Build Predictive Machine Learning with Flink | Workshop on Dec 18 | Register Now
A Beginner’s Perspective on Kafka Streams: Building Real-Time Walkthrough Detection
Here at Zenreach, we create products to enable brick-and-mortar merchants to better understand, engage and serve their customers. Many of these products rely on our capability to quickly and reliably detect when a patron walks in and walks out of the store.
One key metric we provide our merchants is the walkthrough count: the number of walk-ins that happen as a result of an online engagement with the patron (marketing email, SMS, Facebook ad, etc.) via Zenreach. We call this a Zenreach Message.
Recently, we began using Kafka Streams to generate these walkthrough counts. This post describes our use case, our architecture and the lessons we learned along the way.
Our use case at Zenreach
Previously, a Python script would periodically run and read walk-in data from Cassandra and Zenreach Message data from MongoDB, then write walkthrough counts to MongoDB. From there, other Zenreach services would use that data for our various features.
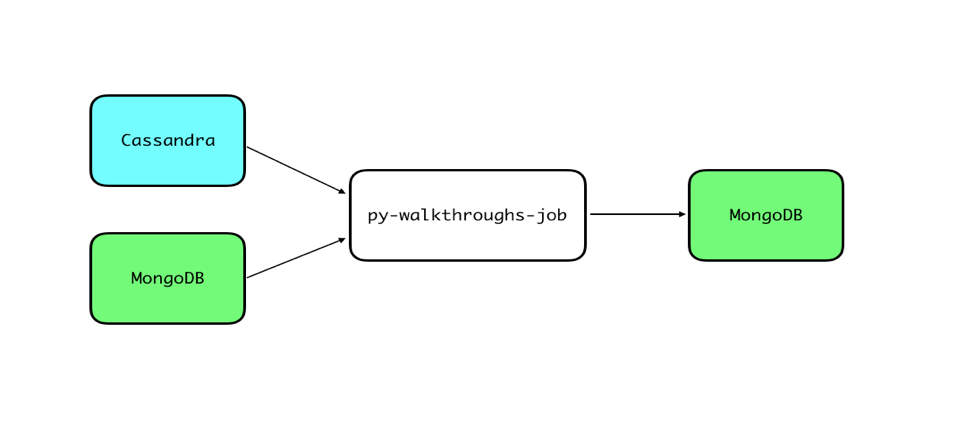
This Python script ran on a single machine, and is from the early days of the company. However, this script didn’t scale since it cannot run in a distributed manner. As a result, this Python job ends up flapping—crashing and restarting regularly in production depending on the load it needs to process.
Second, the Python script puts read pressure on MongoDB and Cassandra, because it has to query the databases for each batch of walk-ins and Zenreach Messages. MongoDB and Cassandra are our primary databases for serving customer read queries. So we wanted to remove the additional read pressure added by this job, which currently competes for resources with our customers.
For these reasons, we wanted to move to a streaming solution—specifically, Kafka Streams. We already switched to Kafka Streams for walk-in detection, which my teammate Eugen Feller explained in a previous post.
Generally, we like that we don’t have to maintain additional infrastructure (e.g., Amazon EMR) like we’d have to for Spark Streaming.
How the walkthrough system works
As merchants send Zenreach Messages to customers, a first service emits the corresponding messages to the zr-messages-topic. As customers produce walk-ins, a second service emits these walk-ins to the walkins-topic.
Since these topics already exist, moving away from Cassandra and MongoDB is only natural. We used Kafka Streams to implement two new services: WalkthroughsGenerator and WalkthroughsMongoExporter (see diagram).
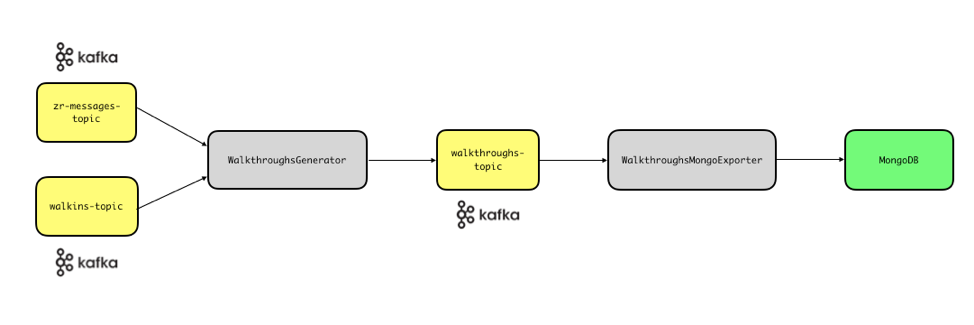
The WalkthroughsGenerator service reads Zenreach Messages and walk-ins from these two topics, and outputs walkthroughs to the walkthroughs-topic.
The WalkthroughsMongoExporter service reads the walkthroughs-topic and updates MongoDB, from which other downstream consumers (e.g., the dashboard) read. Note that Kafka Connect can also be used to write data out to external systems. However, at the time of starting this project Kafka Connect did not support protobuf payload. Moreover, we did not want to provision additional infrastructure.
A closer look at the WalkthroughsGenerator
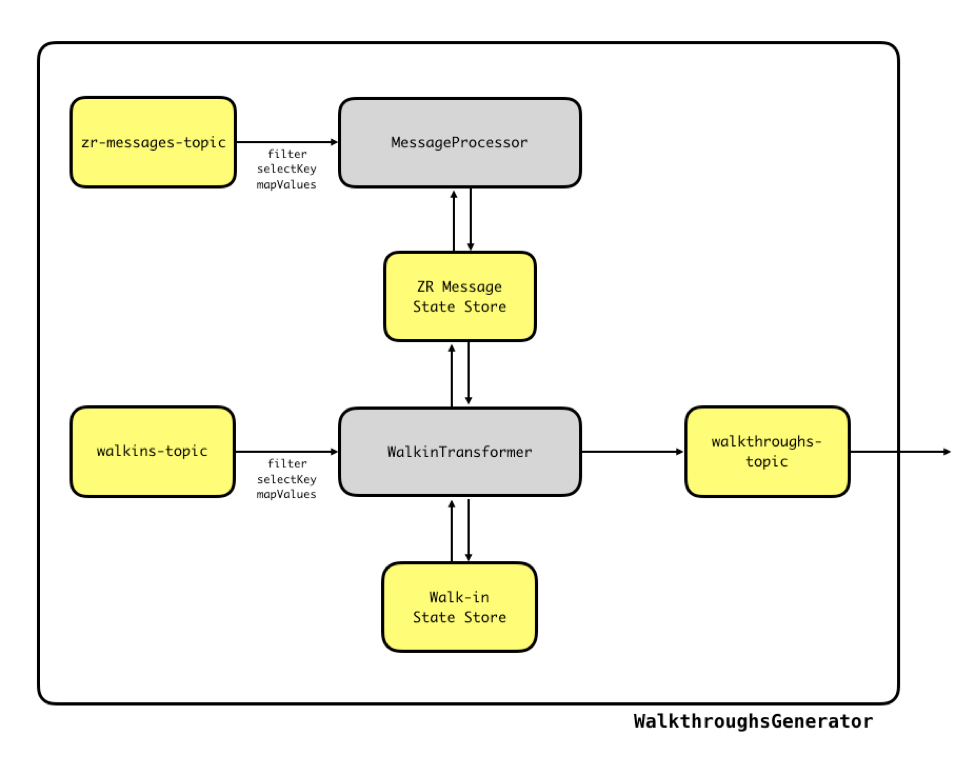
The WalkthroughsGenerator service contains all of our streaming logic. After filtering, rekeying and mapping the two input topics, we pass the Zenreach Message events to a MessageProcessor to process them. This processor keeps an updated state store of mappings: mapping from (business_id, customer_id) pairs to lists of Zenreach Messages.
This processor also uses Kafka Streams’ punctuate mechanism to purge old Zenreach Messages in order to keep the state store from growing infinitely.
Then, we pass the preprocessed walk-in events to the WalkinTransformer, which keeps an updated state store of unprocessed walk-ins: (business_id, customer_id) pairs to list unprocessed walk-ins. At regular intervals, punctuate() is called, and the unprocessed walk-ins are converted to walkthroughs through an algorithm, involving the ZR Message State Store.
Lessons learned
As I wrap up my internship at Zenreach, I am happy to report that I have learned a lot. This was my first time using Kafka Streams or doing any kind of stream processing, and hopefully some of the basic lessons I learned will be useful to others who are just getting started with Kafka Streams.
1. The Processor API has its place
In the design stages of this project, I was hooked on the Kafka Streams DSL. To me, the DSL was functional and beautiful and elegant, and the Processor API was icky, so I first wrote an algorithm entirely avoiding the Processor API. In this algorithm, I used a KTable that stored just the latest Zenreach Message by business_id and customer_id.
But then I was introduced to the real-world constraint that Zenreach Message events could arrive out of order (since we wait for receipt of delivery of Zenreach Messages). Even walk-in events can arrive out of order. It turned out that the DSL does not handle out-of-order data in a way that suits our use case.
The design pattern I ultimately used was to store Zenreach Messages and walk-ins in a state store, and process them regularly with punctuate(): a sort of ad hoc batch processing. This pattern isn’t uncommon, judging from the volume of StackOverflow posts with punctuate() questions. So if you’re considering something like this, you’re not alone.
2. Testing punctuation can be tricky
We have previously written unit tests for Kafka Streams applications using Mocked Streams, a Scala library for unit testing our applications without ZooKeeper or Apache Kafka® brokers. However, Mocked Streams doesn’t provide functionality to manually trigger punctuate(), which we use for the WalkthroughsGenerator service. You have to use real brokers to test punctuation, which isn’t ideal.
Another option we considered was embedded-Kafka. Embedded-Kafka is a library that provides an in-memory Kafka instance to run your tests against. While this is more suited for integration tests, we used this in some unit tests to test punctuate. This required us to include Thread.sleep() calls in our code, which is pretty terrible.
For some reason, we missed TopologyTestDriver, which Kafka Streams provides. TopologyTestDriver internally mocks wall clock time, and you can advance wall clock time through method calls, controlling punctuation that way. This is what I recommend. It’s unfortunate that you get less abstraction than with the Mocked Streams or embedded-Kafka library. In any case, this is much better than having Thread.sleep() in your unit tests.
3. Ensure your records are partitioned and co-partitioned correctly
After writing the service and testing it locally, I tested it against production. For some reason, I’d only get 5–10% of the walkthroughs that were supposed to be generated. I fought this for multiple days.
As it turns out, I had made a silly mistake. I assumed the KStream map() method forced a repartition by key, but it didn’t. So when my code would try to process a walk-in, it wouldn’t be able to find corresponding Zenreach Messages. Unfortunately, the documentation doesn’t explicitly call this out, so I missed it. Don’t let this be you! Check that your records are being repartitioned.
I added a through() call to force a repartition before calling process()/transform(), and this fixed this issue.
Here’s another important tip: If you are using state stores inside your transform() calls for joins, it is necessary that the input topics have the same number of partitions.
Kafka Streams won’t complain if you have a mismatched number of partitions (though it will for DSL joins), but it will operate incorrectly. This is because state store contents are not distributed, but are local to stream tasks, each of which corresponds to one stream partition. So when you process a record in a processor’s process() method, the edits you make to the state store actually happen to the state store local to the stream task that the record is being processed by.
Ultimately, I wouldn’t skip understanding Kafka Streams architecture deeply. Here is a place to start. Make sure your records are partitioned and co-partitioned correctly.
Other tips and tricks
Here are some additional points I didn’t realize at the start but are worth noting.
First, there’s always the possibility your Kafka Streams service will need to reprocess old data (e.g., recompute old walkthroughs). To prepare for this, it’s good practice to read from backfill topics you can write to in case backfills are required.
Second, it is possible to store lists as values in state stores (or even output lists to topics). This isn’t ideal, but in case you need it, here’s the SerDe we based ours on.
Third, when a consumer fails and restarts, it consumes messages from the most recently committed offset. Our setup and most setups use the at-least-once setting, because it offers the best tradeoff between throughput and consistency. This is explained more here.
To account for this setting, you need to design your consumer to handle duplicate messages. In other words, you need to design your consumer idempotently. This is easy to miss if you don’t try to understand Apache Kafka at a lower level.
About Apache Kafka’s Streams API
If you have enjoyed this article, you might want to continue with the following resources to learn more about the Kafka Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices
- Walk through the Confluent tutorial for the Kafka Streams API with Docker and play with the Confluent demo applications
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Unify Streaming and Analytical Data with Apache Iceberg®, Confluent Tableflow, and Amazon SageMaker® Lakehouse
Tableflow can seamlessly make your Kafka operational data available to your AWS analytics ecosystem with minimal effort, leveraging the capabilities of Confluent Tableflow and Amazon SageMaker Lakehouse.



Shift Left: Headless Data Architecture, Part 2
Building a headless data architecture requires us to identify the work we’re already doing deep inside our data analytics plane, and shift it to the left. Learn the specifics in this blog.