New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Unifying Stream Processing and Interactive Queries in Apache Kafka
This post was co-written with Damian Guy, Engineer at Confluent, Michael Noll, Product Manager at Confluent and Neha Narkhede, CTO and Co-Founder at Confluent.
We are excited to announce Interactive Queries, a new feature for stream processing with Apache Kafka®. Interactive Queries allows you to get more than just processing from streaming. It allows you to treat the stream processing layer as a lightweight, embedded database and directly query the state of your stream processing application, without needing to materialize that state to external databases or storage. Apache Kafka maintains and manages that state and guarantees high availability and fault tolerance. As such, this new feature enables the hyper-convergence of processing and storage into one easy-to-use application that uses the Apache Kafka’s Streams API.
The idea behind Interactive Queries is not new; a similar concept actually originated in traditional databases where it’s often known as “materialized views.” Though materialized views are very useful, the way they are implemented in databases is not suitable for modern application development – they force you to write your code all in SQL and deploy it into the database server. With our database background combined with our stream processing experience, we visited a key question: can the concept behind materialized views be applied to a modern stream processing engine to create a powerful and general purpose construct for building stateful applications and microservices? In this blog post, we show how Apache Kafka, through Interactive Queries, helps us do exactly that.
When we set out to design the stream processing API for Apache Kafka – the Kafka Streams API – a key motivation was to rethink the existing solution space for stream processing. Here, our vision has been to move stream processing out of the big data niche and make it available as a mainstream application development model. For us, the key to executing that vision is to radically simplify how users can process data at any scale – small, medium, large – and in fact, one of our mantras is “Build Applications, Not Clusters!” In the past, we wrote about three ways Apache Kafka simplifies the stream processing architecture – by eliminating the need for a separate cluster, having good abstractions for streams and tables and keeping the overall architecture simple. Interactive Queries is another feature to enable this vision.
In this blog post, we’ll start by digging deeper into the motivation behind Interactive Queries through a concrete example that outlines its applicability. Then we will describe how Interactive Queries works under the hood and provide a summary of related resources for further reading.
Example: Real-time risk management
Let’s use an end-to-end example to pick up where we left off in our previous article on why stream processing applications need state. In that article, we described some simple stateful operations, e.g., if you are grouping data by some field and counting, then the state you maintain would be the counts that have accumulated so far. Or if you are joining two streams, the state would be the rows in each stream waiting to find a match in the other stream.
Now as a driving example in this blog, consider a financial institution, like a wealth management firm or a hedge fund, that maintains positions in assets held by the firm and/or its client investors. Maintaining positions means that the bank needs to keep track of the risk associated with those particular assets. The bank continuously collects business events and other data that could potentially influence the risk associated with a given position. This data includes market data fluctuations on the price of the asset, foreign exchange rates, research, or even news information that could influence the reputation of people involved with the asset. Any time this data changes, the risk position needs to be recalculated in order to keep a real-time view of the risk associated with each individual asset as well as on entire portfolios of investments.
Real-time risk management is an example of a stateful application. At a minimum, state is needed to keep track of the latest position for every asset. State is also needed inside the stream processing engine to keep track of various aggregate statistics, like the number of times an asset is traded in a day and the average bid/ask spread. The collected state needs to be continuously updated and queried.
So how is this done today?
Before the Kafka Streams processing engine was introduced in Apache Kafka 0.10 in May 2016, a typical architecture to power a real-time risk management dashboard would have looked something like this:
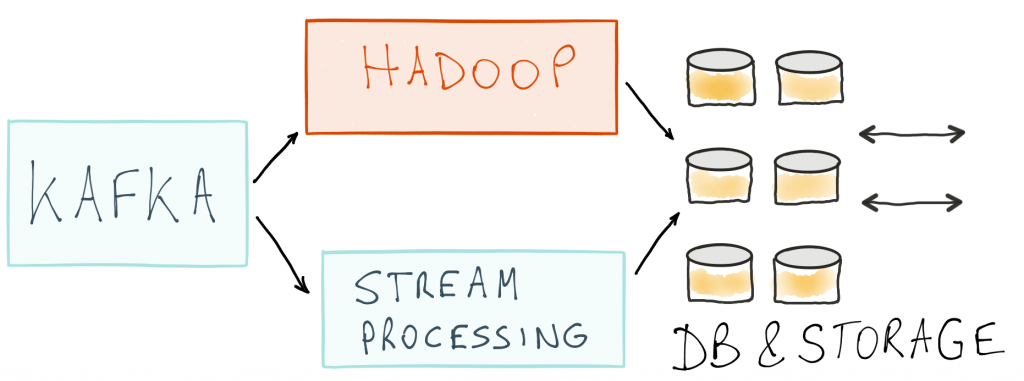
Here, business events would be captured as real-time data streams in Kafka. Let’s focus on the upper part first. Here we have a separate Hadoop processing cluster (e.g., Apache Spark) that would need to be put in place to process these data streams. At this point, there is no stream processing yet. The Hadoop cluster would batch process the data a few times a day and then publish the output positions to some external data store like HDFS or HBase. A request/response layer would then service queries on the positions.
If you want stream processing and continuous position updates, you would then add a stream processing layer as shown in the lower part of the diagram. You would still typically keep the Hadoop cluster to periodically check and validate the results from the streaming layer or to do data reprocessing if the logic of your computation changes. This hybrid architecture is known as the Lambda architecture. We have already written about the inefficiencies that stem from having two separate clusters that need to be deployed, monitored and debugged. So in summary, there are lots of moving parts and inefficiencies in how things are done today, including:
- An extra Hadoop cluster to reprocess data.
- Storage maintained at the stream processing layer. This is needed for lookups and aggregations (e.g., for keeping track of the number of times an asset is bought or sold).
- Storage and databases maintained for outputs from the streaming and Hadoop jobs.
- Write amplification is inevitable. A record is written internally in the stream processing layer to maintain computational state. This state is also duplicated externally so that it can be queried by other apps.
- Locality is destroyed, because data that needs to be local to processing is unnecessarily shipped to a remote storage cluster.
So we started by wanting to write an app that displayed the positions on various assets. What we ended up with is not a single app, but many different systems and clusters that we need to stitch together to implement a stateful service.
The case for Interactive Queries
As an intermediate step, let’s simplify the above deployment by removing the Hadoop layer and having all processing done in the streaming layer. So we move from the Lambda architecture to the so-called Kappa architecture. The question is, can we do even better? It turns out that we can. With Interactive Queries and Apache Kafka we can also eliminate or reduce the need for an external database. Here is how the app would then look like:
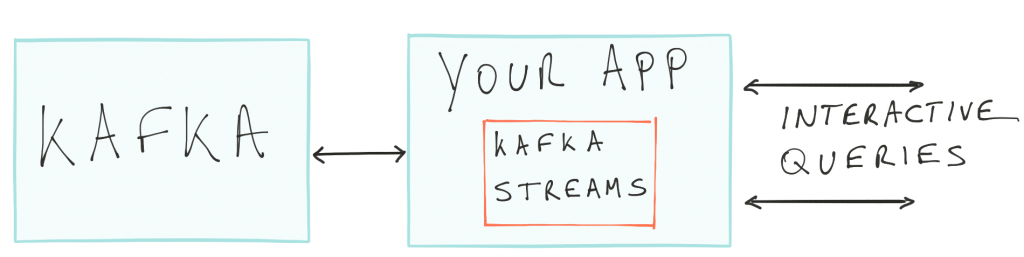
All the state in your app is now queryable through the Interactive Query API.
How are we able to do this? Well, we have designed the Kafka Streams library to maintain internal state through embedded databases (RocksDB by default, but you can plug in your own). These embedded databases act as materialized views of logs that are stored in Apache Kafka, with its excellent guarantees on high-availability, fault tolerance and performance. With Interactive Queries we are directly exposing this embedded state to applications.
So what is the link exactly between Interactive Queries of embedded state and traditional databases? The link is the notion of materialized views. In traditional databases they are copies of the original data, normalized to match specific query patterns. We have made the case in the past that, for streams, materialized views can be thought as a cached subset of a log (i.e., topics in Kafka). Embedded databases and Interactive Queries are our implementations of this concept in Apache Kafka.
Materialized views provide better application isolation because they are part of an application’s state. A rogue application can only overwhelm its own materialized view during queries. Materialized views also provide better performance. An application can directly query its state without needing to go to Kafka.
Right database for the app
Mind you, there are of course use cases where you still need full-fledged external storage or databases you know and trust such as HDFS, MySQL, or Cassandra. The Kafka Streams API uses embedded databases to perform its processing, however querying them is optional, in that you can always copy their data to an external database first. Here are some tradeoffs to consider when selecting which database and storage to use:
Pros of using Interactive Queries with embedded databases:
- There are fewer moving pieces; just your application and the Kafka cluster. You don’t have to deploy, maintain and operate an external database.
- It enables faster and more efficient use of the application state. Data is local to your application (in memory or possibly on SSDs); you can access it very quickly.
- It provides better isolation; the state is within the application. One rogue application cannot overwhelm a central data store shared by other stateful applications.
- It allows for flexibility; the internal application state can be optimized for the query pattern required by the application.
- You can plug in any embedded database of choice (RocksDB comes as default) and still have the database’s backend storage kept fault-tolerant and available in Apache Kafka.
Cons:
- It may involve moving away from a datastore you know and trust.
- You might want to scale storage independently of processing.
- You might need customized queries, specific to some datastores.
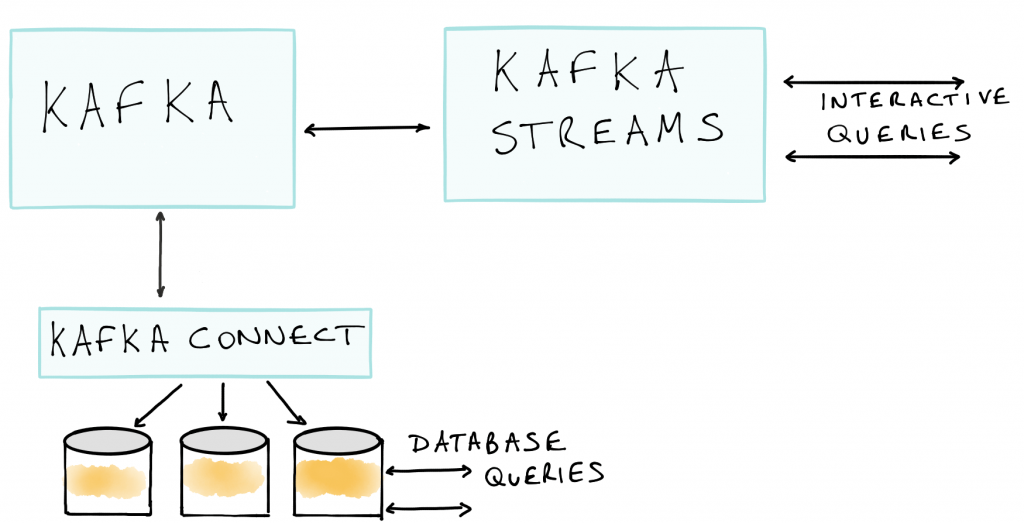
Whatever choice you make, ultimately you have more flexibility with Apache Kafka. Sometimes it will make sense to run a combination of both approaches, where some downstream applications are directly and interactively querying your Kafka Streams application for the latest results; and other downstream applications would run their queries against a full-fledged database, which most probably would be continuously updated with the latest processing results through a data flow from your Kafka Streams application to a Kafka output topic, and from there via Kafka Connect to the external database. That final architecture would then look something like this:
Interactive Queries: Under the hood
In the previous section we made the case for Interactive Queries. In this section, we take a closer look at how you can add interactive queries functionality to your streaming applications.
Which information can be queried interactively?
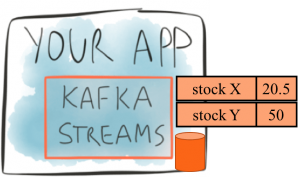 Interactive Queries allows developers to query a streaming app’s embedded state stores. The state stores keep the latest results of a processor node, e.g., one that aggregates data to compute a sum or average. For example, in the illustration on the left, a state store is shown containing the latest average bid price for two assets (stock X and stock Y). The state store is an embedded database (RocksDB by default, but you can plug in your own choice.)
Interactive Queries allows developers to query a streaming app’s embedded state stores. The state stores keep the latest results of a processor node, e.g., one that aggregates data to compute a sum or average. For example, in the illustration on the left, a state store is shown containing the latest average bid price for two assets (stock X and stock Y). The state store is an embedded database (RocksDB by default, but you can plug in your own choice.)
Interactive Queries are read-only, i.e., no modifications are allowed to the state stores. This is to avoid state inconsistencies with the inner workings of the streams processing app. In practice, allowing read-only access is sufficient for most applications that want to consume data from a queryable streaming application. Examples of such consumer applications are plenty. They include live dashboards, where developers can now build graphs and collect statistics without having to first consume data from the streaming application’s output topics or query the output after it was stored in other databases. Other examples can include security-related IP blacklisting, retail inventory, song charting, bank positioning management, etc.
So what does this mean in terms of efficiency? Well, we have avoided copying data to an external store. This means two things:
- Interactive Queries enables faster and more efficient use of the application state. Data is local to your application (in memory or possibly on SSDs); you can access it very quickly. This is especially useful for applications that need to access large amounts of application state, e.g., when they do joins.
- There is no duplication of data between the store doing aggregation for stream processing and the store answering queries.
How do I make my Kafka Streams applications queryable?
What do you need to do as a developer to make your Kafka Streams applications queryable? It turns out that Kafka Streams handles most of the low-level querying, metadata discovery and data fault tolerance for you. Depending on the application, you might be able to query straight out-of-the box with zero work (see local stores section below), or you might have to implement a layer of indirection for distributed querying (don’t worry, we provide a reference implementation as described in this section).
Querying local stores
We start simple with a single app’s instance. That instance can query its own local state stores out-of-the-box. It can enumerate all the stores that are in that instance (in any processor node) as well as query the values of keys in those stores.
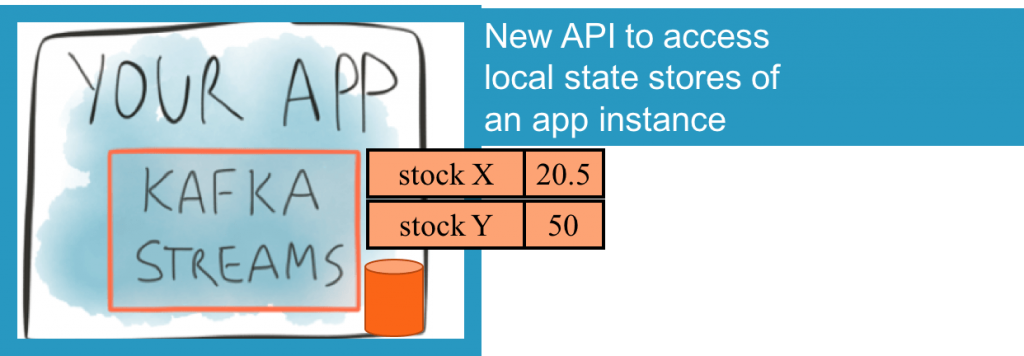
This is simple and useful for apps that have a single instance, however apps can have multiple instances running in potentially different servers. Kafka Streams will partition up the data amongst these instances to scale out the capacity. If I want to get the latest value for key “stock X” and that key is not in my instance, how do I go about finding it?
Discovering any instance’s stores
An application might have multiple instances running, each with its own set of state stores. We have made each instance aware of each other instance’s state stores through periodic metadata exchanges, which we provide through Kafka’s group membership protocol. Starting with Confluent Platform 3.1 and Apache Kafka 0.10.1, each instance may expose its endpoint information metadata (hostname and port, collectively known as the “application.server” config parameter) to other instances of the same application. The new Interactive Query APIs allow a developer to obtain the metadata for a given store name and key, and do that across the instances of an application.

Hence, you can discover where the store is that holds a particular key by examining the metadata. So now we know which store on which application instance holds our key but how do we actually query that (potentially remote) store? It sounds like we need some sort of RPC mechanism.
Towards app-specific distributed querying
Out-of-the box, the Kafka Streams library includes all the low-level APIs to query state stores and discover state stores across the running instances of an application. The application can then implement its own query patterns on the data and route the requests among instances as needed.
Apps often have intricate processing logic and might need non-trivial routing of requests among Kafka Streams instances. For example, an app might want to locate the instance that holds a particular customer ID, and then route a call to rank that customer’s stock to that particular instance. The business logic on that instance would sort the available data and return the result to the app. In more complex instances, we could have scatter-gather query patterns where a call to an instance results in N calls from that instance to other instances and N results being collated and returned to the original caller.
It is clear from these examples that there is no one API for distributed querying. Furthermore, there is no single best transport layer for the RPCs either (some users favor or must use REST within their company, others might opt for Thrift, etc.) RPCs are needed for inter-instance communication (i.e., within the same app). Otherwise instance 3 of the app can’t actually retrieve state information from instance 1. They are also needed for inter-apps communication, where other applications query the original application’s state.
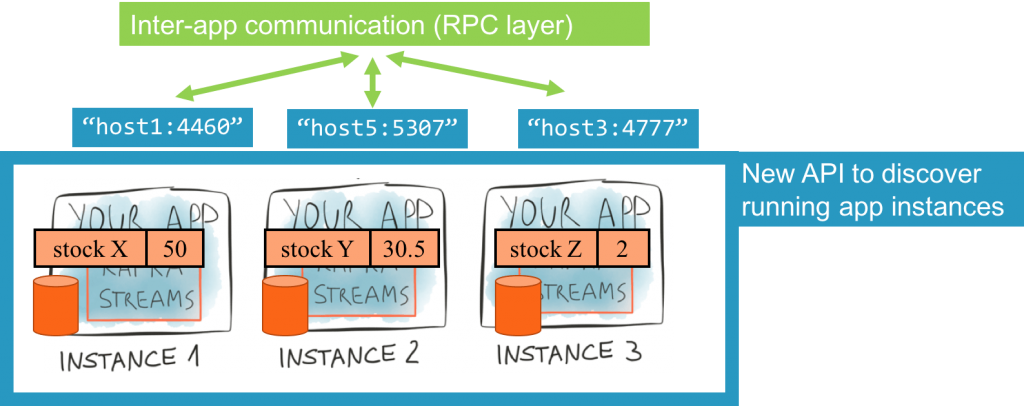
Confluent provides a reference REST-based implementation for the RPC layer for a simple reference app (see next section for code). This functionality was intentionally not included in Apache Kafka for the above reasons.
Once the RPC layer is in place, any application, like a dashboard or a microservice written in Scala or Python can interactively query your application for its latest processing results.
So show me some example code
Interactive Queries is a feature that is introduced in Apache Kafka 0.10.1. We have an example application available that demonstrates how this works end-to-end, using REST for RPC. We won’t go through all the code in detail here, but in a nutshell here is what happens. This app continuously computes the latest Top 5 music charts based on song play events collected in real-time in a Kafka topic. This example shows how we can query the various stores to get the latest music stats.
- Get a list of all the running instances in the system. Here is what you should expect:
https://gist.github.com/miguno/be8ee6e566c4f61e516efbc3be8b4a9a - List running instances that currently manage state store “word-count”: https://gist.github.com/miguno/aaaa8bec8516dcf10ce8abb16fc0c689
- Query the top-five songs:
https://gist.github.com/miguno/f37285ee905623893e54aa706f8c72f7 - Query the top-five songs by genre:
https://gist.github.com/miguno/5910d4f123ab0461cd4eb61d89cd58d8 - Query the details for a particular song:
https://gist.github.com/miguno/39397d097a7f57e42ffafc9523c5cb47
Summary
Regardless of whether you’re building a core banking application or an advertising data pipeline, there will inevitably be the desire to scale processing and make it more real time. Ultimately, this means bridging two worlds: the world of data processing and the world of interactive analytics. To do this you need a toolset that does both. Apache Kafka gives you the power of a declarative API with Kafka Streams. Interactive Queries bridges that into the interactive world by allowing you to query your data online as it is being processed.
We have now achieved a much simpler and much more application-centric infrastructure – we’ve reached the point of “Building Applications, Not Clusters or Infrastructure.” And with Interactive Queries, Apache Kafka is now an even better fit for areas such as event sourcing, CQRS and building microservices.
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
-
- Get started with the Kafka Streams API to build your own real-time applications and microservices
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications
Last but not least, Confluent is hiring. If you liked what you read here and are interested in engineering the next-gen streaming platform, please contact us!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.