Build Predictive Machine Learning with Flink | Workshop on Dec 18 | Register Now
Schemas, Contracts, and Compatibility
When you build microservices architectures, one of the concerns you need to address is that of communication between the microservices. At first, you may think to use REST APIs—most programming languages have frameworks that make it very easy to implement REST APIs, so this is a common first choice. REST APIs define the HTTP methods that are used and the request and response payloads that are expected.
An example can be the backend architecture for an insurance product. There is a UI that lets users update their profiles and a backend profile service responsible for updating the profile database. If the user changed their residential address, the profile service will also call the quote service so that the insurance coverage can be recalculated (after all, some neighborhoods are safer than others).
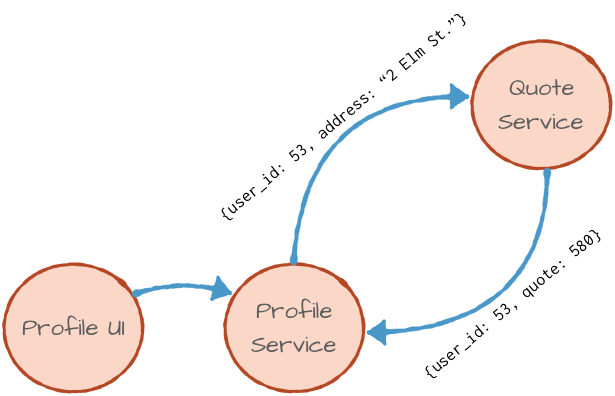
With REST APIs, we can imagine the profile service using HTTP POST to send the following information to the quote service:
{
user_id: 53,
timestamp: 1497842472,
address: “2 Elm St. Chattanooga, TN”
}
And the quote service will acknowledge the request with:
{
user_id: 53,
status: “re-calculating coverage costs”
}
If all goes well, the user will receive an updated quote by mail at his new residential address.
Now you may notice that there is a certain coupling and inversion of responsibility here. The profile service knows that if the address changed, it is responsible for calling the insurance service and asking it to recalculate the quote. However, this bit of business logic really isn’t very relevant to the job of a service that provides simple access to the profile database, and it really shouldn’t be their responsibility.
Imagine that next week I want to roll out a new risk evaluation service that depends on the user address—do I really want to ask the profile service to add some logic to call the new risk service as well? What we really want is for the profile service to record any change in profile, and for the quote service to examine those changes and recalculate when required.
This leads us to event streaming microservices patterns. The profile service will publish the changes in profiles, including address changes to an Apache Kafka® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
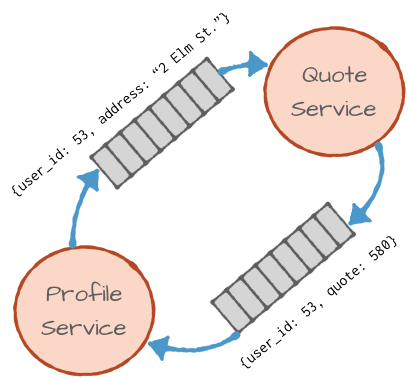
What will the profile service publish? In this case, a simple solution will be to publish the exact same information that it used to send in the HTTP request:
{
user_id: 53,
timestamp: 1497842472,
address: “2 Elm St. Chattanooga, TN”
}
Now that the profile change event is published, it can be received by the quote service. Not only that, but it could also be received by a risk evaluation service, by Kafka Connect that will write the update to the profile database and perhaps by a real-time event streaming application that updates a dashboard showing the number of customers in each sales region. If you evaluate architectures by how easy they are to extend, then this architecture gets an A+.
Real-world architectures involve more than just microservices. There are databases, document stores, data files, NoSQL and ETL processes involved. Having well-defined schemas that are documented, validated and managed across the entire architecture will help integrate data and microservices—a notoriously challenging problem that we discussed at some length in the past. Using events and schemas allow us to integrate the commands and queries that are passed between services and the organization’s data infrastructure—because events are both commands and data, rolled into one.
Note that the same definitions of fields and types that once defined the REST API are now part of the event schema. In both architectures, the profile service sends two fields: user_id, which is an integer, and the new address, a string. The roles are reversed though—the REST API is a promise of what the quote service will accept, and the event schema is a promise of what type of events the profile service will publish. Either way, these promises, whether an API or a schema, is what allows us to connect microservices to each other and use them to build larger applications. Schemas and APIs are contracts between services.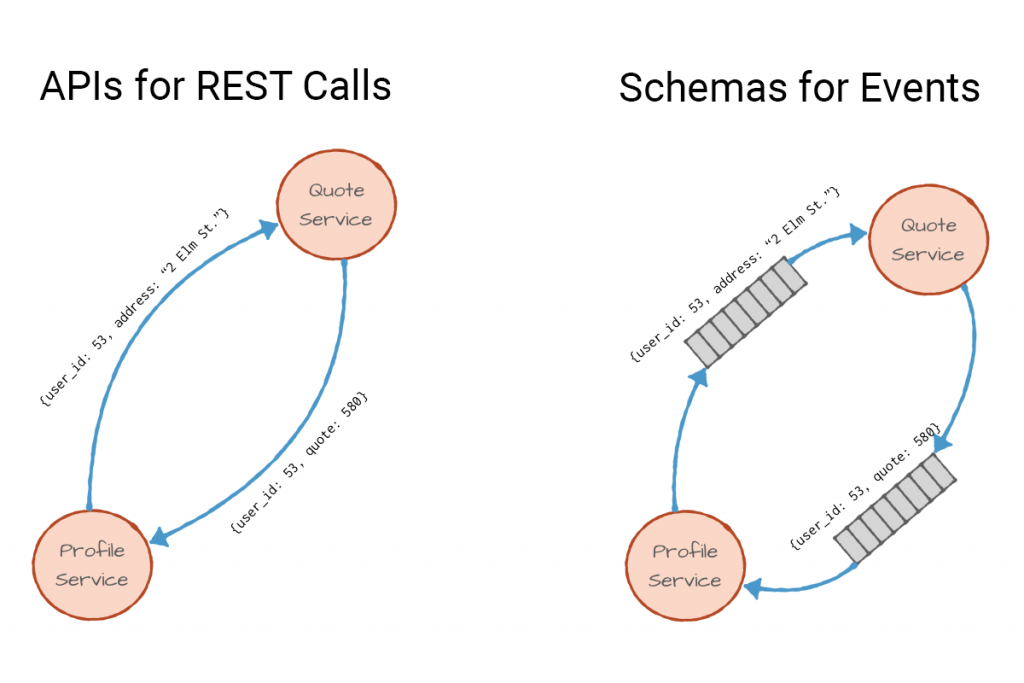
It is not just about services
In fact, schemas are more than just a contract between two event streaming microservices. They are contract between teams. They are at the intersection of the way we develop software, the way we manage data, metadata and the interactions between teams.
To illustrate, let’s look at two examples:
- Documented contracts: Pretend that you are a data scientist working for our imaginary insurance company. You heard through the grapevine that the profile service is now publishing all user profile changes to a Kafka topic, and that anyone with a good business reason can be authorized to read those changes. This is great news! You always suspected that customers who move to even-numbered addresses tend to get involved in car accidents. Now, you can easily test your assumptions. To explore the data a bit, use Confluent’s simple command line tool to read a few events from the Kafka topic in order to see what you are dealing with.Unfortunately, a single event looks like this:
2001 2001 Citrus Heights-Sunrise Blvd Citrus_Hghts 60670001 3400293 34 SAC Sacramento SV Sacramento Valley SAC Sacramento County APCD SMA8 Sacramento Metropolitan Area CA 6920 Sacramento 28 6920 13588 7400 Sunrise Blvd 95610 38 41 56 38.6988889 121 16 15.98999977 -121.271111 10 4284781 650345 52
You can make sense of some of this, but figuring out the house number looks like a serious challenge. In fact, the only way to do it is to find an engineer from the team that built the profile service and ask her. If she says “Oh, field number 7 is the house number. Couldn’t you tell?” you’ll need to bake this information right into your accident-prediction service. So much for decoupling, both in terms of interaction and reliance on other teams, and the code that is written.
- Prevent breaking changes: One of the benefits of event streaming patterns is that once the events are published and the schema is documented, it is very easy for anyone in the organization to use the data. This is a force multiplier for the organization—making it easier for the business to deliver features faster. But there can be unfortunate side effects.Imagine that one of the developers on the team developing the profile service decided that using milliseconds since 1970 to measure time was making their life too difficult. Consequently, the developer decided to switch to a formatted string instead. So instead of sending:
{ user_id: 53, timestamp: 1497842472, address: “2 Elm St. Chattanooga, TN” }They are now sending:
{ user_id: 53, timestamp: “June 28, 2017 4:00pm”, address: “2 Elm St. Chattanooga, TN” }This will break most of the downstream services since they expect a numerical type but now get a string. It is impossible to know how much damage will be caused in advance since any service could consume events from the profiles topic.
Now in both those examples, it is tempting to blame on “miscommunication” or a “lack of proper process.” This is better than blaming individual engineers, but trying to fix the perceived lack of communication and process will result in various meetings, as well as attempts to coordinate changes with many teams and applications, slowing down the development process. The intent of the whole microservices exercise was to speed things up—to decouple teams and allow them to move fast independently. Can we achieve this?
Schemas are APIs
The key to solving a problem is to frame it correctly. In this case, we framed the problems as “people problems.” But if we look at the specifics of the issues, we can see that they would not occur if we used REST APIs instead of events with schemas. Why? Because APIs are seen as first-class citizens within microservice architectures, and any developer worth their salt will document public APIs as a matter of routine. If they didn’t, they would be caught during code review. APIs also have unit tests and integration tests, which would break if a developer changed the field type in an API, so everyone would know far in advance that the change would break things.
The problem is that while schema and APIs are indeed both contracts, schemas often feel like an afterthought compared to APIs, which responsible engineers think deeply about designing, documenting, testing and maintaining. Schemas are often used without the frameworks and tools that allow developers to specify them, evolve them, version them as well as detect breaking changes between schema versions early in the development cycle.
Forgetting about schemas is even more damaging when there are actual databases involved. Databases usually already have schema, whether relational or semi-structured, but there are cases where shortcuts are used to move data between different datastores and services. As a result, the schema information is lost—leading to the same negative outcomes seen when moving from REST APIs to events without well-defined schemas.
Schema management done well, makes it is easy for engineers to find the data they need and to use it safely—without tight coupling between services or teams. Development teams benefit by creating new features and delivering new functionality to the business with very little overhead. They do this by subscribing to existing Kafka topics, receiving well-understood events, processing or using them to make decisions, and publishing the results to existing topics where they will be picked up by other services. For example, you can deploy a new dynamic pricing service by simply reading events that represent current demand, using them to calculate new prices, and publishing the new prices to an existing topic, where they will be picked up by a mobile application.
Things don’t always align that neatly and sometimes the topics you need don’t exist yet, but by having a framework to specify, document, evolve, and validate schemas, you can at the very least prevent services from accidentally breaking each other.
Schema evolution and compatibility
The key difference between schemas and APIs is that events with their schemas are stored for a long duration. Once you finish upgrading all the applications that call the API and move from API v1 to v2, you can safely assume that v1 is gone. Admittedly, this can take some time, but more often than not it is measured in weeks, not years. This is not the case with events where old versions of the schema could be stored forever.
This means that when you start modifying schemas, you need to take into account questions like: Who do we upgrade first—consumers or producers? Can new consumers handle the old events that are still stored in Kafka? Do we need to wait before we upgrade consumers? Can old consumers handle events written by new producers?
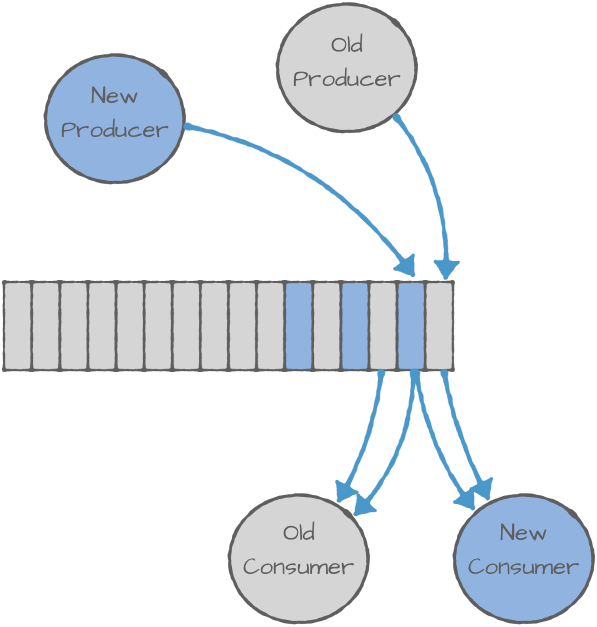
This can get a bit complicated, so data formats like Avro, JSON, and Protobuf define the compatibility rules concerning which changes you’re allowed to make to the schema without breaking the consumers, and how to handle upgrades for the different types of schema changes. The documentation provides detailed information on the different compatibility rules available in Avro and practical examples of their implications in different scenarios. If you’re interested in reading about it more, Martin Kleppmann wrote a good blog post comparing schema evolution in different data formats.
So we recognize that schemas are essential to building a flexible and loosely coupled Kafka architecture, but that they need some care and attention in terms of ensuring compatibility. Of course, memorizing and adhering to a bunch of rules is quite painful and not how developers like to work. What we really want is a way to validate our changes and see if they are compatible. In the same way that unit tests automatically validate changes to the code and to APIs, we also want an automated process to validate schema modifications.
Enter Schema Registry for Apache Kafka
Avro requires that readers have access to the original writer schema in order to be able to deserialize the binary data. Whilst this is not a problem for data files where you can store the schema once for the entire file, providing the schema with every event in Kafka would be particularly inefficient in terms of the network and storage overhead.
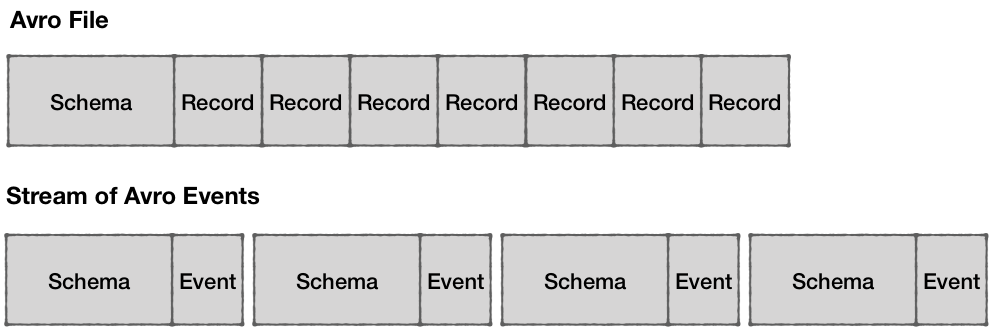
As an architecture pattern, a schema registry is quite simple and has only two components:
- REST service for storing and retrieving schemas
- Java library for fetching and caching schemas
Although the concept of a schema registry for Apache Kafka was first introduced at LinkedIn, since then quite a few companies have created their own versions and talked about them in public: Confluent, Yelp, Airbnb, Uber, Monsanto, Ancestry.com, and probably a few more. Confluent’s Schema Registry is available through Confluent Platform under the Confluent Community License.
As the number of public use cases has grown, so has the list of ways in which the Confluent Schema Registry is used at different companies, from basic schema storage and serving to sophisticated metadata discovery interfaces. Let’s take an in-depth look at how Confluent Schema Registry is used to optimize data pipelines, and guarantee compatibility.
Enabling efficiently structured events
This is the most basic use case and the one LinkedIn engineers had in mind when originally developing the schema registry. Storing the schema with every event would waste lots of memory, network bandwidth and disk space. Rather, we wanted to store the schema in the schema registry, give it a unique ID and store the ID with every event instead of the entire schema. These are the roots from which Confluent Schema Registry evolved.

Doing so requires integration of the schema registry with Kafka producers and consumers so that they are able to store and retrieve the actual schema itself, using Avro serializers and deserializers.
When a producer produces an Avro event, we take the schema of the event and look for it in the schema registry. If the schema is new, we register it in the schema registry and generate an ID. If the schema already exists, we take its ID from the registry. Either way, every time we produce an event with that schema, we store the ID together with the event. Note that the schema and the ID are cached, so as long as we keep producing events with the same schema, we don’t need to talk to the schema registry again.
When a consumer encounters an event with a schema ID, it looks the schema up in the schema registry using the ID, then caches the schema, and uses it to deserialize every event it consumes with this ID.
As you can see, this is a simple yet nice and efficient way to avoid having to attach the schema to every event, particularly since in many cases the schema is much larger than the event itself.
Validating the compatibility of schemas
This is the most critical use case of the Confluent Schema Registry. If you recall, we opened this blog post with a discussion of the importance of maintaining compatibility of events used by microservices, even as requirements and applications evolve. In order to maintain data quality and avoid accidentally breaking consumer applications in production, we need to prevent producers from producing incompatible events.
The context for compatibility is what we call a subject, which is a set of mutually compatible schemas (i.e., different versions of the base schema). Each subject belongs to a topic, but a topic can have multiple subjects. Normally, there will be one subject for message keys and another subject for message values. There may also be a special case where you want to store multiple event types in the same topic, in which each event type will have its own subject.
In the previous section, we explained how producers look up the schemas they are about to produce in the schema registry, and if the schema is new, they register a new schema and create a new ID. When the schema registry is configured to validate compatibility, it will always validate a schema before registering it.
Validation is done by looking up previous schemas registered with the same subject, and using Avro’s compatibility rules to check whether the new schema and the old schema are compatible. Avro supports different types of compatibility, such as forward compatible or backward compatible, and data architects can specify the compatibility rules that will be used when validating schemas for each subject .
If the new schema is compatible, it will be registered successfully, and the producer will receive an ID to use. If it is incompatible, a serialization exception will be thrown, the schema will not register and the message will not be sent to Kafka.
The developers responsible for the application producing the events will need to resolve the schema compatibility issue before they can produce events to Kafka. The consuming applications will never see incompatible events.
Compatibility validation in the development process
Stopping incompatible events before they are written to Kafka and start breaking consumer applications is a great step, but ideally we’d catch compatibility mistakes much sooner. Some organizations only deploy new code to production every few months, and no one wants to wait that long to discover what could be a trivial mistake.
Ideally, a developer is able to run schema validation on their own development machine in the same way they run unit tests. They’d also be also able to run schema validation in their CI/CD pipeline as part of a pre-commit hook, post-merge hook or a nightly build process.
Confluent Schema Registry enables all this via the Schema Registry Maven Plugin, which can take a new schema, compare it to the existing schema in the registry and report whether or not they are compatible. This can be done without registering a new schema or modifying the schema registry in any way, which means that the validation can safely run against the production schema registry.
So far, we assumed that new schema will be registered in production by producers when they attempt to produce events with the new schema. When done this way, the registration process is completely automated and transparent to developers.
In some environments, however, access to the schema registry is controlled and special privileges are required in order to register new schema. We can’t assume that every application will run with sufficient privileges to register new schema. In these cases, the automated process of deploying changes into production will register schemas using either the Maven plugin or schema registry REST APIs.
Because the rules of forward and backward compatibility are not always intuitive, it can be a good idea to have a test environment with the applications producing and consuming events. This way the effects of registering a new schema and upgrading the applications producing and consuming events can be tested empirically.
Looking ahead
We started out by exploring the similarities between schemas and APIs, and the importance of being able to modify schemas without the risk of breaking consumer applications. We went into the details of what compatibility really means for schemas and events (and why it’s so critical!), and then discussed multiple ways a schema registry helps build resilient data pipelines by managing schemas and enforcing compatibility guarantees.
You can explore Schema Registry in more depth by signing up for Confluent Cloud, Apache Kafka as a fully managed event streaming service. Confluent Cloud includes not just a fully managed schema registry, but also a web-based UI for creating schemas, exploring, editing, and comparing different versions of schemas.
What to read next
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Deep Dive into Handling Consumer Fetch Requests: Kafka Producer and Consumer Internals, Part 4
Dive into the inner workings of brokers as they serve data up to a consumer.



Introducing Apache Kafka® 3.9
We are proud to announce the release of Apache Kafka 3.9.0. This is a major release, the final one in the 3.x line. This will also be the final major release to feature the deprecated Apache ZooKeeper® mode. Starting in 4.0 and later, Kafka will always run without ZooKeeper.