New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Build Services on a Backbone of Events
For many, microservices are built on a protocol of requests and responses. REST etc. This approach is very natural. It is after all the way we write programs: we make calls to other code modules, await a response and continue. It also fits closely with a lot of use cases we see each day: front facing websites where users hit buttons and expect things to happen.
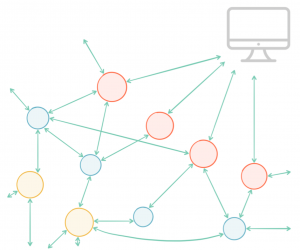 But when we step into a world of many independent services, things start to change. As the number of services grows gradually over time, the web of synchronous interactions grows with them. Previously benign availability issues start to trigger far more widespread outages.
But when we step into a world of many independent services, things start to change. As the number of services grows gradually over time, the web of synchronous interactions grows with them. Previously benign availability issues start to trigger far more widespread outages.
Our unfortunate Ops Engineers end up donning deerstalkers, as they play out distributed murder mysteries. Frantically running from service to service, piecing together snippets of second hand information (who said what, to whom, and when?).
This is a well known problem and there are a number of solutions. One is to ensure your individual services have significantly higher SLAs than your system. Google provide a protocol for doing this. The alternative is to simply break down the synchronous ties which bind services together.
 We can use asynchronicity as a mechanism for doing this. If you’re working in online retail you’ll find synchronous interfaces like getImage() or processOrder() feel natural. Calls which expect an immediate response. But when a user clicks ‘Buy’ they trigger a complex and asynchronous process. A process that takes a purchase and physically delivers it to the user’s door, way beyond the context of the original button-click. So splitting software into asynchronous flows allows us to compartmentalise the different problems we need to solve, as well as allowing us to embrace a world that is itself, inherently asynchronous.
We can use asynchronicity as a mechanism for doing this. If you’re working in online retail you’ll find synchronous interfaces like getImage() or processOrder() feel natural. Calls which expect an immediate response. But when a user clicks ‘Buy’ they trigger a complex and asynchronous process. A process that takes a purchase and physically delivers it to the user’s door, way beyond the context of the original button-click. So splitting software into asynchronous flows allows us to compartmentalise the different problems we need to solve, as well as allowing us to embrace a world that is itself, inherently asynchronous.
In practice we tend to embrace this automatically. We’ve all found ourselves polling database tables for changes, or implementing some kind of scheduled cron job to churn through updates. These are simple ways to break the ties of synchronicity, but they always feel like a bit of a hack. There is a good reason for this. They probably are.
So we can condense all these issues into a single observation. The imperative programming model, where we command services to do our bidding, isn’t a great fit for estates where services are operated independently.
In this post we’re going to look at the other side of the architecture coin: composing services not through chains of commands, but rather through streams of events. This is a valid approach in its own right. It also forms a baseline for the more advanced patterns we’ll be discussing later in this series, where we blend the ideas of event-driven processing with those seen in Streaming Platforms.
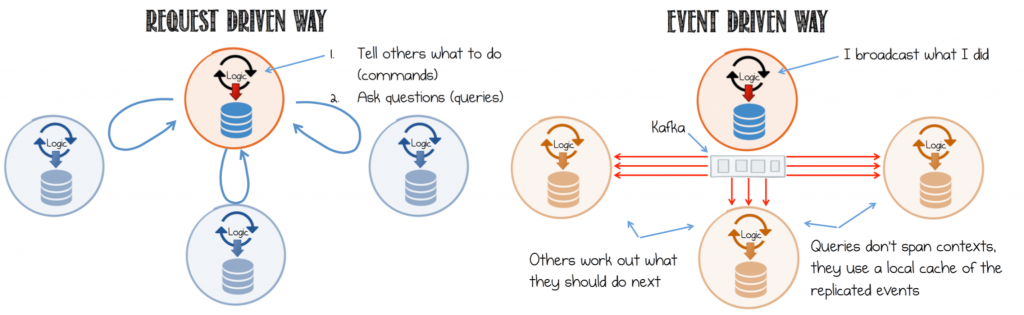
Commands, Events and Queries
Before we dive into an example, we need to fix three simple concepts. There are three ways that services can interact with one another: Commands, Events and Queries. If you’ve not considered the distinction between these three before, it’s well worth doing so.
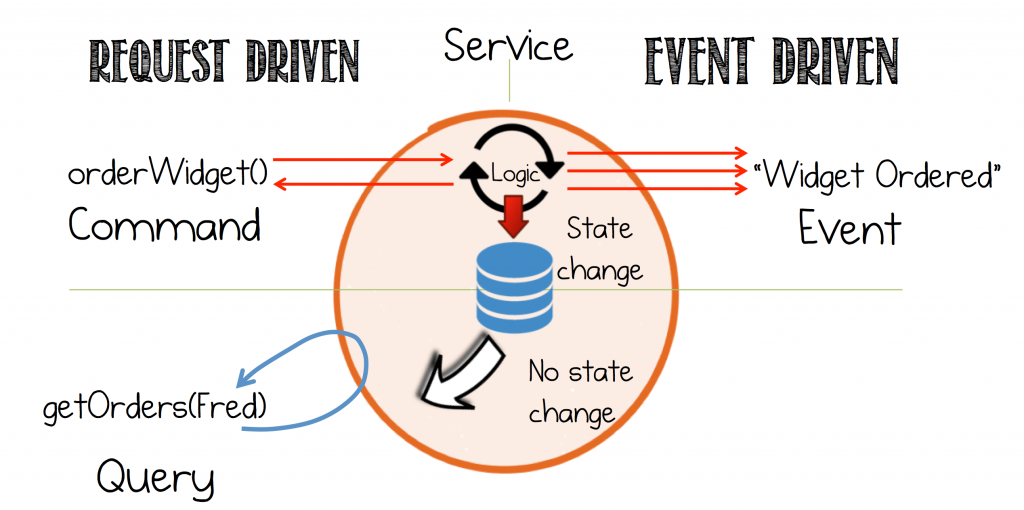
The beauty of events is they are both fact and trigger. Data-on-the-outside that can be reused by any service in the system. But from a services perspective Events lead to less coupling than Commands and Queries. This fact is important.
- Commands are an action. A request for some operation to be performed in another service. Something that will change the state of the system. Commands expect a response.
- Events are both a Fact and a Trigger. Something that has happened, expressed as a notification.
- Queries are a request to look something up. Importantly, queries are side effect free; they leave the state of the system unchanged.
A Simple Event Driven Flow
Let’s start with a simple example: a customer ordering a widget. Two things happen next:
- The associated payment is processed.
- The system checks to see if more widgets need to be ordered.
In the request-driven approach this can be represented as a chain of commands. There are currently no queries. The interaction would look like this:
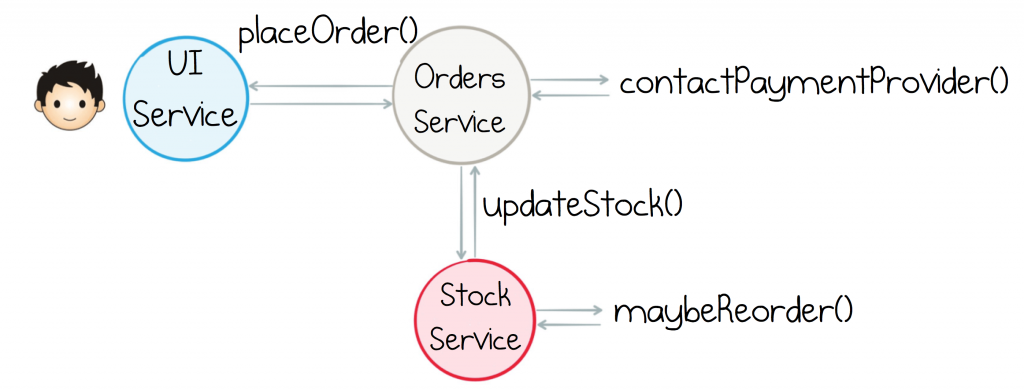
The first thing to note is the business process for “Buying more Stock” is initiated by (called by) the Orders Service. This mingles responsibilities across the two services. Ideally we’d have a better separation of concerns.
Now if we can represent the same flow using an Event Driven approach things work a little better.
- The UI Service raises OrderRequested and awaits OrderConfirmed (or Rejected) before returning to the user.
- Both the Orders Service and the Stock Service react to the raised event.
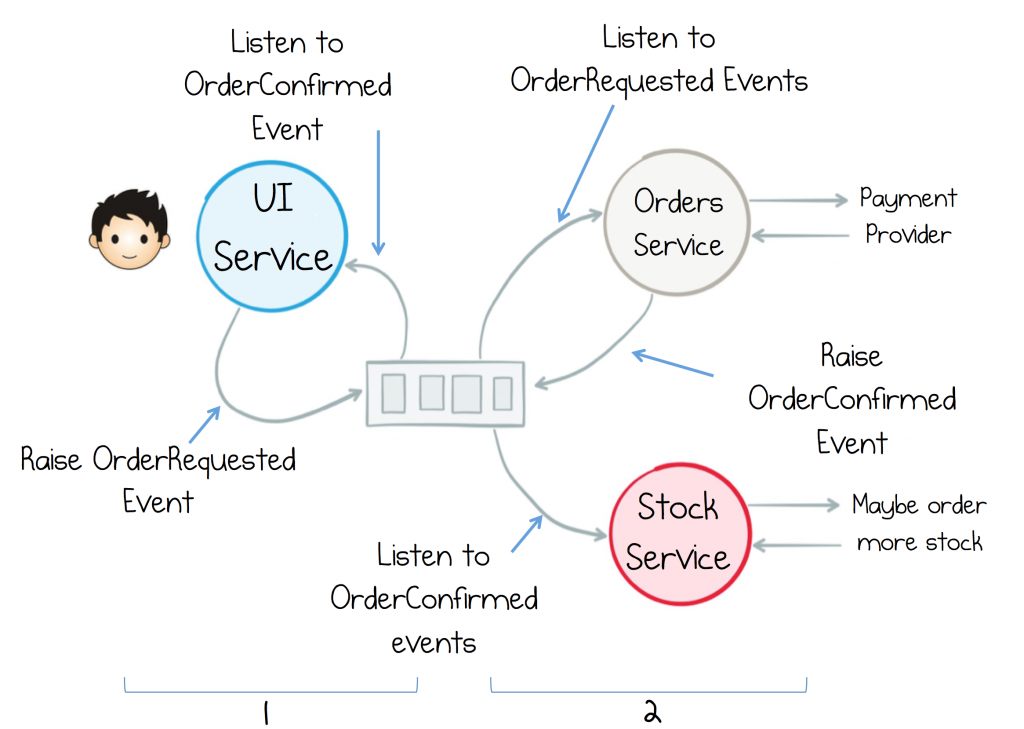
Looking at this closely, the Interaction between the UI service and the Orders Service hasn’t changed all that much, other than they communicate via events, rather than calling one another directly.
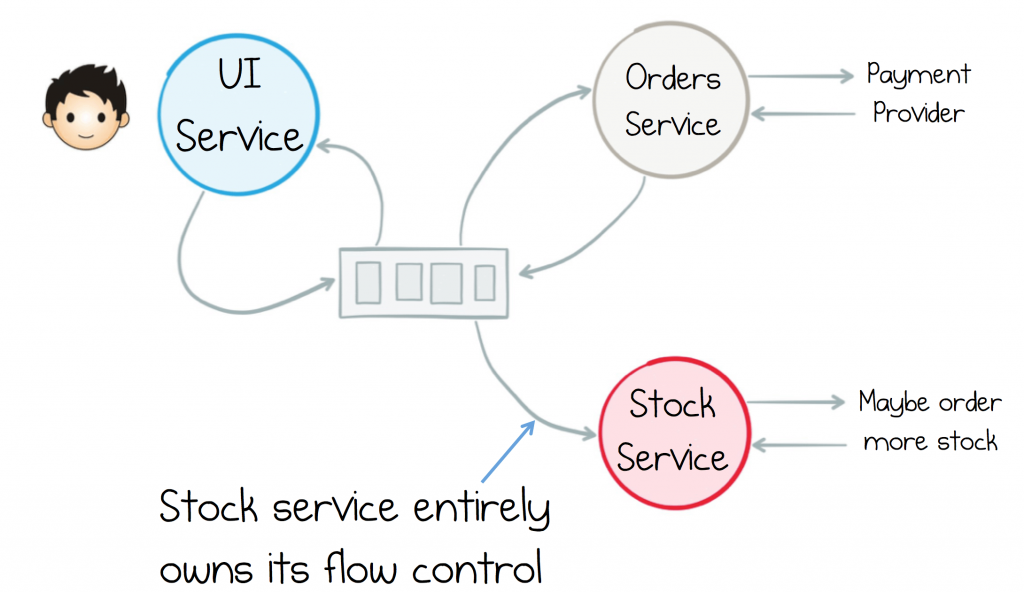
The Stock service is interesting though. No longer does the Orders Service tell it what to do. It controls whether it partakes in the interaction, or not. This is a very important property of this type of architecture, termed Receiver Driven Routing. Logic is pushed to the receiver of the events, rather than the sender. The burden of responsibility is flipped!
Flipping control to receivers reduces the coupling between services, which opens up an important level of pluggability to the architecture. Components can be swapped in and out with ease.
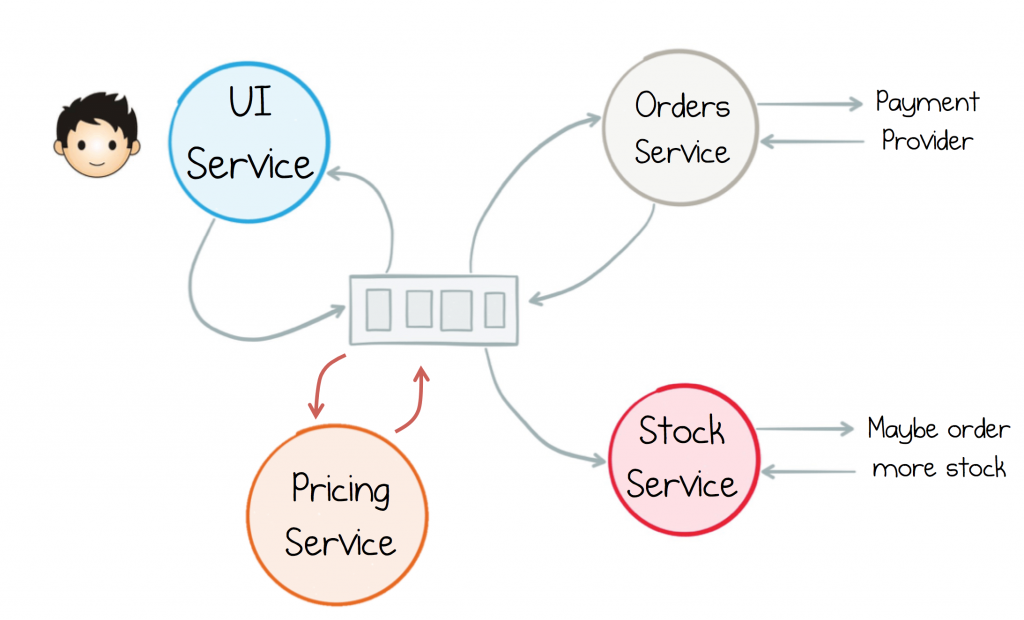
This element of pluggability becomes increasingly important as architectures become more complex. Say we were to add a service that manages pricing in real time, tweaking a product’s price based on supply and demand. In a command-driven world we would need to introduce a maybeUpdatePrice() method which is called by both the Stock Service and the Orders Service. But in the event-driven world re-pricing is just a service that subscribes to the shared stream, sending out price updates when relevant criteria are met.
Blending Events and Queries
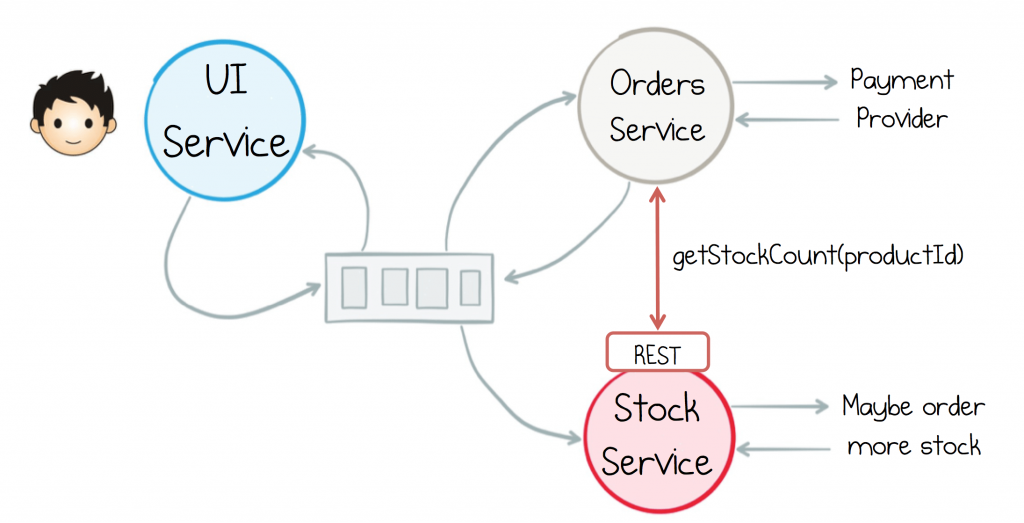
The above example considered only commands/events. There were no queries (remember we defined all interactions as being one of commands, events and queries earlier). Queries are a necessity for all but the simplest architecture. So let’s extend the example a bit, making the Orders Service check that there is sufficient Stock before it processes a Payment.
The request-driven approach to this would involve sending a query to the Stock service to retrieve the current stock count. This leads to a hybrid model, where the event stream is used purely for notification, allowing any service to dip into the flow, but queries go directly to source.
For larger ecosystems, where services need to evolve independently, remote queries add a lot of coupling, tying services together at runtime. We can avoid such cross-context queries by internalising them. The stream of events is used to cache datasets in each service, where they can be queried locally.
So to add this stock check, the Orders Service would subscribe to the stream of Stock events, storing them locally in a database. It would then query this ‘view’ to validate there is sufficient stock.
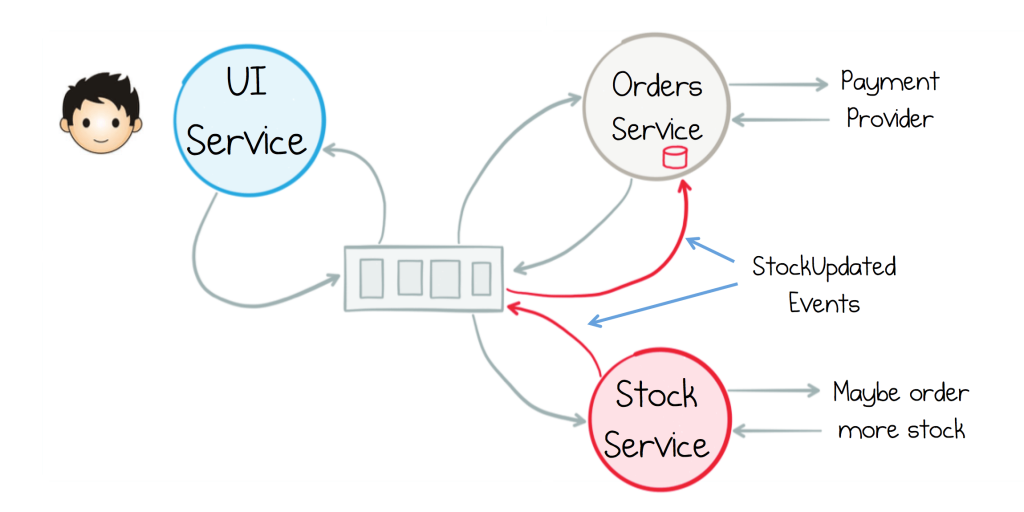
Pure event-driven systems have no concept of remote queries – events propagate state to services where it is queried locally
There are three advantages of this ‘Query by Event-Carried State Transfer’ approach:
- Better decoupling: Queries are local. They involve no cross-context calls. This ties services far less tightly than their request-driven brethren.
- Better autonomy: The Orders service has a private copy of the Stock dataset so it can do whatever it likes with it, rather than being limited to the query functionality offered by the Stock Service.
- Efficient Joins: If we were to “look up the stock” on every order, we would effectively be doing a join over the network between the two services. As workloads grow, or more sources need to be combined, this can be increasingly arduous. ‘Query by Event Carried State Transfer’ solves this issue by bringing queries (and joins) local.
This approach isn’t without its downsides though. Services become inherently stateful. They need to keep track of, and curate, the propagated data set over time. The duplication of state can also make some problems harder to reason about (how do we decrement the stock count atomically?) and we should be careful of divergence over time. But all these issues have workable solutions, they just need a little consideration. This is well worth the effort for larger, more complex estates.
The Single Writer Principle
A useful principle to apply with this style of system is to assign responsibility for propagating events of a specific type, to a single service: a single writer. So the Stock Service would own how the ‘Inventory of Stock’ progresses forward over time, the Orders Service would own Orders, etc.
This helps funnel consistency, validation and other ‘write path’ concerns through a single code path (although not necessarily a single process). So in the example below, notice that the Order Service takes control of every state change made to an Order, but the whole event flow spans Orders, Payments and Shipments, each managed by their respective services.
Assigning responsibility for event propagation is important because these aren’t just ephemeral events, or transient chit-chat. They represent shared facts, the data-on-the-outside. As such, services need to take responsibility for curating these shared datasets over time: fixing errors, handling situations where schemas change etc.
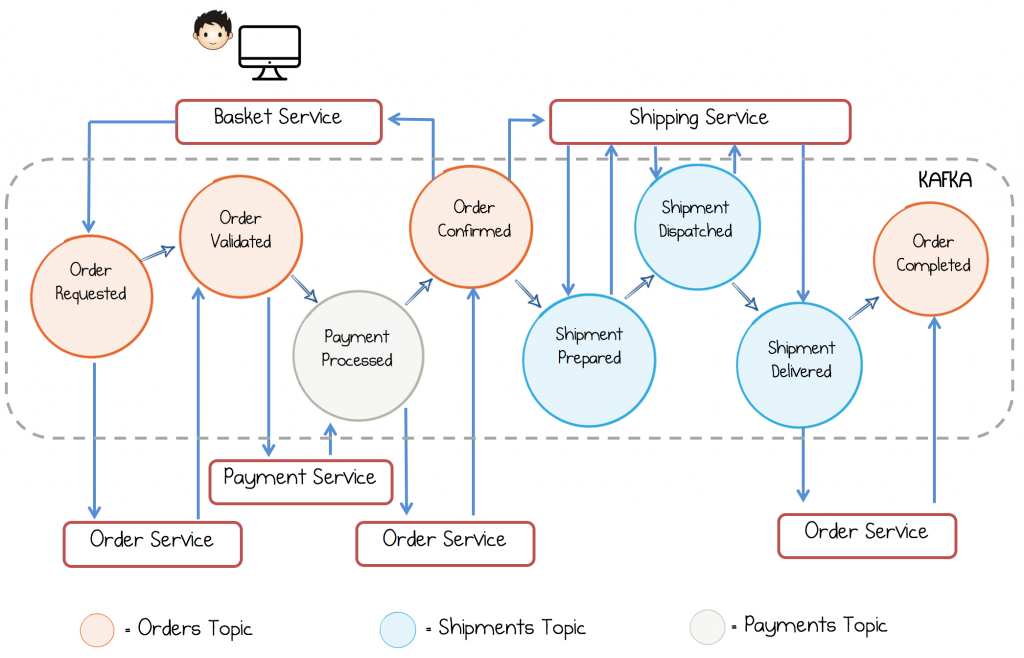
| Here each color represents a topic, in Kafka, for Orders, Shipments and Payments. The basket service starts the ball rolling. When a user clicks ‘buy’ it raises Order Requested, waiting for the Order Confirmed event before it responds back to the user. The three other services handle the state transitions that pertain to their section of the workflow. So for example, after the payment is processed, the Order service pushes the Order from Validated to Confirmed. |
Blending Patterns and Clustering Services
For some the pattern described above will look like Enterprise Messaging, but it is subtly different. Enterprise Messaging, in practice, focuses on state transfer, effectively tying databases together across a network.
Event Collaboration is about services progressing some business goal, through a cascade of events, which trigger services into action. So it’s a pattern for business processing, rather than simply a mechanism for moving state.
But we typically want to leverage both “faces” of this pattern in the systems we build. In fact, one of the beauties of this pattern is it can handle both the micro and the macro, or be hybridized where it makes sense.
Combining patterns is also quite common. We might want the flexibility of remote queries rather than the overhead of maintaining a dataset locally, particularly as datasets grow. This makes it easier to deploy simple functions (which is important if we want to compose lightweight, serverless-styled, event flows), or because we’re in a stateless container or browser.
The trick is to limit the scope of these query interfaces, ideally to within a bounded context*. It’s typically better to have an architecture with many specific, targeted views rather than a single, shared datastore. (*A bounded context, here, is a set of services which share the same deployment cycle or domain model.)
To limit the scope of remote queries we can use a clustered context pattern. Here event flows are the sole communication pattern between contexts. But services within a context leverage both event-driven processing and request-driven views, where they are needed.
In the example below we have three divisions, which communicate with one another only through events. Inside each one we use finer grained event-driven flows. Some of these include a view tier (query layer). This balances coupling with convenience, allowing us to blend fine-grained services with the larger entities; the legacy applications or off the shelf products, which inhabit many real world service estates.
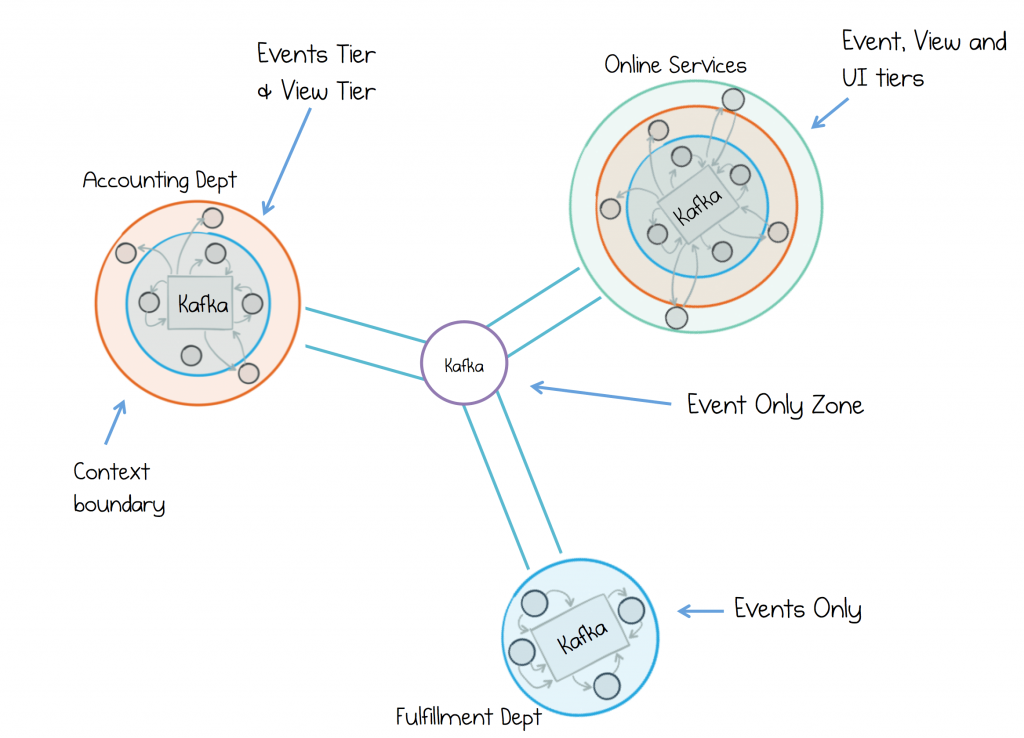
Clustered Context Model
- Decoupling: Break long chains of blocking commands. Decompose synchronous workflows. Brokers decouple services so it’s easier to plug new ones in, or change those that are there.
- Offline/Async flows: When the user clicks a button many things happen. Some synchronously, some asynchronously. Design for the latter and the former falls out for free.
- State Transfer: event become the dataset of your system. Streams provide an efficient mechanism for distributing datasets, so they can be reconstituted, and queried, inside a bounded context.
- Joins: It’s easier to combine/join/augment datasets from different services. Joins are fast and local.
- Traceability: It’s easier to debug the distributed ‘murder mystery’ when there’s a central, immutable, retentive narrative journaling each interaction as it unfolds in time.
Summing Up
So in the event driven approach we use Events instead of Commands. Events trigger processing. They are also turned into views we can query locally. We revert back to remote, synchronous queries where necessary, particularly in smaller ecosystems, but we limit their scope in larger ones (ideally to a single bounded context).
But all these approaches are just patterns. Guiding principles for sewing systems together. We shouldn’t be too dogmatic about them. For example a global query service can still be a good idea, if it is something that rarely changes (like a Single Sign On service).
The trick is to start with a baseline of events. Events provide far less opportunity for services to couple themselves to one another, and flipping flow-control to the receiver makes for better separated concerns and better pluggability.
The other interesting thing about event-driven approaches is they work as well for large, complex architectures as they do for small, highly collaborative ones. A backbone of events gives services the autonomy they need to evolve freely. Missing the complex ties of commands and queries. As for the Ops engineers, they’ll still be wearing deerstalkers and playing murder mystery, but hopefully not quite as often, and at least now the story comes with a script!

But with all this talk of events, we’ve talked little of distributed logs or stream processing. When we apply this pattern with Kafka the rules of the system change. Retention in the broker becomes a tool we can design for, allowing us to embrace data-on-the-outside. Something services can refer back to.
Streaming Platforms sit very naturally with this model of processing events and building views. Views embedded directly inside a service, views a service queries remotely, or views materialised as an on-going stream.
This leads to a whole host of optimisations: leveraging the duality between event stream and event store, blending in stream processing tools that sift through the narrative, joining streams from many services and materializing views we can query. These patterns are empowering. They allow us to reimagine business processing using a toolset specifically designed for handling streams of events. But all these optimisations build on the concepts discussed here, simply applied with a more contemporary toolset.
In the next post, we will look at how we can use the various features Kafka offers to build scalable, highly-available event driven services.
Thanks to Antony Stubbs, Tim Berglund, Kaufman Ng, Gwen Shapira and Jay Kreps for their help reviewing this post.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures (Read Next)
Part 4: Chain Services with Exactly Once Guarantees
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
Find out More:
- Apache Kafka® for Microservices: A Confluent Online Talk Series
- Whitepaper on Microservices for Apache Kafka
- “Event Collaboration” post by Martin Fowler
- “What do you mean by Event Driven” post and associated talk by Martin Fowler
- “Data on the Outside versus Data on the Inside” by Pat Helland
- “The Calculus of Service Availability” by Ben Treynor, Mike Dahlin, Vivek Rau, Betsy Beyer
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Streaming Data Integration with Apache Kafka®
Streaming data integration supports enriched, reusable, canonical streams that can be transformed, shared ,or replicated to different destinations, not just one.



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.