New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Scylla and Confluent Integration for IoT Deployments
The internet is not just connecting people around the world. Through the Internet of Things (IoT), it is also connecting humans to the machines all around us and directly connecting machines to other machines. In light of this, we’ll share an emerging machine-to-machine (M2M) architecture pattern in which MQTT, Apache Kafka®, and Scylla all work together to provide an end-to-end IoT solution. We’ll also provide demo code so you can try it out for yourself.
IoT scale
IoT is a fast-growing market, already known to be over $1.2 trillion in 2017 and anticipated to grow to over $6.5 trillion by 2024. The explosive number of devices generating, tracking and sharing data across a variety of networks is overwhelming to most data management solutions. With more than 25 billion connected devices in 2018 and internet penetration increasing at a staggering 1,066% since 2000, the opportunity in the IoT market is significant.
There’s a wide variety of IoT applications, like datacenter and physical plant monitoring, manufacturing (a multibillion-dollar sub-category known as Industrial IoT or IIoT), smart meters, smart homes, security monitoring systems and public safety, emergency services, smart buildings (both commercial and industrial), healthcare, logistics and cargo tracking, retail, self-driving cars, ride sharing, navigation and transport, gaming and entertainment…the list goes on.
Interactive M2M/IoT Sector Map
This growth depends greatly on the overall reliability and scalability of IoT deployments. As IoT projects go from concepts to reality, one of the biggest challenges is how the data created by devices will flow through the system.
How many devices will be creating information? What protocols do the devices use to communicate? How will they send that information back? Will you be capturing that data in real time or in batches? What role will analytics play in future?
What follows is an example of such a system, using existing best-in-class technologies.
An end-to-end architecture for the Internet of Things
Most IoT-based applications (both B2C and B2B) are typically built in the cloud as microservices and have similar characteristics. It is helpful to think about the data created by the devices and the applications in three stages:
- Stage one is the initial creation, which takes place on the device, and is then sent over the network.
- Stage two is how the central system collects and organizes that data.
- Stage three is the ongoing use of that data stored in a persistent storage system.
Typically, when sensors/smart devices get actuated, they create data. This information can then be sent over the network back to the central application. At this point, one must decide which standard the data will be created in and how it will be sent over the network.
For delivering this data one widely used protocol is MQTT. MQTT is a lightweight messaging protocol for pub/sub communication typically used for Machine-to-Machine (M2M) communication. Apache Kafka is not a replacement to MQTT, but since MQTT is not built for high scalability, longer storage, or easy integration to legacy systems, it complements Apache Kafka well.
In an IoT solution, the devices can be classified into sensors and actuators. Sensors generate data points while actuators are mechanical components that may be controlled through commands. For example, the ambient lighting in a room may be used to adjust the brightness of an LED bulb, and MQTT is the protocol optimized for sensor networks and M2M. Since MQTT is designed for low-power and coin-cell-operated devices, it cannot handle the ingestion of massive datasets.
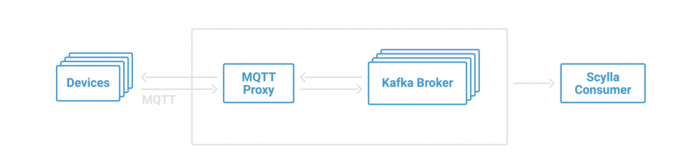
MQTT Proxy + Apache Kafka (no MQTT broker)
On the other hand, Apache Kafka may deal with high-velocity data ingestion but not M2M. Scalable IoT solutions use MQTT as an explicit device communication while relying on Apache Kafka for ingesting sensor data. It is also possible to bridge Kafka and MQTT for ingestion and M2M, and it is recommended to keep them separate by configuring the devices or gateways as Kafka producers while still participating in the M2M network managed by an MQTT broker.
At stage two, typically data lands as streams in Kafka and is arranged in the corresponding topics, which various IoT applications consume for real-time decision making. Various options like KSQL and Single Message Transforms (SMT) are available at this stage.
At stage three this data, which typically has a shelf life, is streamed into a long-term store like Scylla using the Kafka Connect framework. A scalable, distributed, peer-to-peer NoSQL database, Scylla is a perfect fit for consuming the variety, velocity, and volume of data (often time-series) coming directly from users, devices, and sensors spread across geographic locations.
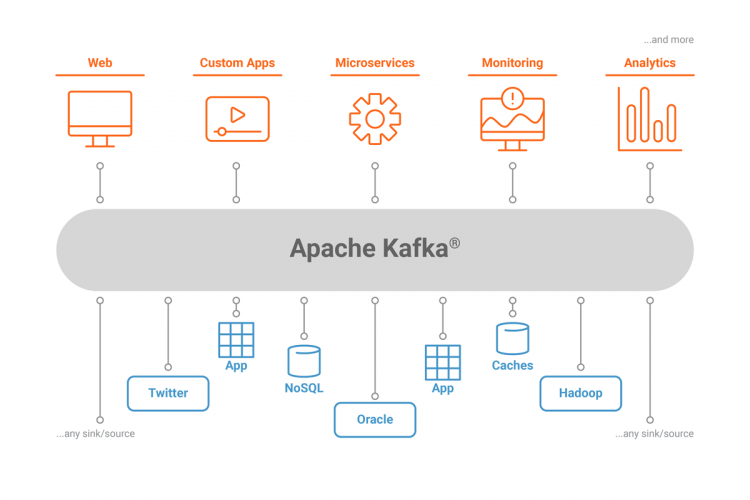
What is Apache Kafka?
Apache Kafka is an open source, distributed message queuing and streaming platform capable of handling a high volume and velocity of events. Since its creation at LinkedIn in 2011, Kafka has quickly evolved from a message queuing system to a full-fledged streaming platform.
Enterprises typically accumulate large amounts of data over time from different sources and data types, such as IoT devices and microservices applications. Traditionally, for businesses to derive insights from this data, they have used data warehousing as part of extract, transform, load (ETL) strategies, which are batch driven and run at a specific cadence. This creates an unmanageable situation, in which custom scripts move data from their sources to destinations as one-offs, provide many single points of failure and fail to permit analysis of the data in real time.
Kafka provides a platform that can arrange all these messages by topics and streams. Kafka is enterprise ready, and has powerful features like high availability (HA) and replication on commodity hardware. Kafka decouples the impedance mismatch between the sources and the downstream systems that need to perform business-driven actions on the data.
What is Scylla?
Scylla is a scalable, distributed, peer-to-peer NoSQL database that works as a drop-in replacement for Cassandra. Scylla provides high throughput, low latency, and better cluster resource utilization while building upon the existing Cassandra ecosystem and APIs.
Most microservices developed in the cloud prefer to have a distributed database native to the cloud that can linearly scale. Scylla fits this use case well by harnessing modern multi-core/multi-CPU architecture, and producing low, predictable latency response times. Scylla is rewritten in C++, yielding benefits in terms of TCO, ROI and overall better user experience.
Scylla is a perfect complement to Kafka because it leverages the best from Cassandra in high availability, fault tolerance, and its rich ecosystem. Kafka is not an end data store itself, but a system to serve a number of downstream storage systems that depend on sources generating the data.
Demo of Scylla and Confluent integration
The goal of this demo is to demonstrate an end-to-end use case where sensors emit temperature and brightness readings to Kafka and the messages are then processed and stored in Scylla. To demonstrate this, we are using Confluent MQTT Proxy (part of the Confluent Platform), which acts as a broker for all the sensors that are emitting the readings.
We also use the Kafka Connect Cassandra connector, which spins up the necessary consumers to stream the messages into Scylla. Scylla supports both the data format (SSTable) and all relevant external interfaces as Cassandra, so we can use the out-of-the-box Kafka Connect Cassandra Connector.
The load from various sensors is simulated as MQTT messages via the MQTT client (Mosquitto), which will publish to the MQTT broker proxy. All the generated messages are then published to the corresponding topics, and then a Scylla consumer will pick up the messages and store them in Scylla.
Although you can do this demo on any platform, the steps below were performed on a Mac OS X system with homebrew installed. We use the Google Cloud API to automate the deployment of a ScyllaDB cluster. There is documentation about setting up Google Cloud here (alternatively, if you prefer aws/bare-metal, instructions are also available).
Steps
1. Download the Confluent Platform.
2. Once the tarball is downloaded:
3. Set the $PATH variable:
For the demo, we choose to run the Kafka cluster locally, but if we want to run this in production, we would have to modify a few files to include the actual IP addresses of the cluster:
ZooKeeper: /etc/kafka/zookeeper.properties
Kafka: /etc/kafka/server.properties
Confluent Schema Registry: /etc/schema-registry/schema-registry.properties
Kafka Connect: /etc/schema-registry/connect-avro-distributed.properties
4. Let’s install a Confluent Hub client and then install the Cassandra connector.
For other platforms, please refer to the documentation.
5. Now, we need to start Kafka and ZooKeeper:
This should start both ZooKeeper and Kafka. To do this manually, provide these parameters:
6. Create Kafka topics.
The simulated MQTT devices will be publishing to the topics temperature and brightness, so let’s create those topics in Kafka manually:
7. Start MQTT Proxy:
8. Install the Mosquitto framework:
Note: For other platforms, please refer here.
9. Publish MQTT messages.
We are going to be publishing messages with quality of service (QoS) 2, that is, the highest quality of service supported by MQTT protocol.
10. Verify messages in Kafka.
Make sure that the messages are published into the Kafka topic:
11. To produce a continuous feed of MQTT messages (optional), run this on the terminal:
12. Let’s start a Scylla cluster and make it a Kafka Connect sink:
Once the cluster comes up with three nodes, SSH into each node, uncomment the broadcast address in /etc/scylla/scylla.yaml and change it to the public address of the node. This should occur if we are running the demo locally on a laptop, or if we are running the Kafka Connect framework in another datacenter compared to where the Scylla cluster is running.
As prerequisites to running the automation, please install
Open the script gce_deploy_and_install_scylla_cluster.sh and set the PROJECT variable to a value that is relevant to your environment. You will also need to create a Google App Engine application ID for the project. Running this from a Google Compute Engine VM with full cloud API access is easiest.
Note: If you are choosing to use Scylla in a different environment like AWS or bare-metal, start here.
Once the cluster comes up with three nodes, SSH into each node, uncomment the broadcast_address and broadcast_rpc_address in /etc/scylla/scylla.yaml, and change it to the public address of the node. This step is needed if we are running the demo locally on a laptop, or if we are running the Kafka Connect framework in another datacenter compared to where the Scylla cluster is running.
13. Start the KSQL server. We will be interacting with the data in Kafka via KSQL.
Create a stream, which will use the Connect framework to store the data in Scylla.
14. Once the KSQL server starts, open a KSQL shell and list all the topics available. You should see the temperature and brightness topics.
15. Now, let’s create the corresponding stream:
16. We should install the Kafka Connect Cassandra connector now using:
17. We need to update a couple of fields in the Cassandra sink connector. Then we should be able to start the Connect framework.
Update the contents of /confluent-5.2.0/share/confluent-hub-components/confluentinc-kafka-connect-cassandra/etc/sink.properties with the relevant information:
18. Now, let’s start the Connect framework using the Cassandra connector in standalone mode, as this is a demo:
To run this in production, we would have to modify and run Connect in distributed mode. We would also have to supply the relevant files, i.e., connect-avro-distributed.properties.
19. Try to run a script that can simulate the activity of a MQTT device by cloning this repo and then running:
This script simulates MQTT sensor activity and publishes messages to the corresponding topics. The Connect framework streams the messages from the topics into the corresponding tables in Scylla.
You did it!
If you follow the instructions above, you should now be able to connect Kafka and Scylla using the Connect framework. In addition, you should be able to generate MQTT workloads that publish the messages to the corresponding Kafka topics, which are then used for both real-time as well as batch analytics via Scylla.
Given that applications in IoT are by and large based on streaming data, the alignment between MQTT, Kafka, and Scylla makes a great deal of sense. With the new Kafka Connect Scylla Connector, application developers can easily build solutions that harness IoT-scale fleets of devices, as well as store the data from them in Scylla tables for real-time as well as analytic use cases.
Many of ScyllaDB’s IoT customers like General Electric, Grab, Nauto, and Meshify use Scylla and Kafka as the backend for handling their application workloads. Whether a customer is rolling out an IoT deployment for commercial fleets, consumer vehicles, remote patient monitoring, or a smart grid, our single-minded focus on the IoT market has led to scalable service offerings that are unmatched in cost efficiency, quality of service, and reliability.
Try it yourself
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.