New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building a Microservices Ecosystem with Kafka Streams and KSQL
Today, we invariably operate in ecosystems: groups of applications and services which together work towards some higher level business goal. When we make these systems event-driven they come with a number of advantages. The first is the idea that we can rethink our services not simply as a mesh of remote requests and responses—where services call each other for information or tell each other what to do—but as a cascade of notifications, decoupling each event source from its consequences.
The second comes from the realization that these events are themselves facts: a narrative that not only describes the evolution of your business over time, it also represents a dataset in its own right—your orders, your payments, your customers, or whatever they may be. We can store these facts in the very infrastructure we use to broadcast them, linking applications and services together with a central data-plane that holds shared datasets and keeps services in sync.
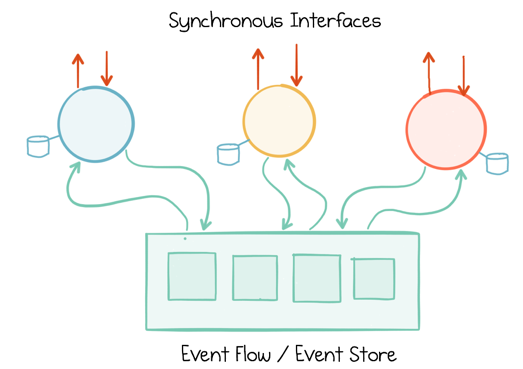
These insights alone can do much to improve speed and agility, but the real benefits of streaming platforms come when we embrace not only the messaging backbone but the stream processing API itself. Such streaming services do not hesitate, they do not stop. They focus on the now—reshaping, redirecting, and reforming it; branching substreams, recasting tables, rekeying to redistribute and joining streams back together again. So this is a model that embraces parallelism not through brute force, but instead by sensing the natural flow of the system and morphing it to its whim.
Life is a series of natural and spontaneous changes. Don’t resist them – that only creates sorrow. Let reality be reality. Let things flow naturally forward.
Lao-Tzu
Complex business systems can be built using the Kafka Streams API to chain a collection of asynchronous services together, connected via events. The differentiator here is the API itself, which is far richer than, say, the Kafka Producer or Consumer. It ships with native support for joining, summarising and filtering event streams, materializing tables, and it even encases the whole system with transparent guarantees of correctness.
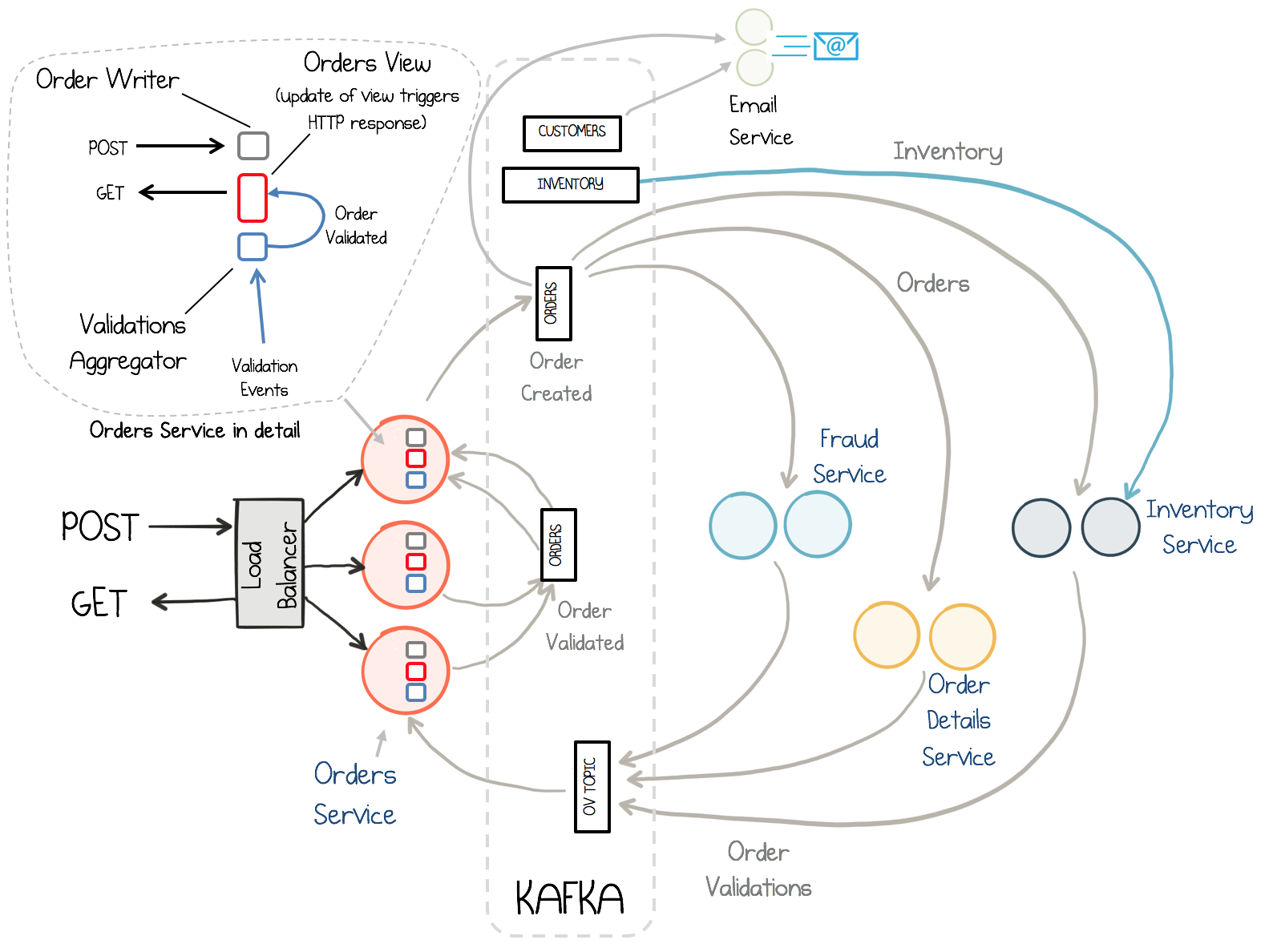
Systems built in this way, in the real world, come in a variety of guises. They can be fine-grained and fast executing, completing in the context of an HTTP request, or complex and long-running, manipulating the stream of events that map a whole company’s business workflow. This post focusses on the former, building up a real-world example of a simple order management system that executes within the context of an HTTP request, and is entirely built with Kafka Streams. Each service is a small function, with well-defined inputs and outputs. As we build this ecosystem up, we will encounter problems such as blending streams and tables, reading our own writes, and managing consistency in a distributed and asynchronous environment. Here is a picture of where we will end up (just to whet your appetite):
Your System has State: So Let’s Deal with It
Making services stateless is widely considered to be a good idea. They can be scaled out, cookie-cutter-style, freed from the burdensome weight of loading data on startup. Web servers are a good example of this: to increase the capacity for generating dynamic content a web tier can be scaled horizontally, simply by adding new servers. So why would we want anything else? The rub is that most applications need state of some form, and this needs to live somewhere, so the system ends up bottlenecking on the data layer—often a database—sat at the other end of a network connection.
In distributed architectures like microservices, this problem is often more pronounced as data is spread throughout the entire estate. Each service becomes dependent on the worst case performance and liveness of all the services it connects to. Caching provides a respite from this, but caching has issues of its own: invalidation, consistency, not knowing what data isn’t cached, etc.
Streaming platforms come at this problem from a slightly different angle. Services can be stateless or stateful as they choose, but it’s the ability of the platform to manage statefulness—which means loading data into services—that really differentiates the approach. So why would you want to push data into your services? The answer is that it makes it easier to perform more data-intensive operations efficiently (the approach was invented to solve ultra-high-throughput streaming problems after all).
To exemplify this point, imagine we have a user interface that allows users to browse Order, Payment, and Customer information in a scrollable grid. As the user can scroll through the items displayed, the response time for each row needs to be snappy.
In a traditional, stateless model each row on the screen would require a call to all three services. This would be sluggish in practice, so caching would likely be added, along with some hand-crafted polling mechanism to keep the cache up to date.
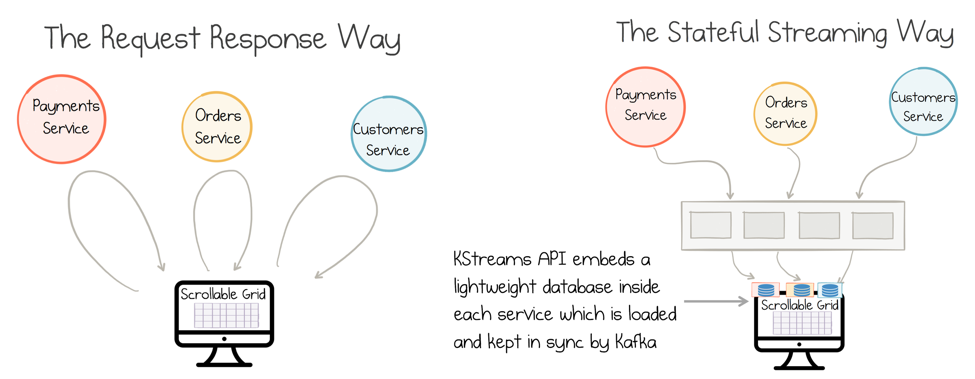
Using an event-streaming approach, we can materialize the data locally via the Kafka Streams API. We define a query for the data in our grid: “select * from orders, payments, customers where…” and Kafka Streams executes it, stores it locally, keeps it up to date. This ensures highly available should the worst happen and your service fails unexpectedly (this approach is discussed in more detail here).
To combat the challenges of being stateful, Kafka ships with a range of features to make the storage, movement, and retention of state practical: notably standby replicas and disk checkpoints to mitigate the need for complete rebuilds, and compacted topics to reduce the size of datasets that need to be moved.
So instead of pushing the data problem down a layer, stream processors are proudly stateful. They let data be physically materialized wherever it is needed, throughout the ecosystem. This increases performance. It also increases autonomy. No remote calls are needed!
Of course, being stateful is always optional, and you’ll find that many services you build don’t require state. In the ecosystem we develop as part of this post; two are stateless and two are stateful, but the important point is that regardless of whether your services need local state or not, a streaming platform provisions for both. Finally, it’s also possible to control a stream processor running in a separate process using KSQL. This creates a hybrid pattern where your application logic can be kept stateless, separated from your stream processing layer, in much the same way that you might separate state from business logic using a traditional database.
Coordination-Free by Design
One important implication of pushing data into many different services is we can’t manage consistency in the same way. We will have many copies of the same data embedded in different services which, if they were writable, could lead to collisions and inconsistency.
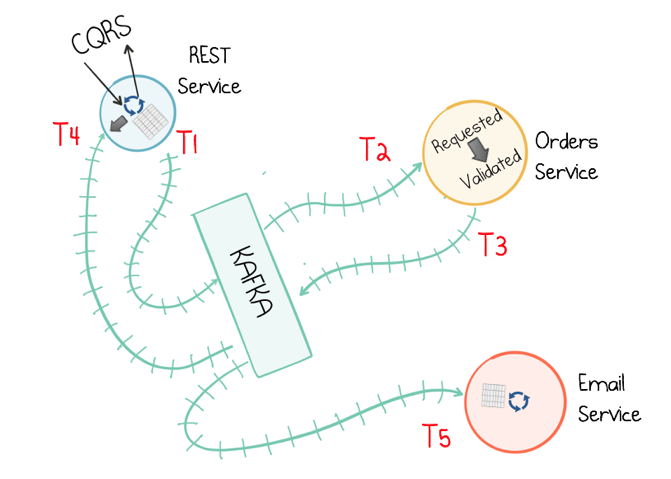
As this notion of ‘eventual consistency’ is often undesirable in business applications, one solution is to isolate consistency concerns (i.e. write operations) via the single writer principle. For example, the Orders Service would own how an Order evolves in time. Each downstream service then subscribes to the strongly ordered stream of events produced by this service, which they observe from their own temporal viewpoint.
This adds an important degree of ‘slack’ into the system, decoupling services from one another in time and making it easier for them to scale and evolve independently. We will walk through an example of how this works in practice later in the post (the Inventory Service), but first, we need to look at the mechanics and tooling used to sew these ecosystems together.
Using Kafka Streams & KSQL to Build a Simple Email Service
Kafka Streams is the core API for stream processing on the JVM: Java, Scala, Clojure, etc. It is based on a DSL (Domain Specific Language) that provides a declaratively-styled interface where streams can be joined, filtered, grouped or aggregated (i.e. summarized) using the DSL. It also provides functionally-styled mechanisms — map, flatMap, transform, peek, etc.—so you can add bespoke processing of your own, one message one at a time. Importantly you can blend these two approaches together, with the declarative interface providing a high-level abstraction for SQL-like operations and the more functional methods adding the freedom to branch out into any arbitrary code you may wish to write.
But what if you’re not running on the JVM, or you want to do stateful stream processing in a separate process (say, to keep your application logic stateless)? In this case, you’d use KSQL. KSQL provides a simple, interactive SQL interface for stream processing and can be run standalone and controlled remotely. KSQL utilizes the Kafka Streams API under the hood, meaning we can use it to do the same kind of declarative slicing and dicing we might do in JVM code using the Streams API. Then a native Kafka client, in whatever language our service is built in, can process the manipulated streams one message at a time. Whichever approach we take, these tools let us model business operations in an asynchronous, non-blocking, and coordination-free manner.
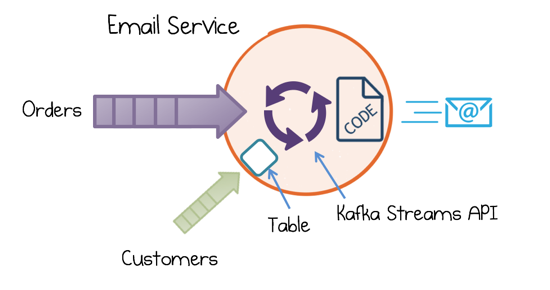
Let’s consider something concrete. Imagine we have a service that sends emails to platinum-level clients (this fits into the ecosystem at the top of the above system diagram). We can break this problem into two parts: firstly we prepare the data we need by joining a stream of Orders to a table of Customers and filtering for the ‘Platinum’ clients. Secondly, we need code to construct and send the email itself. We would do the former in the DSL and the latter with a per-message function:
//Filter input stream then send Email orders.join(customers, Tuple::new) //join customers and orders .filter((k, tuple) → tuple.customer.level().equals(PLATINUM) //filter platinum customers && tuple.order.state().equals(CONFIRMED)) //only consider confirmed orders .peek((k, tuple) → emailer.sendMail(tuple)); //send email for each cust/order tuple
A more fully-fledged Email service can be found in the microservice code examples. We also extend this Transform/Process pattern later in the Inventory Service example discussed later in this post.
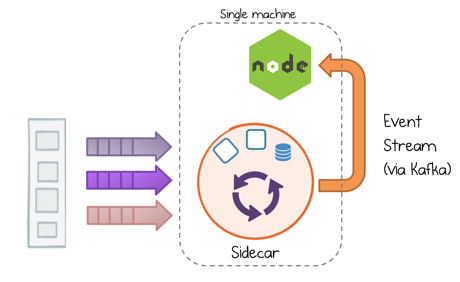
An equivalent operation can be performed, off the JVM, using KSQL. The pattern is the same: the event stream is dissected with a declarative statement, then processed one record at a time. Here we implement the emailer in Node.js with KSQL running via the Sidecar Pattern:
//Execute query in KSQL sidecar to filter stream ksql> CREATE STREAM orders (ORDERID string, ORDERTIME bigint...) WITH (kafka_topic='orders', value_format='JSON'); ksql> CREATE STREAM platinum_emails as select * from orders, customers where client_level == ‘PLATINUM’ and state == ‘CONFIRMED’;
//In Node.js service send Email var nodemailer = require('nodemailer'); … var kafka = require('kafka-node'), Consumer = kafka.Consumer, client = new kafka.Client(), consumer = new Consumer(client, [ { topic: 'platinum_emails', partition: 0 } ] );
consumer.on('message', function (orderConsumerTuple) { sendMail(orderConsumerTuple); });
The Tools of the Trade: Windows, Tables & State Stores
Before we develop more complex microservice example let’s take a look more closely at some of the key elements of the Kafka Streams API. Kafka Streams needs its own local storage for a few different reasons. The most obvious is for buffering, as unlike in a traditional database—which keeps all historical data on hand—stream operations only need to collect events for some period of time. One that corresponds to how ‘late’ related messages may be with respect to one another.
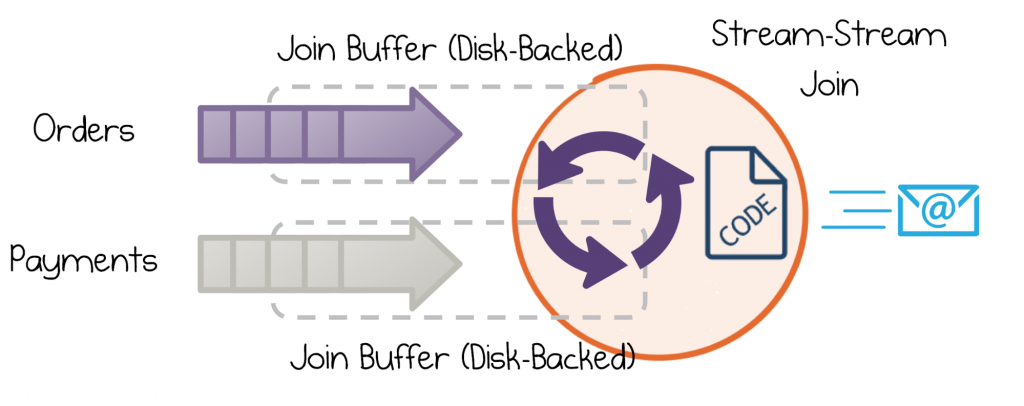
Let’s use a few variants on the email example. Imagine you want to send an email that confirms payment of a new order. We know that an Order and its corresponding Payment will turn up at around the same time, but we don’t know for sure which will come first or exactly how far apart they may be. We can put an upper limit on this though—let’s say an hour to be safe.
To avoid doing all of this buffering in memory, Kafka Streams implements disk-backed State Stores to overflow the buffered streams to disk (think of this as a disk-resident hashtable). So each stream is buffered in this State Store, keyed by its message key. Thus, regardless of how late a particular event may be, the corresponding event can be quickly retrieved.
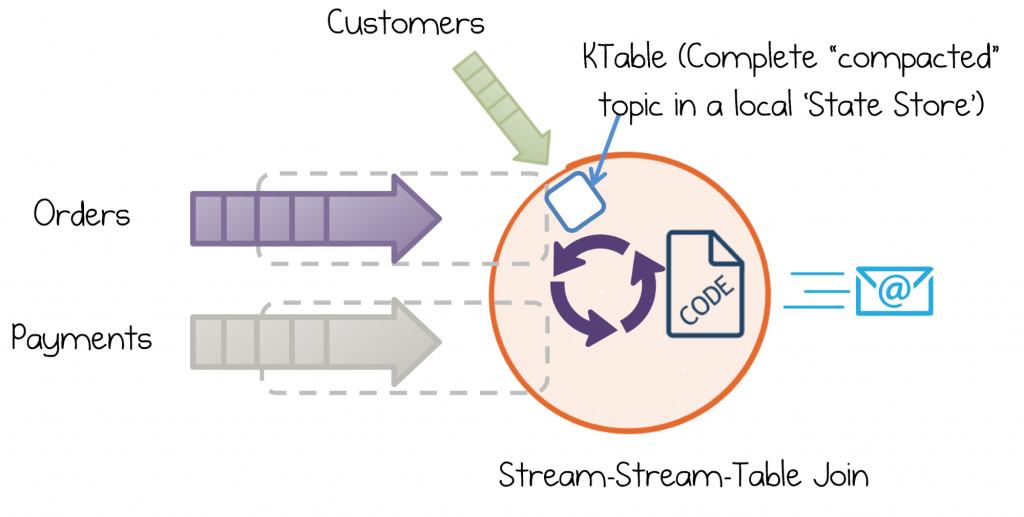
Kafka Streams takes this same concept a step further to manage whole tables. Tables are a local manifestation of a complete topic—usually compacted—held in a state store by key. (You can also think of them as a stream with infinite retention.) In a microservices context, such tables are often used for enrichment. Say we decide to include Customer information in our Email logic. We can’t easily use a stream-stream join as there is no specific correlation between a user creating an Order and a user updating their Customer Information—that’s to say that there is no logical upper limit on how far apart these events may be. So this style of operation requires a table: the whole stream of Customers, from offset 0, replayed into the State Store inside the Kafka Streams API.
The nice thing about using a KTable is it behaves like a table in a database. So when we join a stream of Orders to a KTable of Customers, there is no need to worry about retention periods, windows or any other such complexity. If the customer record exists, the join will just work.
There are actually two types of table in Kafka Streams: KTables and Global KTables. With just one instance of a service running, these effectively behave the same. However, if we scaled our service out—so it had, say, four instances running in parallel—we’d see slightly different behavior. This is because Global KTables are cloned: each service instance gets a complete copy of the entire table. Regular KTables are sharded: the dataset is spread over all service instances. So in short, Global KTables are easier to use, but they have scalability limits as they are cloned across machines, so use them for lookup tables (typically up to several gigabytes) that will fit easily on a machine’s local disk. Use KTables, and scale your services out, when the dataset is larger.
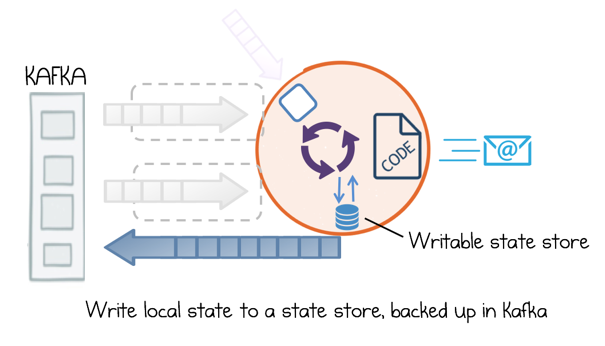
The final use of the State Store is to save information, just like we might write data to a regular database. This means we can save any information we wish and read it back again later, say after a restart. So we might expose an Admin interface to our Email Service which provides stats on emails that have been sent. We could store these stats in a state store and they’ll be saved locally, as well as being backed up to Kafka, inheriting all its durability guarantees.
Scalable, Consistent, Stateful Operations in the Inventory Service
Now we have a basic understanding of the tools used in stream processing, let’s look at how we can sew them together to solve a more complex and realistic use case—one which requires that reads and writes are performed consistently, at scale.
In the system design diagram, there is an Inventory Service. When a user makes a purchase—let’s say it’s an iPad—the Inventory Service makes sure there are enough iPads in stock for the order to be fulfilled. To do this a few things need to happen as a single atomic unit. The service needs to check how many iPads there are in the warehouse. Next, one of those iPads must be reserved until such time as the user completes their payment, the iPad ships, etc. This requires four actions to be performed inside each service instance as a single, atomic transaction:
- Read an Order message
- Validate whether there is enough stock available for that Order: (iPads in the warehouse KTable) – (iPads reserved in the State Store).
- Update the State Store of “reserved items” to reserve the iPad so no one else can take it.
- Send out a message that Validates the order.
You can find the code for this service here.
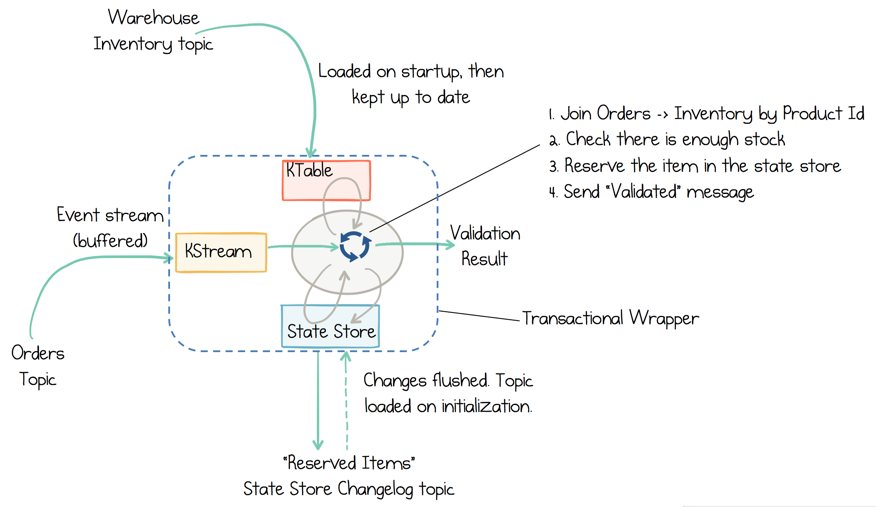
What is neat about this approach is its ability to scale these atomic operations out across many threads or machines. There is no remote locking, there are no remote reads. This works reliably because the code ensures two things:
- Kafka’s transactions feature is enabled.
- Data is partitioned by ProductId before the reservation operation is performed.
The first point should be obvious. Kafka’s transactions ensure atomicity. Partitioning by ProductId is a little more subtle. Partitioning ensures that all orders for iPads are sent to a single thread in one of the available service instances, guaranteeing in order execution. Orders for other products will be sent elsewhere. So in a distributed deployment, this guarantees in-order execution for orders for the same type of product, iPads, iPhones, etc., without the need for cross-network coordination. (For more detail see the section “Scaling Concurrent Operations in Streaming Systems” in the book Designing Event-Driven Systems.)
Bridging the Synchronous and Asynchronous Worlds
Finally, we can put all these ideas together in a more comprehensive ecosystem that validates and processes orders in response to an HTTP request, mapping the synchronous world of a standard REST interface to the asynchronous world of events, and back again.
Looking at the Orders Service first, a REST interface provides methods to POST and GET Orders. Posting an Order creates an event in Kafka. This is picked up by three different validation engines (Fraud Check, Inventory Check, Order Details Check) which validate the order in parallel, emitting a PASS or FAIL based on whether each validation succeeds. The result of each validation is pushed through a separate topic, Order Validations, so that we retain the ‘single writer’ status of the Orders Service —> Orders Topic. The results of the various validation checks are aggregated back in the Order Service (Validation Aggregator) which then moves the order to a Validated or Failed state, based on the combined result. This is essentially an implementation of the Scatter-Gather design pattern.
To allow users to GET any order, the Orders Service creates a queryable materialized view (‘Orders View’ in the figure), using a state store in each instance of the service, so any Order can be requested historically. Note also that the Orders Service is partitioned over three nodes, so GET requests must be routed to the correct node to get a certain key. This is handled automatically using the Interactive Queries functionality in Kafka Streams, although the example has to implement code to expose the HTTP endpoint. (Alternatively, we could also implement this view with an external database, via Kafka Connect.)
The example also includes code for a blocking HTTP GET so that clients have the option of reading their own writes (i.e. avoiding the race conditions that come with eventual consistency). In this way we bridge the synchronous, blocking paradigm of a Restful interface with the asynchronous, non-blocking processing performed server-side:
# Submit an order. Immediately retrieving it will block until validation completes.
$ curl -X POST ... --data {"id":"1"...} http://server:8081/orders/
$ curl -X GET http://server:8081/orders/validated/1?timeout=500
Finally, there are two other interesting services in the example code. The Fraud Service tracks the total value of orders for each customer in a one-hour window, alerting if the configured fraud limit is exceeded. This is implemented entirely using the Kafka Streams DSL, although it could be implemented in custom code via a Transformer also. The Order Details Service validates the basic elements of the order itself. This is implemented with a producer/consumer pair, but could equally be implemented using Kafka Streams.
When to Apply Architectures of this Type
This example is about as fine-grained as streaming services get, but it is useful for demonstrating the event-driven approach and how that is interfaced into the more familiar synchronous request-response paradigm via event collaboration. (We discussed the merits of event collaboration in an earlier post.)
But we should look at any architectural change with a critical eye. If we’re building systems for the synchronous world, where users click buttons and wait for things to happen, there may be no reason to change. The architecture described here is more complex than many simple CRUD systems. That’s to say the baseline cost is higher, both in complexity and in latency. This tradeoff is worth making if the system we are building needs to grow and evolve significantly in the future. Notably, incorporating different teams, as well as offline services that do not require a response go immediately back to the user: re-pricing, fulfillment, shipping, billing, notifications, etc. In these larger, distributed ecosystems, the pluggability, extensibility, and decoupling that comes with the event-driven, brokered approach increasingly pay dividends as the ecosystem grows.
So the beauty of implementing services on an Event Streaming Platform lies in its ability to handle both the micro and the macro with a single, ubiquitous workflow. Here, fine-grained use cases merge into larger architectures that span departments, companies, and geographies.
Summing Up
When we build services using a Streaming Platform, some will be stateless: simple functions that take an input, perform a business operation and produce an output. Some will be stateful, but read-only, as in when views need to be created so we can serve remote queries. Others will need to both read and write state, either entirely inside the Kafka ecosystem (and hence wrapped in Kafka’s transactional guarantees), or by calling out to other services or databases. Having all approaches available makes the Kafka’s Streams API a powerful tool for building event-driven services.
But there are of course drawbacks to this approach. Whilst standby replicas, checkpoints, and compacted topics all mitigate the risks of pushing data to code, there is always a worst-case scenario where service-resident datasets must be rebuilt, and this should be considered as part of any system design. There is also a mindset shift that comes with the streaming model, one that is inherently asynchronous and adopts a more functional style, when compared to the more procedural style of service interfaces. But this is—in the opinion of this author—an investment worth making.
So hopefully the example described in this post is enough to introduce you to what event streaming microservices are about. We looked at how a small ecosystem can be built through the propagation of business events that describe the order management workflow. We saw how such services can be built on the JVM with Kafka’s Streams API, as well as off the JVM via KSQL. We also looked more closely at how to tackle trickier issues like consistency with writable state stores and change logs. Finally, we saw how simple functions, which are side-effect-free, can be composed into service ecosystems that operate as one. In the next post in this series, Bobby Calderwood will be taking this idea a step further as he makes a case for a more functional approach to microservices through some of the work done at Capital One.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled
Part 8: Toward a Functional Programming Analogy for Microservices (by Bobby Calderwood)
Interested in More?
If you have enjoyed this series, you might want to continue with the following resources to learn more about stream processing on Apache Kafka®:
- Learn about ksqlDB, the successor to KSQL
- Get started with the Kafka Streams API to build your own real-time applications and microservices
- Join us for our three-part online talk series for the ins and outs behind how KSQL works, and learn how to use it effectively to perform monitoring, security and anomaly detection, online data integration, application development, streaming ETL and more
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications
- Check out the Apache Kafka for Microservices: A Confluent Online Talk Series
- Read the Microservices for Apache Kafka white paper
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.