New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
What is Retrieval-Augmented Generation (RAG)?
RAG is an architectural pattern in generative AI designed to enhance the accuracy and relevance of responses generated by large language models (LLMs). It works by retrieving external data from a vector database at the time a prompt is issued. This approach helps prevent hallucinations, which are inaccuracies or fabrications that LLMs might produce when they lack sufficient context or information.
To ensure that the data retrieved is always current, the vector database should be continuously updated with real-time information. This ongoing update process ensures that RAG pulls in the most recent and contextually relevant data available.
While LLMs excel at text generation, including translation and text summarization, they struggle to generate highly specific information based on real-time data. Retrieval-augmented generation (RAG) addresses this by retrieving external data to provide context for LLMs, enabling them to respond to queries more accurately and relevantly.



Consider an AI chatbot using an LLM without RAG. Without context, trustworthiness, or real-time data, LLMs cannot deliver meaningful value to users.
To improve information precision, RAG systems leverage semantic search and vector search. This allows context from retrieved data to enhance the relevance and accuracy of responses.
By matching input parameters with real-time data, RAG can address queries that need current information. For example, an airline chatbot using RAG can help a customer find alternative flights or seats by providing the most accurate, up-to-the-minute options. The combination of advanced search techniques with real-time data enables RAG to help LLMs generate contextually relevant responses tailored to the customer’s specific request.
Why RAG?



LLM Challenges
LLMs are excellent foundational tools for building GenAI applications and have made AI more accessible. However, they come with challenges.
LLMs are stochastic by nature and generally trained on a large corpus of static data. As a result, they lack current domain-specific knowledge. When there is a knowledge gap, LLMs can provide hallucinated answers that are false or misleading despite sounding plausible. For businesses with GenAI applications, hallucinations can break customer trust, damage brand reputation, and even create legal issues.
LLMs can function as a ‘black box’ with unclear knowledge fidelity and provenance, which can lead to potential issues with data quality and trust.
RAG architecture addresses these issues by augmenting LLM responses with real-time data, without the high costs of re-training the model. Since LLMs are expensive to run, these costs are often passed on to customers based on the number of tokens processed. By querying a vector database, RAG can provide accurate answers by contextualizing prompts with the most relevant domain-specific information, reducing the number of calls to the LLM. This, in turn, lowers the number of tokens processed, thereby significantly reducing costs. LLMs have limited context windows of ‘attention‘ for each prompt, so this RAG pattern enables use cases that would otherwise be infeasible without filtering out only the most relevant information.
RAG architecture can also minimize privacy concerns related to sensitive information generated by LLMs. It allows sensitive data to be stored locally while still leveraging the speed of LLMs’ generative capabilities. RAG provides an opportunity to filter out private or sensitive data within a model’s knowledge library before sending the prompt to the LLM.



Advantages of RAG over Pre-trained or Fine-tuned LLMs
RAG has distinct advantages over pre-trained or fine-tuned LLMs.
Pre-training involves training an LLM from scratch using a large dataset. While this allows for extensive customization, it requires significant resources and time investment.
Fine-tuning adapts pre-trained models to new tasks or domains with specialized datasets. Although more resource-efficient than pre-training, fine-tuning still demands considerable GPU resources and can be challenging. It may inadvertently cause the LLM to forget previously learned information or reduce its proficiency.
RAG, on the other hand, augments publicly available data from LLMs with domain-specific data from the enterprise. This allows for parsing and inferencing with context at prompt time. Additionally, post-processing in a RAG system verifies generated responses, minimizing the risk of inaccuracies or false information from the LLM.
RAG has emerged as a common pattern for GenAI, extending the power of LLMs to domain-specific datasets without the need for retraining models.
Benefits of RAG
Key benefits of RAG for generative AI include:
Access to real-time information
By using a real-time data streaming platform to keep the vector store up to date, RAG retrieves real-time data from sources such as operational databases or industrial data historians. This ensures that LLMs generate the most current and accurate responses.
Domain-specific, proprietary context
RAG incorporates information from proprietary and non-public data sources, allowing for tailored responses that align with specific industries, company policies, or user needs.
Cost-effectiveness
RAG reduces reliance on resource-intensive methods like pre-training or fine-tuning, making it a more cost-effective solution.
Reduced hallucinations
RAG mitigates the risk of hallucinations by providing the LLM with accurate, up-to-date information from reliable data sources. For example, if the vector store has up-to-date information provided by a Kafka topic, it can ensure that a chatbot accesses accurate and relevant inventory levels when responding to queries.
Semantic Search and Vector Search



Semantic search is a data-searching technique that helps AI systems understand the meaning and intent of a query. It uses natural language processing (NLP) to go deeper than keyword search. Instead of matching the words in the query, semantic search breaks down the meaning of words and phrases in order to retrieve the most relevant results.
To generate precise results when analyzing the semantic similarity between words, semantic search relies on vector search. Vector search turns individual words, phrases, and documents into vectors–a numeric representation of data–as points in multidimensional space. Things that are closely related in meaning (e.g., backpack, knapsack) have vectors that are positioned more closely together in space. In this way, during a vector search, a query is transformed into a vector in order to search for nearby vectors in multidimensional space. The more closely positioned they are, the more relevant they are to one another.
RAG leverages both vector search and semantic search. For example, MongoDB's Atlas Search Index supports both methods to search through unstructured data. Atlas Vector Search allows searching through data based on semantic meaning captured in vectors. RAG maximizes the likelihood of finding the most precise and contextually appropriate answers to user queries.
RAG Use Cases
The versatility and adaptability of RAG enhance workflows across various industries and real-time scenarios. Here are a few examples:
In proprietary customer support chatbots, such as those used by airlines, RAG facilitates tasks like flight rebooking or seat changes. This reduces the need for customer service calls and wait times by providing immediate answers to customer questions.
In retail, RAG supports product recommendation systems by leveraging customer 360 data, real-time mobile app insights, and purchase patterns. It can suggest personalized products or add-ons as customers browse in-store or complete transactions at the point of sale.
RAG assists GenAI applications in generating concise and compelling sales snippets from real-time customer interactions and calls, enabling sales representatives to deliver targeted pitches effectively.
RAG is invaluable for accessing real-time logistics information. It helps businesses maintain accurate inventory levels and optimize shipping by automatically generating the most efficient routes. While significant investments are being made here, the outcomes for many of these kinds of these constraint satisfaction problems have been limited for most domains, particularly those without comprehensive training data.
In healthcare, RAG retrieves and produces patient-specific treatment recommendations and fact-based medical reports. It also aids in analyzing drug interactions, thereby enhancing patient care and AI decision support systems.
Learn More
Watch a webinar with a demo of a RAG-enabled AI chatbot.
How RAG Works
RAG provides LLMs with relevant, up-to-date context to generate the most accurate responses. The end-to-end flow can be summarized as:
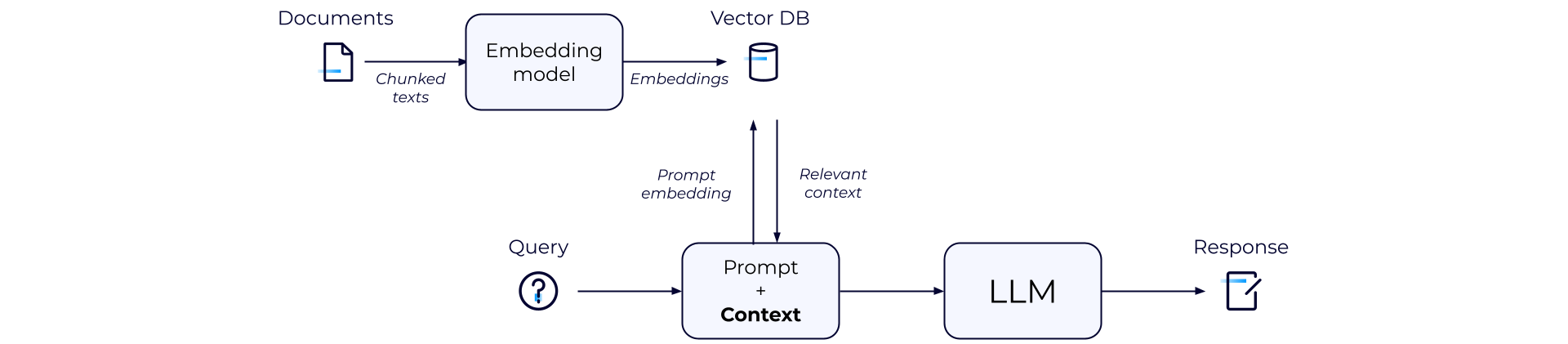
-
External data sources, such as document repositories or APIs, are gathered. Documents are chunked and passed through an embedding model to convert them into embeddings. These embeddings are then stored in a vector database.
-
A user or machine submits a query, which becomes a prompt for the LLM and goes to the generative AI application which should use RAG to enhance the query with relevant data not available to the LLM.
-
The RAG system converts the query into an embedding. Leveraging semantic search, RAG matches the prompt embedding with the most relevant information and retrieves that vector embedding.
-
The RAG system combines the embeddings with the original query–augmenting it with additional context–then passes it to the LLM to generate a natural-language response for the user.
-
Finally, the LLM response should be validated during post-processing to ensure that it is trustworthy and free of hallucinations.
Common Tools in Building RAG
Several tools are frequently used in building a context-specific real-time RAG architecture.
Frameworks like LangChain and LlamaIndex support building GenAI applications that use LLMs. They help in data integration, retrieval, workflow orchestration, and enhancing performance of LLMs.
LLMs such as GPT, Gemini, Claude, Olympus, LlaMA, Falcon, and PaLM serve as the backbone for generating high-quality responses.
Vector databases like Pinecone, Weaviate, Zilliz, and MongoDB store data as numerical vectors. They allow the RAG system to retrieve the most relevant data at prompt time.
Embedding models convert data into embeddings, or numerical vectors that preserve semantic meaning. These include platforms like OpenAI, Cohere, and HuggingFace and tools such as Word2Vec.
Apache Kafka as the de facto standard for data streaming ingests real-time data from any source, making it instantly available for downstream consumers. It brings consistency and scalability with a decoupled, event-driven architecture.
Apache Flink is an open-source distributed stream processing framework used to enrich, transform, and aggregate data in flight. It can perform low-latency stateless and stateful computations, providing processed data for retrieval.
Building RAG with Confluent
Confluent’s data streaming platform supports RAG implementation by providing a real-time, contextualized, and trustworthy knowledge base that can be coupled with prompts at inference time to generate better LLM responses. Confluent helps lower the barrier to entry for GenAI application teams, enabling faster time to market while providing the guardrails for data security and compliance.
Building RAG-enabled GenAI applications with a data streaming platform involves 4 key steps:
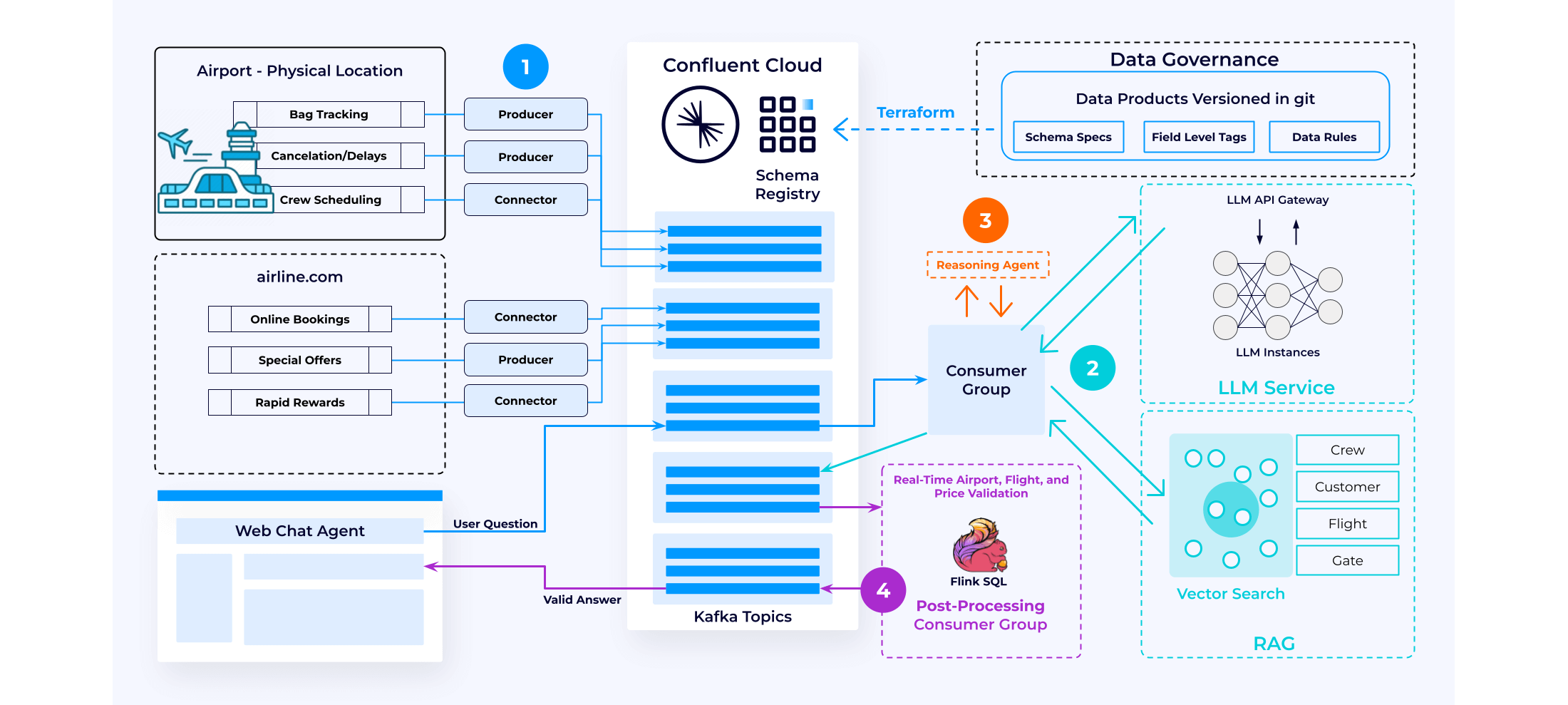
Data Augmentation
Confluent continuously ingests and processes data streams from various data sources to create a real-time knowledge base. In this phase, a tool like Flink SQL can call a vector embedding service to augment the data with vectors. The processed data is then stored in a vector database using a sink connector. This setup enables RAG against the vector database with continuously updated information.
Inference
A consumer group takes the user question and prompt from the Kafka topic and enriches it with private data from the vector store database. This process involves inspecting the user's query and using it to perform a vector search within the vector database, adding relevant results as additional prompts. For instance, in the case of flight cancellations, a KNN (k-nearest neighbors) search can identify the next best available flight options. This enriched and contextually relevant data is then sent to an LLM service, which generates a comprehensive response.
Workflows
To enable GenAI applications to break a single natural language query into composable multipart logical queries and ensure real-time information availability, reasoning agents are often used. This approach is more effective than processing the entire query at once.
In such workflows, a chain of LLM calls is used, with reasoning agents deciding the next action based on the prompt output, allowing for seamless interaction and data retrieval.
Post-processing
Many organizations are not yet comfortable trusting LLM outputs directly. In automated workflows, every application includes a step to enforce business logic and compliance requirements.
Using an event-driven pattern, the GenAI workflow can be decoupled from post-processing, allowing independent development and evolution. Confluent helps validate LLM outputs, enforcing business logic and compliance requirements to ensure trustworthy answers. This enhances the reliability and accuracy of AI-driven workflows.
Additional Resources
Get Started
Get started free with Confluent Cloud to start building a real-time, contextualized, and trustworthy knowledge base for your GenAI use cases.