New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
How to Choose Between Strict and Dynamic Schemas
Event modeling has always been a pain point in organizations. From figuring out the standard format of your schemas, processing said data models effectively, and finally testing before you deploy to production, there is a need for some sort of standardization in how your company communicates about its data assets.
This is the first of a three-part series on Spring for Apache Kafka® and Protobuf, which dives into the world of modeling events and the ramifications that they pose for the enterprise.
This series guides you through how to tackle these problems when it comes to schemas, implementing generic processors leveraging Confluent Schema Registry, and caps off with how to test all of these frameworks and components from the comfort of your laptop.
For parts 2 and 3, see Self-Describing Events and How They Reduce Code in Your Processors and Advanced Testing Techniques for Spring for Apache Kafka.
Background
Imagine a postal worker delivers mail to you, and you find some of the mail in envelopes, others without envelopes, and the rest packaged in large boxes.
Like most people, you’d love to get on with your day as fast as you can by finding the one or two letters you’d been expecting and throwing the rest into the recycling bin.
Instead, you now have to rummage through the contents of the envelopes, open up large bulky boxes and remove the bubble wrap, and read the letters sans envelopes. Wouldn’t life be easier if the mail arrived with some sort of standardized structure?
To make matters even more challenging, upon opening the mail, you realize it comes from different countries and is written in different languages.
This scenario is much like the life of a software engineer tasked with creating an event-driven platform for the enterprise.
Let’s say that a company called BoopBop has a collection of various microservices, data pipelines, and field equipment for collecting metrics. The technologies vary across programming languages and hardware. Your job is to investigate how to set up the main patterns for an event-driven platform in terms of event design.
Designing event-driven models
Before delving into using a specific modeling language for your events, there are three major approaches to consider:
- Bare letter: The event model has all the fields needed for the specific data your process wants to emit.
- Deep envelope: The event you wish to emit is packaged into an envelope with high-level metadata required for handling. The envelope is considered “deep” as it defines all known event payloads that can be encapsulated. Think schema on write.
- Shallow envelope: This event model is similar to the deep envelope approach, but the envelope can accept any arbitrary payload placed inside it. Think schema on read.
The next few sections outline each approach in more detail, present their tradeoffs, and summarize the impact of each on your organizational structures (in relation to Conway’s Law).
Bare letter
Using the bare letter approach means that each process is free to publish their events according to the structure they define, which contains all the data needed to process it (either in place or with references).
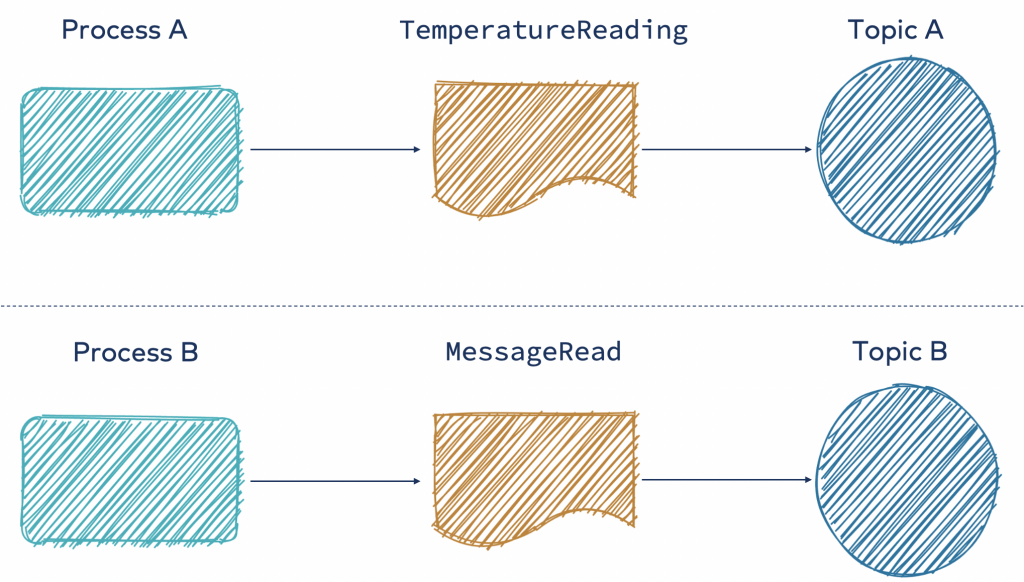
Here are the advantages:
- There is no event schema overlap; it is not dependent on other teams; and it allows for “microservice” benefits
- Writing a simple consumer for these events is straightforward; the fields in the schema emitted are true to the intent
- A minimal amount of data needs to be serialized
- Schema is fully expressed, allowing for compatibility checking before releases and therefore reducing risk
On the flip side, here are the disadvantages:
- Common schema elements are not guaranteed to exist because of event schema independence. This makes writing higher-level processors more difficult (the creation time of the event can be in a different field for each schema, such as userReadDate and temperatureRecordingTime).
- More effort on the consumer side is required to reconcile the data together, leading to data quality issues on semantics and translation requirements.
- As a result, duplication across a domain(s) for common fields occurs.
This approach is great when the domain you are working with does not have many shared components or if you are still early in the process of figuring out the scope of your system.
Envelopes
Before delving into the two envelope approaches, let’s define a few terms and properties of an envelope.
An envelope seeks to pull up identification or metadata related to the contents contained within the payload of an envelope. Much like a real-life envelope, it helps you quickly assign relevance or priority to certain envelopes like bills and payroll. In essence, every envelope should seek to minimize the amount of effort required to identify or assign value to a given payload without explicitly looking at the payload itself via standardized fields. In the realm of software, this can be IDs, timestamps, priority, and enumerations. The benefit is that it allows generic processors to be written so that they operate on the envelope level, without needing to dive into the specifics of where to find certain metadata across several different event schemas.
Given that event models mimic the tree data structure, you can define the depth of a model which is the most nested element (e.g., depth[“payload.nested1.nested2.product_id”] = 4).
Naturally, the width of your data model can be defined as the widest fan-out for a given field. For example, if a certain field in your data model could be of N different types, then the width of that field would be N (a node with N children).
From an empirical perspective, you want to design your envelopes such that the depth and width dimensions are not too small or too large. An envelope that encompasses all of the events in an organization with a width in the thousands is probably not the easiest to work with—much like having a single table in a relational database with thousands of columns is not usually the best design approach.
The more localized the envelope is to the domain, the better the depth and width dimensions, the proxy for developer experience and maintainability, as well as the relevance and number of shared envelope fields. It is common to have multiple envelope definitions grouped by some parameter, such as department, domain, or team.
Deep envelope
The deep envelope approach attempts to pull out certain commonalities into the top level—that is, the envelope fields—such as event ID or user ID. This reduces duplication between the N payloads in terms of redefining these fields and also allows downstream consumers to use the envelope metadata to do higher-level operations like routing and grouping. Note that the common fields above are just examples. In actuality, they are dependent on your domain and use case.
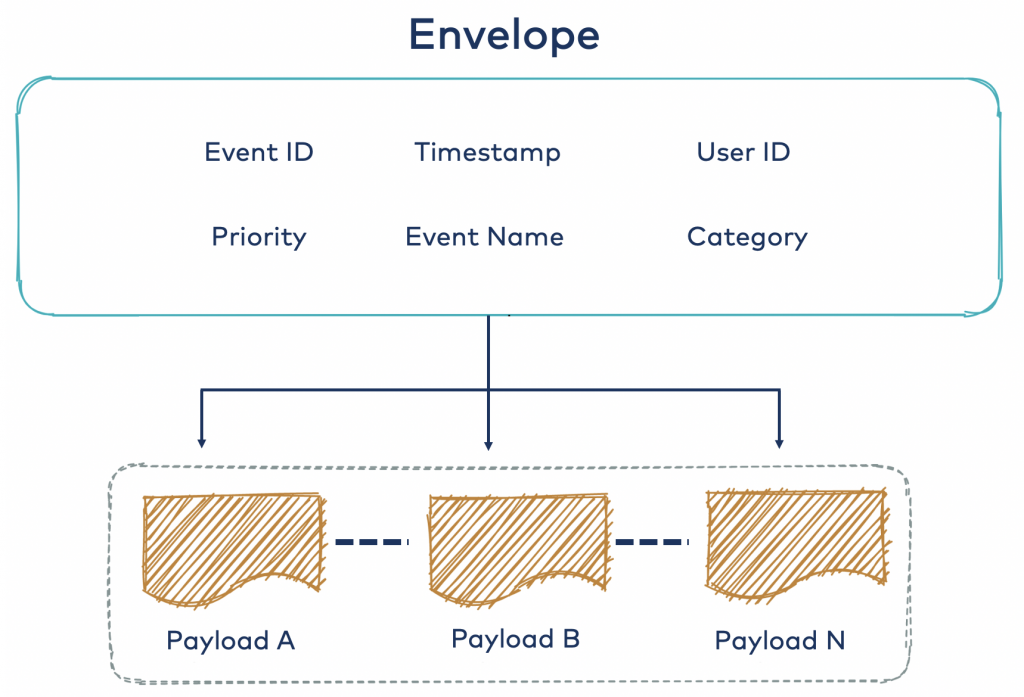
Now let’s take a look at the advantages of this approach:
- There can be less boilerplate fields between payload schemas by defining them at the top level
- The standardized envelope fields allow for routing to be done without looking at which payload is attached, as well as deduplication, priority processing, and more
- Schema is deep, allowing for compatibility checks at compile and release times
- With a correctly scoped envelope, the model provides guidance on what you are allowed to send and what you cannot because of the explicit nature of the definition
- Collaboration on the definition of the envelope and payloads is encouraged.
Yet this approach is not without its disadvantages:
- An extra layer is added between the payload (the intent) and anyone trying to emit or process the event. This increases the room for error and misinterpretation when it comes to filling out certain common fields versus specific payload fields.
- This approach can be scoped improperly due to depth and width, leading to poor maintainability and a poor developer experience.
- Without more advanced data governance tools, and process, this approach is harder to implement and manage across teams and departments.
- In only looking at the envelope, there is more to deserialize even when you do not want to process the event.
This approach works well when the domain is well known and understood and permits for generic processors to “see” the payloads, with robust compatibility checking before release as well.
Shallow envelope
The shallow envelope allows any possible payload to be attached to the envelope, much like a real-life envelope. Whether it is a bill or a romantic love letter—that holds no significance to the envelope itself. It’s like a BLOB data type in a relational database: “I’ll figure this out later,” or what is better referred to as the schema-on-read approach.
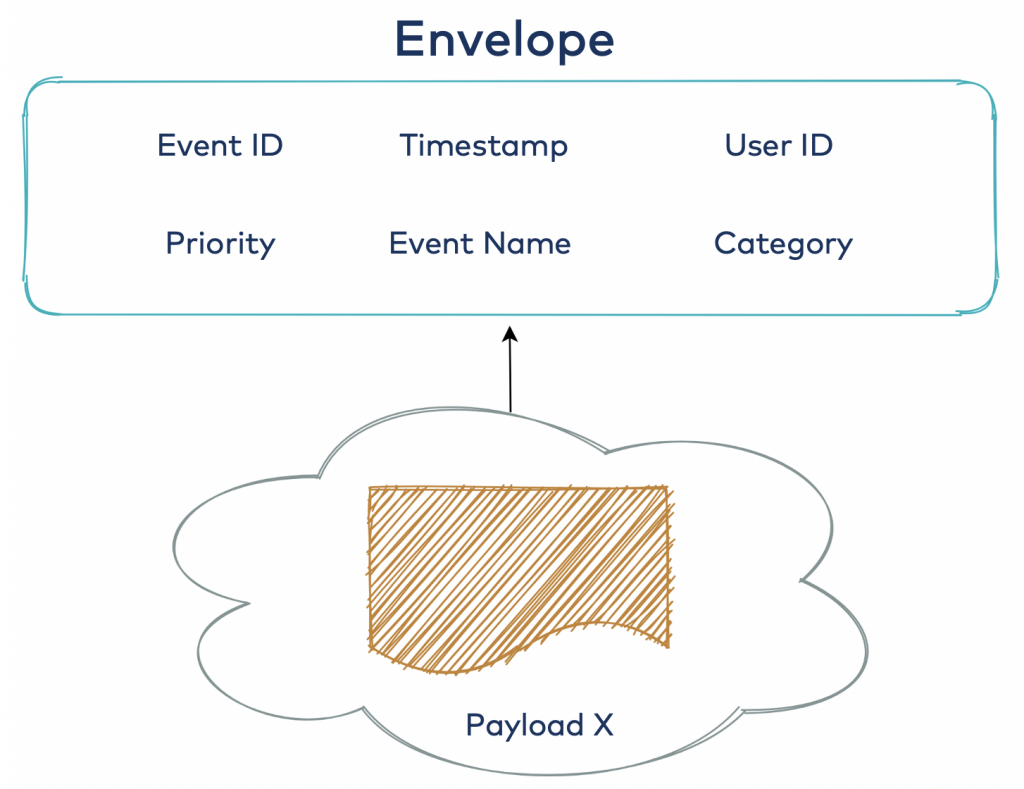
These are the advantages:
- The absence of strict coupling allows maximum flexibility and does not require you to update the definition of the envelope when a new payload arises. This leads to a quick time to market without needing to update the model.
- You can perform shallow deserialization of the envelope only, meaning that less resources are taken up for processing only the envelope and not the payload.
- This approach is ideal for situations when you do not know the possible data that you will be producing upfront or are still in the process of feeling out the domain.
These are the disadvantages:
- Compatibility checks are not possible at compile and release times due to the model not defining what can be attached to the envelope. This defers risk to the runtime context.
- Due to no associated bound model with the event, you are forced to explicitly code logic to “unpack” the arbitrary payload. This leads to code duplication across applications and code drift across the software ecosystem. The more layers the event definition needs to be redefined into the programming language of choice manually, the higher the risk of outages and errors.
- The model’s arbitrary payload expression does not lend itself well to being self-documenting. In other words, “playbooks” are more likely to be written for certain domains and services, effectively mimicking a deep envelope via a “shared understanding” enforcement.
- The width of this approach is unbounded and can take any payload, which could be costly if the wrong payload is attached.
The final approach works well when the envelope is more generic, usually when there is a need to encapsulate a broad set of payloads. It’s perfect if you can do extra validation work at the application level to ensure that the correct payloads get attached, or if your application is a proxy for the data assets and simply needs to wrap and tag the data flowing through.
Summary of design approaches
As you can see, these design approaches have different levels of explicitness and localization. Depending on your organization’s structure and stage in the organizational life cycle, certain approaches will either go against the grain or synergize with the momentum of the enterprise. Anecdotally, companies in the earlier stages of their life cycles might opt for the bare letter or shallow envelope approach because of its flexibility, while other more hierarchical enterprises might lean toward the deep envelope approach due to its rigidity and natural domain-like division. The following matrix provides an overview:
| Pre-Release Compatibility Checks with Model Only | Maintainability of Model | Maintainability of Code | Generic Processing Ability* | |
| Bare Letter | Yes | High | High | Low |
| Deep Envelope | Yes | Medium | Medium | High |
| Shallow Envelope | Only envelope level | High | Low | Low-Medium |
*Generic processing ability: The ability to write event stream processors that can leverage standardized fields or the “deepness” of the model to process events without requiring explicit code to handle each event type. Read part 2 of this series to learn more.
Protobuf – From logical to physical
So far, we have discussed the logical views on expressing event data, but how do you actually materialize these models in the real world?
To define models in a language-independent way, you can leverage an interface definition language (IDL). This serves as the “code” that sets up the structure of your logical models that can be programmed against. Some examples are Avro, Google’s protocol buffers (aka Protobuf), and Thrift.
Once your model is encoded into an IDL, it can then be generated with the specific tool’s compiler to the target language of choice (e.g., C++, Java, and Python). Not having to manually write these boilerplate definitions by hand saves lots of time and reduces risk in model distribution and usage. The added advantage is that you can then upload the compiled models to an artifact repository and register the schemas to a schema registry within your organization through your CI/CD setup.
Given the earlier specification of the wide-ranging tech stack example at BoopBop, which IDL should you choose?
In this context, Protobuf seems like the best choice as it is still actively maintained, widely used, and also has support for many languages. To learn more about the advantages of Protobuf, check out this blog post from online food delivery company Deliveroo citing how Protobuf has certain advantages, such as not being JVM/Hadoop-centric like Avro or being inactive in maintenance like Thrift.
Confluent recently added support to their Schema Registry to manage Protobuf schemas with first-class support, an indication that Protobuf is gaining more traction and adoption outside of gRPC. For a more in-depth view of how these IDLs materialize, check out Schema Evolution in Avro, Protocol Buffers, and Thrift by Martin Kleppmann.
The next few sections provide some example models expressed in Protobuf, reflecting the three major approaches defined earlier so that you can get an idea on what it entails.
Specifically, Protobuf definitions are structured around the concept of a message, similar in concept to a class in OOP, and they can be composed of various predefined data types or user-defined types. This blog post does not dive into all the details, so it is recommended that you read the Protobuf documentation for more on the wire encoding format and other syntactical specifics.
Protobuf – Bare letter
The following illustrates a Protobuf message with the attributes of the bare letter pattern, which in this case, is for a temperature reading from a device.
syntax = "proto3";
package com.zenin.examples;
option java_package = "com.zenin.examples"; option go_package = "zenin.com/examples";
import "google/protobuf/timestamp.proto";
message TemperatureReading { string id = 1; google.protobuf.Timestamp time_of_reading = 2; double temperature_in_celsius = 3; string device_id = 4; }
As shown, the intent of this message is fairly clear and easy to express in Protobuf. Please note the option settings, which also provide some configuration around the package names for the generated Java and Go artifacts (class and struct in this case).
Protobuf – Deep envelope
Building off the last example around temperature readings, imagine you now want to add more related events to measure the physical conditions in the environment. Notice that there are many shared fields between your models, which lends itself well to a deep envelope approach as shown below:
syntax = "proto3";
package com.zenin.examples;
option java_package = "com.zenin.examples"; option go_package = "zenin.com/examples";
import "google/protobuf/timestamp.proto";
message EnvironmentReadings { string reading_id = 1; google.protobuf.Timestamp time_of_reading = 2; string device_id = 4; double latitude = 5; double longitude = 6; double elevation_in_meters = 7;
oneof readings { TemperatureReading temperature_reading = 8; PrecipitationReading precipitation_reading = 9; PHReading ph_reading = 10; } }
The envelope is designed to encompass the possible environmental readings your sensors can emit, defining an explicit list of all readings you can send using this model. If a new type of reading appears in your organization (e.g., HumidityReading), you can simply add a new field underneath the oneof construct in a backward-compatible way. The powerful functionality of the oneof construct is that it forces the developer to only attach one of the possible message models defined by the construct, enforced via the generated code.
For simplicity’s sake, the other message models were defined inline with the EnvironmentReadings message in order to avoid import statements. These are shown below:
message TemperatureReading {
double temperature_in_celsius = 1;
}
message PrecipitationReading {
uint32 delta_in_millimetres = 1;
}
message PHReading {
uint32 ph_value = 1;
PHType ph_type = 2;
}
enum PHType {
UNSPECIFIED = 0;
NEUTRAL = 1;
ACIDIC = 2;
BASIC = 3;
}
By using the envelope, you reduce duplication across your possible reading models and leave them as specific as possible to their intent.
You should note that the above example does not aim to create a perfect model for environmental readings. Rather, it showcases the possible modeling you can achieve with Protobuf. For example, the PHReading should probably not categorize its own reading. Instead, your backend should enrich the event with server-side centralized logic over client-side deduction. Also, depending on how general you would want your envelopes to be, more generic names like event_id instead of reading_id could be appropriate.
One final thing to note is that you could also build tooling around Protobuf to ease the management of your envelopes across all your models (e.g., a monorepo). This strategy is beyond the scope of this blog post, however, and is offered solely as a technical detail about how to keep your model definitions DRY and standardized across an organization.
Protobuf – Shallow envelope
Continuing our example, imagine now that you do not want to create deep envelopes because the width would get too large and become hard to use. Imagine hundreds of readings and the need for either one very large envelope or several deep envelopes for segmentation.
Using a shallow envelope approach helps alleviate some of the upfront scoping tasks as expressed below in Protobuf:
syntax = "proto3";
package com.zenin.examples;
option java_package = "com.zenin.examples"; option go_package = "zenin.com/examples";
import "google/protobuf/timestamp.proto"; import "google/protobuf/any.proto";
message EnvironmentReadings { string reading_id = 1; google.protobuf.Timestamp time_of_reading = 2; string device_id = 4; double latitude = 5; double longitude = 6; double elevation_in_meters = 7;
google.protobuf.Any reading = 8; }
The above model looks almost identical to the last except for the replacement of the oneof construct with the Any message. This is a native type built into the Protobuf library and requires a special Google API to pack/unpack the corresponding Protobuf message. A code snippet in Java is provided below to show how to create an Any message that can then be used to attach to a model that has an Any field:
Foo foo = … ;
Any any = Any.pack(foo);
…
if (any.is(Foo.class)) {
foo = any.unpack(Foo.class);
}
As described earlier, any valid Protobuf message can be attached, which means the risk for data quality issues increases as someone could attach a DebitEvent or a DogBarked message instead of the payload you were expecting. By bypassing the upfront tasks related to model explicitness, the architectural ramification is that more needs to be done outside the model definition to ensure data quality and backward compatibility before release.
Bringing it all together
Through the example of mail and how it applies to event design, you can see the importance of selecting an appropriate approach for a given situation within your company and domain. Any one of the three “primitives” for model expression laid out in this blog post directly affects your ability to reduce risk in deployments, keep your software ecosystem maintainable, and create generic processors. To express these primitives, this blog post detailed how an IDL like Protobuf can reduce duplication and standardize the language of definition and communication about the data in your organization, irrespective of the tech stack.
Certain approaches encourage collaboration like the deep envelope, while others encourage autonomous, independent thinking. As a leader in your organization, it is up to you to instill the type of culture your business needs, all the way down to how you express your events.
While you’re at it, look out for the second post in the series, which leverages the power of Kafka, Spring Boot, Protobuf, and Confluent Schema Registry to create a generic processor. For part 3, check out Advanced Testing Techniques for Spring for Apache Kafka.
If you’d like to know more, you can sign up for Confluent Cloud and get started with a fully managed event streaming platform powered by Apache Kafka. Use the promo code SPRING200 to get an additional $200 of free Confluent Cloud usage!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.