New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Introducing ksqlDB
Today marks a new release of KSQL, one so significant that we’re giving it a new name: ksqlDB. Like KSQL, ksqlDB remains freely available and community licensed, and you can get the code directly on GitHub. I’ll first share about what we’ve added in this release, then talk about why I think it is so important and explain the new naming.
There are two new major features we’re adding: pull queries and connector management.
Feature 1: Pull queries
For those who don’t know KSQL, let me describe it a bit to give context on the new features we’re adding.
KSQL as it has existed thus far has been about continuously transforming streams of data. It allows you to take existing Apache Kafka® topics and filter, process, and react to them to create new derived topics. These topics can represent pure events or updates to some keyed table that is being materialized off the stream. For example, I could join together many sources of data I have about my customers to create a continually updated “unified customer profile.” KSQL continually processes the stream of incoming events and updates those materializations.
Until now, KSQL has only had support for this kind of continuous, streaming query against its tables of data. That is, in the customer profile example I gave, the output produced is a continuous stream of customer profiles, but you can’t do a lookup on a particular profile. There isn’t really a standard terminology for this kind of streaming SQL query (yet), but we’ve taken to calling them push queries as they push out a continual stream of changes. These queries run forever and produce an ongoing feed of results that updates as new changes occur.
ksqlDB, our new release, integrates traditional database-like lookups on top of these materialized tables of data. We’re calling these pull queries as they allow you to pull data at a point in time. In other contexts, this kind of functionality is sometimes referred to as point-in-time queries or queryable state.
As an example, consider a ride sharing app. It needs to get a continuous feed of the current position of the driver (a push query), as well as look up the current value of several things such as the price of the ride (a pull query).
By default, a query is considered to be a pull query, just as in a normal database. For example, consider the following query:
SELECT ride_id, current_latitude, current_longitude FROM ride_locations WHERE ROWKEY = ‘6fd0fcdb’;
+-----------+-----------------------+-----------------------+ |RIDE_ID |CURRENT_LATITUDE |CURRENT_LONGITUDE | +-----------+-----------------------+-----------------------+ |45334 |37.7749 |122.4194 | +-----------+-----------------------+-----------------------+
Note that this is treated as a pull query and returns the current location at the time the query is executed.
However, if we append EMIT CHANGES, this will be transformed into a push query that produces a continuously updating stream of current driver position coordinates, not just the current state:
SELECT ride_id, current_latitude, current_longitude FROM ride_locations WHERE ROWKEY = ‘6fd0fcdb’ EMIT CHANGES;
+-----------+-----------------------+-----------------------+ |RIDE_ID |CURRENT_LATITUDE |CURRENT_LONGITUDE | +-----------+-----------------------+-----------------------+ |45334 |37.7749 |122.4194 | |45334 |37.7749 |122.4192 | |45334 |37.7747 |122.4190 | |45334 |37.7748 |122.4188 |
This allows us to subscribe to the location as it changes and have that stream of values continuously pushed out to the app. These push queries are nothing new, of course. They are exactly the type of stream processing query that KSQL traditionally handled, but now they exist alongside lookups against stored data as in a traditional database.
Feature 2: Connector management
Often the data you want to work with isn’t in Kafka yet. Perhaps it is in one or more traditional databases, SaaS application APIs, or other systems. Kafka Connect has a great ecosystem of prebuilt connectors that can help you to continuously ingest the streams of data you want into Kafka as well as to continuously export the data out of Kafka again. In the past, you’d have to work across multiple systems: Kafka, Connect, and KSQL, each of which is a bit different in its interface. Now, ksqlDB allows you to directly control and execute connectors built to work with Kafka Connect:
CREATE SOURCE CONNECTOR rider_profiles WITH ( 'connector.class' = 'io.confluent.connect.jdbc.JdbcSourceConnector', 'connection.url' = 'jdbc:postgresql://postgres:5432/postgres', 'key' = 'profile_id', ... );
Why this matters
Our motivation in focusing on this is very simple: building applications around event streams has been too complex thus far. Consider this common stream processing application architecture:
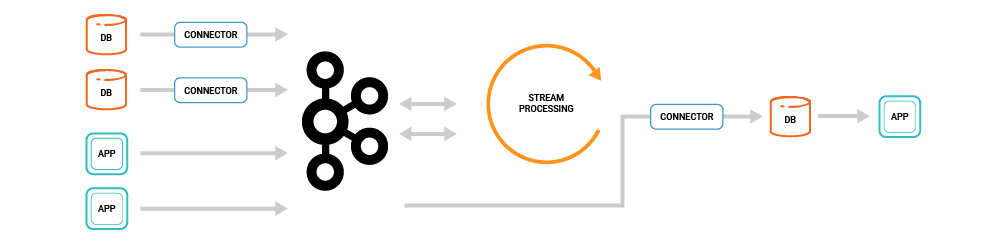
This architecture has a lot of moving parts:
- Extract: there is a set of connectors, perhaps running in Kafka Connect or perhaps custom built, that extract data from source databases or other systems
- Store streams: there is Kafka itself which is storing these streams of events and derived streams
- Transform: there is a stream processing system such as KSQL, Kafka Streams, Spark, or Flink which transforms these streams
- Load: there is a continuous load into a database for serving, perhaps again using Kafka Connect
Store and query: there is a traditional database receiving the stream of computed results and serving those up in an application
In other words, you have the following stages, each handled by different systems:

This is quite complex as it involves a number of different distributed systems, all of which have to be integrated, secured, monitored, and operated as one. It’s a pretty heavy-weight stack for one application! However, one could be forgiven for preferring the simple three-tier architecture of traditional CRUD applications that only need a single database for serving all its data needs.
We want ksqlDB to provide the same simplicity for event streaming applications that relational databases provide for CRUD applications.
ksqlDB allows us to simplify this architecture substantially. Now, there are just two things: Kafka and ksqlDB, bringing together the full set of components needed from connectors, to processing, to queries.
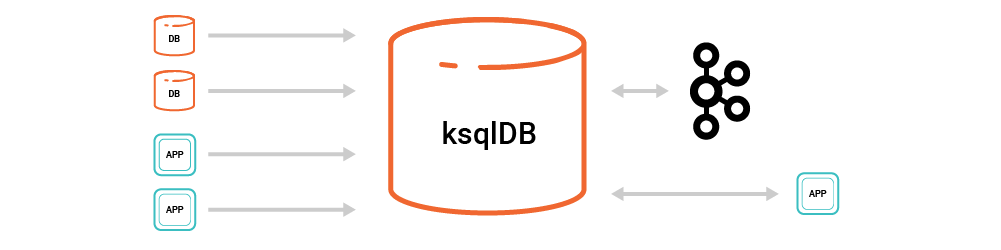
Simplicity is essential if we want to make event streaming a mainstream approach to application development. We think events belong as a first-class citizen in the modern development stack, but to make this viable, we need to make building event streaming applications as easy as building a REST service or CRUD application. The difficulty of spanning multiple, separate systems comes not only from integrating the security, operations, and monitoring of the separate parts, but also from mapping all the conceptual models each piece provides and tying them together in your head as you build a solution. By providing a database built for event streaming, we can avoid that complexity.
ksqlDB in action
What’s cool about adding pull queries and connector management is that you can now build an end-to-end event streaming application in just a few SQL queries:
- Extract: one or more queries to extract the event streams from source systems using Kafka connectors
- Transform: queries to continually materialize results off these streams
- Query: queries to access particular results to serve a UI
Here’s a quick video showing all these in action:
Internal architecture
This raises an interesting question: what does it mean to integrate query capabilities and stream processing capabilities, and does it make sense to do so?
At first glance, a distributed database and a distributed stream processing layer can seem quite different, so one might ask whether this marriage of functionality would be compatible. Actually, it makes even more sense when you know how these systems work on the inside. Although a full architectural breakdown is beyond the scope of this post, I’ll comment briefly on how state is implemented in ksqlDB under the hood.
Databases come in many flavors, but one architecture for a distributed database is centered around a distributed commit log used to synchronize the data across nodes.
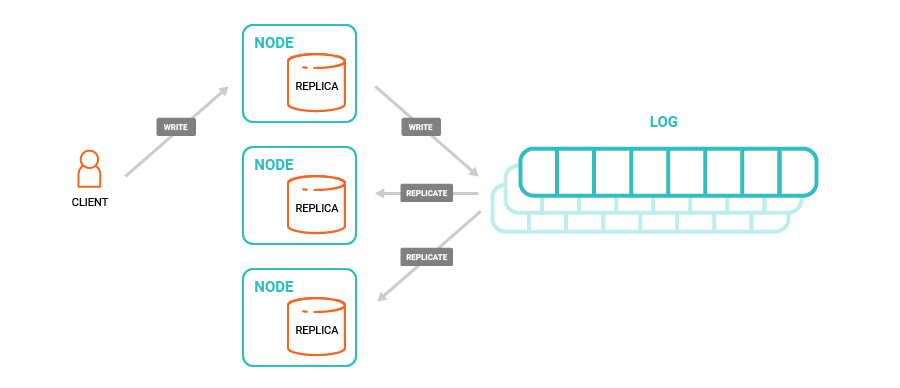
In this architecture, you have a set of storage nodes, each of which maintains data in a local random-access queryable form (say a B-tree or LSM tree). These instances are kept in sync by applying changes through a commit log that centralizes the sequence of updates that are applied. Replicas provide fault tolerance, so if a node fails, its data is also maintained on an identical node elsewhere. Databases that have followed variations on this approach include Amazon Aurora, LinkedIn’s Espresso, Yahoo!’s PNUTs, and Twitter’s Manhattan, among many others.
This is also the precise model used for managing state in KSQL and Kafka Streams. They use RocksDB which provides a local queryable on disk format. They use a commit log that sequences the state updates and provides failover across instances for high availability. KSQL has long supported large, disk-resident tables of materialized data, and this new release now just makes that available for interactive pull queries.
A stateful stream processing system is thus quite similar except that it takes its input from other commit logs and applies transformation logic to that rather than relying on the user or application to directly issue write commands.
Push, meet pull
I think the integration of pull and push queries on top of tables and event streams is a very natural generalization of databases. If you think about it, our conception of what a database needs to do is very much tied to the requirements of a UI-centric application. A user loads a UI and data is fetched at a particular point in time to display.
In a modern company, though, applications aren’t islands that exist disconnected from each other. Rather, what happens in the business percolates out and triggers activity in other parts of the business. Indeed the “user” of a modern service is as likely to be another software application as it is to be a human. A human uses it only at a particular point in time, and the query need only run then. But a service will run continuously, reacting, processing, and transforming events as they arrive. This is where push queries come in. They allow applications to continually process and react to endless streams of events.
We talked in the past about the idea of turning the database inside out. Kafka provides the foundational ingredients for this kind of event-oriented model, but we think with this new functionality, ksqlDB makes this an easily implementable architectural pattern.
KSQL ➝ ksqlDB
As we thought about the experience we wanted to provide in KSQL, we realized it was more than just a couple of new features. People were still thinking of KSQL as a kind of SQL DSL for Kafka Streams, but we felt we could provide a much more interactive and complete solution.
Ultimately, we realized that what we were building had the following properties:
- It stores replicated, fault-tolerant tables of data
- It allows queries and processing in SQL
- You can work interactively against a cluster via a (RESTful) network API
The most obvious way to describe a remote system that provides storage and data processing for event streams in SQL is to call it an event streaming database, and that was what prompted us to change the name from KSQL to ksqlDB.
We think this also captures the experience we want to provide. The reality is that a relational database like Postgres, while far from perfect, provides a much better experience for iteratively developing and debugging an application than that of the current poorly and loosely integrated ecosystem of stream processing components. A unified interactive experience is what we strive towards.
ksqlDB’s place in the ecosystem
We’ve all heard the promise of the “one database to rule them all,” the one system that will solve all problems in data management. These days, though, the reality is there are many great databases out there, and ksqlDB won’t change that. ksqlDB is useful for asynchronously materializing views using SQL and querying them in an interactive fashion. It doesn’t replace something like Postgres or MongoDB as a primary storage system, nor does it have the rich query capabilities of an analytical store like Elasticsearch, Druid, or Snowflake. Its sweet spot is for event streaming applications that are gluing together multiple systems to get simple query capabilities.
In fact, the addition of the connector management functionality in ksqlDB makes it even easier to use ksqlDB with these stores. A simple example is building a real-time indexing pipeline in Elasticsearch, where ksqlDB can help extract and continuously stitch together the documents you want to index and send them off to Elasticsearch for storage, search, and analytics.
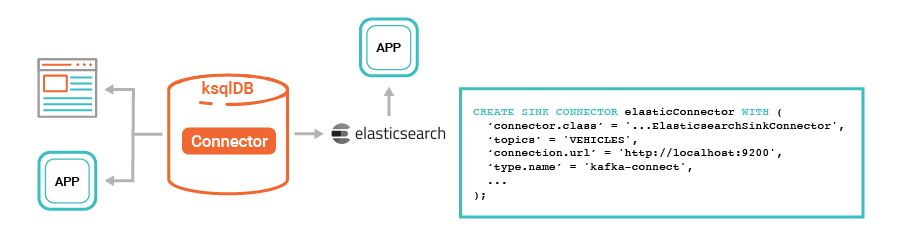
Limitations
As with any new infrastructure layer, it is worth saying what characteristics ksqlDB provides and the limitations it has.
First, ksqlDB is for stream processing and materializing asynchronously computed views. It does not provide read-after-write consistency, and isn’t intended as an OLTP store for primary data.
Secondly, the availability of the serving layer is limited by the failover time. Currently, this takes several seconds as it waits for full group availability. We think this can be improved significantly and will work on that in future releases.
Performance for simple pull queries where the I/O system is not the bottleneck is up to several thousand QPS. We think this can be improved significantly. For larger datasets, which no longer fit in memory when partitioned and replicated across the cluster, the performance is dependent on RocksDB (or since the storage engine is pluggable, the embedded store of your choice).
What’s next
We have an exciting roadmap coming up:
First, we plan on expanding the pull query capabilities to support a wider range of expressions, including range queries and complex groupings. This makes ksqlDB applicable to a broader range of consuming applications.
Second, we’ll be introducing a more robust networked API to serve traffic from ksqlDB’s servers. We plan to directly leverage this work to introduce first-class client library support.
Finally, we’ll sweep through and rectify some of the shortcomings of today’s architecture. In particular, when multiple persistent stream processing queries are running, they each compile into their own Kafka Streams topology. This area is ripe for optimization to cut down on resource consumption.
Getting started
Ready to check it out? Head over to ksqldb.io to get started. Follow the quick start, read the docs, and check out the project on Twitter!
Let us know what you think is missing or ways it can be improved—we invite your feedback within the community and would love to work really closely with early people kicking the tires, so don’t be shy.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.