New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Getting Your Feet Wet with Stream Processing – Part 1: Tutorial for Developing Streaming Applications
Stream processing is a data processing technology used to collect, store, and manage continuous streams of data as it’s produced or received. Stream processing (also known as event streaming or complex event processing) has numerous use cases, and is often the backend process for billing, fulfillment or fraud detection, which may need to be decoupled from the frontend where users click buttons and expect things to happen.
Benefits of Stream Processing
The event-driven model provides many benefits: It decouples dependencies between services, provides some level of pluggability to the architecture, enables services to evolve independently, etc.
In his book Designing Event-Driven Systems, Ben Stopford explains how event-driven architectures can be used to build business-critical systems. He describes the value of turning databases “inside out” and treating event streams as a “source of truth.” Among other things, the book shows you how to apply patterns, including event collaboration, event sourcing and CQRS for building microservices and event-oriented architectures.
Such systems typically use Apache Kafka® as the foundation. Kafka is like a central dataplane that holds shared events and keeps services in sync. Its distributed cluster technology provides availability, resiliency and performance properties that strengthen the architecture, leaving the programmer to simply write and deploy client applications that will run load balanced and be highly available.
If you are ready to move from reading about these fundamental concepts to more hands-on learning, Confluent offers several resources:
This two-part blog series will help you develop and validate real-time streaming applications. With part 1, we introduce a new resource:
And in the second part, we validate those streaming applications. For now, let’s talk about this new tutorial for developers.
Stream Processing Tutorial for Developers
This free, self-paced tutorial is a great introduction for developers who are just getting started with stream processing. You will learn the basics of the Kafka Streams API, which is far richer than a Kafka producer or Kafka consumer, and common patterns to design and build event-driven applications.
The tutorial is based on a small microservices ecosystem, showcasing an order management workflow, such as one you might find in retail and online shopping. It is built using Kafka Streams, whereby business events that describe the order management workflow propagate through this ecosystem. The blog post Building a Microservices Ecosystem with Kafka Streams and KSQL outlines the approach used.
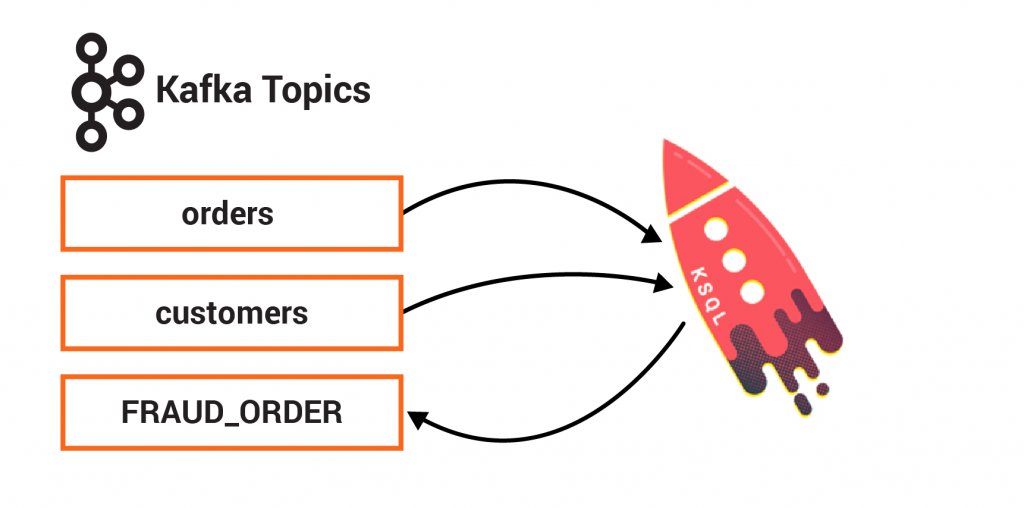
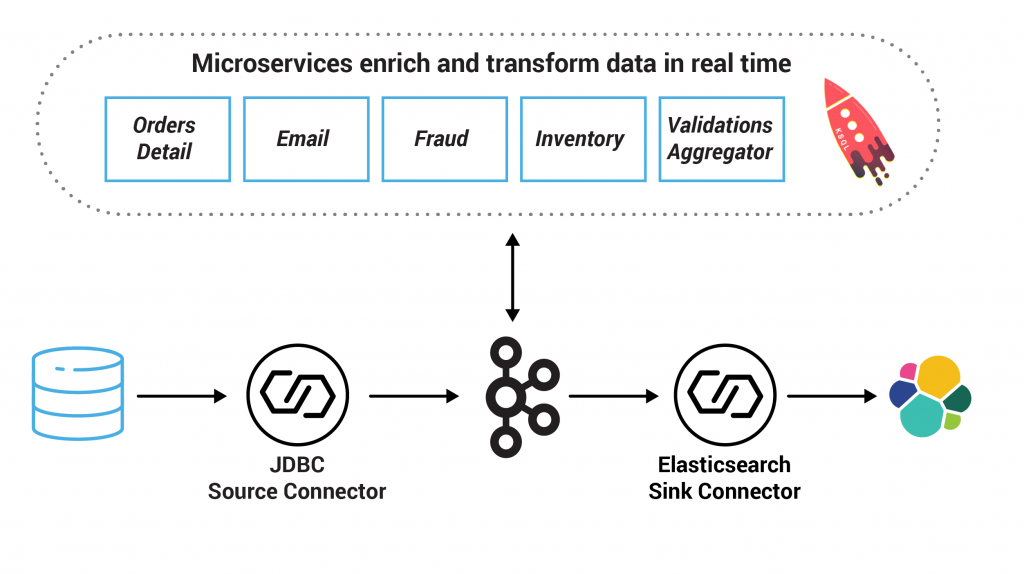 In this example, the system centers on an Orders Service which exposes a REST interface to POST and GET Orders. Posting an Order creates an event in Kafka that is recorded in the topic orders. This is picked up by three different validation engines (Fraud Service, Inventory Service and Order Details Service), which validate the order in parallel, emitting a PASS or FAIL based on whether each validation succeeds.
In this example, the system centers on an Orders Service which exposes a REST interface to POST and GET Orders. Posting an Order creates an event in Kafka that is recorded in the topic orders. This is picked up by three different validation engines (Fraud Service, Inventory Service and Order Details Service), which validate the order in parallel, emitting a PASS or FAIL based on whether each validation succeeds.
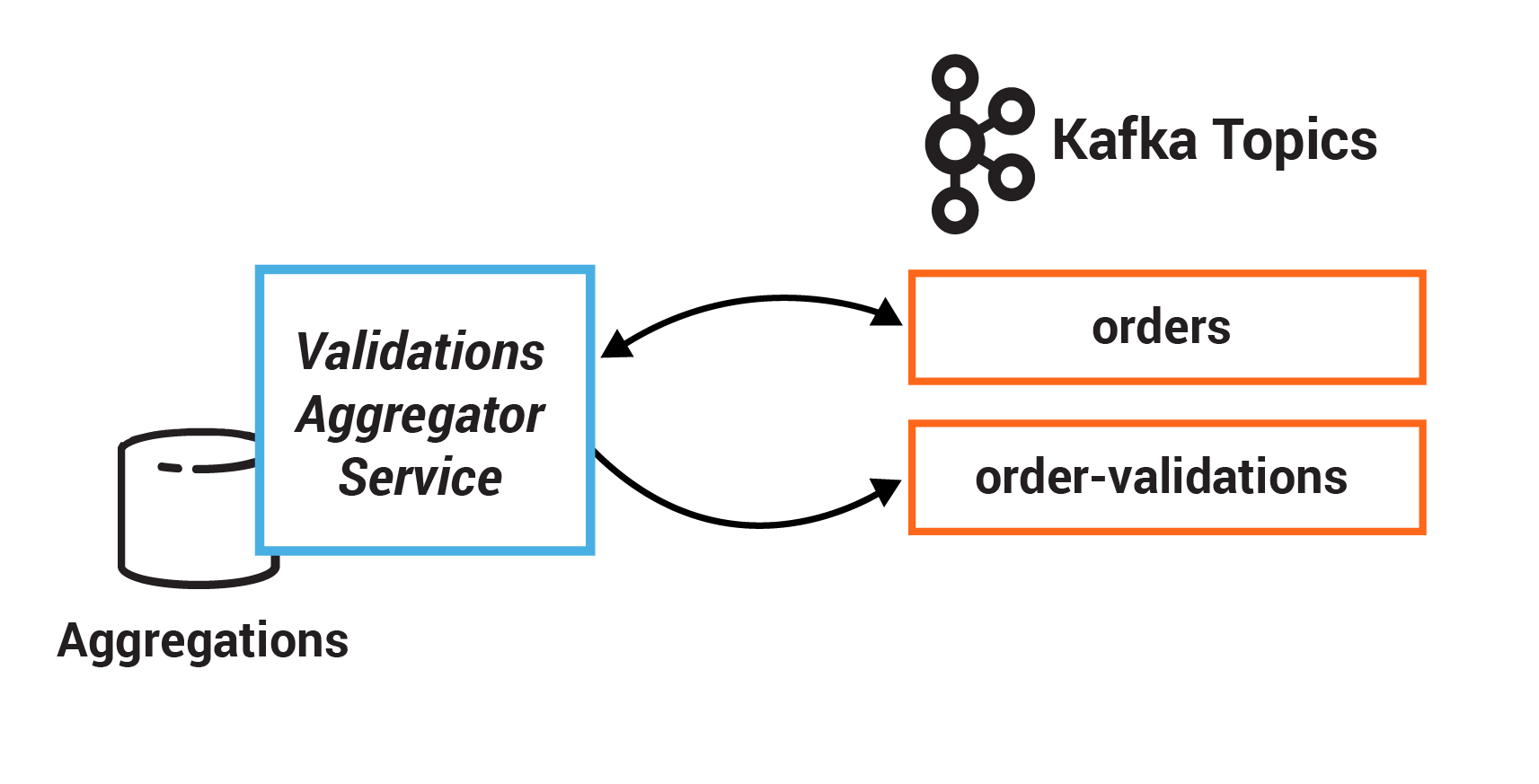
The result of each validation is pushed through a separate topic, Order Validations, so that we retain the single writer status of the Orders Service —> Orders Topic (Ben Stopford’s book discusses several options for managing consistency in event collaboration). The results of the various validation checks are aggregated in the Validation Aggregator Service, which then moves the order to a Validated or Failed state, based on the combined result.
To allow users to GET any order, the Orders Service creates a queryable materialized view (embedded inside the Orders Service), using a state store in each instance of the service, so that any Order can be requested historically. Note also that the Orders Service can be scaled out over a number of nodes, in which case GET requests must be routed to the correct node to get a certain key. This is handled automatically using the interactive queries functionality in Kafka Streams.
The Orders Service also includes a blocking HTTP GET so that clients can read their own writes. In this way, we bridge the synchronous, blocking paradigm of a RESTful interface with the asynchronous, non-blocking processing performed server side.
There is a simple service that sends emails, and another that collates orders and makes them available in a search index using Elasticsearch.
Finally, Confluent KSQL is running with persistent queries to enrich streams and to also check for fraudulent behavior.
Here is a diagram of the microservices and the related Kafka topics: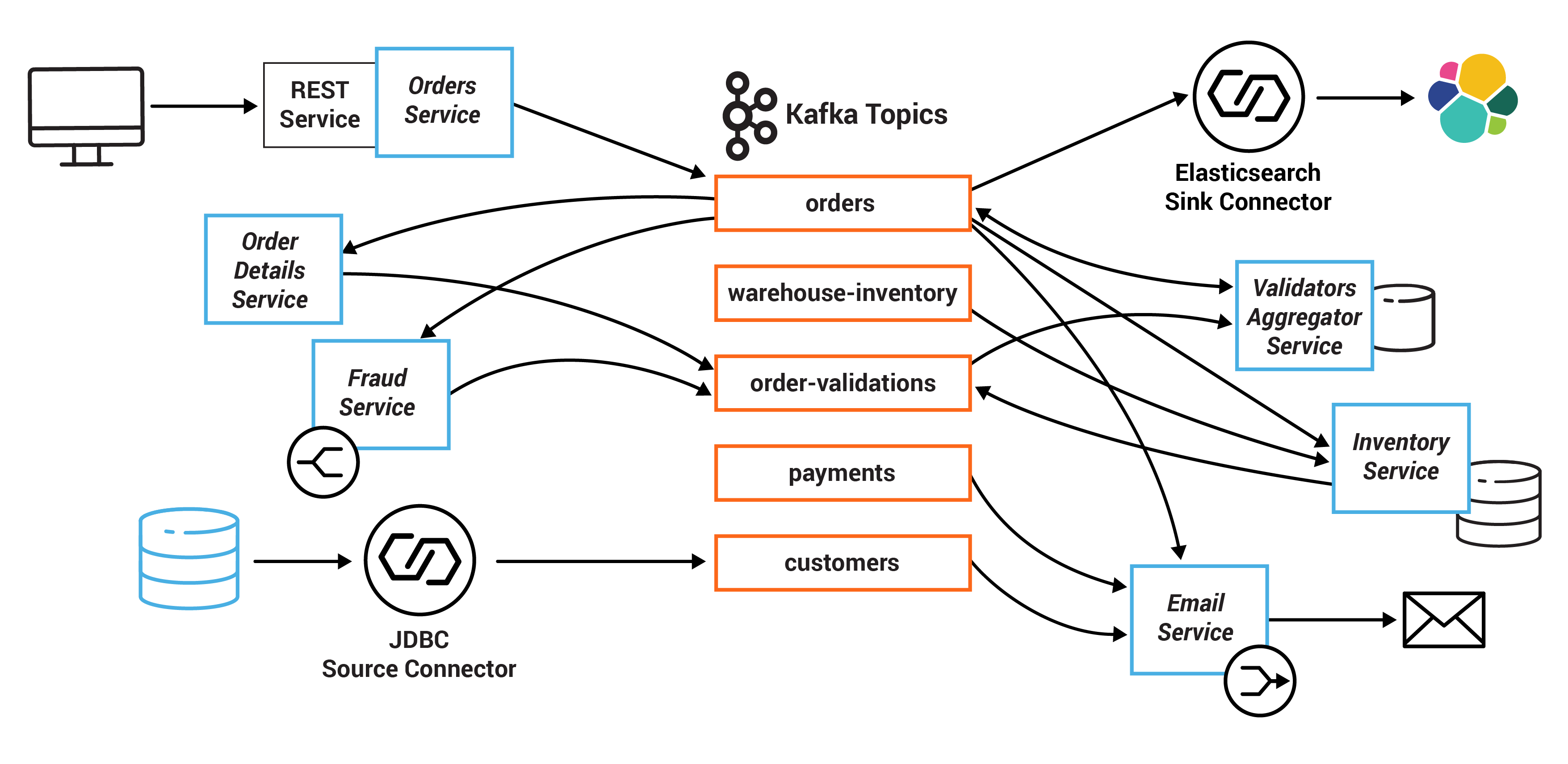
To use the tutorial, first you have to properly set up your environment. You can use a local Confluent Platform install or Docker.
Then run the full end-to-end working solution, which requires no code development, to see a customer-representative deployment of a streaming application. This provides context for each of the exercises in which you will develop pieces of the microservices.
After you have successfully run the full solution, go through the individual exercises in the tutorial to better understand the basic principles of streaming applications. For each exercise, the tutorial provides a stub file for which you have to complete the code. By working on these exercises, you will learn the patterns for writing solid streaming applications and gain experience with using the Kafka Streams API. Complete the code (there are hints if you need them!), compile and run the provided tests to ensure it works!
The tutorial walks through the following exercises:
- Exercise 1: Persist events
- Exercise 2: Event-driven applications
- Exercise 3: Enriching streams with joins
- Exercise 4: Filtering and branching
- Exercise 5: Stateful operations
- Exercise 6: State stores
- Exercise 7: Enrichment with KSQL
Exercise 1: Persist Events
In this exercise, you will persist events into Kafka by producing records that represent customer orders. An event is simply a thing that happened or occurred. An event in a business is some fact that occurred, such as a sale, an invoice, a trade, a customer experience, etc., and it is the source of truth. In event-oriented architectures, events are first-class citizens that constantly push data into applications. Client applications can then react to these streams of events in real time and decide what to do next.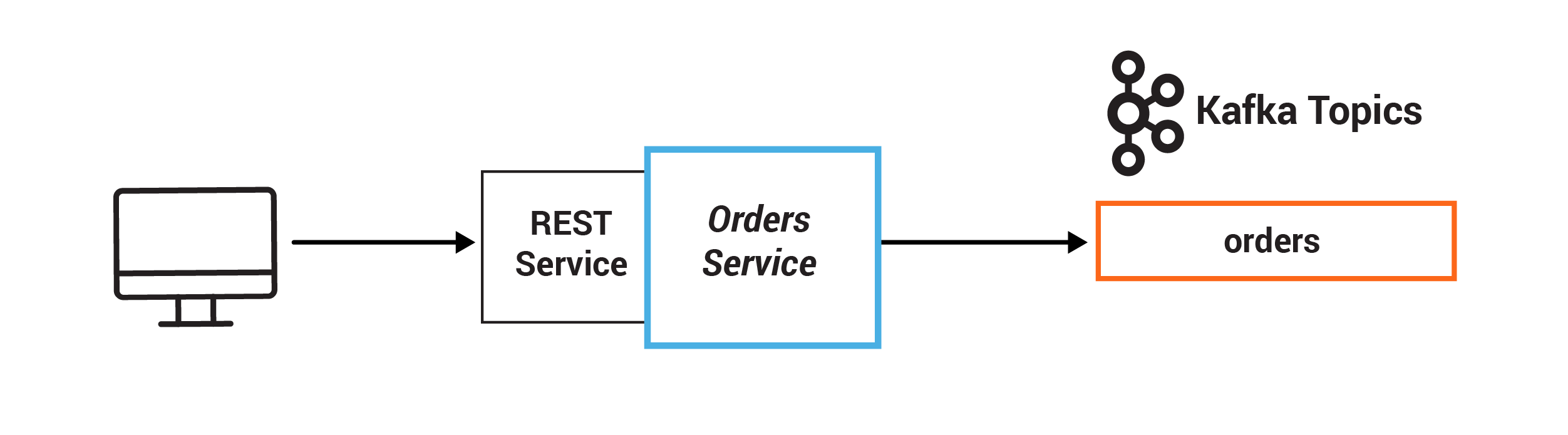
Exercise 2: Event-driven applications
In this exercise, you will let the order event itself trigger a service. In such an event-driven design, an event stream is the inter-service communication that leads to less coupling and queries, enables services to cross deployment boundaries and avoids synchronous execution. In contrast, service-based architectures are often designed to be request driven, in which services send commands to other services to tell them what to do, await a response or send queries to get the resulting state.
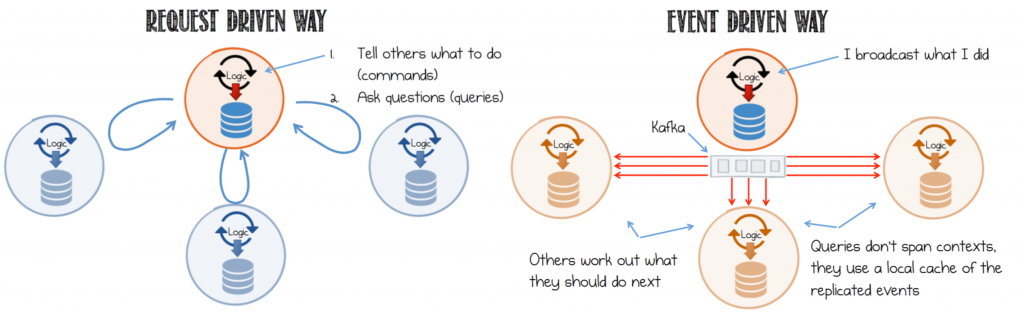
A visual summary of commands, events and queries
Exercise 3: Enriching Streams with Joins
In this exercise, you will write a service that enriches the streaming order information by joining it with streaming payment information and data from a customer database. Many stream processing applications in practice are coded as streaming joins. For example, applications backing an online shop might need to access multiple updating database tables (e.g., sales prices, inventory, customer information) in order to enrich a new data record (e.g., customer transaction) with context information. In these scenarios, you may need to perform table lookups at very large scale and with a low processing latency.
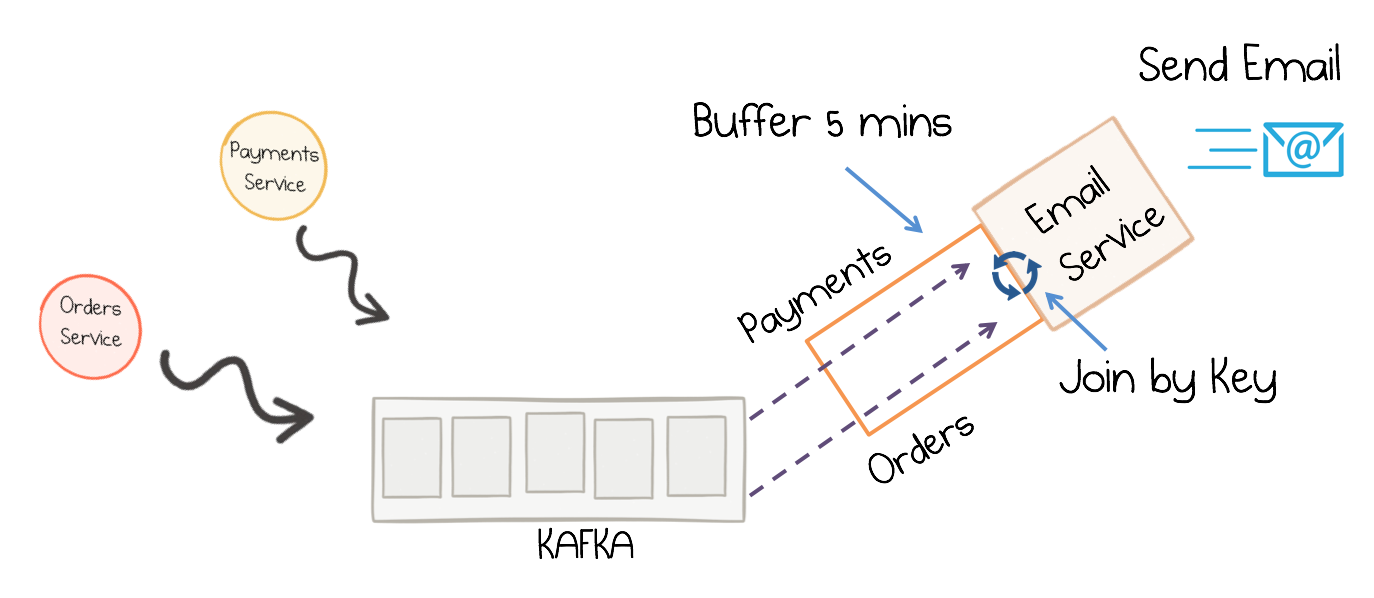
A stateful streaming service that joins two streams at runtime
A popular pattern is to make the information in the databases available in Kafka through so-called change data capture (CDC), together with Kafka’s Connect API to pull in the data from the database (read more in Robin Moffatt’s blog post No More Silos: How to Integrate Your Databases with Apache Kafka and CDC). Once the data is in Kafka, client applications can perform very fast and efficient joins of such tables and streams, rather than requiring the application to make a query to a remote database over the network for each record.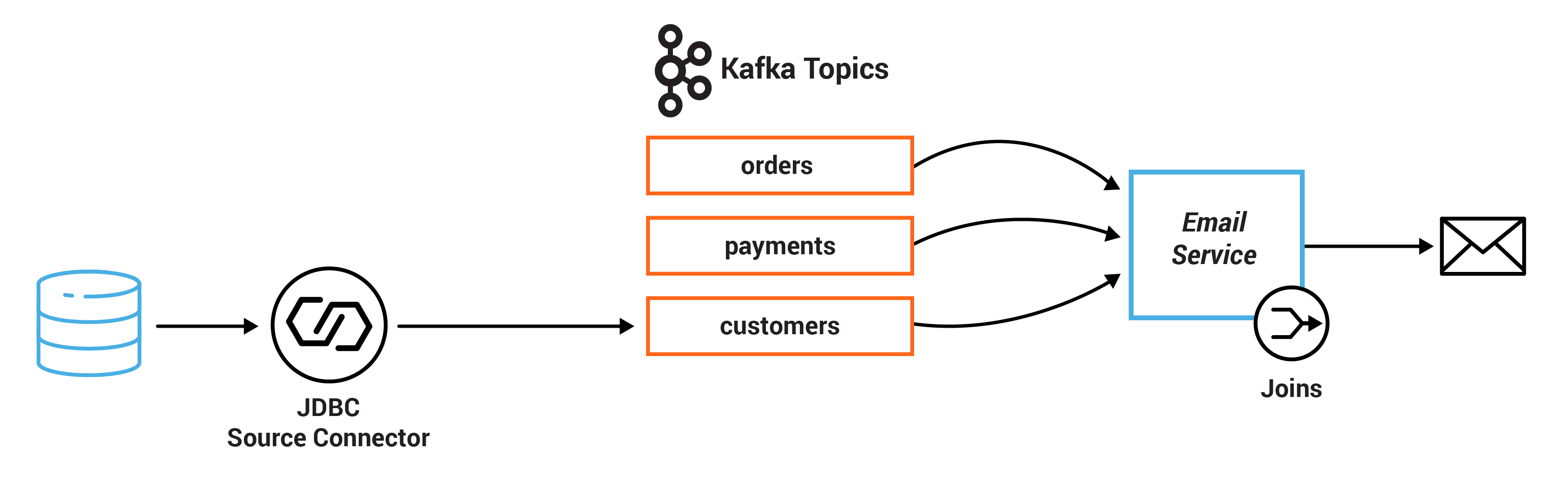
Exercise 4: Filtering and branching
Kafka can capture a lot of information related to an event into a single Kafka topic. Client applications can then manipulate that data based on some user-defined criteria to create new streams of data that they can act on. In this exercise, you will define one set of criteria to filter records in a stream based on some criteria. Then you will define define another set of criteria to branch records into two different streams.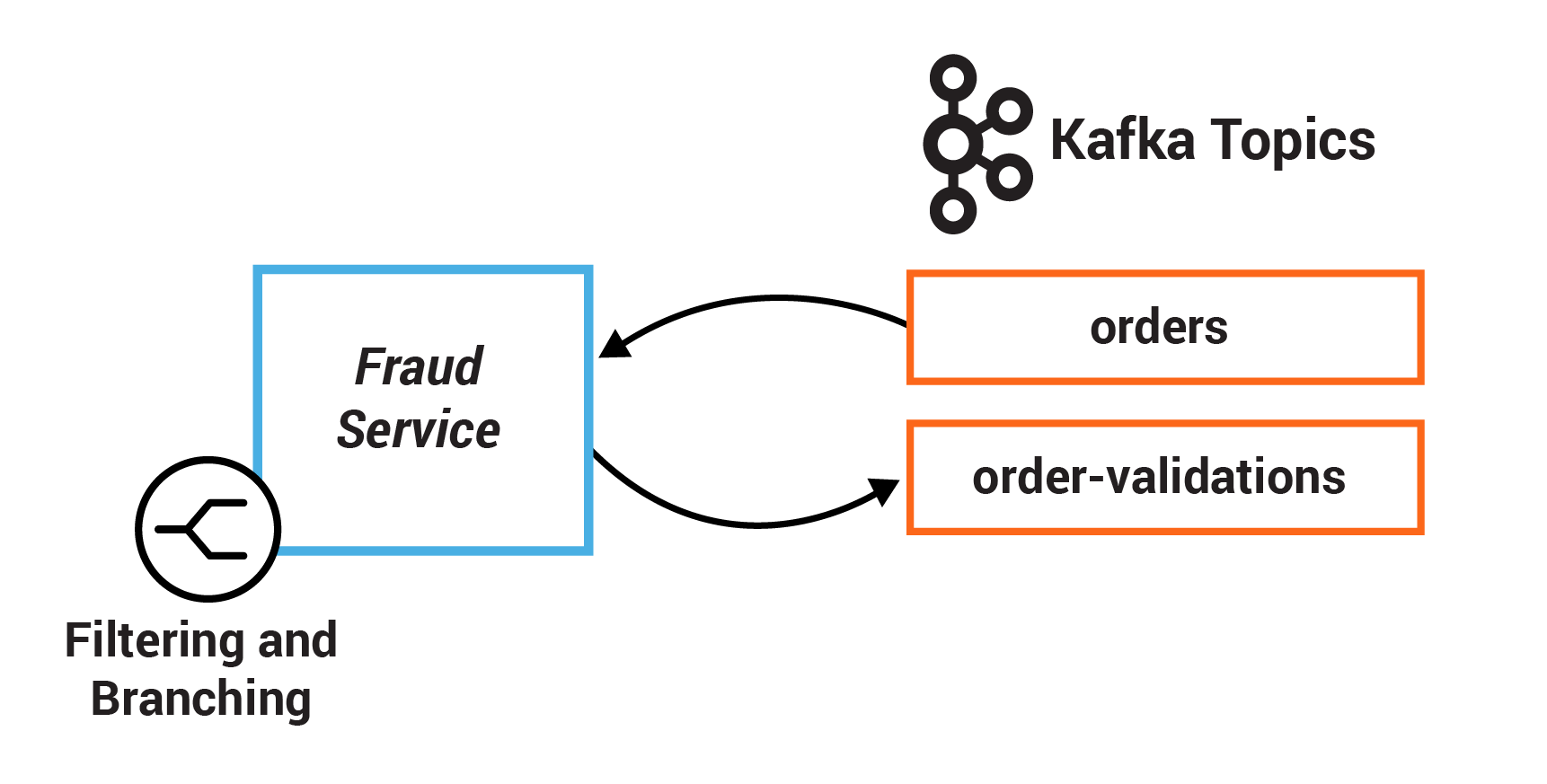
Exercise 5: Stateful operations
In this exercise, you will create a session window to define five-minute windows for processing. You can combine current record values with previous record values using aggregations. They are stateful operations because they maintain data during processing. Oftentimes, these are combined with windowing capabilities in order to run computations in real time over a window of time. Additionally, you will use a stateful operation to collapse duplicate records in a stream.
Exercise 6: State Stores
In this exercise, you will create a state store which is a disk-resident hash table held inside the API for the client application. The state store can be used within stream processing applications to store and query data, an important capability when implementing stateful operations. It can be used to remember recently received input records, to track rolling aggregates, to de-duplicate input records, etc.
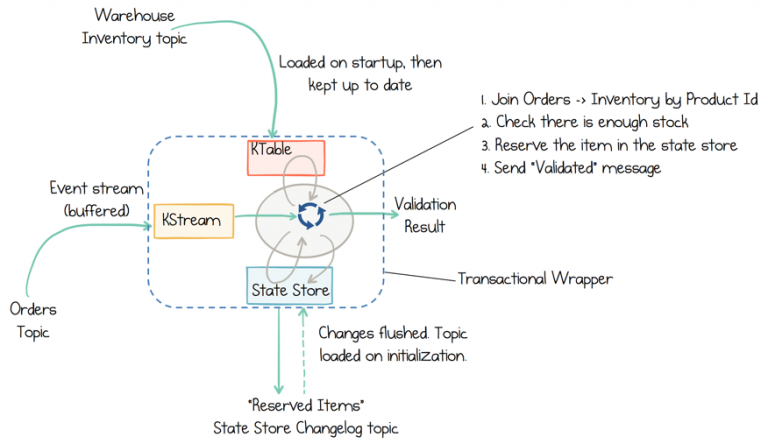
State stores in Kafka Streams can be used to create use-case-specific views right inside the service
A state store is also backed by a Kafka topic and comes with all the Kafka guarantees. Consequently, other applications can also interactively query another application’s state store. Querying state stores is always read-only to guarantee that the underlying state stores will never be mutated out of band (i.e., you cannot add new entries).
Exercise 7: Data Enrichment with KSQL
Confluent KSQL is the streaming SQL engine that enables real-time data processing against Apache Kafka. It provides an easy-to-use, yet powerful interactive SQL interface for stream processing on Kafka, without requiring you to write code in a programming language such as Java or Python.
KSQL is scalable, elastic, fault tolerant and able to support a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing and sessionization. In this exercise, you will create one persistent query that enriches the orders stream with customer information. You will create another persistent query that detects fraudulent behavior by counting the number of orders in a given window.
Learn More about Stream Processing
The new tutorial Introduction to Streaming Application Development is a great introduction for developers to learn the basics of the Kafka Streams API, and apply them to a retail microservices example with an event-driven architecture. With each of these exercises, you can dive in and run the end-to-end automated demo.
We hope you will stay with us for part 2 of this blog series, which will help you be successful in validating your streaming applications and cover unit testing, integration testing, Avro and schema compatibility testing, Confluent Cloud™ tools and multi-datacenter testing.
Validating that a solution works is just as important as implementing one. It provides assurance that the application is working as designed, can handle unexpected events and can evolve without breaking existing functionality.
Meanwhile, to get a deeper understanding of Kafka Streams, check out these other resources:
Related Articles
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.