New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Streaming in the Clouds: Where to Start
Only a few years ago, when someone said they had a “cloud-first strategy,” you knew exactly who their new preferred vendor was. These days, however, the story is a lot cloudier.
Every conversation around cloud now involves terms like hybrid cloud and multi-cloud. Executives want to avoid vendor lock-in and operate as close to their data sources as possible. Developers and data scientists would like the flexibility to leverage best-in-class services for their specific use case from different cloud providers. A strategy focused around a single, massive cloud environment just doesn’t cut it in many cases.
However, these complex cloud strategies create new challenges. In an ideal situation, developers build cloud-native applications, leverage cloud ecosystem services and move seamlessly between cloud providers without having to worry about where their data is. But this is difficult.
Companies are just getting a grip on how to move some of their data to the cloud and build new applications specifically in and for the cloud. It’s a massive challenge to forklift existing systems of record and associated applications that have been the backbone of a company’s operations into cloud. How can they possibly architect for moving data between multiple applications and clouds, and having the relevant data show up across environments in real time, regardless of where it was created?
So even if companies are looking at cloud-first as their ultimate goal, many end up working in a hybrid cloud model in the short to medium term where some applications run on-premises and some run in the cloud. Imagine the challenges in the hybrid cloud world of connecting legacy systems with new cloud applications and making it appear as a single cohesive system across the company.
A common anti-pattern we see looks like the diagram shown below—HTTP requests across the WAN which creates a point-to-point architecture. It works initially but has several drawbacks. It makes for a slow, weak bridge with massive interconnections, with different systems talking to the cloud services in different ways. This is not a scalable architecture.
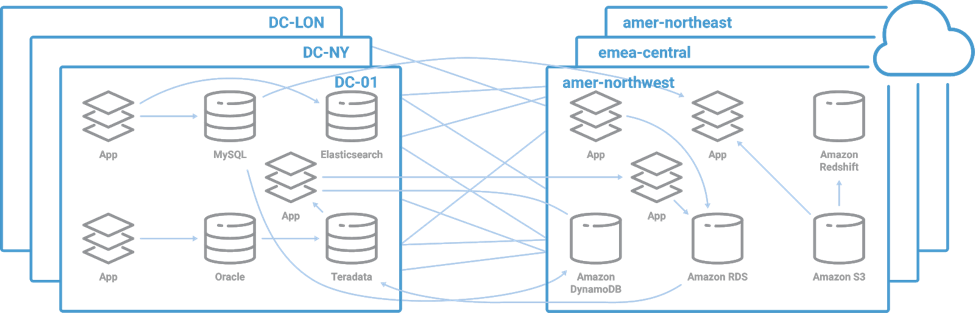
Leveraging Apache Kafka for cloud migration and beyond
Fortunately, Apache Kafka® has risen to prominence as a key enabler of hybrid, cloud-only and multi-cloud strategies. Kafka has been the leader among technologies used in developing streaming data pipelines and apps for several years. As it turns out, organizations are finding that many of the components that make Kafka great for building and managing real-time pipelines and apps are also incredibly valuable in building a bridge to cloud.
Alternatively, Apache Kafka can also be used to build data pipelines across cloud regions to address disaster recovery (DR) requirements that your organization might have. This can be a more practical way to implement DR strategies instead of relying on costly proprietary solutions.
For example, let’s consider Confluent Replicator, which actively replicates data across datacenters and public clouds. It provides a simple and scalable solution to bridge your data into the cloud. Below are some examples of how Confluent Replicator can help you build a bridge to cloud, or even a bridge between clouds.

Hybrid Cloud (environment spanning on prem and cloud) |

Multi-Cloud (environment spanning different cloud providers) |

Cloud Only (environment only in the cloud) |
| Replicate data between on-prem datacenter and public clouds continuously and reliably. | Replicate data between public clouds. | Replicate data between clouds, across applications or anywhere else. |
So let’s take a look at how you might build a hybrid architecture that allows for a step-by-step migration. Instead of having many point-to-point connections, you can build a hub and spoke implementation based on a central Kafka platform.
You can publish streams of data from your local on-prem environment, replicate it to different cloud regions and environments, load into data systems in the cloud and trigger cloud-native applications off of those events and data. So the data stays in sync across both on prem and cloud. It shows up across the infra, in near real time, and what you end up with is a future-proof, massively scalable platform to support all of your company’s needs.
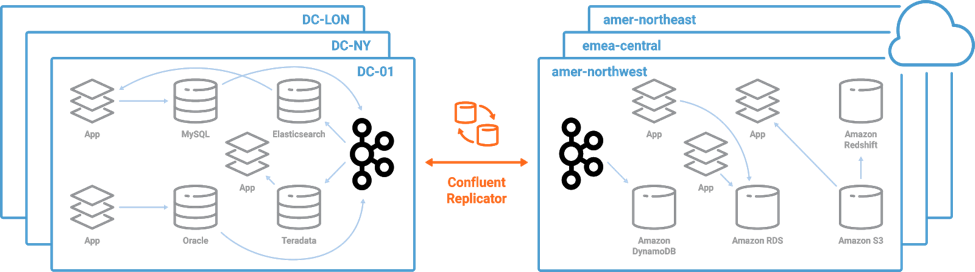
Once you have your data in the cloud, you can take advantage of the broad Apache Kafka ecosystem of connectors to easily and quickly scale out to various cloud services and data systems. The most popular data systems, such as S3 on AWS, Elasticsearch, GCS on GCP, etc., have prebuilt connectors from Confluent, its partners or the Kafka community.
Comparing Confluent Replicator and MirrorMaker
While Confluent Replicator has been compared to open source MirrorMaker in the past, there are enterprise-critical features in Confluent Replicator that cannot be found in MirrorMaker. Yes, both technologies provide data, schema and Connect replication, which are all extremely important in managing data across datacenters and clouds. But MirrorMaker only partially supports flexible topic selection and auto-creation of topics.
And, there are loads of enterprise-grade features in Confluent Replicator that are not supported in MirrorMaker. Confluent Replicator automatically detects and replicates new partitions in your streams. It replicates topic configuration between two clusters so your two clusters are always in sync. With Confluent Replicator, you can filter, modify and route events on the fly. (For a thorough comparison, please see Confluent documentation on multi-datacenter replication.)
Given all of the above, it makes a lot of sense to leverage Apache Kafka for your cloud migration. It means setting up Kafka clusters in the source and destination environments, sizing the clusters for the right throughput, ensuring availability, addressing security requirements and all of the other nitty gritty operational details that go into building distributed systems.
You’re thinking all the benefits sound great but implementation takes time, expertise and management. How might you speed up your migration or Kafka deployment, and offload some of the management burden while ensuring peace of mind and reliability?
Would a fully managed Kafka service help?
Confluent Cloud provides Apache Kafka as a fully managed service in your cloud of choice with 99.95% uptime SLA. It guarantees under one-hour response time for high priority issues from Kafka experts—the same people who originally created Kafka and commit regularly to Kafka source code. So why not offload the burden of deploying, upgrading and maintaining Kafka to the experts, and instead focus on your migration strategy and plan?
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.