New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
The Data Dichotomy: Rethinking the Way We Treat Data and Services
If you were to stumble upon the whole microservices thing, without any prior context, you’d be forgiven for thinking it a little strange. Taking an application and splitting it into fragments, separated by a network, inevitably means injecting the complex failure modes of a distributed system.
Yet, whilst the approach certainly involves many independent services, the goal is a little broader than simply running them across different machines. It’s about facing up to a world that is, itself, inherently distributed. Not in some narrow technical sense, but rather as a broad ecosystem composed from many people, many teams and many programs, all of which need to do their own thing to some degree or other.
Companies for example are collections of disparate systems which, collectively, further some common aim. For decades we have largely ignored this fact, patching them together with FTP file transfers or enterprise integration tools, whilst concentrating on our own somewhat isolationist goals. But services change this. They force our heads up above the parapet, into a world of collaborative, inter-dependent programs. But to be successful at this we must recognize, and design for, two fundamentally different worlds: The external world, where we live in an ecosystem of many other services, and our private, internal world, where we alone reign king.
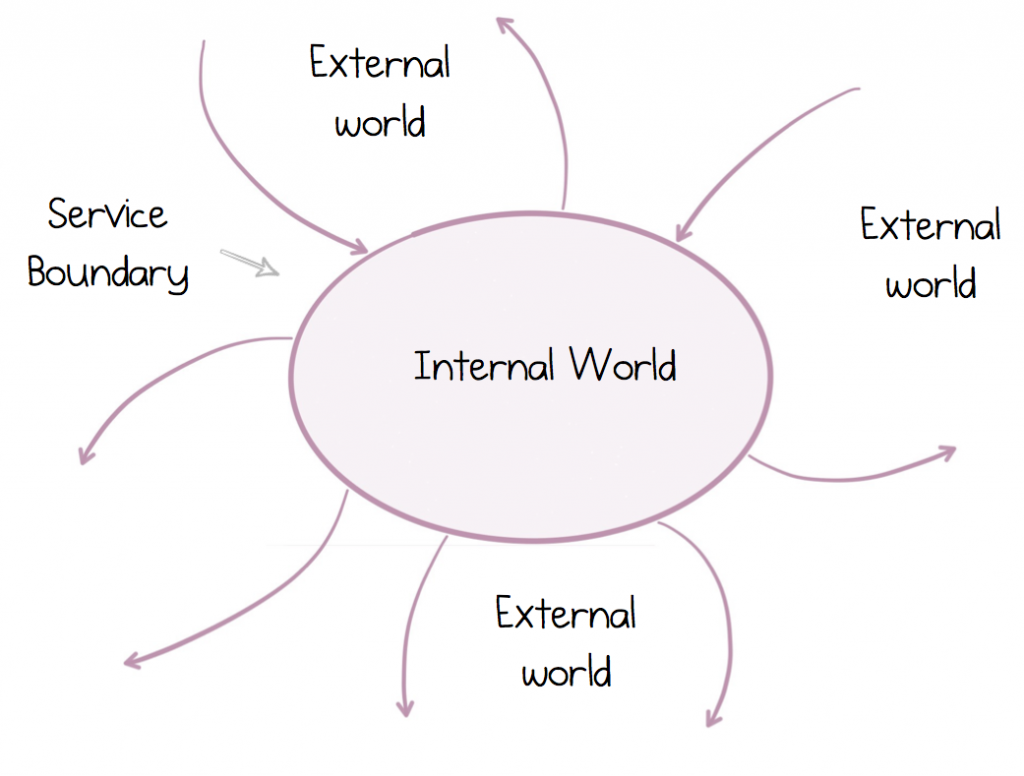
But this distributed world is a little different to the one we grew up in. The rules of traditional, monolithic software engineering no longer hold water in the same way. So getting such systems right is more than putting together a cool sketch on a whiteboard or a sexy proof of concept. It’s about making these things work successfully over time. Fortunately, services have been around for a long time, albeit in a few different guises. The lessons from SOA still hold, despite the recent sprinkling of Docker, Kubernetes and some slightly over-coiffed hipster beards.
So today we’re going to look at how the rules have changed, why we should rethink our approach to services and the data they share, and why we need a different toolset to do this.
Encapsulation Isn’t Always Your Friend
Microservices are independently deployable. It is this attribute, more than any other, that give them their value. It allows them to scale. To grow. Not so much in the sense of scaling to quadrillions of users or petabytes of data (although they may help with that), but rather scaling in people terms, as your teams and organization grow.
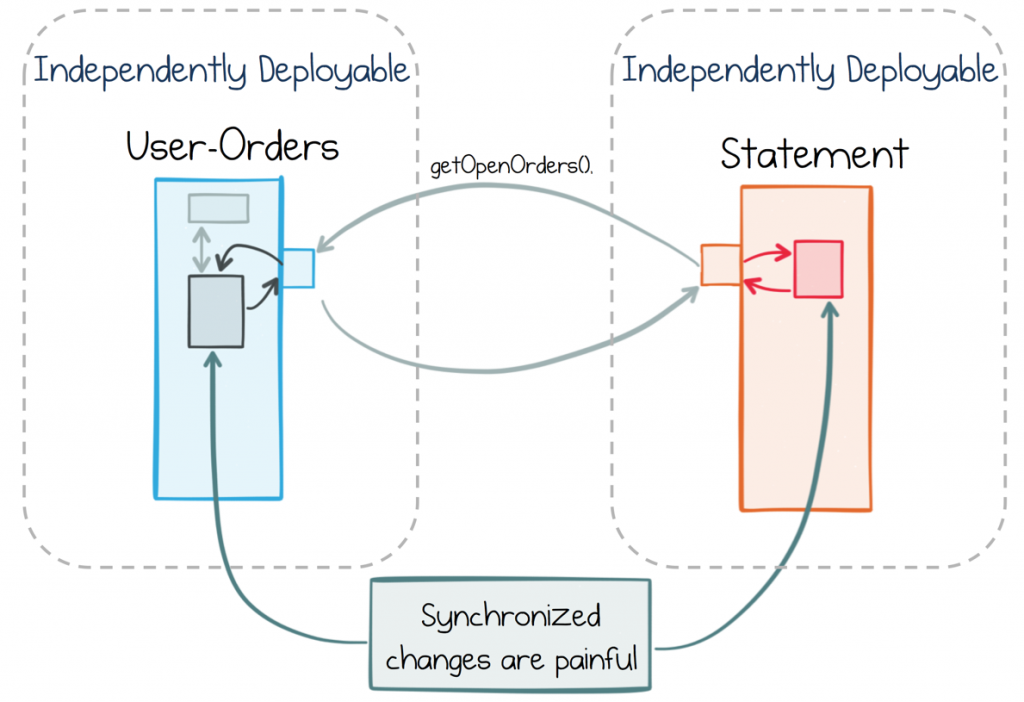
But independence itself is a double edged sword. It means a service can iterate quickly and freely. But if one service implements a feature which requires another service to change, we end up having to make changes to both services at around the same time. Whilst this is easy in a monolithic application, where you can simply make the change and do a release, it’s considerably more painful where independent services must synchronize. The coordination between teams and release cycles erodes agility.
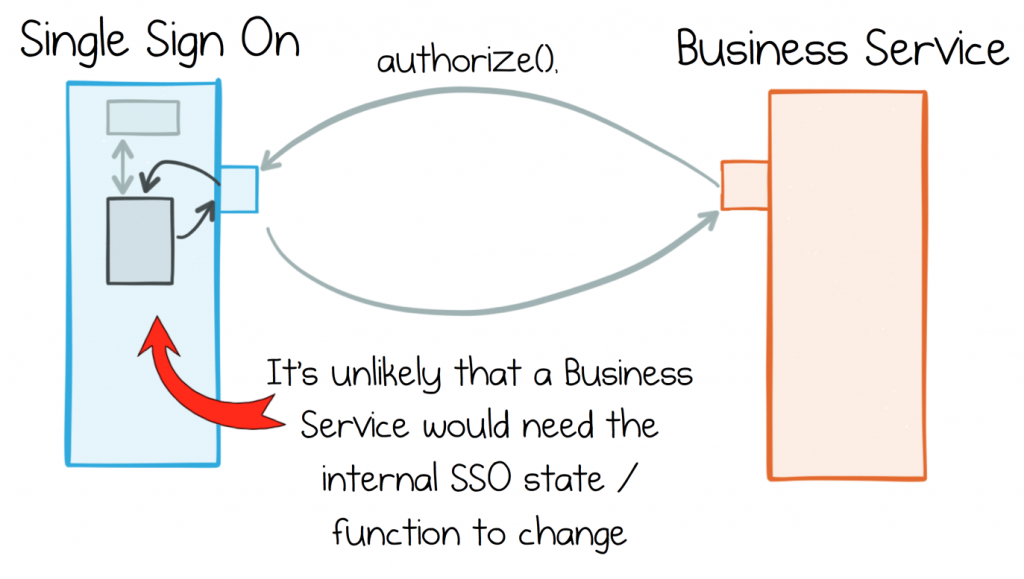
The typical approach is to simply avoid such pesky, crosscutting changes by cleanly separating responsibilities between services. A Single Sign-On service is a good example. It has a well-defined role which can be cleanly separated from the roles other services play. This clean separation means that, even in the face of rapid requirement churn in surrounding services, it’s unlikely the SSO service will need to change. It exists in a tightly bounded context.
The problem is that, in the real world, business services can’t typically retain the same, clean, separation of concerns. For example, business services inevitably rely more heavily on one another’s data. If you’re an online retailer, the stream of Orders, the Product Catalog or Customer Information will likely find it’s way into the requirements of many of your services. Each of these services needing broad access to these datasets to do their work.
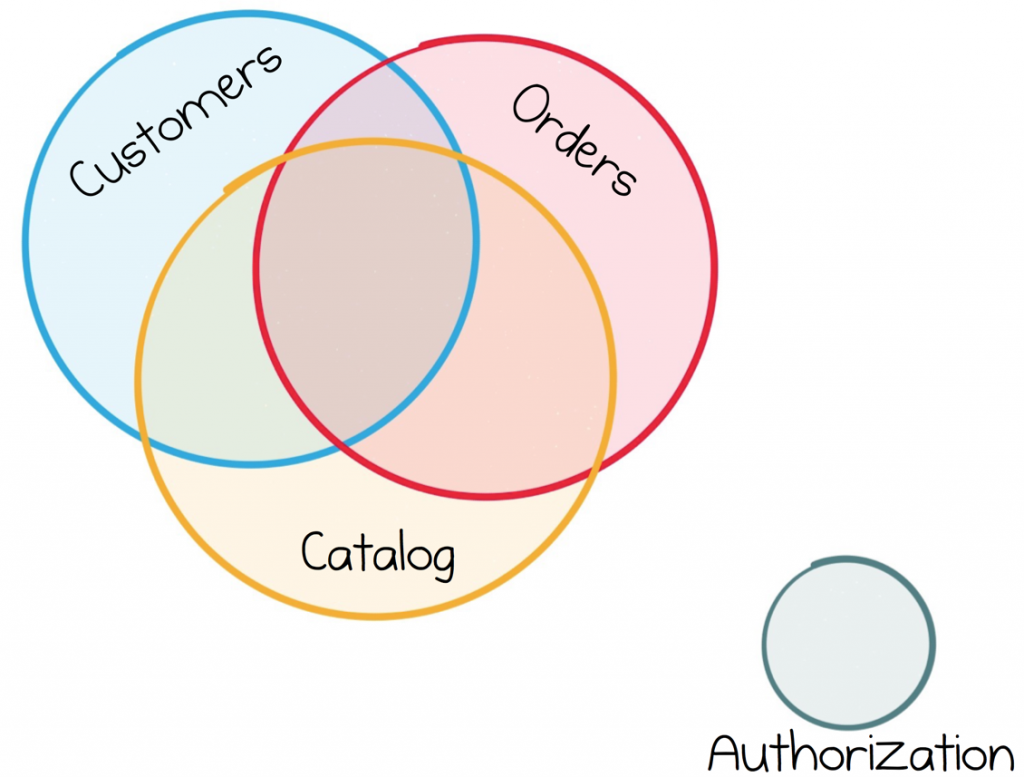
Most business services share the same stream of facts. This makes their futures inevitably intertwined.
So this is an important point to note, whilst services work well for infrastructure components, which have the luxury of living largely in isolation, the futures of most business services are far more tightly intertwined.
The Data Dichotomy
Service-based approaches may have been around for a while, but they still offer relatively little insight into how to share significant datasets between services.
The underlying issue is that data and services don’t sing too sweetly together. On one side, encapsulation encourages us to hide data; decoupling services from one another so they can continue to change and grow. This is about planning for the future. But on the other side, we need the freedom to slice and dice shared data like any other dataset. This is about getting on with our job right now, with the same freedoms as any other data system.
But data systems have little to do with encapsulation. In fact, quite the contrary. Databases do everything they can to expose the data they hold. They come with a wonderfully powerful, declarative interface that can contort data into pretty much any shape you might desire. Exactly what you need for exploratory investigation, but not so great for managing the onset of complexity in a burgeoning service estate.
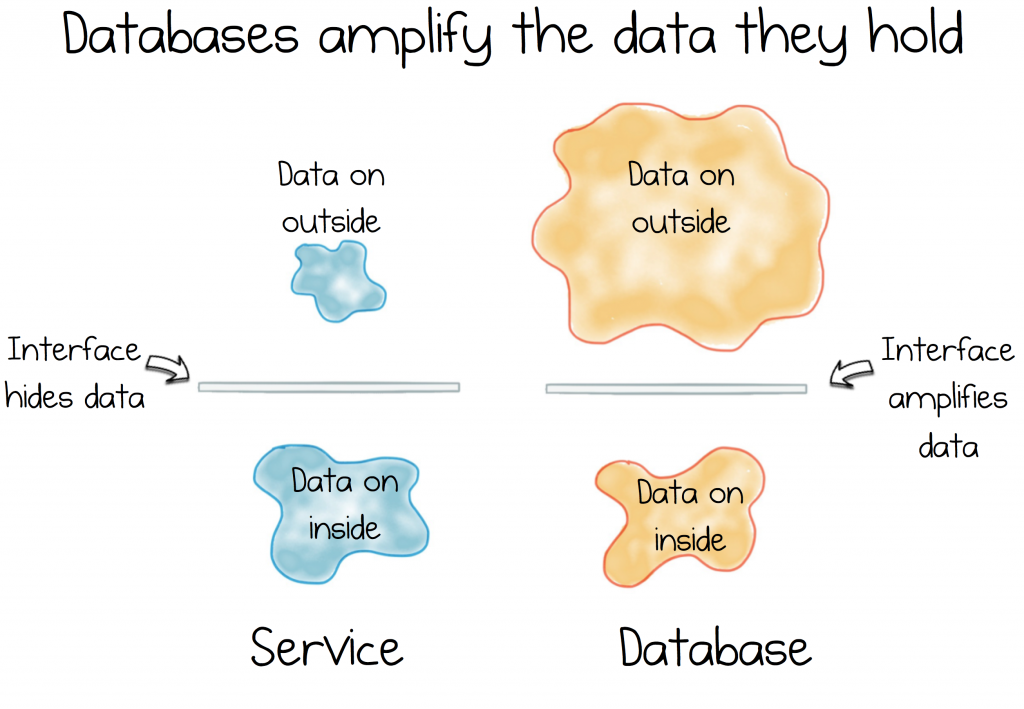
So we find ourselves faced with a conundrum. A contradiction. A dichotomy: Data systems are about exposing data. Services are about hiding it.

These two forces are fundamental. They underlie much of what we do, subtly jostling for supremacy in the systems we build.
As we evolve and grow service-based systems, we see the effects of this Data Dichotomy play out in a couple of different ways. Either a service interface will grow, exposing an increasing set of functions, to the point it starts to look like some form of kookie, homegrown database. Alternatively, frustration will kick in and we add some way of extracting and moving whole datasets, en masse, from service to service.
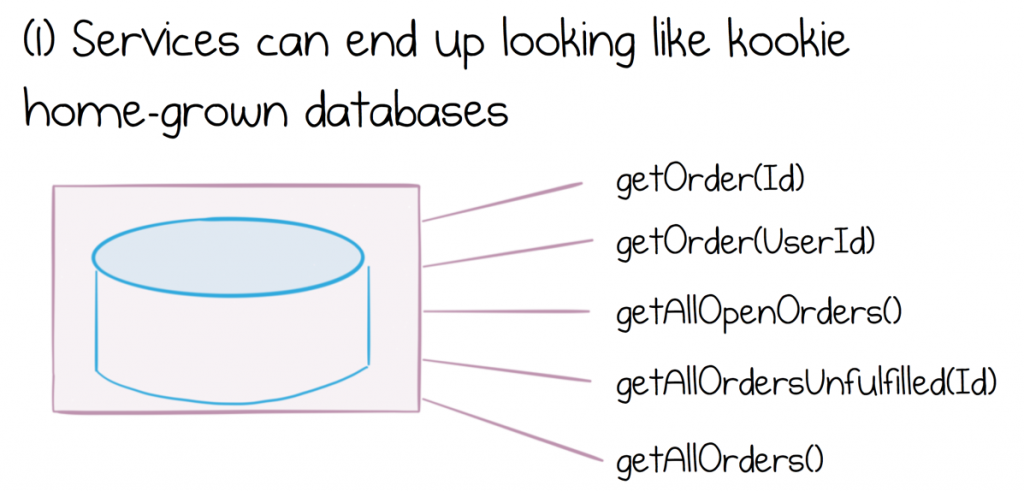
Now creating something that looks like a kookie, shared database can lead to a set of issues of its own. We won’t go into the perils of shared databases here, but suffice to say they represent significant and expensive engineering and operational challenges for companies that attempt them.
To make matters somewhat worse, data volume actually amplifies this service boundary problem. The more shared data is hidden inside a service boundary, the more complex the interface will likely become, and the harder it will be to join datasets across different services.

Yet the alternative – extracting and moving whole datasets – has problems too. A common approach to this is to simply extract and hold the whole dataset and then store it in a local database inside each consuming service.
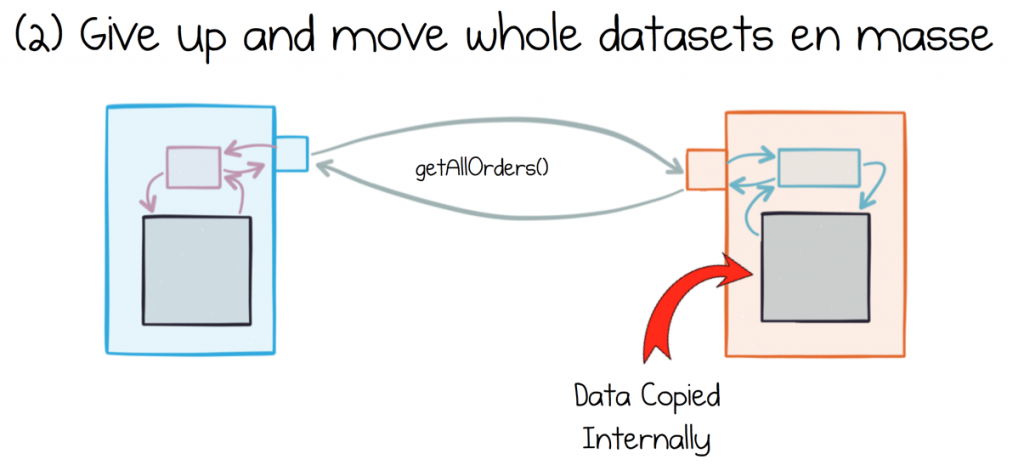
The problem is that different services make different interpretations of the data they consume. They keep that data around. Data is altered and fixed locally. Pretty soon it doesn’t represent the source dataset much at all.
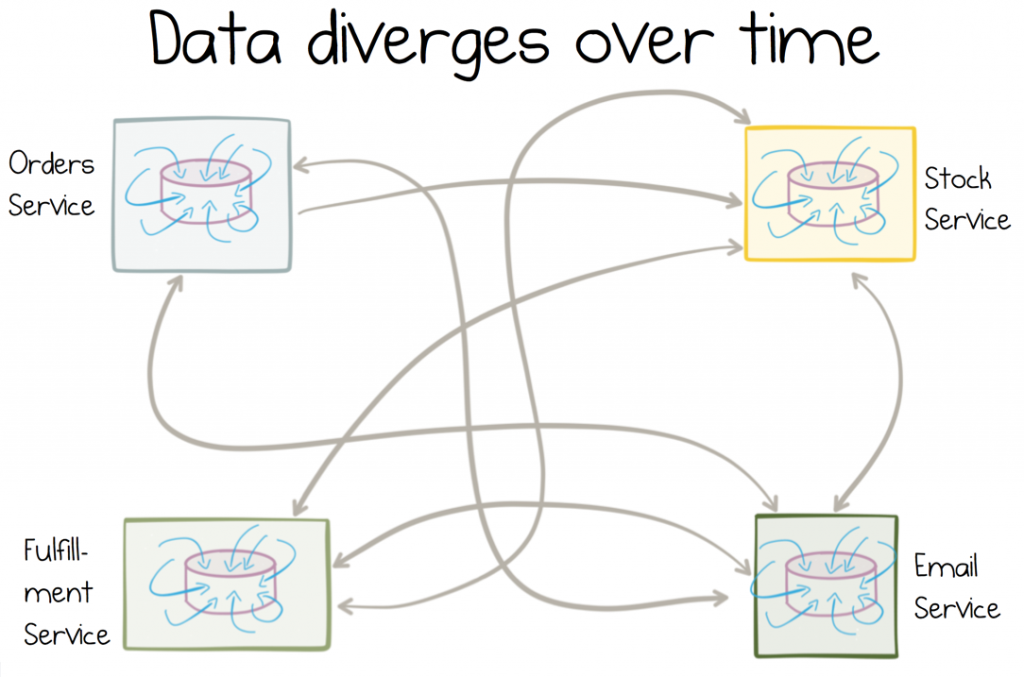
The more mutable copies, the more data will diverge over time.
Making matters worse, divergent data is very hard to fix in retrospect (MDM is really a sticky-plaster over this). In fact some of the most intractable technology problems that businesses encounter arise from divergent datasets proliferating from application to application.
To address this we need to think about shared data in a slightly different way. We need to consider it a first class citizen of the architectures we build. Pat Helland calls this data-on-the-outside, and this is a useful distinction to make. We need encapsulation so we don’t expose a service’s internal state. But we need to make it easy for services to get access to shared data so they can get on and do their jobs.
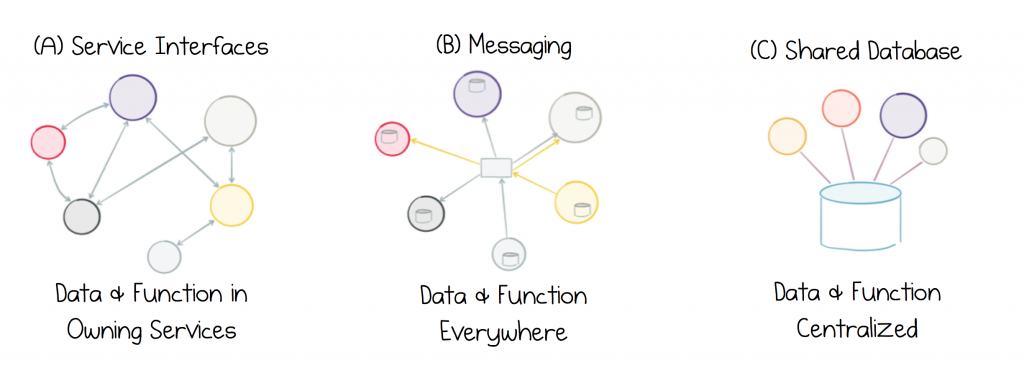
The problem is that none of the approaches available today, Service Interfaces, Messaging or a Shared Database, provide a good solution for dealing with data-on-the-outside. Service interfaces are poorly suited to sharing data at any level of scale. Messaging moves data, but provides no historical reference, and this leads to data corruption over time. Shared databases concentrate too much in one place, stifling progress. Hence we inevitably get stuck in a cycle of data Inadequacy:
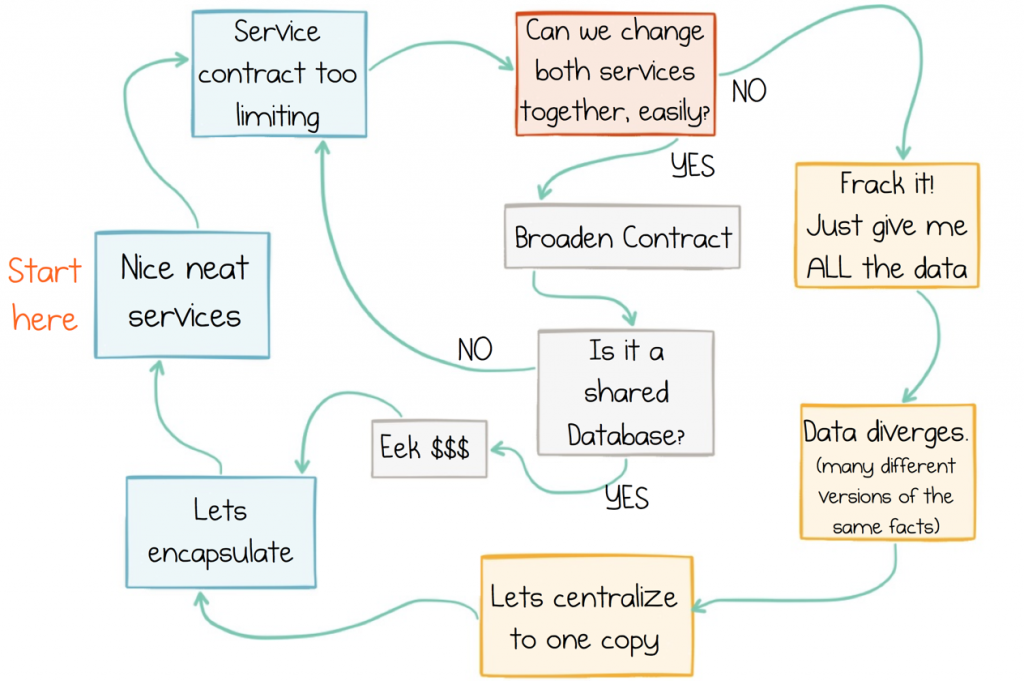
The Cycle of Data Inadequacy
Streams: A Decentralized Approach to Data and Services
So, ideally, we’d like to rejig the way services approach shared data. Now any such approach has to face up to the aforementioned dichotomy, there is no technical fairy dust we can sprinkle on liberally and magic it away. But we can reframe the problem, and pick a subtly different compromise.
This particular compromise involves a degree of centralization. We can use a Distributed Log for this as it provides retentive, scalable streams. Now we need our services to be able to join and operate on these shared streams, but we want to avoid complicated, centralized ‘God Services’ that do this type of processing. So a better approach is to embed stream processing into each consuming service. That means services can join together various shared datasets and iterate on them at their own pace.
One way to achieve this is to use a Streaming Platform. There are a number of options available, but here we’ll consider Kafka, as it’s use of Stateful Stream Processing makes it particularly well suited to this problem.
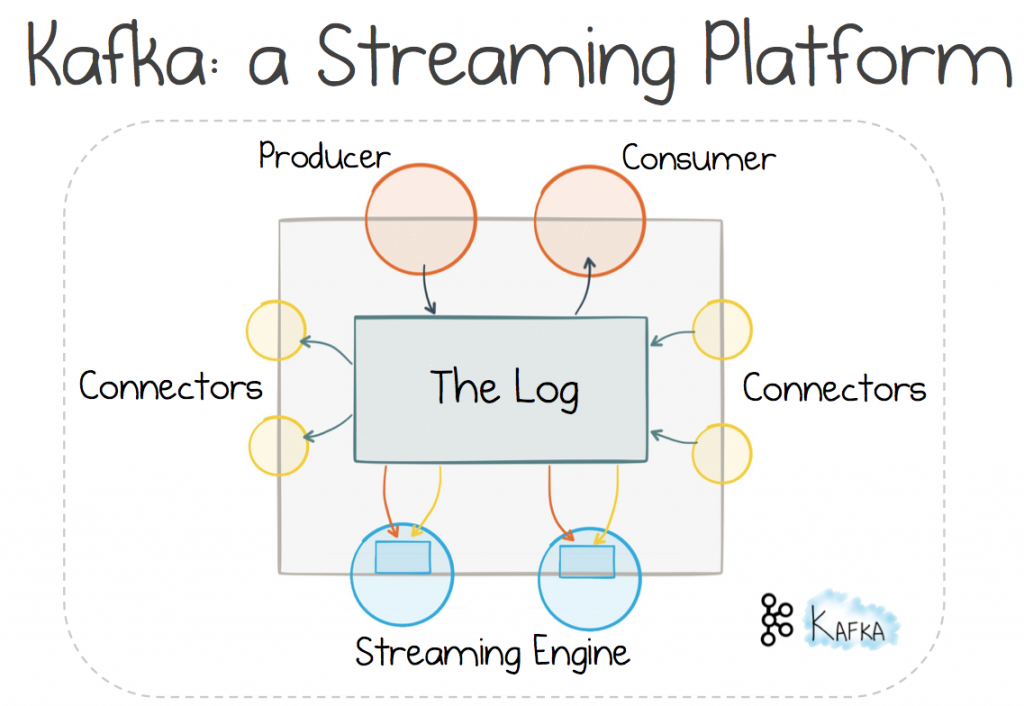
Using a distributed log pushes us down a fairly well-trodden path, one which uses messaging to make services Event Driven. Such approaches are generally considered to provide better scalability and better decoupling than their Request-Response brethren, as they move flow control from the sender to the receiver. This increases the autonomy of each service. In fairness it comes at a cost: you need a broker. But for significant systems, this is often a tradeoff worth making (less so for your average web app)
Now if the broker is a distributed log, rather than a traditional messaging system, a few additional properties can be leveraged. The transport can be scaled out linearly in much the same way as a distributed file system. Data can also be retained in the log, long term. So it’s messaging, but it’s also storage. Storage that scales, and without the perils of shared, mutable state.
Then a stateful stream processing engine can be used to embed the declarative tools of a database right inside the consuming services. This point is important. Whilst data is stored in shared streams, which all services might access, the joins and processing a service does, is private. The smarts are isolated inside each bounded context.
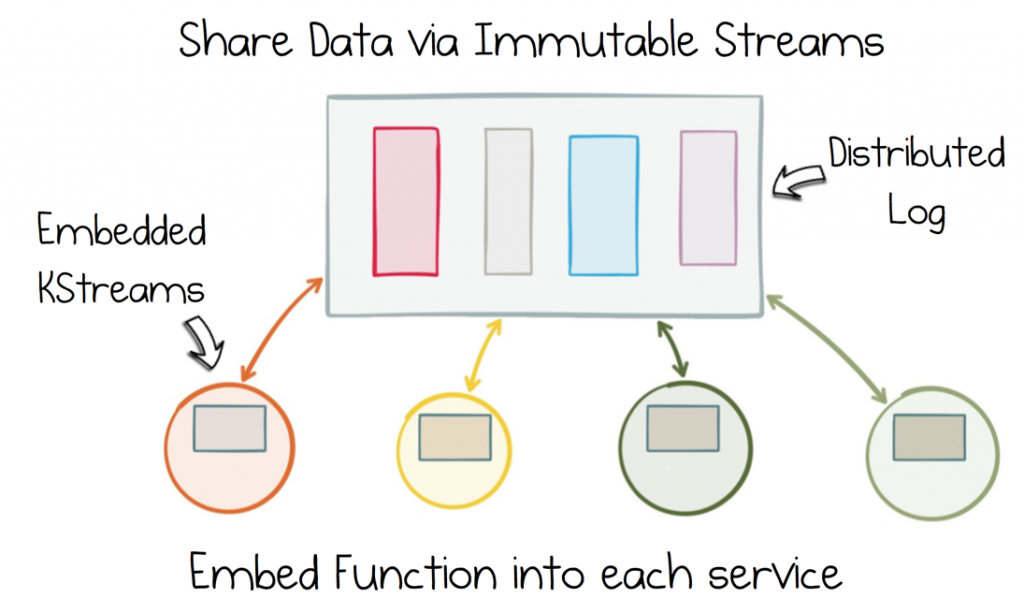
Address the data dichotomy by sharing an immutable stream of state. Then push the function into each service with a Stateful Stream Processing Engine.
So if your service needs to operate on the company’s Orders, Product Catalogue or Inventory, it has full access: you decide which datasets should be combined, you decide where it executes and you decide when and how to evolve it over time. This means that, whilst data itself is shared, operation on that shared data is fully decentralized. It sits entirely inside each service boundary, in a world where you alone reign king.
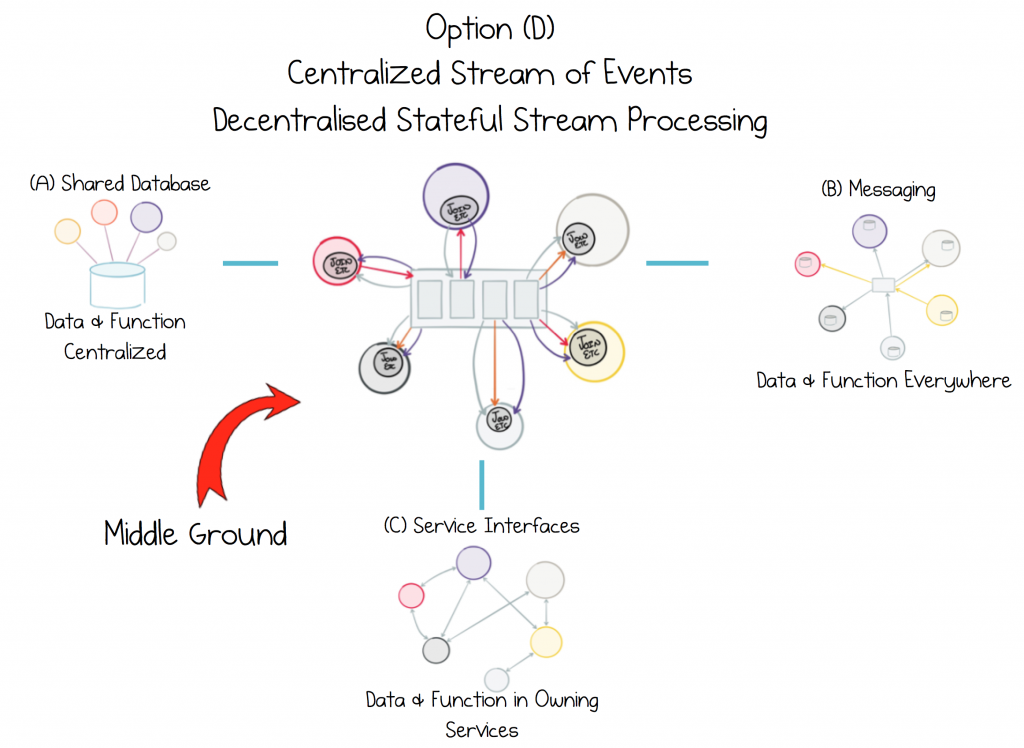
Share data in a way that keeps it true to source. Encapsulate function, not at source, but in each service that needs it.
Now it turns out that sometimes data must be moved, en masse. Sometimes a service needs a local, historic dataset in a database engine of their choice. The trick here is to ensure that the copy can be regenerated from source at will, by going back to the Distributed Log. Connectors in Kafka help with this.

So there are a few specific advantages to this approach:
- Data is shared as streams, which can reside in the log long term, but the mechanism for manipulating that shared data is embedded into each bounded context, making it easy to iterate quickly and freely. This balances the data dichotomy.
- Datasets can easily be joined across different services on the fly. This makes it easier to interact with shared data, avoiding the need to maintain local datasets in a database.
- Stateful Stream Processing only caches data, the “golden source” is the shared log, so the problems of data diverging over time are far less prevalent.
- Services are event driven in essence, this means that, as datasets grow, services can still react quickly to business events.
- Scalability concerns move from services to the broker. This makes it much easier to build simpler services that don’t need to worry about scale.
- Adding new services doesn’t require upstream services to change. This makes it easier to plug new services in.
So this is more than just REST. It’s a toolset that embraces shared data, in a decentralized way.

This post is really just a taster, glossing over many details. We still need to dig into how we balance request-response and event-driven paradigms. We’ll do this in the next post. There are subjects we need to better understand too, like why Stateful Stream Processing is so valuable. The third post will look at this. There are also some other powerful constructs we can take advantage of, if we choose this path, such as Exactly Once Processing. This is a game changer for distributed, business systems as it provides the transactional guarantees of XA in a scalable form. The fourth post will go into that. Finally, we need to run through the nitty gritty of implementing these things.
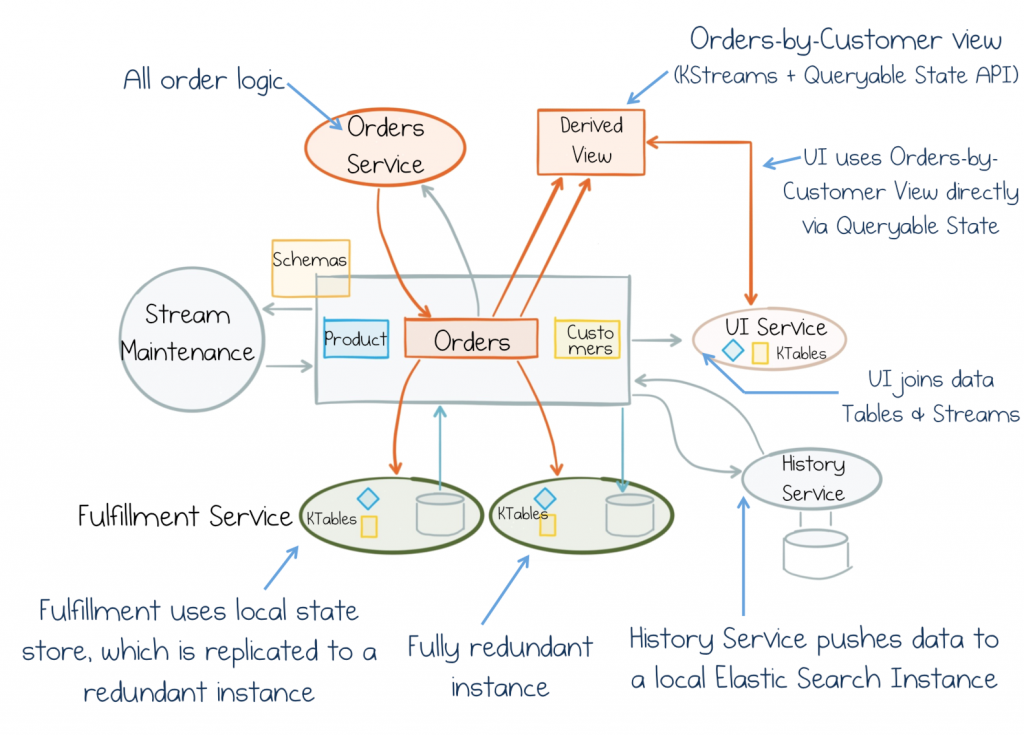
But for now, just remember this: The Data Dichotomy describes a tension we must all face when we build business services. We should be mindful of this fact. The trick is to switch things up: To consider shared data a first-class citizen. Something we design for. Stateful Stream Processing provides a unique compromise for this. It avoids the central “God Components” that typically stifle progress. But moreover, it brings the immediacy, scalability and fault tolerance of streaming data pipelines and embeds them right inside each service. So we focus on a holistic stream of consciousness which any service can dip into to make its decisions. This makes services more scalable, fungible and autonomous. So not only will they look good on whiteboards and in POCs, they’ll go on to survive and evolve for decades.
Thanks to Jay Kreps and Gwen Shapira for their help reviewing this post.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events (Read Next)
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
Did you like this blog post? Share it now
Subscribe to the Confluent blog





