New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Messaging as the Single Source of Truth
This post discusses Event Sourcing in the context of Apache Kafka®, examining the need for a single source of truth that spans entire service estates.
Events are Truth
One of the trickiest parts of building microservices is managing data. The reason is simple enough. In traditional systems there is a system of record, typically a database; the trusted resource for facts. In service-oriented systems there is no single source of truth, there are many. Different datasets are owned by a variety of different services. This is by design. Services will have a range of different roles: individual pieces in a far larger puzzle.
Calling remote services works well in many simple cases, populating drop-down boxes or looking up products. But if you want to combine datasets from a whole range of services, for example, to build a complex report or populate a datagrid on a dashboard, the remote calls turn out to be far more painful: a hand-crafted ‘distributed join’ spanning several independent services. The bigger the ecosystem gets, the more data becomes fragmented, and the harder these challenges become. Events help with this.
Events are typically sewn into an architecture because the concept of notification is desired. For example, if you’re building an online retail application, and you have a service that manages the shipping process, it makes sense to decouple that process from the user clicking ‘Buy’.
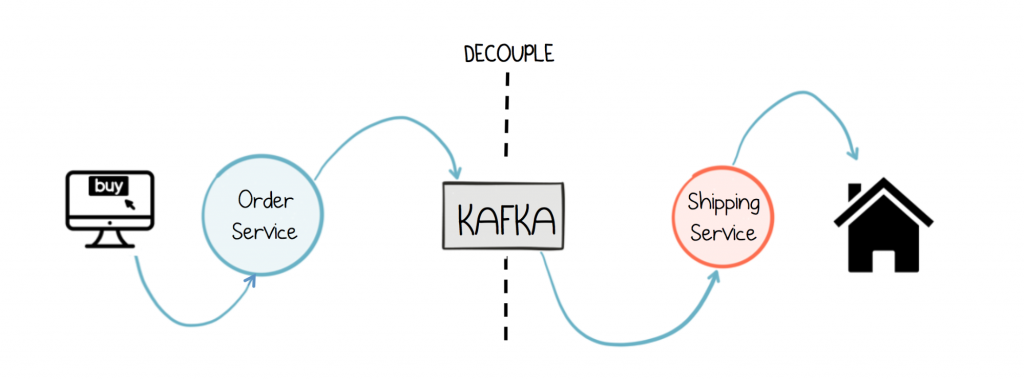
This concept of notification, via a broker, breaks down complex call graphs, allowing processes to decouple themselves from one another. We discussed the benefits of event-driven design in this previous post.
The kicker is that these events are much more than just notifications. Events are facts that evolve and tell a story. A narrative that describes your system’s evolution as a whole; a day in the life of your business, day after day, forever.
So events solve two important architectural issues: (1) Managing real-world asynchronicity (2) Bringing together and manipulating datasets from different services. If we use a traditional messaging system to push events around, the events are ephemeral. They are sent, received and deleted without any form of ‘historic reference’. But what would happen if we kept these events around? The answer to this question is both interesting and formative: the events form a single source of truth, something most modern service estates are sorely lacking.
Logs Never Lie and they Never Forget: Version Control for your Data.
If we keep events in a log, it starts to behave like a version control system for our data. For example, if you were to deploy a faulty program, the system might become corrupted, but it would always be recoverable. The sequence of events provides an audit point, so that you can examine exactly what happened. Further, when the bug is fixed, you can rewind your service back, and start your processing again.
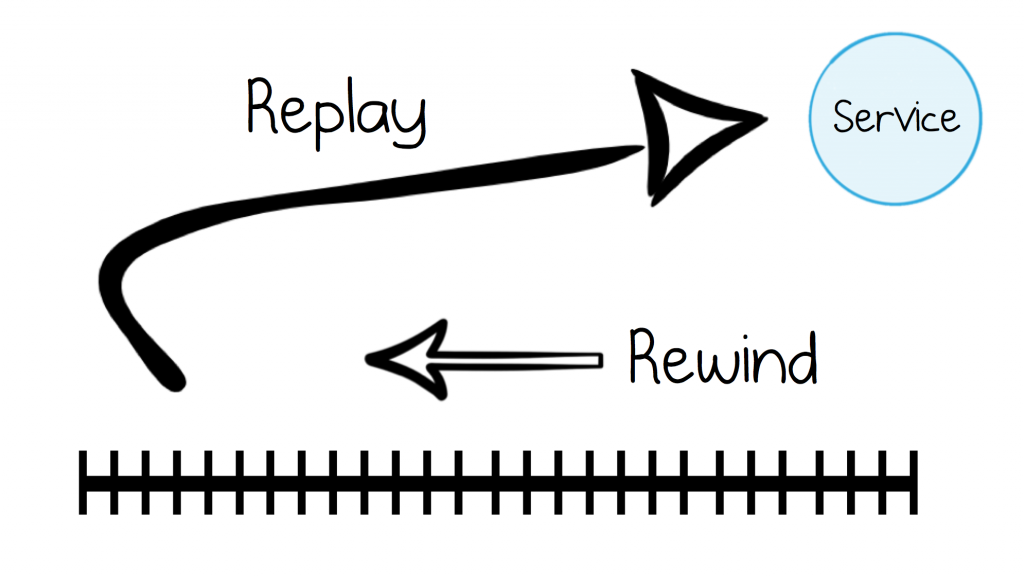
This is useful for addressing questions like: why did this order mysteriously get rejected? Why is this balance suddenly in the red? These are impossible questions for systems that hold data as mutable state because the past is lost forever. Moreover, rewinding and replaying is typically far less error prone than crafting some kookie, one-off rollback script.
Event Sourcing: Have One Source of Truth.
Event sourcing is a simple but powerful idea. When we build ‘traditional’ event-driven systems, each service typically listens to events, records its actions in a database, and raises new events. For example, if a user buys a widget, the Orders service would save the order to a database, then raise an event so the next step in the process (validation) would be triggered.
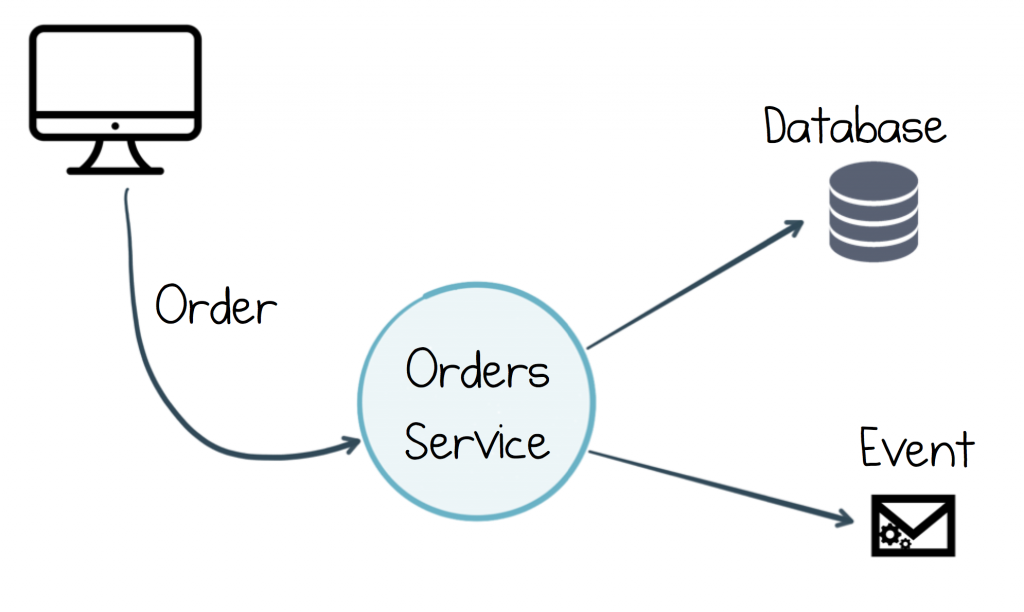
In this case, the database is the source of truth. That makes sense from the internal perspective of the Orders service. But if you think about it from the context of other microservices, the source of truth is really the event.
This leads to a few different issues. The first is maintaining consistency. The events are dual-written to both the database and the event stream and both writes must be atomic. The second is that, in practice, it’s quite easy for the data in the database, and the events that are emitted by the service, to diverge. They end up with different data models, following different code paths. As events are fire and forget, the ‘forgetting’ part leaves you open to subtle bugs, which only come to light when some downstream team notices and starts shouting at you! Finally, unlike the event stream, the database is typically a mutable resource, so regeneration of past events is not an option.
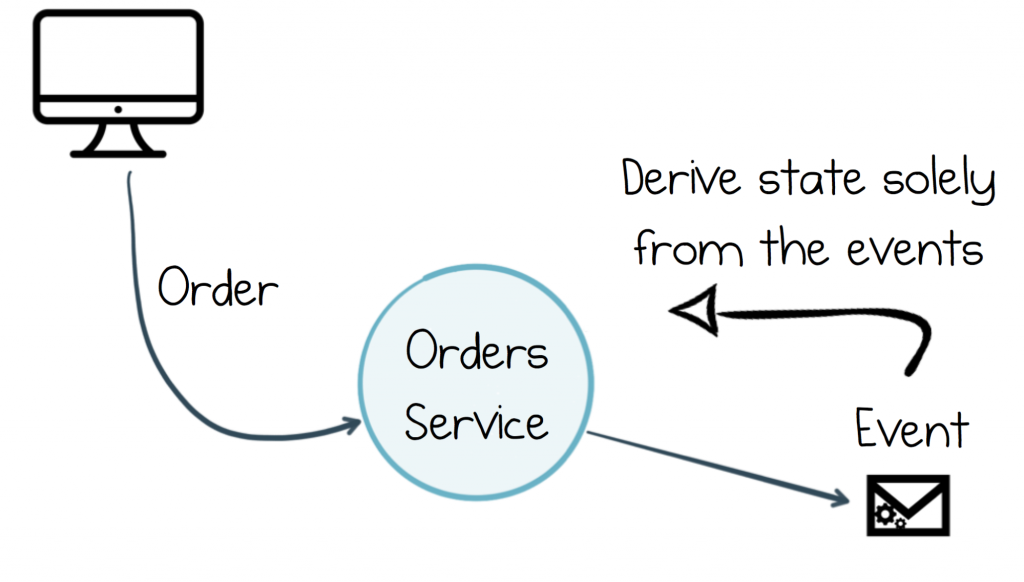
The alternative is to merge the two. We make the events first class entities which are used both internally within our service, as well as by other services downstream. So in an event sourced system, there is no dual-write. The events are the system of record. Services literally ‘eat their own dog food.’
Open, Evolutionary Architectures through Messaging that Remembers
One view of good system design is that it can’t be found on a whiteboard, in a Visio document, or any other static resource. It comes from a system’s ability to evolve: to grow into new requirements, to leverage new hardware and development practices, to incrementally morph itself into the unknown.
The event stream provides a foundation for this type of evolutionary approach. It is the data-plane that your services share.
So as the events you exchange become a shared dataset in their own right, they blur the distinction between communication protocol and data store. The resulting historical reference is something new services can hook into. A powerful bootstrapping tool, opening the architecture to extension.
For example, if you write a new service for fraud detection, that service requires orders, payments and customer information. This information is available in the log, either as a constantly updated stream or as a complete dataset: set offset = 0 and ingest.
Using Apache Kafka as an Event Store
As a technology, Kafka is well suited to the role of storing events long term. It provides powerful scalability primitives, as well as both retention-based and compacted topics. We discussed these attributes, in detail, earlier.
Retention-based topics, which are immutable, provide a ‘version history’: the event sourced view. If you were storing products, the topic would hold every amendment made, in chronological order. Conversely, compacted topics provide the ‘latest’ view (i.e. the current product catalog without the ‘version history’).
Very large datasets can be stored in Kafka. It is, after all, designed for ‘big data’ workloads, with production use cases of over one hundred terabytes not being uncommon in either retention-based or compacted forms.
But to better understand Kafka’s use as an event store we need to delve a little deeper into (a) how services get data into the log and (b) how they query the data that is held there.
Getting Events into the Log
Event Sourcing
At a high level, event sourcing is really just the observation that in an event driven architecture, the events are facts. So if you keep them around, you can use them as a datasource.
One subtlety comes from the way the events are modelled. They can be values: whole facts (an Order, in its entirety) or they can be a set of ‘deltas’ that must be re-combined (a whole Order message, followed by messages denoting just the state changes: “amount updated to $5”, “order cancelled” etc).
As an analogy, imagine you are building a version control system. When a user commits a file for the first time, you save it. Subsequent commits might only save the ‘delta’: just the lines that were added, changed or removed. Then, when the user performs a checkout, you open the version-0 file and apply all the deltas, to derive to the current state.
The alternate approach is to simply store the whole file, exactly as it was at the time it was changed. This makes pulling out a version quick and easy, but to compare different versions you would have to perform a ‘diff’.
The essence of event sourcing is the former approach: the current state is derived. People sometimes get hung up on this and they probably shouldn’t. Both approaches are perfectly valid, but come with slightly different tradeoffs in practice. Regardless of which one you pick, the important thing is to save facts exactly as they were observed, immutably.
Implementing event sourcing in Kafka is a no-op if you’ve taken the event-driven approach. You simply write events as they occur. Sometimes you will have multiple output events which is where transactions become useful. But you do need to consider how to handle reads, as there are a few options, which are discussed in more detail below.
Writing Through a Database into an Event Stream
One way to get started with events is to write through a database table into a Kafka topic.
The most reliable and efficient way to do this is using a technique called Change Data Capture (CDC). Most databases write every single insert, update and delete operation to a transaction log. This serves as a “source of truth” to the database and in case of errors, the database state is recovered from there. This means that we can also recreate the database state externally by copying the transaction log to Kafka, via Kafka’s Connect API, in a way that makes the events (insert, update, delete operations) accessible by other services.
Different databases take slightly different approaches to this. Couchbase, which we’ve used in the example, uses a push-based mechanism, rather than long polling, but the end result is the same.
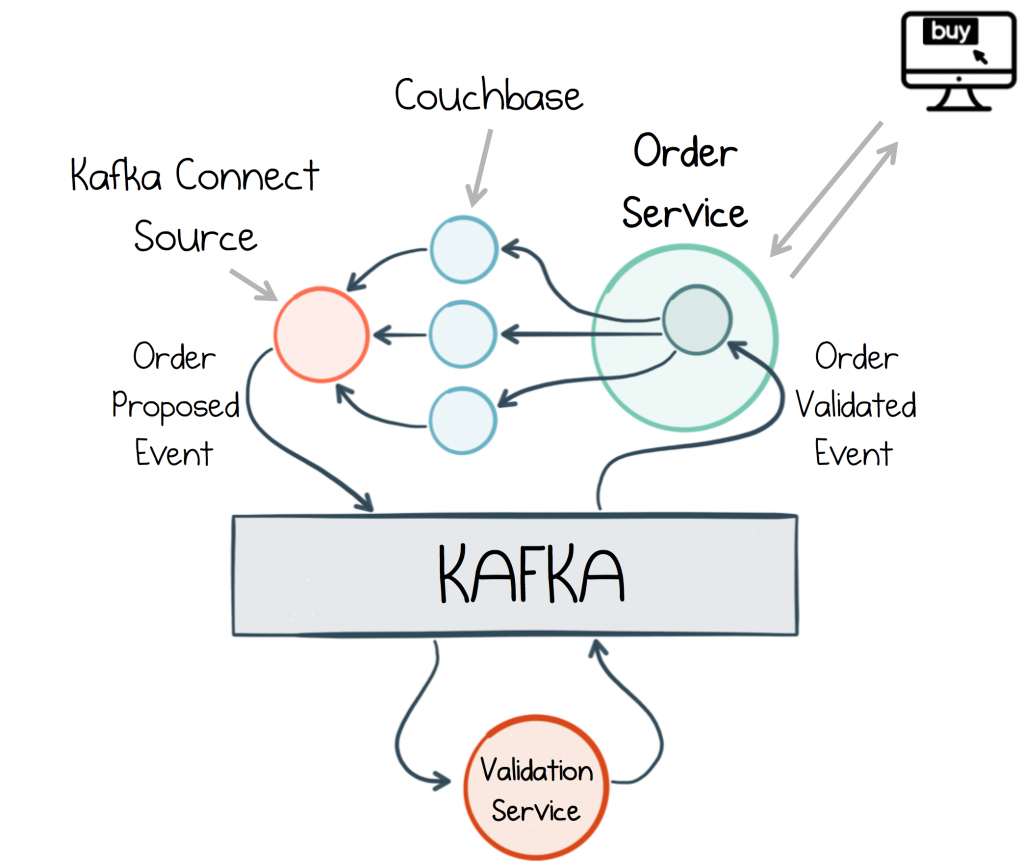
In the example above, the Orders Service writes Orders to a database (Couchbase is used here but any CDC-enabled database will work). The writes are converted into an event stream by Kafka’s Connect API. This triggers downstream processing which validates the order. When the OrderValidated event returns to the Orders Service the database is updated with the final state of the order, before the call returns to the user.
The advantage of this ‘database-fronted’ approach is it provides a consistency point: you write through it into Kafka, meaning you can always read your own writes. The pattern is also less error prone than write-aside, where your service writes to the database, then writes to the log—a pattern that requires distributed transactions for ensured accuracy.
When we talk about streaming approaches later in this series, which embed storage inside our services, we’ll see they achieve an equivalent result.
CDC isn’t available for every database, but the ecosystem is growing. Some popular databases currently supported for CDC in Kafka Connect are MySQL, Postgres, MongoDB and Cassandra. There are also proprietary CDC connectors for Oracle, IBM, SQL Server etc. The full list of connectors is here.
Incrementally Evolve Away from Legacy Systems
One of the most useful applications of Change Data Capture is in migrating from an old architecture to a new one. In reality, most projects have an element of legacy and renewal, and while there is a place for big-bang redesigns, incremental change is typically an easier pill to swallow.
The problem with legacy is there is usually a good reason for moving away from it: the most common being that it is hard to change. Most business operations in legacy applications will converge on their database. This means that, no matter how creepy the legacy code is, the database provides a clean and coherent ‘seam’ to latch into the existing business workflow, from where we can extract events. Once we have the events, we can build new event-driven services that allow us to evolve away from the past, incrementally.
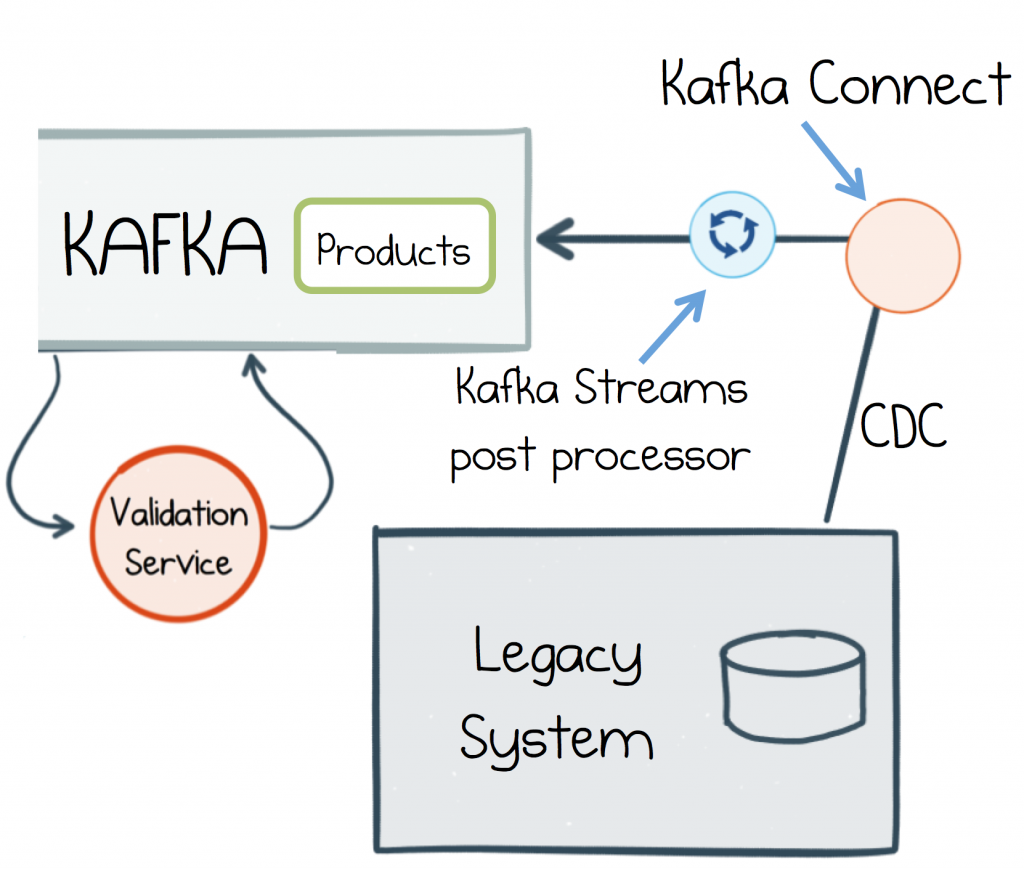
So part of our legacy system might allow admins to manage and update the product catalog. We might retain this functionality by sucking the dataset into Kafka from the legacy system’s database. Then that product catalog can be reused in the validation service, or any other.
An issue with attaching to legacy or externally source data is that the data is not always well formed. If this is a problem, consider adding a post processing stage. Kafka Connect’s single message transforms are useful for this type of operation, for example adding simple adjustments or enrichments—like adding information about the source—, while Kafka’s Streams API is ideal for simple to very complex manipulations and for pre-computing views that other services need.
Creating Materialized Views
In Memory Views
Event sourcing is often used with Memory Images. This is just a fancy term, coined by Martin Fowler, for caching a whole dataset into memory—where it can be queried—rather than making use of an external database.
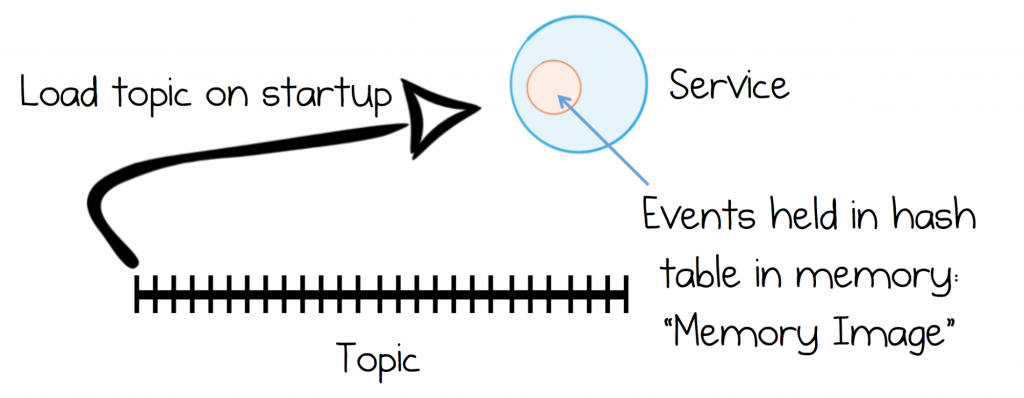
Memory Images provide a simple and efficient model for datasets that (a) fit in memory and (b) can be loaded in a reasonable amount of time. For example, the validation service above might load one million products into memory, at say 100B each. This would take around 100MB of RAM and would load from Kafka in around a second on GbE. These days memory is typically easier to scale than network bandwidth so ‘worst case load time’ is often the more limiting factor of the two.
To reduce the load time issue it’s useful to keep a snapshot of the event log using a compacted topic (which we discussed in a previous post). This represents the ‘latest’ set of events, without any of the ‘version history’.
Memory Images provide an optimal combination of fast, in process reads, with write performance far faster and more scalable than a typical database. Thus it’s particularly well suited to high performance use cases.
Derived Views created in a Database
Kafka comes with several sink connectors that push changes into a wide variety of databases. This opens the architecture to a huge range of data stores, tuned to handle a variety of workloads. In the example here we use ElasticSearch for its full-text indexing capabilities, but whatever shape the problem there is probably a datastore that fits.
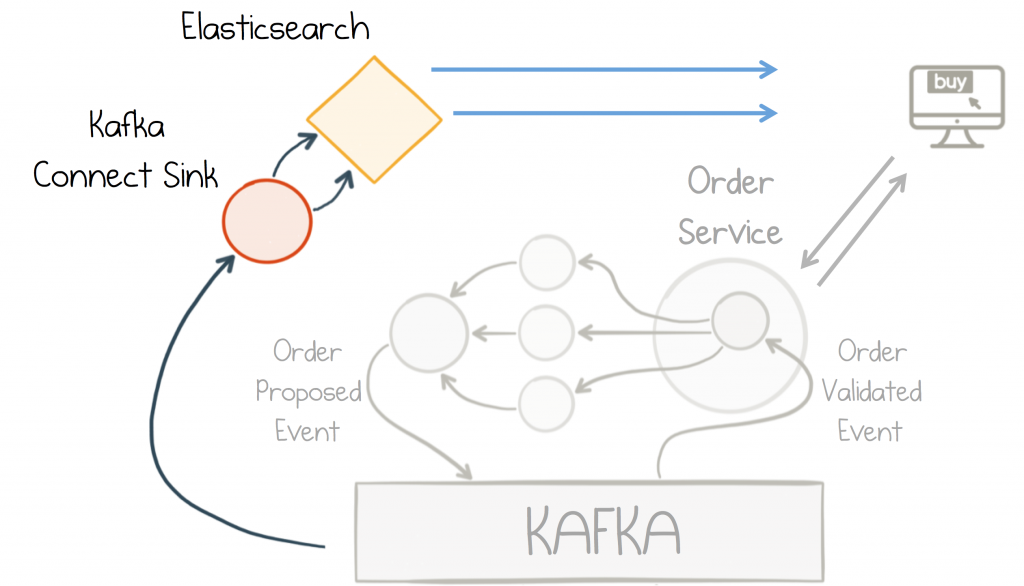
Full Text search is added via an Elasticsearch database
connected to the Orders topic via Kafka’s Connect API interface.
This ability to quickly and efficiently translate the log into a range of different ‘views’ turns out to be a powerful attribute of its own. Later in the series we’ll look a lot more closely at this pattern, in particular the various service specific views we are able to create.
Derived Views in KStreams State Stores
Kafka’s Streams API provides the most complete abstraction for using event sourcing within JVM based services. A key element of this is the notion of State Stores. These are Key-Value databases (RocksDB by default) which are backed by Kafka topics.
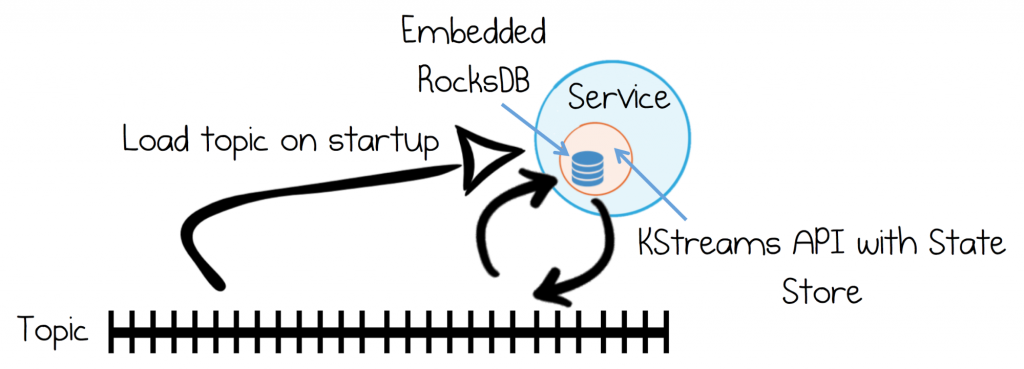
Services can read and write events via a state store. Events are flushed to Kafka and reloaded on startup.
The State Store is backed by RocksDB (or hash table).
You can write events to a State Store and they will be flushed to Kafka. Additionally, when a service starts, it will automatically populate its State Stores, so events can be queried from within the service. All the mechanics for this are handled for you. This is, however a far larger topic, so we will leave a detailed discussion to a later post.
The Latest-Versioned Pattern
A useful pattern, when using event sourcing in this way, is to hold events twice: once in a retention-based topic and once in a compacted topic. The retention-based topic will be larger as it holds the ‘version history’ of your data. The compacted topic is just the ‘latest’ view, and will be smaller, so it’s faster to load into a Memory Image or State Store.
To keep the two topics in sync you can either dual write to them from your client (using a transaction to keep them atomic) or, more cleanly, use Kafka Streams to copy one into the other. Later in this series we’ll look at extending this pattern to create a whole variety of different types of views.
The Truth Should be Shared
Events are an important part of real world system design. They represent an invaluable trinity of notification, state distribution and decoupling. But Apache Kafka changes things. It pushes these three into a layer of permanence: messaging that remembers.
So your applications get a choice: they can hit other services directly, and stay request driven, or embrace the event streams themselves; be it to drive their processing or extract whole datasets for their own private use. A value proposition that compounds as ecosystems grow and become more complex.
As we develop these ideas further we are forced to question the very nature of data itself. To consider events not only as a source of shared truth, but as the only source of truth that matters. A shared narrative that underpins and safeguards the whole service estate.
But if there is one killer feature of this architectural pattern it is its ability to evolve. The log breeds extensibility. Bootstrapping new services is a breeze with datasets always on hand, and always up to date. Migrating away from legacy, moving to new cloud platforms, new geographical regions, or simply building new services whose requirements have yet to be conceived, all these things are empowered by a service backbone that embraces data at its core.
In the next post, we’ll take this argument a step further by rethinking estates of services using the lens of a database ‘turned inside out’.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled (Read Next)
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
Find Out More:
“Immutability Changes Everything” by Pat Helland
“Data on the Outside, Data on the Inside” by Pat Helland
“Commander: Better Distributed Applications through CQRS and Event Sourcing” by Bobby Calderwood
“Event sourcing, CQRS, stream processing and Apache Kafka: What’s the connection?” by Neha Narkhede
“Event Sourcing” Martin Fowler’s Original Definition
“What do you mean by Event Driven” post and associated talk by Martin Fowler
Confluent Resources:
Apache Kafka® for Microservices: A Confluent Online Talk Series
Apache Kafka® for Microservices: Online Panel
Microservices for Apache Kafka white paper
Kafka Streams API Landing Page
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Streaming Data Integration with Apache Kafka®
Streaming data integration supports enriched, reusable, canonical streams that can be transformed, shared ,or replicated to different destinations, not just one.



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.