[Demo] Design Event-Driven Microservices for Cloud → Register Now
Announcing the Confluent Q3 ’21 Release
The Confluent Q3 ‘21 release is here and packed full of new features that enable the world’s most innovative businesses to continue building what keeps them on top: real-time, mission-critical services fueled by data in motion.
This is our first quarterly release for Confluent, which is a new cadence we’re introducing to provide our customers with a single resource to learn about the accelerating number of new features we’re launching. We’ll also point you toward the resources you need to start using the features right away.
In this release, you’ll also find a description of what Confluent sees as the key pillars of a best-in-class service for data in motion, and how we’re delivering on each of them to support our customers.
Here’s an overview of what you’ll find in this blog post:
- Cloud-native, complete, and everywhere
- The Q3 ‘21 release summary
- Learn about the new features:
- Cloud Cluster Linking
- ksqlDB pull queries
- 2 new fully managed connectors
- Infinite Storage for Google Cloud
- Getting started
Cloud-native, complete, and everywhere
Depended upon by over 70% of the Fortune 500 today, Apache Kafka® has become the industry standard for real-time event streaming.
However, to move beyond event streaming and capture the full value of data in motion, you need a solution that goes beyond open source tools to help you focus on what matters most: building, launching, and running the applications that differentiate your business.
That solution is what we’ve built here at Confluent—we’re delivering a fully managed solution for Apache Kafka that is cloud-native, complete, and available everywhere. These three pillars are paramount to a data-in-motion platform, representing the capabilities that you need to drive key business outcomes and achieve aggressive IT initiatives.
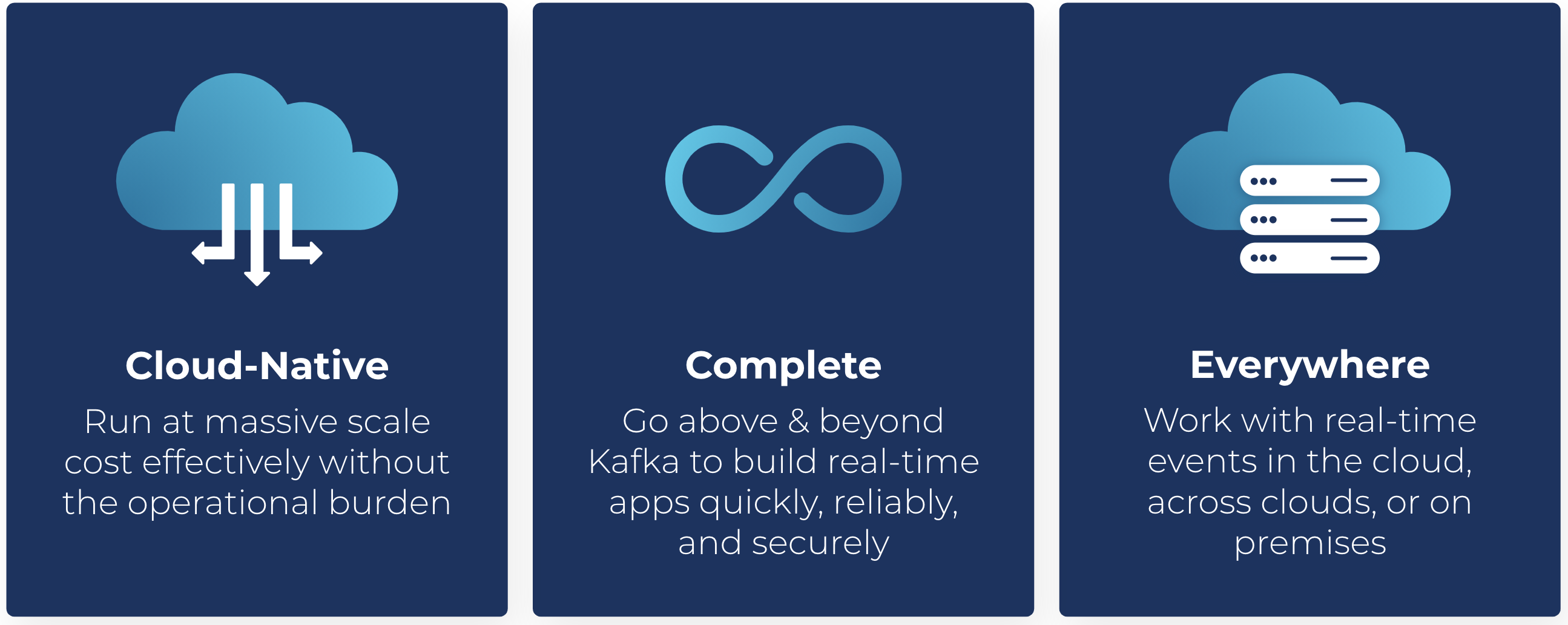
Cloud-native: We’ve re-engineered Kafka to provide a best-in-class cloud experience, for any scale, without the operational overhead of infrastructure management. Confluent offers the only truly cloud-native experience for Kafka—delivering the serverless, elastic, cost-effective, highly available, and self-serve experience that developers expect.
Complete: Creating and maintaining real-time applications requires more than just open source software and access to scalable cloud infrastructure. Confluent makes Kafka enterprise ready and provides customers with the complete set of tools they need to build apps quickly, reliably, and securely. Our fully managed features come ready out of the box, for every use case from POC to production.
Everywhere: Most organizations today run in multiple regions and environments. Confluent meets our customers everywhere they need to be—powering and uniting real-time events across regions, across clouds, and across on-premises environments.
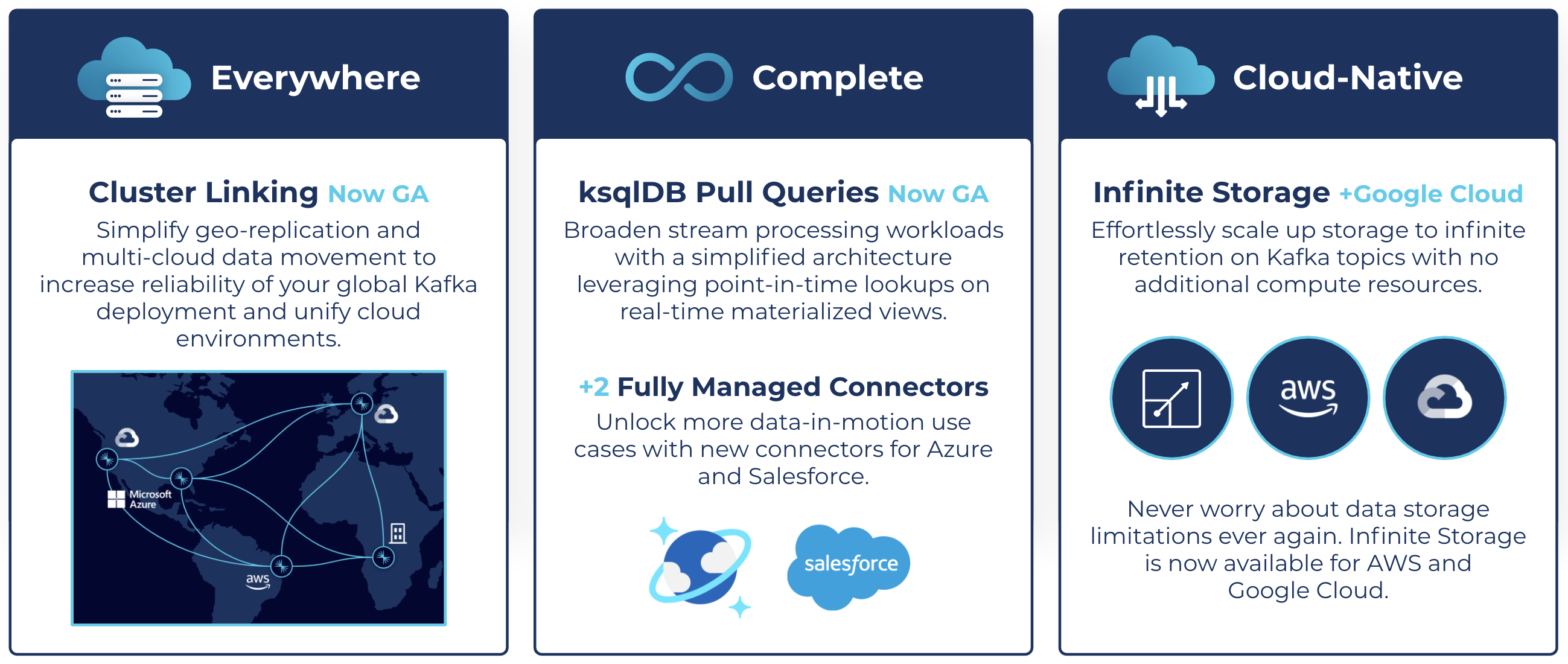
Within each of our quarterly releases, you’ll learn about our development in these three pillars of Confluent. Let’s take a look at what’s in the Q3 ‘21 release starting with a major addition to our everywhere capabilities: the general availability of Cloud Cluster Linking.
The Confluent Q3 ‘21 release
Everywhere: Cloud Cluster Linking
Building modern data systems that span environments isn’t easy. Confluent is changing that with the general availability (GA) of fully managed Cluster Linking. We’ve simplified geo-replication and multi-cloud data movement, enabling you to increase the reliability of your global Kafka deployment and to unify your cloud environments. Cluster Linking equips you with an easy-to-use solution for global data replication, disaster recovery readiness, and simple workload migrations. Data in motion can power every cloud application—across public and private clouds—with linked Kafka clusters that sync in real time.
Continue reading about Cloud Cluster Linking
Complete: ksqlDB pull queries
To deliver the real-time applications that today’s businesses need, you need access to a suite of tools that take you beyond just Kafka. That’s why Confluent has developed tools like ksqlDB, the database purpose-built for stream processing applications.
With ksqlDB, you can process and enrich streams of data flowing through Apache Kafka and serve continuous streaming queries against its derived tables and streams. These queries are known as push queries, which push out ongoing, incremental query results to clients in real time.
However, many applications cannot rely on push queries alone; they also require traditional point-in-time lookups of static information. Now generally available, ksqlDB’s pull queries enable point-in-time lookups on real-time materialized views. This allows customers to simplify their stream processing architecture and broaden the kinds of stream processing workloads they can support, ultimately expanding the possible stream processing applications that they can build.
Continue reading about ksqlDB pull queries
Complete: New fully managed connectors
Data is distributed across systems, and that can make it difficult to build applications. Confluent makes it easy to access data across your entire business through a library of fully managed source and sink connectors. As part of the Q3 ‘21 release, we’re excited to announce two new connectors to help businesses set more of their data in motion: Azure Cosmos DB Sink and Salesforce Platform Events Source connectors.
Continue reading about new connectors
Cloud-native: Infinite Storage
Provisioning Kafka clusters and retaining the right amount of data is operationally complex and expensive. With Infinite Storage, now generally available for Google Cloud (alongside AWS) for Standard and Dedicated clusters, Confluent solves this problem by enabling customers to elastically retain infinite volumes of data while only paying for what they use.
Having both real-time and historic data in Kafka allows for more advanced use cases based upon historical context, as well as compliance with regulatory requirements for data retention. It also helps Kafka serve as a central system of record across the entire business. With current and historical information in the same place, businesses are able to take faster, better informed action.
Continue reading about Infinite Storage
Now let’s take a deeper dive into the individual product launches within the release. Already seen enough and ready to learn how to put these new tools to use? Register for the Confluent Q3 ‘21 release instructional demo series.
Learn about the new features:
Everywhere: Cloud Cluster Linking
Simplify geo-replication and multi-cloud data movement with Cluster Linking
To fuel their global architectures with real-time data, businesses need a fully managed, easy-to-use, and globally consistent solution for connecting independent clusters across regions and clouds.
With fully managed Cluster Linking, Confluent simplifies geo-replication and multi-cloud data movement, enabling customers to increase the reliability of their global Kafka deployments and unify cloud environments. Teams across the business are equipped with perfectly mirrored and globally consistent topic replication with no additional infrastructure. Data in motion can power every cloud application—across public and private clouds—with linked Kafka clusters that sync in real time.
- Build a globally connected and multi-cloud Kafka deployment with operational simplicity
- Increase the reliability of mission critical applications by minimizing data loss and downtime during public cloud provider outages
- Accelerate project delivery times and build more value with simple, global availability of all your real-time data

Bring data in motion to every cloud application—across public and private clouds—with linked Kafka clusters that sync in real time.
“In order to meet new architectural requirements and reduce costs, we needed a solution for migrating data and existing workloads to a new Kafka cluster,” said Zen Yui, data engineering manager, Namely. “We completed this migration quickly and easily using Confluent’s Cluster Linking. With perfectly mirrored topic data/metadata replication, offset preservation, and support for non-Java consumers, the migration was even more simple than we expected.”
Historically, moving data between Kafka clusters required additional replication tools like MirrorMaker 2 and Replicator. These solutions can be costly to manage, make it hard to hit Recovery Time Objectives (RTOs), and most notably, hinder agile development and delay application deliveries. Based on Kafka Connect, these replication tools introduce a number of challenges to multi-region and multi-cloud architectures and cloud migrations, including:
- Deploying a separate system (Kafka Connect) to manage replication increases infrastructure costs, operational burden, and architectural complexity.
- It’s nearly impossible to reason about the state of a system and maintain a “source of truth” because offsets are not consistent between clusters. The effort required to establish offset matching in the event of a failover can make hitting recovery time objective (RTO) targets difficult and negatively impact overall system performance.
Cluster Linking is the next-generation of geo-replication technology, eliminating legacy middle-system approaches that require additional infrastructure. Two clusters can replicate data directly, bidirectionally, and consistently. With just a few simple commands, event data is readily available throughout an entire business. Consumer application offsets are mirrored with no extra plugins or tooling for Kafka clients. System architects can design global environments with improved data consistency guarantees while system admins can operate and monitor these distributed systems with ease, regardless of cloud provider. Teams are able to both improve and simplify critical operations for the business:
- Global data replication
Cluster Linking offers a cost-effective, secure, and performant data transport layer across regional clusters and public cloud providers. This helps you build highly available, globally connected, and multi-cloud Kafka deployments with minimal operating effort. Because Kafka messages can be read by many consumers, data can be replicated once from one region or cloud provider to another, and then be read by any applications or data store in each cloud. This reduces integration time, saves substantial cloud networking costs, and improves application performance. - Regional disaster recovery
Cluster Linking delivers near-real-time disaster recovery for your Kafka deployment through an easy-to-use data mirroring experience. In the event of a major service disruption—such as a regional outage of a public cloud provider—a single Confluent Cloud CLI or API command lets you fail over to perfectly mirrored Kafka topics on a separate region or different cloud provider altogether, allowing teams to easily meet RTOs and maintain SLAs.We’ve built tools specifically designed to assist system operators with preparation for and management of topic failovers in the event of a disaster recovery procedure:
- Confluent Cloud Metrics API: At any point in time, you can monitor lag directly through the Confluent Cloud Metrics API to determine your RPO (recovery point objective)—that is, the amount of data (if any) that is at risk of loss during a failover. Lag details are available at both the link level and topic level. Additionally, through the Confluent Cloud CLI or new REST API for Cluster Linking, you can query aggregate lag for individual topics and even topic partitions.
- Dry run feature: This allows you to preview the results of a topic promotion or failure command without actually executing the change. You can practice and build confidence with failover procedures in advance of an actual disaster scenario.
- Cluster migrations
Cluster Linking provides a prescriptive, low-downtime way to migrate data across different environments. In a planned migration, consumers reading from a topic in one environment can start reading from the same topic in a different environment without any risk of reprocessing or skipping critical messages. And for organizations looking to offload cluster management altogether to the Kafka experts at Confluent, Cluster Linking provides a simple solution to move open source Apache Kafka workloads to our fully managed and cloud-native service, Confluent Cloud.When promoting clusters during migrations, lag monitoring through the Confluent Cloud Metrics API allows you to determine exactly how much longer a destination topic or cluster link has to go until it is fully synced with historical data from the source. With clear knowledge of when syncing is complete, system operators are able to facilitate smooth migrations with no data loss and minimal producer downtime. Additionally, Cluster Linking puts them in control of when each application is moved over, as promotions can be run consumer by consumer and topic by topic, or in batch. This means you can safely promote topics and applications to the new cluster over time, only when you’re ready, and avoid the hardships of attempting an all-at-once full cluster migration.
Ready to learn how to link clusters within your system directly from Confluent’s expert, Luke Knepper? Register for the Confluent Q3 ‘21 release demos. Once you’ve registered, be sure to check out the Cluster Linking quick start guide.
Complete: ksqlDB pull queries
Broaden stream processing capabilities with ksqlDB pull queries
Here at Confluent, we believe building applications on top of data in motion should be as easy as building CRUD applications on top of a regular database. That’s why we built ksqlDB, the database purpose-built for stream processing applications.
We’ve previously only supported push queries on ksqlDB. However, many stream processing applications require traditional point-in-time lookups of static information. Consider a ride sharing app—the driver’s position and ETA need to be continuously updated in real time, but the driver’s name and the price of the ride only need to be determined once. Up until now, supporting this second query type required users to send derived tables and streams to a separate data store that could serve these point-in-time lookups, resulting in increased architectural complexity and operational burden and forcing teams to work across multiple systems to build a single app.
Helping solve this challenge is why we’re excited to introduce the general availability of ksqlDB pull queries on Confluent Cloud. Pull queries support point-in-time lookups directly on derived tables and streams, complementing the existing functionality of push queries. This functionality enables you to eliminate that second datastore, simplifying your architecture and enabling you to use a single solution to build a complete stream processing app, all with simple and widely familiar SQL syntax.
Together, these complementary push and pull patterns provide flexibility and enable a broad class of end-to-end stream processing workloads and applications.
- Enable a broad class of end-to-end stream processing workloads to power your stream processing applications with simple and familiar SQL syntax
- Simplify your stream processing architecture with a single solution that supports stream processing and serves both push and pull queries
“Our customers expect instant updates on their order status and what’s in stock, which makes processing inventory data in real time a must-have for our business,” said Chirag Dadia, director of engineering, Nuuly. “ksqlDB pull queries enable us to do point-in-time lookups to harness data that is critical for real-time analytics across our inventory management system. Now, we can pinpoint exactly where each article of clothing is in the customer experience.”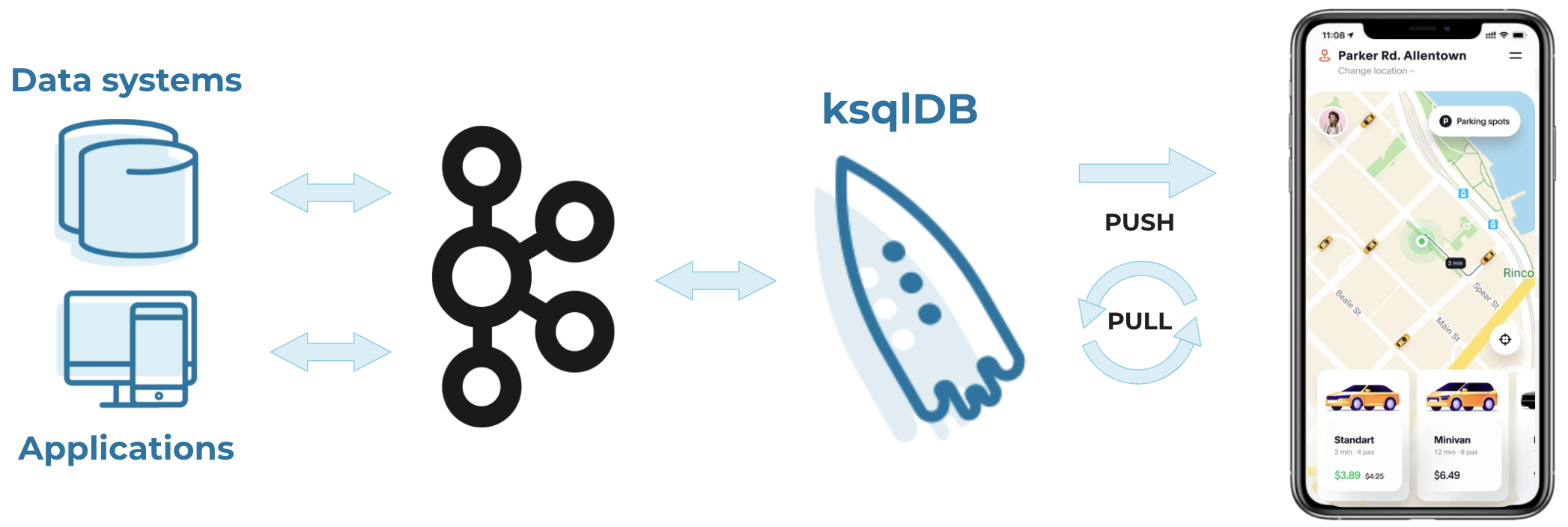
ksqlDB simplifies the underlying architecture to easily build innovative, streaming apps.
Complete: New connectors
Set more data in motion with new fully managed connectors for Azure Cosmos DB and Salesforce
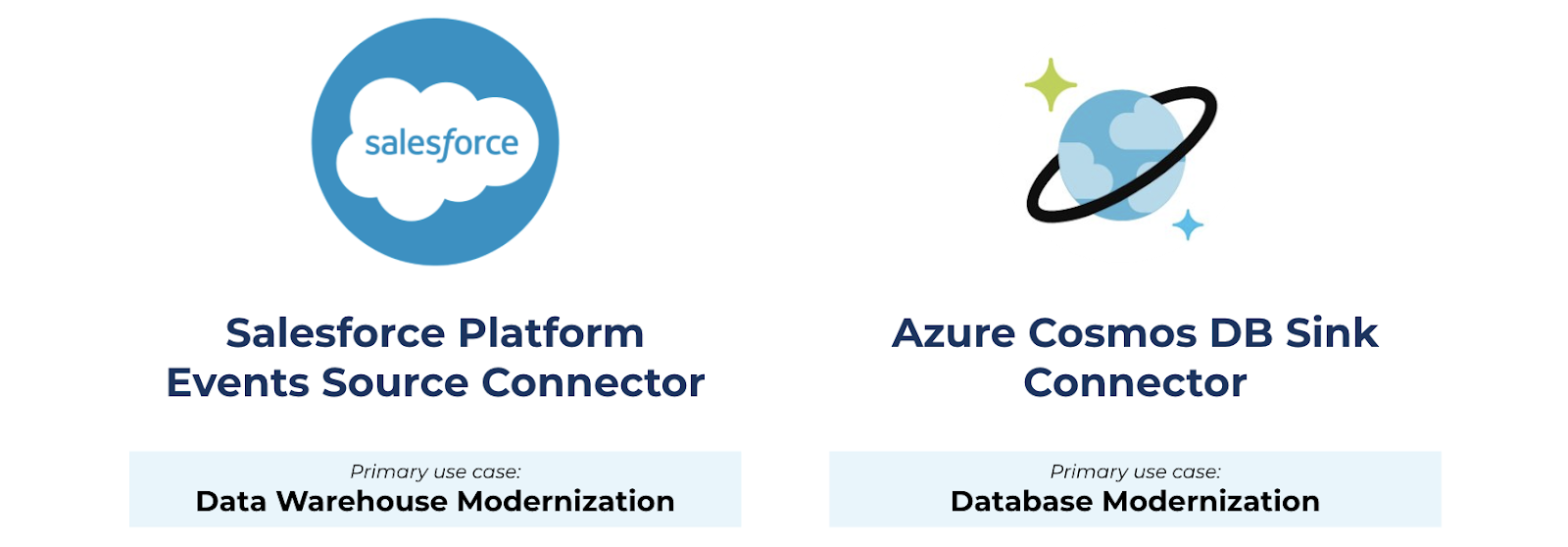
Confluent is adding two new fully managed connectors for modern SaaS platforms and cloud ecosystems.
Our connector portfolio helps you modernize and future-proof your data infrastructure, giving you the flexibility to share data broadly and build across any environment. Ready to use straight out of the box, these fully managed connectors save you 3–6 months of engineering development, as well as ongoing operational and maintenance efforts, freeing you instead to focus on building value-add products and apps that drive the business forward.
These newly released connectors strengthen two primary use cases: integrating modern SaaS-based applications with your downstream cloud data warehouse and using Confluent as a data pipeline to modernize your databases.
- Data warehouse modernization: Integrate even more cloud-based SaaS data with your cloud data warehouse using the fully managed Salesforce Platform Events Source connector and deliver business intelligence, analytics, and enriched customer experiences. When used in conjunction with Confluent’s pre-built sink connectors for Snowflake, BigQuery, and Redshift, the latest data from Salesforce can be shared synchronously with your cloud data warehouse of choice. The new connector also complements our existing Salesforce CDC Source connector, enabling you to unlock valuable customer data in whichever method better suits your use case.
- Database modernization: Migrate to a modern, cloud-native database using the fully managed Azure Cosmos DB Sink connector, enabling high performance, automatic scaling, and real-time use cases like fast and scalable IoT device telemetry, real-time retail services, and critical applications with distributed users. With Confluent, you can offload data sitting on your legacy databases across different environments and stream the data to Azure Cosmos DB in real time, breaking data silos, improving your development velocity, eliminating operational burdens, and reducing the risk of downtime.
Cloud-native: Infinite Storage
Enhance data-in-motion apps with Infinite Storage and rich historical context
While real-time data is powering a new frontier of competitive advantages, many business decisions and customer applications need historical context in order to provide more accurate insights and better experiences. Traditionally, businesses have needed to over-provision Kafka clusters to meet their needs for data storage and have had to overpay for more infrastructure and compute than necessary. Or conversely, they skimp on storage in order to cut costs and run the risk of cluster downtime, data loss, and a possible breach in data retention compliance.
With Infinite Storage, now generally available for Google Cloud (alongside AWS) for both Standard and Dedicated clusters, you never have to worry about data storage limitations again. You can offer business-wide access to all of your data while creating an immutable system of record that ensures events are stored as long as needed. Companies building event-driven applications with Confluent can easily scale their apps and use cases without having to worry about horizontal cluster scaling, disk capacity, or the high storage costs that traditionally come with retaining massive amounts of data. You only pay for storage used rather than storage provisioned.
- Transform Kafka into your central nervous system for all events with infinite retention in Confluent Cloud
- Harness the full power of Kafka to infinitely retain events without ever pre-provisioning or paying for unused storage
Broadening your Kafka data set with Infinite Storage allows for the development of advanced use cases requiring deep historical context, for example, a lifetime customer transaction history log for financial institutions or clickstream records filtered by product for a retailer. Additionally, you can achieve regulatory requirements for data retention while ultimately establishing Kafka as the central system of record tracking events across your entire business.
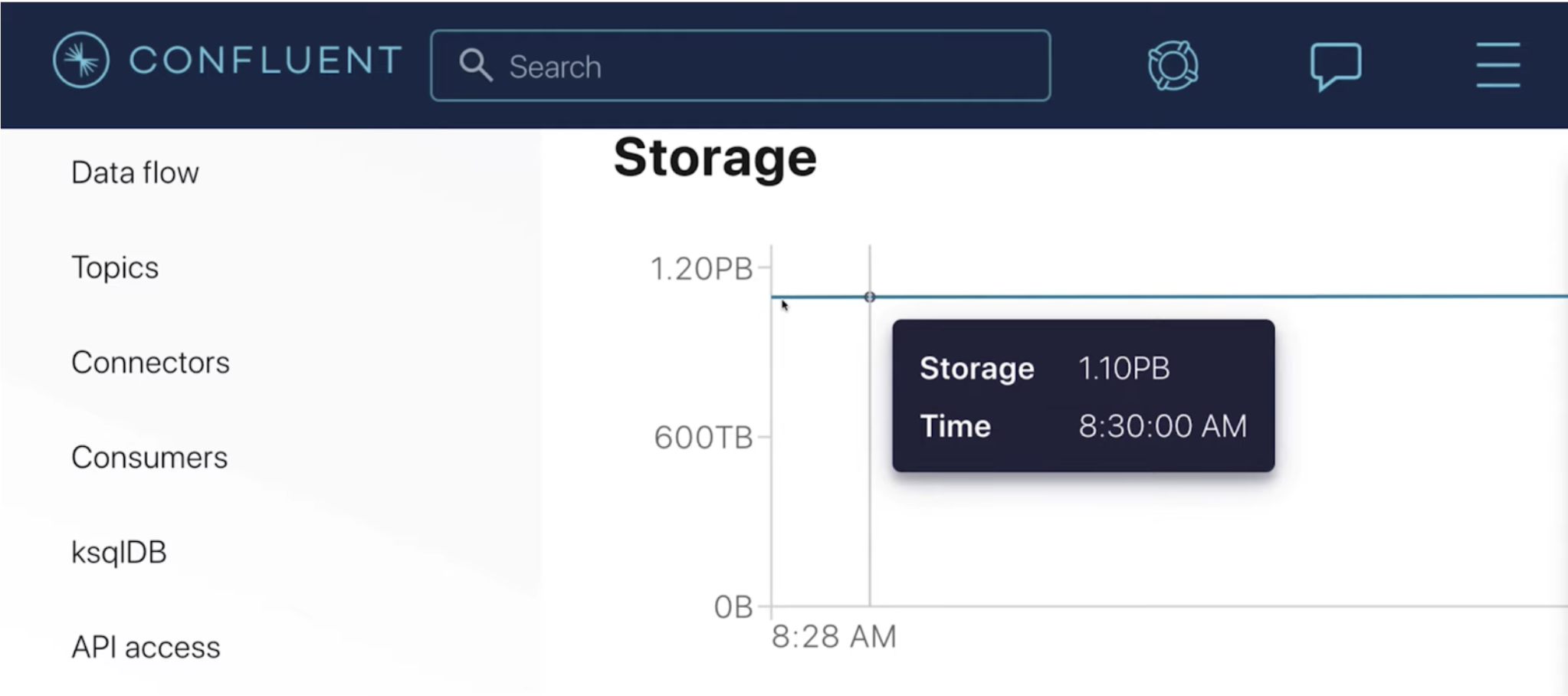
Infinite Storage enables you to elastically retain infinite volumes of data while only paying for the storage that you actually use.
Start building with the Confluent Q3 ‘21 release
Ready to get started? Register for the Confluent Q3 ‘21 release demos for quick guidance on how to get up and running with these features. This four-part webinar series will provide you with once-a-day, bite-sized tutorials for how to get started with the all latest capabilities available on the platform.
If you’ve not done so already, make sure to sign up for a free trial of Confluent Cloud and pick up a little something extra with promo code Q3CLOUD200.
Learn more about Confluent Cloud updates within the release notes and keep your eyes open for the upcoming Q4 release!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Amazon OpenSearch Ingestion Adds Support for Confluent Cloud as Source
Discuss how to use OpenSearch Ingestion to integrate Confluent with Amazon OpenSearch.


Best Practices for Confluent Terraform Provider
The blog post delves into best practices and recommendations for utilizing the Confluent Terraform Provider. It offers insights on efficiently provisioning resources within Confluent Cloud infrastructure while ensuring adherence to industry standards. Additionally, it provides a GitHub repository...