—assumes this model of small services calling each other synchronously, usually via HTTP. And it is usually this model that is the subject of the adopt-or-abandon assessments described above. This conflating of the underlying values and goals of microservices with a specific model for their implementation is unfortunate.
 AWS Death Star diagram, circa 2008 as per Werner Vogels tweet
AWS Death Star diagram, circa 2008 as per Werner Vogels tweet
This view of microservices shares much in common with object-oriented programming: encapsulated data access and mutable state change are both achieved via synchronous calls, the web of such calls among services forming a graph of dependencies. Programmers can and should enjoy a lively debate about OO’s merits and drawbacks for organizing code within a single memory and process space. However, when the object-oriented analogy is extended to distributed systems, many problems arise: latency which grows with the depth of the dependency graph, temporal liveness coupling, cascading failures, complex and inconsistent read-time orchestration, data storage proliferation and fragmentation, and extreme difficulty in reasoning about the state of the system at any point in time.
Luckily, another programming style analogy better fits the distributed case: functional programming. Functional programming describes behavior not in terms of in-place mutation of objects, but in terms of the immutable input and output values of pure functions. Such functions may be organized to create a dataflow graph such that when the computation pipeline receives a new input value, all downstream intermediate and final values are reactively computed. The introduction of such input values into this reactive dataflow pipeline forms a logical clock that we can use to reason consistently about the state of the system as of a particular input event, especially if the sequence of input, intermediate, and output values is stored on a durable, immutable log.
(Of course, the application of these single-memory-space programming styles as analogies to distributed architectures is not a rigorous attempt to extend their underlying formal models, but is rather an informal extension of their basic intuition and principles.)
Functional (and reactive) programming as an analogy for microservices
What would a microservices architecture following this functional programming analogy look like? One possibility is the Commander Pattern, of which Capital One has provided an open-source reference implementation:
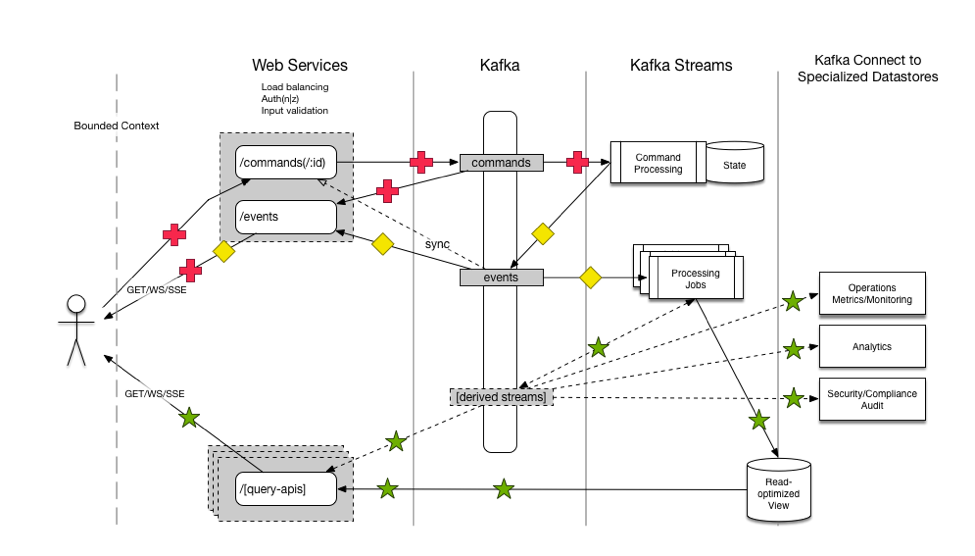
In this model, an action (in the form of a command from outside or event from inside the bounded context) is written down in its raw, denormalized, business-domain form to an immutable log. Various topologies of functions (dataflows) react to process this new event, eventually incorporating its various data-domain consequences into aggregations representing current state. Clients of the service (and the various processors themselves) perceive/query the current system state via these aggregations.
Though, as observed above, much of the microservices mind-share is devoted to the OO-analogy synchronous style, there are some battle-hardened tools and techniques for implementing the FP-analogy style.
CQRS and Event Sourcing
In the model above, action (state-changing writes) flows through a separate system path from perception (non-state-changing reads), which is an example of Command Query Responsibility Segregation (CQRS).
System state is derived from the log of these actions, which is an example of Event Sourcing.
These two architectural techniques from Domain Driven Design (DDD) often go hand-in-hand, and happen to fit well within this functional programming view of microservices.
Single (logical) writer
In this FP architecture, many services perceive and react to new values on the log, because log consumption is ubiquitous and cheap. However, writing to the log must be handled much more carefully, as Ben Stopford observed in the section “The Single Writer Principle” of Build Services on a Backbone of Events. Other log-centric, CQRS systems that I’ve worked on, such as the database Datomic also follow this principle.
Three categories of microservices
Within this architecture, just as functions within a functional program, different microservices in the topology will serve different purposes. Most of the processing nodes in the topology will act as “pure” functional transforms, i.e. accepting new inputs from some set of input logs, doing some math according to the business rules (possibly involving a local aggregation for stateful computations like joins, windowed aggregates, etc.), and emitting new values onto some set of output logs. These form the “Functional Core” of the system.
The other two types of microservices act as the “Imperative Shell” of the system, executing certain side-effects. The first category of these are shared aggregations within the bounded context. These services build useful “materialized views” of the current state of the system, such as full-text indexes, entity-oriented REST services, attributed oriented BI/analysis services, analytics dashboard views, etc.
The second type of these “Imperative Shell” services execute side-effects outside of the bounded context, such as sending an email, SMS, or mobile push notification to a user, or calling out to some other external service. These side-effects must be managed carefully, accounting for target service downtime, retries, idempotency, and the storage of the results of such calls as applicable. The record of external actions and the corresponding results may be used to implement Sagas or distributed rollback/reversal.
Kafka, Kafka Streams, and Kafka Connect
Kafka has exactly the characteristics needed to form the backbone of such a FP-analogy microservices architecture. It both durably stores and reactively conveys immutable values, making it the ideal place to record input, intermediate, and output values for functional dataflow pipelines.
Kafka’s Streams API provides powerful primitives for implementing precisely such distributed computational pipelines. Kafka Streams provides a high-level API for building topologies of transforms (e.g. map and filter), local and shared aggregations (e.g. Global Tables and Stores API, and side-effect processors like foreach, peek, and even map for storing results). Via the aggregations described above, Kafka Streams also seamlessly unifies stream processing with interactive queries, potentially making each processing microservice also a read-only view of its current state via e.g. REST or RPC.
Kafka’s Connect framework also provides a simple and powerful way of building shared aggregations in external systems like RDBMSes, full-text indexes, document-oriented stores, key-value stores, graph databases, column-oriented or star-schema analytics databases, or whatever most closely matches the desired data-access patterns of your services.
A real-world example
Let’s explore the ideas above using a real-life (though somewhat simplified) example from a banking use-case at Capital One, created by our colleague Qiang Xue (much of this section is adapted from his summary, with his permission and our thanks).
Our customer wants to be able to set spending limits on particular debit or credit card numbers for their account (e.g. in order to rein in Junior’s spending at college). In order to authorize a financial transaction on that card number (e.g. a debit or credit card swipe), the authorizing process must maintain a running balance of the spending on that card number.
Note: The code examples below target version 0.11 of Kafka’s Streams API. Since this article was first written, the Streams API changed slightly in the latest 1.0 release.
For illustrative purposes, let’s assume that the transactions are accessible through a Kafka topic. We can write our main stream processing code in Java:
In fact, the actual implementation of this example is much more complicated:
- Both settled transactions (from one data source) and pending authorizations (from another source) must be taken into account…
- …over a hopping time window during which the authorizations are valid
- Authorizations matching a settled transaction must not be double counted
- etc.
But even when adding in these complications, the service boundaries, topics, and code stay relatively straightforward (the full code listing was even included in a draft of this post!).
Both the transform and aggregation service types are obvious in the example above, but we can also easily imagine a side-effect service which observed calculated spending balances, and notifies customers via mobile push or SMS when the preset spending limit is reached. In line with the microservices value of coordination avoidance, such a notification service could be added later without any knowledge or involvement from the team that implemented the business logic.
The functional style of microservices enabled by Kafka and its Streams API have helped this service to meet its goals in production:
- Tame complexity. Kafka Streams enabled very sophisticated stream processing and aggregation in clear, concise, small code. Kafka Streams also provides a much easier development experience compared with either using the Kafka Consumer/Producer APIs directly or with calling out to OO-style microservices to fetch needed data. The associated failure modes are also much simpler when using Kafka Streams in FP-style microservices.
- Real-time aggregated result. Kafka Streams provides sub-second streaming aggregation performance. Also, the aggregations are pre-computed as new events arrive, and cached wherever they’re needed so that reads of the balances (either for processing decisions or to show to end-users) are very fast.
- Easy deployment compared with other streaming data processing environments like Hadoop/Spark/Storm/Samza and friends. No cluster needed, just running Java application as usual.
Several other applications from various product lines are being migrated to this functional streaming style.
Comparing FP-analogy and OO-analogy microservices
Finally, let’s compare and contrast the FP-style of microservices described above with the ubiquitous OO-style along several important dimensions: data access patterns, orchestration patterns, handling failure, write-time and read-time latency, reasoning about state over time, and dealing with side-effects.
Data Access patterns
In the OO-style of microservices, the service boundaries are usually drawn such that each service encapsulates a relatively small data domain (sometimes just a single type of entity). This fragmentation has some negative consequences:
- The service dictates the data access patterns by which it will make its data available, and accessing via different patterns requires coordination (e.g. ETL from database, team implements new query interface for service…6 months from now)
- Storage of the primary business data is fragmented across many different data stores, making joins and other aggregates cumbersome and possibly inconsistent (sort of like lack of referential transparency in single process space)
- The interfaces for accessing the data proliferate with the number of services, burdening aggregating clients just like OO programming proliferates classes/interfaces, each having only a few operations/methods
On the other hand, the FP-style we’ve presented:
- Offers uniform, ubiquitous data access via a shared log, Kafka, much like the functional programming concept of having few data structures each participating in many operations/functions.
- This uniform, ubiquitous data access to a log containing all the facts allows all consumers to build their own local view of state in the data access pattern that best suits each consumer.
- The primary business data is stored in Kafka, and all local views of state are derived aggregations (and could be thrown away and rebuilt from the source if needed).
Orchestration patterns
The OO-style of microservices which encapsulate data require lots of read-time orchestration in order to put together aggregate queries across services.
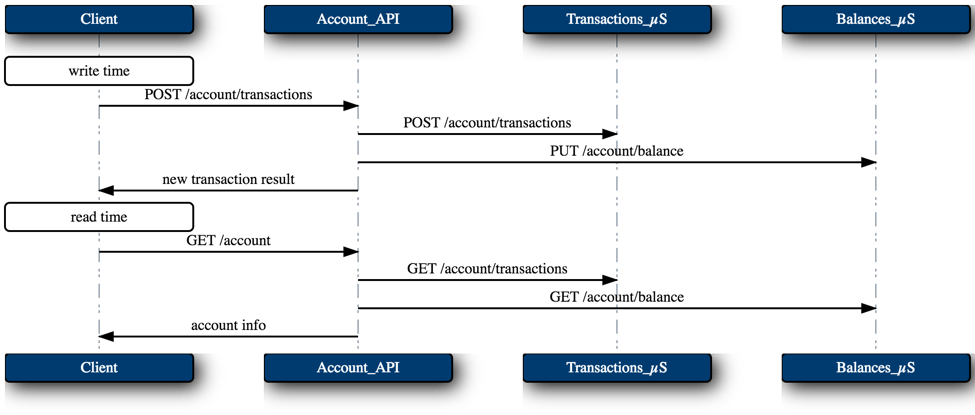 Client asks the Accounts_API a question, so Accounts_API turns around and asks the Transactions_µS and the Balances_µS.
Client asks the Accounts_API a question, so Accounts_API turns around and asks the Transactions_µS and the Balances_µS.
The reactive FP-style does all of this orchestration at write-time. As new facts are recorded in Kafka, the various topologies eagerly do their respective processing.
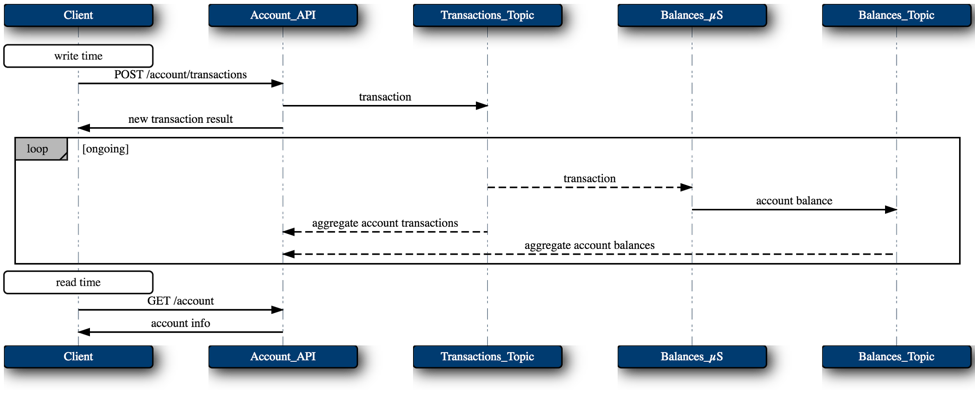
Handling failure
The orchestration pattern described above has another shortcoming: availability in the face of failure. The synchronously communicating services are temporally coupled to each others’ runtime liveness, i.e. the Balances_µS has to be alive at the time the Accounts_API calls it in order for the Accounts_API to be fully available. The problem compounds exponentially as the call graph deepens. Techniques like circuit-breakers, etc. may be employed to paper-over this dependency, but the underlying problem remains.
This shortcoming is even worse at write-time, since the write-orchestrating service’s sequence of actions is likely not atomic, i.e. Accounts_API might die or encounter an unavailable target service mid-way through a complex orchestration of writes to its various dependencies, leaving the system in an inconsistent state or subject to complex and error-prone roll-back logic.
In the FP-style, and especially since transactional writes were introduced in Kafka 0.11, writes are simple, atomic (either all fail or all succeed), and carefully managed (single writer principle described above). Writes to Kafka may be tuned for a desired consistency level, and do depend on Kafka’s availability, which is likely to be much better than the availability of any given microservice.
Reads are not coupled to the availability of upstream writers, or even to that of Kafka, since reads are served from a locally managed, read-optimized, materialized view. Reads from any given service can proceed for an indefinite amount of time, and will always be consistent as of some point in time, with clients understanding that that point in time might lag behind the latest upstream event (and clients can decide if that’s good enough). If this AP tradeoff is unacceptable for a service’s use-case, that service can choose to return errors or become unavailable when it falls behind. Aggregation microservices control their own availability and consistency trade-offs.
Latency
In the sequence diagrams above, the OO-style is obviously much more latent at read time than the FP example, since it has to call through a two-layer deep graph of latency: Client->Accounts_API + max(Accounts_API->Transactions_µS, Accounts_API->Balances_µS). Why wait until a client asks a question before computing the answer? Why incur so many hops of HTTP latency?
In the FP-style, writes are very fast (since it’s just writing down a command/event to Kafka), then there is some intervening processing latency while this new fact is incorporated into the system, and then reads are very fast because they’re served out of a purpose-built, read-only materialized view.
State over time
The OO-style orchestration model described above also introduces great difficulty in maintaining consistency and in reasoning about the state of the system over time.
At write-time, commands are constantly coming into the various services and are being recorded locally without any whole-system sequencing of these commands. This makes validating consistency a burdensome and error-prone task during write-time orchestration (e.g. two-phase commit between separate services, proper sequencing and error recovery, unknown atomicity in face of mid-process service failure, etc.)
At read time, a new transaction may arrive between the call Accounts_API->Transactions_µS and Accounts_API->Balances_µS such that the transaction is present in the Transactions_µS response, but the impact on balance hasn’t landed in the Balances_µS. The response from Accounts_API would then be inconsistent.
In the FP-style, however, there is an explicit notion of logical time in the ordering of the events in the log, which creates both a clear provenance of derived facts tracing back to source facts, and the ability to reason about the state of the system as of any particular source event. As of version 0.11, Kafka and its Streams API support exactly-once processing semantics, ensuring that the processing pipelines work properly under failure.
Reads in this FP-style will always be consistent as of some valid point in logical time, but any given view might not yet have incorporated every available event.
Side-effects
In the OO-style, each call from one service to another is possibly a side-effect, depending on the safety semantics of the particular call. Service orchestration is the process of sequencing these side-effects with local business rule processing to produce the desired end state. This pervasive intermingling of local processing with side-effecting calls to other services makes it very difficult to roll back and prevent duplicate calls during failures.
In the FP-style, as discussed above in “Three categories of microservices”, the pure functional transforms and local aggregations that comprise the “functional core” of the system have no side-effects (i.e. other than writing to local storage and writing to Kafka which are carefully managed by Kafka Streams to have the proper “functional” semantics). Side-effects to targets outside the bounded context (like the notification service invocation cited above) are executed carefully by purpose-built services in the “imperative shell” of the system when triggered by an upstream immutable value added to the log.
Conclusion
Before either rejecting microservices architecture as too complicated, or implementing it blindly according to the grooves cut by early adopters and popular stacks of tooling, consider what type of system will meet your needs, and whether the reactive, immutable, functional style of microservices enabled by Kafka and Kafka Streams might be a better fit.
Learn more about best practices and technical patterns of Capital One’s deployment of Apache Kafka in Capital One Delivers Risk Insights in Real Time with Stream Processing, an online talk featuring Ravi Dubey, Senior Manager, Software Engineering, and Jeff Sharpe, Senior Software Engineer.
Posts in this Series:
- Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
- Part 2: Build Services on a Backbone of Events
- Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
- Part 4: Chain Services with Exactly Once Guarantees
- Part 5: Messaging as the Single Source of Truth
- Part 6: Leveraging the Power of a Database Unbundled
- Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
More on Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





