New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Deep Dive into ksqlDB Deployment Options
The phrase time value of data has been used to demonstrate that the value of captured data diminishes by time. This means that the sooner the data is captured, analyzed and acted upon, the more value it brings for the user. To process and act on the data as soon as it is available, many enterprises employ stream processing frameworks.
However, there is a high barrier of entry to using many stream processing systems. Users of such systems need to have deep technical expertise in software design and implementation along with knowledge of programming languages such as Java or Scala. By lowering this barrier of entry, stream processing becomes available to a wider audience, simplifying timely processing and ability to act on incoming data.
To achieve this goal, we developed ksqlDB, the event streaming database purpose-built for stream processing applications. We developed ksqlDB on top of Kafka’s Streams API so we can inherit all of the advantages that Kafka Streams provides, including its advantages for operations and deployment.
Understanding the execution model of Kafka Streams will help with understanding the ksqlDB execution model and hence ksqlDB’s deployment options. To help you understand how it works, I will first provide a brief overview of Kafka Streams and its execution model, and then talk about ksqlDB deployment options.
This post also summarizes my talk ksqlDB 201: A Deep Dive into Query Processing from Kafka Summit London 2018, where I described how each deployment option in ksqlDB executes your statements.
Kafka Streams API, a brief introduction
Kafka Streams is a client library for writing stream processing applications in a JVM language such as Java or Scala. These applications are standard JVM applications and do not need a special processing cluster—instead, you write, test, build, package and deploy them like any other JVM application. A common pattern for applications using Kafka Streams is to read the input data from one or more source topics in Apache Kafka® and, after processing, to write the resulting data into one or more output topics.
One of the main benefits of using Kafka Streams for implementing stream processing applications is its simple, easy-to-integrate yet powerful execution model. Unlike other stream processing frameworks, Kafka Streams does not require the deployment of a separate processing cluster to run your streaming application—all you need is your existing Kafka cluster, which is the place where your data resides.
In addition, Kafka Streams is tightly integrated with Kafka. This allows Kafka Streams to delegate some important aspects of distributed stream processing to Kafka. The foundation of Kafka Streams’ elasticity, scalability, fault tolerance and persistence is provided by Kafka, which results in much simpler execution model for Kafka Streams applications.
Note that stream processing applications built with Kafka Streams do not run inside the Kafka brokers—you run your applications next to your Kafka clusters.
You may run a Kafka Streams application as one or more application instances, where each instance is responsible for processing a portion of the input data. The workload is assigned to the app instances based on the partitions in the input topics, and each partition will be consumed by only one instance.
One of the main operations in distributed data processing systems is data shuffle. Many stream processing frameworks implement the shuffle operation in their processing cluster using a custom many-to-many network communication protocol among all processing nodes. In other words, they are implementing their own messaging layer.
But building a messaging layer that is robust, scalable and fault tolerant is a very challenging endeavor. Instead of following such an approach, Kafka Streams uses a battle-tested solution for large-scale messaging: Kafka!
Kafka Streams uses Kafka topics to perform tasks such as the shuffle operation as well as data sharing across processing nodes (the various instances of your application). This model greatly simplifies the execution and delegates the shuffle complexity to your Kafka cluster.
Consider the following example: We have a clickstream topic with the schema clicktime, pageid and userid for the Kafka message values. The key of the messages is the same as pageid. Now assume we want to count clickstreams per userid. This will require a shuffle operation in which we gather all messages with the same userid at the same place to perform the counting for that userid.
Kafka Streams performs such operations by re-partitioning the input topic, when needed, into a new internal topic where the message key is userid. So now, in the internal topic, we have all the messages with the same userid in the same partition, and we can perform the counting over each partition for each userid.
Kafka Streams uses Kafka’s consumer group protocol for reading and writing messages. This makes deployment of Kafka Streams applications much easier. When you have a Kafka Streams application, you can run multiple independent instances of your application, which will collaboratively process the application’s input data.
Since we use the consumer group protocol, each instance will read a portion of input data and generate a portion of the results. You can scale out (more compute power) or scale in your application (less compute power) by simply adding or removing existing instances, respectively.
Here, the consumer group protocol ensures that the new instances will receive portions of the input data to process. Adding a new instance to your application will trigger a rebalance operation in the consumer group protocol and result in assignment of some partitions from source topics to the newly joined instance.
Similarly, if you scale in your application or lose some of its instances due to machine failures or crashes, the consumer group protocol will ensure that their load is migrated to and redistributed among the remaining instances. Again, this is done using a rebalance operation in the consumer group protocol. Note that in this model, the application instances are not aware of each other. They process the input data and generate the results independently.
Now that we’ve had a quick overview of Kafka Streams and its execution model, let’s move on to how all this powerful functionality helps ksqlDB to perform stream processing by running continuous streaming queries.
ksqlDB deployment options
As I mentioned, we have implemented ksqlDB on top of the Kafka Streams API. This means that every ksqlDB query is compiled into a Kafka Streams application. Therefore, ksqlDB queries follow the same execution model of Kafka Streams applications.
A query can be executed on multiple instances, and each instance will process a portion of the input data from the input topic(s) as well as generate portions of the output data to output topic(s). Based on this execution model and depending on how we want to run our queries, currently, ksqlDB provides two deployment options.
Option 1: Headless ksqlDB deployments
The simplest deployment mode for ksqlDB is the headless mode. We also call this application mode. In the headless mode, you write all of your queries in a SQL file, and then start ksqlDB server instances with this file as an argument. Each server instance will read the given SQL file, compile the ksqlDB statements into Kafka Streams applications and start execution of the generated applications.
The execution model is exactly the same as the Kafka Streams execution model except that in this case, instead of one application, we have multiple applications, one per query, running in each ksqlDB server instance. All the instances run the same set of statements, and the load is distributed among them in the same way as for Kafka Streams applications.
As an example, consider the ksqlDB quick start example where we have a pageview stream and a users table. Let’s say we want to build an application that continuously computes the number of page views for every gender and region. We first create our SQL file with the following content:
CREATE STREAM pageviews (viewtime bigint, userid varchar, pageid varchar) WITH (kafka_topic='pageviews', value_format='JSON');CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR) WITH (kafka_topic='users', value_format='JSON', key = 'userid');
CREATE STREAM pageviews_enriched AS SELECT users.userid AS userid, pageid, regionid, gender FROM pageviews LEFT JOIN users ON pageviews.userid = users.userid;
CREATE TABLE pageviews_regions AS SELECT gender, regionid , COUNT(*) AS numusers FROM pageviews_enriched WINDOW TUMBLING (SIZE 30 SECONDS) GROUP BY gender, regionid;
Let’s also assume we saved the above file in my_counter_pipeline.sql. Now that we have our SQL file, we can start our ksqlDB cluster by starting a ksqlDB server instance and passing the query file as an argument. Assuming you have the ksqlDB commands in your $PATH, you can start a ksqlDB server instance as follows:
$ ksql-server-start /path/to/ksql-server.properties --queries-file /path/to/my_counter_pipeline.sql
Note that we also pass the server configuration file ksql-server.properties. An important configuration setting that you must define is ksql.service.id, the service ID for the ksqlDB cluster, which represents the unique prefix for the Kafka Streams applications generated by ksqlDB for its queries.
You need to make sure that for each ksqlDB cluster you start, the ksql.service.id property is the same for all instances. You must likewise make sure that different ksqlDB clusters use different ksql.service.id. The following picture shows a ksqlDB cluster with three server instances:
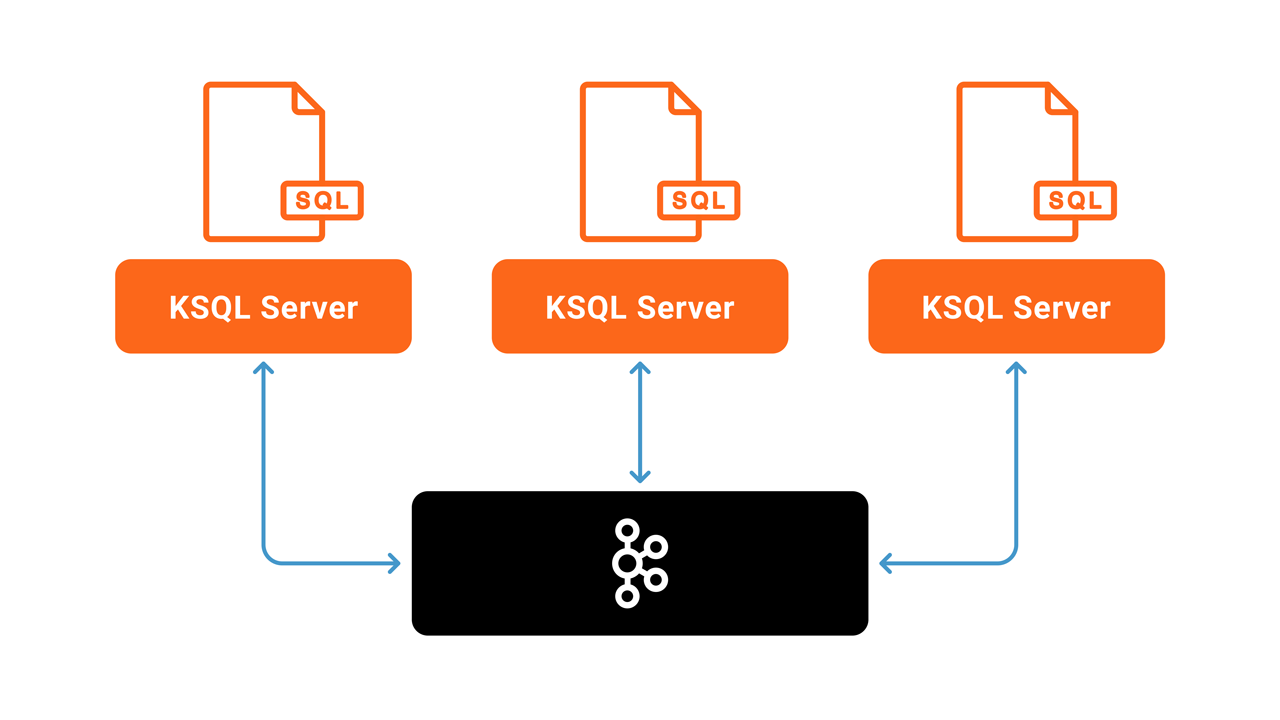 You can, of course, start additional server instances, depending on the resource requirements of your queries. You can verify the output data of your queries by inspecting the contents of the generated output topics. For instance, the count values above will be written into a Kafka topic named PAGEVIEWS_REGION.
You can, of course, start additional server instances, depending on the resource requirements of your queries. You can verify the output data of your queries by inspecting the contents of the generated output topics. For instance, the count values above will be written into a Kafka topic named PAGEVIEWS_REGION.
We recommend headless ksqlDB for production deployments because it provides the best isolation among different use cases, e.g., separating team A’s ksqlDB cluster(s) from team B’s. Furthermore, in headless configuration, ksqlDB disables interactive access (see next section) to servers via the ksqlDB REST API, ksqlDB CLI and Confluent Control Center in order to minimize accidents and mistakes caused by human operators.
Option 2: Interactive ksqlDB deployments
The other option for running ksqlDB is interactive mode, in which you interact with the ksqlDB servers through a REST API either directly via your favorite REST clients, through ksqlDB CLI or through Confluent Control Center.
Here, you can interactively explore the existing topics in your Kafka cluster, write queries, inspect their results in real time and more. You can also share an interactive ksqlDB cluster so that users can see and use each other’s streams and tables. In this mode, you start the desired number of servers for your ksqlDB cluster and then interact with them through the ksqlDB REST API. We provide two clients out of the box for ksqlDB’s REST API:
- Confluent Control Center, which you can use from your web browser
- ksqlDB CLI, which you can use from a terminal
Unlike the headless mode, where each server already knows all the queries it’s supposed to run at the time of startup (via the SQL file), interactive ksqlDB servers in the same ksqlDB cluster share the ksqlDB statements being executed using a special Kafka topic called the ksqlDB cluster’s command topic.
When a ksqlDB server is started in interactive mode, it first checks for its cluster’s command topic. The command topic name is inferred from the ksql.service.id setting in the server configuration file. If the command topic does not exist, the ksqlDB server creates it and then subscribes to it. If the topic already exists, the server subscribes to the command topic, and reads and executes all the statements from the beginning of the topic.
The following figure depicts an interactive ksqlDB cluster with three servers:
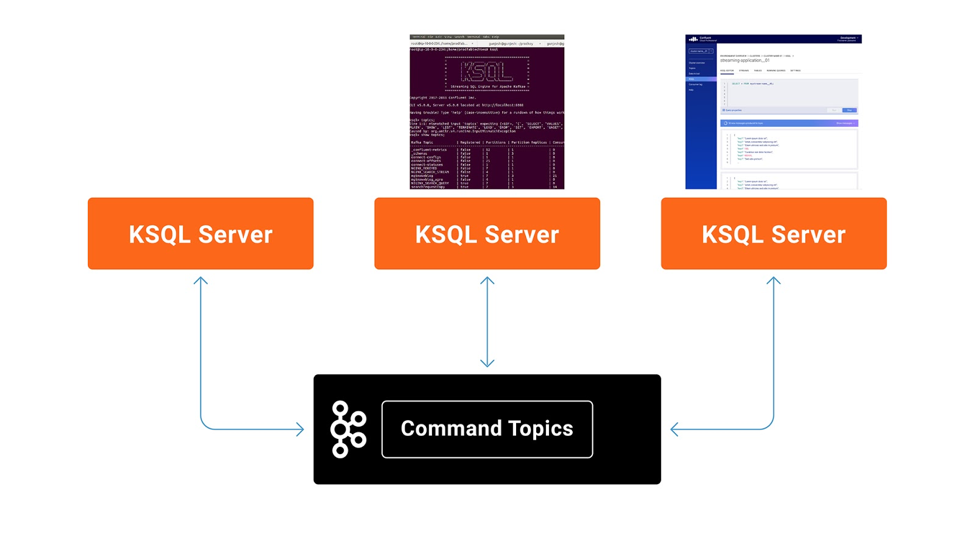
When a ksqlDB server receives a new ksqlDB statement via the REST API, it first validates the statement. If the statement is valid, the server then writes the statement into the ksqlDB cluster’s own command topic. Whenever a new statement is written into the command topic, all the servers of the same ksqlDB cluster will read the new statement from the topic and execute it.
As you can see, the command topic ensures that all ksqlDB server instances will read and execute the same set of ksqlDB statements in the same order. This guarantees that all the servers will be in the same state.
If any of the ksqlDB servers fail while running queries, the remaining servers will coordinate and run the failed server’s workload the same way that Kafka streams applications handle failures, as described earlier. If we need more resources, we can scale out the ksqlDB cluster by simply adding new instances of the server with the same ksql.service.id. The newly added servers will read all the statements in the cluster’s command topic and then execute them in the same order.
Similar to Kafka Streams applications, the new servers will take a portion of the workload from the other servers to run. If we need to scale down, we simply shut down the desired number of ksqlDB servers, and the workload for the eliminated servers will be distributed among the remaining servers.
Summary
ksqlDB currently provides two deployment options: interactive ksqlDB and headless ksqlDB. Each option provides distinct properties to deploy and run continuous streaming queries. These options allow users to make the right deployment decisions for their organizational as well as technical needs.
Looking ahead, we have designed ksqlDB in such a way that we can add further options for orchestrating the ksqlDB query execution engines in the future. We are also looking into query optimization opportunities in each of these deployment options. We are especially keen on looking into multi-query optimizations in the current deployment options.
Unlike traditional store and query systems where the queries have a short lifespan, continuous queries run indefinitely in streaming systems such as ksqlDB, which makes multi-query optimization even more appealing. If these are interesting challenges for you that you’d like to help tackle, check out our career page for open engineering positions at Confluent!
Interested in more?
- Download the Confluent Platform, the leading distribution of Apache Kafka
- Learn more about ksqlDB, the successor to KSQL, and see the latest syntax
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.