New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Chain Services with Exactly-Once Guarantees
This fourth post in the microservices series looks at how we can sew together complex chains of services, efficiently, and accurately, using Apache Kafka’s Exactly-Once guarantees.
Duplicates, Duplicates Everywhere
Any service-based architecture is itself a distributed system, a field renowned for being difficult, particularly when things go wrong. We have thought experiments like The Two Generals Problem and proofs like FLP which highlight that these systems are difficult to work with.
In practice we make compromises. We rely on timeouts. If one service calls another service and gets an error, or no response at all, it retries that call in the knowledge that it will get there in the end.
The problem is that retries can result in duplicate processing—which can cause very real problems. Taking a payment, twice, from someone’s account will lead to an incorrect balance. Adding duplicate tweets to a user’s feed will lead to a poor user experience. The list goes on.
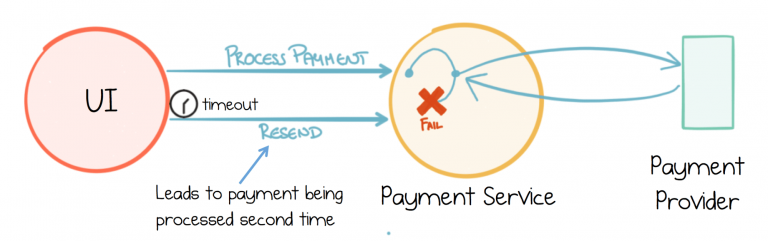
The UI makes a call to the Payment Service, which calls an external Payment Provider. The Payment Service fails before returning to the UI. As the UI did not get a response it eventually times out and retries the call. The user’s account could be debited twice.
Paying for some product twice sounds pretty bad, particularly if you’re the one doing the paying, but many other scenarios seem far more innocuous. If a customer updates their address, and a failure causes the message to be sent twice, the end result would likely be the same. The address would be updated, to the same value, a second time. Put another way, duplicate messages have no affect on this particular outcome; the operation is naturally idempotent. We use this trick all the time when we build systems, often without even thinking about it.
But what is really happening here is the “address updates” are being deduplicated at the end point, probably by storing them in a database by CustomerId.
We can use the same trick to make payment messages idempotent. To ensure correctness the Payment Provider would have to de-duplicate payments, typically using a database, making use of the unique IDs of each payment. This need for deduplication applies equally to synchronous and asynchronous systems.
So it is actually the use case itself that is important. So long as deduplication happens at the start and end of each use case, it doesn’t matter how many duplicate calls are made in between. This is an old idea, dating back to the early days of TCP. It’s called the End-to-End Principle.
The rub is this: As the number of services increases, so does the cognitive overhead of considering how your program will be affected when duplicates occur. Also, as a variety of use cases build up over time, the end-point trick becomes less useful, as it becomes less clear where each one starts, and ends.
As a result most event-driven systems end up deduplicating on every message received, before it is processed, and every message sent out has a carefully chosen ID, so it can be deduplicated downstream. This is at best a bit of a hassle. At worst it’s a breeding ground for errors.
But if you think about it, this is no more an application layer concern than ordering of messages, arranging redelivery, or any of the other benefits that come with TCP. We choose TCP over UDP, because we want to program at a higher level of abstraction, where delivery, ordering, etc., are handled for us. So we’re left wondering why these issues of duplication have leaked up into the application layer? Isn’t this something our infrastructure should solve for us?
Streaming Platforms, like Apache Kafka, address these issues, allowing you to build long chains of services, where the processing of each step in the chain is wrapped in exactly-once guarantees.
Building Services with Exactly-Once Guarantees
Apache Kafka ships with exactly-once processing built in. Now this isn’t some magic fairy dust that sprinkles exactly-onceness over your entire system. Your system will involve many different parts, some based on Kafka, some based on other technologies, the latter of which won’t be covered by the guarantee.
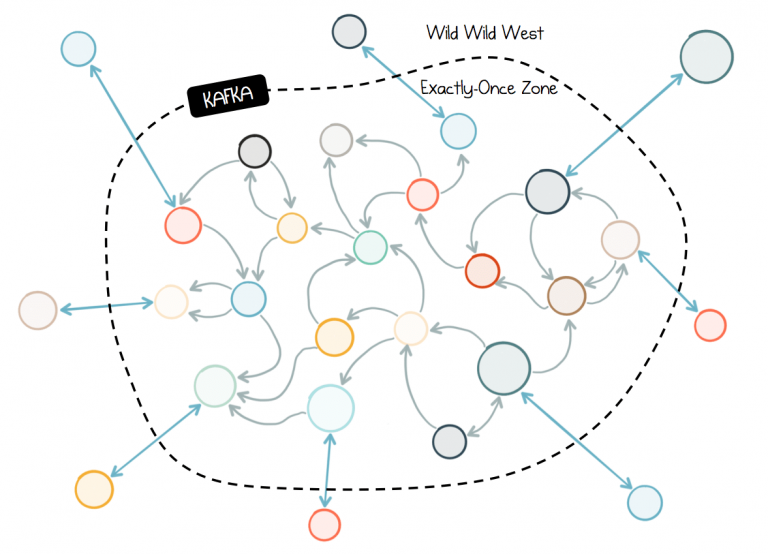
But it does sprinkle exactly-onceness over the Kafka bits; the interactions between your services. This frees services from the need to deduplicate data coming in, and pick appropriate keys for data going out. So we can happily chain services together, inside an event driven workflow, without these additional concerns. This turns out to be quite empowering.
As a simple example imagine we have an account validation service. It takes Deposits in, validates them, then sends a new message back to Kafka marking the deposit as validated.
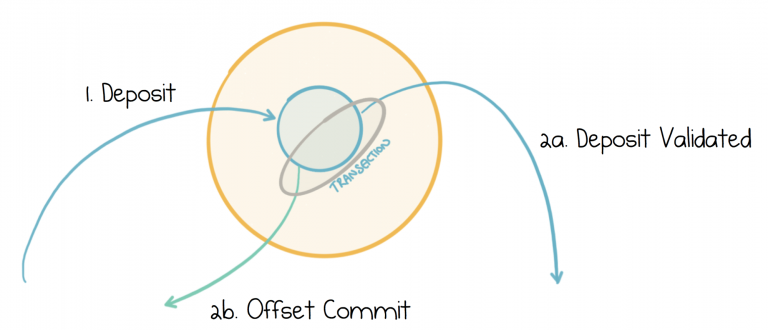
You may know that Kafka records the progress that each consumer makes by storing an offset in a special topic, called consumer_offsets. So to validate each deposit exactly once we need to perform the final two actions (a) send the “Deposit Validated” message back to Kafka and (b) commit the appropriate offset to the consumer_offsets topic—as a single atomic unit. The code for this would look something like the below:

But unlike direct service calls, Kafka is a message broker. An intermediary. This means there are actually two opportunities for duplication. Sending a message to Kafka might fail before an acknowledgement is sent back, with a resulting retry and potential for a duplicate message. On the other side the read from Kafka might fail, before offsets are committed, meaning the same message might be read a second time, when the process restarts.
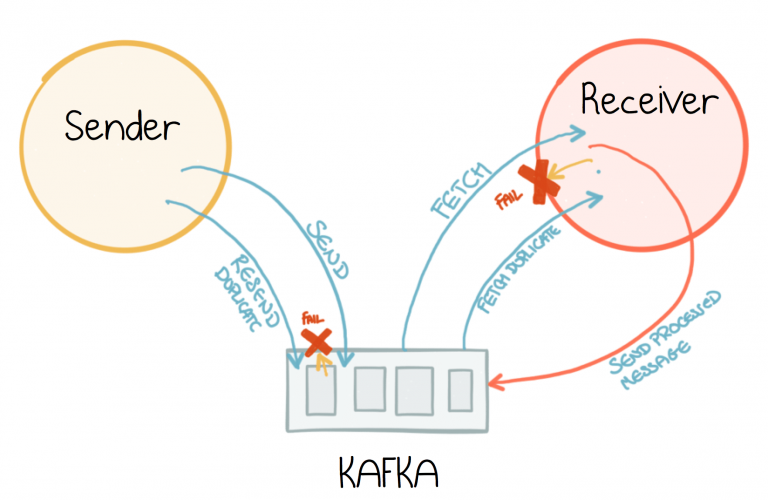
So idempotence is added to the broker to address the send-side. Idempotence, in this context, is just deduplication. Each producer is given an identifier, and each message is given a sequence number. The combination of the two uniquely defines each batch of messages sent. The broker uses this unique sequence number to work out if a message is already in the log and discards it if it is. This is a significantly more efficient approach than storing every key you’ve ever seen in a database.
That covers the send side, ensuring we don’t get duplicates in the log. On the read side we might simply deduplicate. But Kafka’s Transactions actually provide a broader guarantee, more akin to transactions in a database, tying all messages sent together in a single atomic unit. Be it to one topic or to many topics, it doesn’t matter. But whilst there are conceptual similarities, the mechanism is very different from that seen in your standard DBMS. It’s also a lot more scalable.
So idempotence is built into the broker, meaning you can’t get a duplicate message in the log. Then a Transactions API is layered on top, to handle the read side, as well as chaining together subsequent calls atomically.
How Kafka’s Transactions Work Under the Covers
Looking at the code example above you’ll see that transactions like these, which are designed for Streaming Platforms, look a bit like transactions in a database. You start a transaction, write messages to Kafka, then commit or abort. But the implementation is quite different to that found in a database, so it’s worth building an understanding of how it actually works.
One key difference is the use of marker messages which make their way through the various streams. Marker messages are an idea first introduced by Chandy & Lamport almost thirty years ago in a method called the Snapshot Marker Model. Kafka’s transactions are an adaptation of this idea, albeit with a subtly different goal.
While this approach to transactional messaging is complex to implement, conceptually it’s quite easy to understand. Take our previous example above, where two messages were written to two different topics atomically. One message goes to the Deposits topic, the other to the committed_offsets topic.
‘Begin’ markers are sent down both*. We then send our messages. Finally, when we’re done, we flush each topic with a ‘Commit’ (or ‘Abort’) marker which concludes the transaction.
Now the aim of a transaction is to ensure only ‘committed’ data is seen by downstream programs. To make this work, when a consumer sees a ‘Begin’ marker it starts buffering internally. Messages are held up until the “Commit” marker arrives. Then and only then are the messages presented to the consuming program. This buffering ensures that consumers only ever read committed data*.
![]()
Conceptual model of transactions in Kafka
To ensure each transaction is atomic the sending of the commit markers makes use of a Transaction Coordinator. There will be many of these spread throughout the cluster, so there is no single point of failure, but each transaction makes use of just one of them.
The transaction coordinator is the ultimate arbiter that marks a transaction committed, atomically, and maintains a transaction log to back this up (this step implements two phase commit).
For those that worry about performance, there is of course an overhead that comes with this feature, and if you were required to commit after every message the performance degradation would be noticeable. But in practice there is no need for that as the overhead is dispersed among whole batches of messages, allowing us to balance transactional overhead with worst-case latency. For example, batches that commit every 100ms, with a 1KB message size, have a 3% overhead when compared to in-order, at-least-once delivery. You can test this out yourself with the performance test scripts that ship with Kafka.
In reality there are many subtle details to this implementation, particularly around recovering from failure, fencing zombie processes, and correctly allocating IDs, but what we have covered here is enough to provide a high-level understanding of how this feature works. You can find out more about the implementation here.
*In practice a clever ‘optimisation’ is used to move buffering from the consumer to the broker, reducing memory pressure. Begin markers are also optimized out.
Transactions that Span both Streams and State: A More Complex Example
Not having to handle idempotence manually is certainly a boon, but transactions actually provide more rigorous guarantees. Kafka can be used both as a communication mechanism, pushing events from service to service, as well as a persistence mechanism, storing our service’s state so it can be reloaded after a restart. We can use transactions to tie these two concepts together, atomically. This turns out to be a powerful idea.
Imagine we extend the previous example so our validation service keeps track of the balance as money is deposited. So if the balance is currently $50, and we deposit $5 more, then the balance should go to $55. We record that $5 was deposited, but we also store this ‘current balance’, $55, by writing it to a compacted topic.
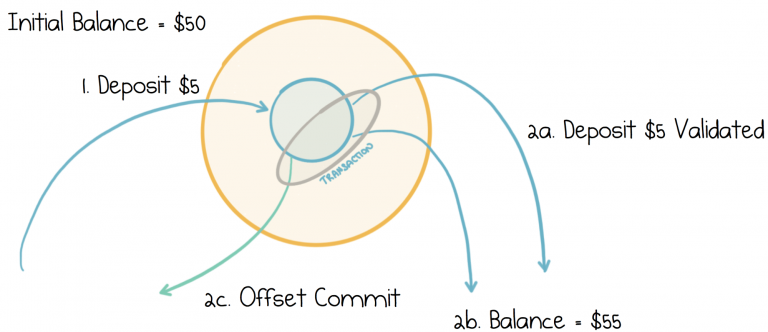
We wrap the ‘balance update’, along with the other two writes, in a transaction, ensuring the balance will always be atomically in-sync with deposits. Importantly, we can also read the current account balance when our service starts (or crashes and restarts) and know it is correct because it was committed transactionally back to Kafka. So the code would look something like this:
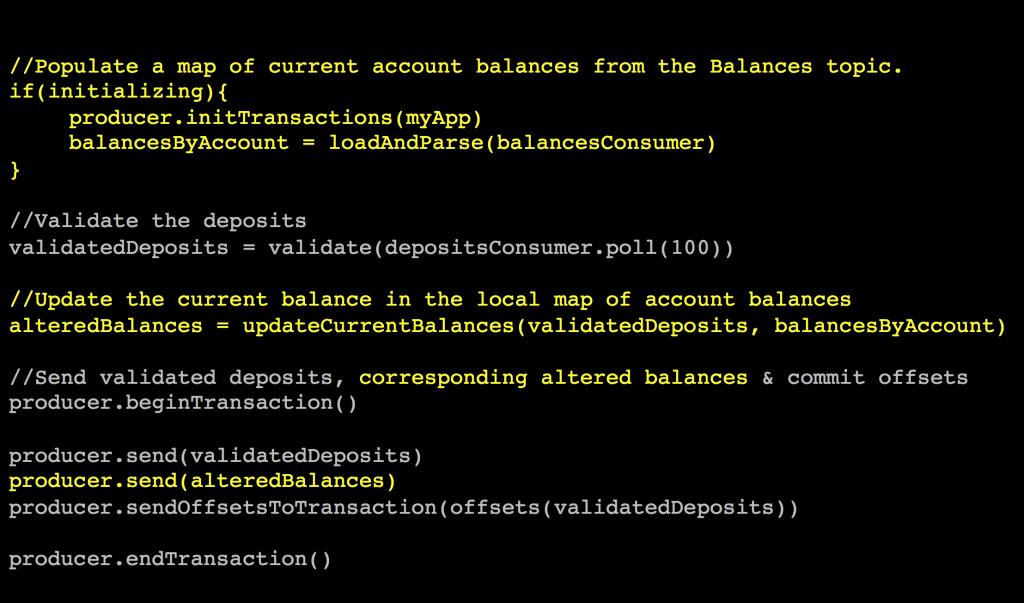
What’s interesting about this example is we are blending concepts of messaging and state management. We listen to events, act, and create new events, but we also manage state, the “current balance”, in Kafka. All wrapped in the same transaction.
When we discuss Stateful Stream Processing later in this series we’ll be leveraging this fact heavily through the more functional Kafka Streams API, which rolls in its own state management via state stores.
Do we need Transactions? Can we do all this with Idempotence?
People have been building event driven systems for decades, simply by making their processes idempotent with identifiers and databases. But implementing idempotence comes with some challenges. While defining the ID of an Order is relatively obvious, not all streams of events have such a clear concept of identity. If we had a stream of events representing “the average account balance per region per hour” we could come up with a suitable key, but you can imagine it would be a lot more brittle and error prone.
Also, transactions encapsulate the concept of deduplication entirely inside your service. You don’t muddy the waters seen by other services downstream, with any duplicates you might create. This makes the contract of each service clean and encapsulated. Idempmotence, on the other hand, relies on every service that sits downstream correctly implementing deduplication, which clearly makes their contract more complex and error prone.
What Can’t Transactions Do?
There are a few limitations or potential misunderstandings of transactions that are worth noting. Firstly, they only work in situations where both the input and the output goes through Kafka. If you are calling an external service (e.g. via HTTP), updating a database, writing to stdout, or anything other than writing to and from the Kafka broker, transactional guarantees won’t apply and calls can be duplicated. So much like using a transactional database, transactions only work when you are using Kafka.
Also akin to accessing a database, transactions commit when messages are sent, so once they are committed there is no way to roll them back, even if a subsequent transaction downstream fails. So if the UI sends a transactional message to the Orders Service and the Orders Service fails while sending messages of its own, any messages the Orders Service sent would be rolled back, but there is no way to roll back the transaction in the UI. If you need multi-service transactions consider implementing Sagas.
Transactions commit atomically in the Broker (just like a transaction would commit in a database) but there are no guarantees regarding when an arbitrary consumer will read those messages. This may appear obvious, but it is sometimes a point of confusion. Say we send a message to the Orders topic and a message to the Payments topic, inside a transaction, there is no way to know when a consumer will read one or the other, or that they might read them together. But again note, this is identical to the contract offered by a transactional database.
Finally, in the examples here we use the producer and consumer APIs to demonstrate how transactions work. But the Kafka’s Streams API actually requires no extra coding whatsoever. All you do is set a configuration and exactly-once processing is enabled automatically.
But while there is full support for individual producers and consumers, the use of transactions with consumer groups is subtly nuanced (essentially you need to ensure that a separate transactional producer is used for each consumed partition) so we recommend using the Streams API when chaining together producers and consumers where consumer groups are supported without any extra considerations on your part.
Making use of Transactions in your Services
In the second post in this series we described, in some detail, a design pattern known as Event Collaboration. This is a good example of transactions simplifying a complex, multi-stage business workflow which is relatively fine grained. So while operations like contacting the Payment or Shipping Provider will still need careful, end-to-end IDs, the internal service interactions don’t inherit this concern.
![]()
Later in the series we’ll discuss using the Streams API to build Streaming Services. Building reliable streaming services without transactions turns out to be pretty tough. There are a couple of reasons for this: (a) Streams applications make use of more intermediary topics and deduplicating them after each step is a burden (b) the DSL provides a range of one-to-many operations (e.g. flatMap()) which are hard to manage idempotently without the transactions API.
Kafka’s transactions feature resolves these issues, along with atomically tying stream processing with the storing of intermediary state in state stores.
Summing Up
Transactions affect the way we build services in a number of specific ways:
Firstly, they take idempotence right off the table for services interconnected with Kafka. So when we build services that follow the pattern: read, process, (save), send, we don’t need to worry about deduplicating inputs or constructing keys for outputs.
Secondly, we no longer need to worry about ensuring there are appropriate unique keys on the messages we send. This typically applies less to topics containing business events, which often have good keys already. But it’s useful when managing derivative/intermediary data, say when we’re remapping events, creating aggregate events, or using the Streams API.
Thirdly, where Kafka is used for persistence, we can wrap both messages we send to other services, and state we need internally, in a single transaction that will commit or fail. This makes it easier to build simple stateful apps & services.
Finally, transactions give a kind of closure to services that read input and produce output. This encapsulates one of the key side effects of distributed programming, so you can build and test services in isolation without needing to worry about duplicate inputs.
Put simply, when building event-based systems, Kafka’s transactions free you from the worries of failure and retries in a distributed world—a worry that really should be a concern of the infrastructure, not a concern of your code. This raises the level of abstraction, making it easier to get accurate, repeatable results from large estates of fine-grained services.
Having said that, we should also be careful. Transactions remove just one of the issues that come with distributed systems, but there are many more. Coarse-grained services still have their place. But in a world where we want to be fast and nimble, Streaming Platforms raise the bar, allowing us to build finer grained “micro” services that behave as predictably in complex chains as they would standing alone.
In the next post we’ll look at leveraging Kafka’s ability to retain messages long term, and how this changes the way we handle shared data. Data-on-the-outside.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth (Read Next)
Part 6: Leveraging the Power of a Database Unbundled
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
Find Out More:
Exactly-once Semantics are Possible: Here’s How Kafka Does it
Introducing Exactly Once Semantics in Apache Kafka®
Other Resources:
Apache Kafka® for Microservices: A Confluent Online Talk Series
Apache Kafka® for Microservices: Online Panel
Microservices for Apache Kafka white paper
Kafka Streams API Landing Page
Did you like this blog post? Share it now
Subscribe to the Confluent blog





