Introducing Connector Private Networking: Join The Upcoming Webinar!
Yes, Virginia, You Really Do Need a Schema Registry
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
I ran into the schema-management problem while working with my second Hadoop customer. Until then, there was one true database and the database was responsible for managing schemas and pretty much everything else. In comparison, Hadoop and many other NoSQL systems are the wild west – schemas still exist, but there is no standard format and no enforcement – leaving each developer on their own when it comes to figuring out what data is stored in which table and directory. For the rest of the post I’m assuming the reader is already familiar with the concept as well as the importance of data schemas. For those unfamiliar we recommend to read “How I Learned to Stop Worrying and Love the Schema, part 1”
When I started working on Hadoop projects, I found myself working on the single most common Hadoop project: Data Warehouse Offloading. DWH Offloading projects are all very similar and include three main requirements:
- Dump a bunch of tables from relational databases (commonly some combination of Oracle, Teradata and Netezza) into Avro or Parquet files on HDFS using Sqoop.
- Create Hive / Impala tables from these files.
- Keep dumping new data from the databases and merging with the existing tables.
Usually, “a bunch of tables” means “around 10,000”, so automation is key. Since some Sqoop connectors can’t load data into Hive automatically, we had to dump data into Avro files and then use another script to load the data into Hive. The schema can be pretty large, so we need to store it in HDFS and just give the URI to Hive. Then a large number of other applications can start processing the data. These applications also need to be aware of the schema we previously stashed away.
Lets look at the information flow in this use-case:
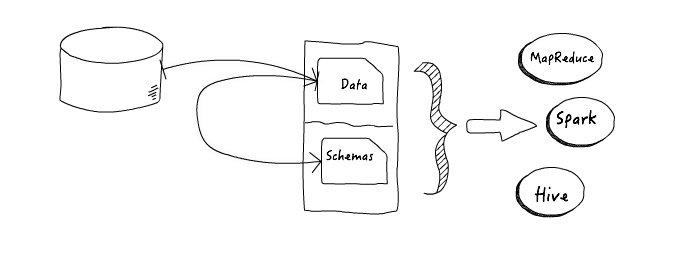
Note how critical it is to save the schemas somewhere safe – the whole process depends on our ability to get the Avro schema and share it with every app that will need to access the data. The shared schema allowed for data discovery and for different teams to use the same data for their applications and analysis. No shared schema means no data sharing.
At first those metadata directories holding the schemas were rather ad-hoc, but soon we realized that this is a common pattern.
The Importance of Shared Schema Registry
There is an important general lesson. As I wrote earlier: Schemas are critical and a shared repository of all schemas used by your organization is important to make siloed knowledge shared and explicit. Different projects need to collaborate on the same data – and to do that, they all need to know the metadata – which fields are available and what are their types. The core need is for readers to be able to understand and read data written by upstream writers, at all times.
Let’s look at the benefits of schema registry in detail:
- Tackling organizational challenges of data management: A schema registry provides a central location to agree upon schemas across all your applications — and teams — which drastically simplifies data consumption. For example, you can define a standard schema for “website clicks” that all applications will use. Upstream applications simply generate events in the agreed upon format and downstream ETL no longer needs a complex data normalization step. Unifying schemas across a large organization is still a large challenge, but a well-designed registry allows you to support a variety of mutually compatible schemas for a single logical topic (“clicks”) and still enjoy the benefits of a unified reporting pipeline.
- Resilient data pipelines: Applications and stream processing pipelines that subscribe to a data stream should be confident that a producer upstream won’t send them data they can’t handle. In this case a shared schema registry, where the reader is assured to be able to deserialize all data coming from upstream writers, makes your data pipelines much more robust.
- Safe schema evolution: Some changes to the data can require very painful re-processing of stored historical data. One example I ran into was a developer who decided to change dates from formatted String to milliseconds since 1970 stored in Long. Wise decision, but an analytics app consuming the data couldn’t handle both types, which meant that the developers had to upgrade the app before they could process new data and transform the date field in 15TB of stored data so they can continue to access it. Ouch.
With a shared registry and schema evolution, where the date schema would’ve evolved in a backwards compatible manner, this pain can be avoided. - Storage and computation efficiency: Your data storage and processing is more efficient because you don’t need to store the field names, and numbers can be stored in their more efficient binary representation rather than parsed from text.
- Data discovery: Having a central schema registry helps with data discovery, and allows data scientists to move faster without depending on the ETL teams. Ever seen a Kafka topic and wondered what’s in it, what is valid to put in it, and how the data can be used?
- Cost-efficient ecosystem: A central schema registry and the consistent use of schemas across the organization makes it much easier to justify the investment in, as well as to actually build additional, automated tooling around your data. A simple example would be a monitoring application that automatically sends email alerts to product owners as soon as upstream data sources change their data formats.
- Data policy enforcement: A schema registry is also a great instrument to enforce certain policies for your data such as preventing newer schema versions of a data source to break compatibility with existing versions — and thus breaking any existing consumer applications of this data source, which may result in service downtime or similar customer-facing problems.
Because shared schemas are so critical, I’ve implemented this process with some small variations for at least 10 different customers. All doable, but our customers were forced to reinvent the wheel time and again because this critical component was missing from their data platform.
Stream Processing and the Schema Registry
The need to manage schemas became more pronounced with the rise of real-time data and the need for stream processing. In stream processing pipelines, there are no files to act as containers for messages with a single format. Instead, we just see a stream of individual records that can be of any type, and we need an efficient way to determine the schema for each arriving record. You can’t send your schema together with each record since that incurs huge overhead — schemas are often larger than the records themselves. But if you don’t send your schema with every record – how will your stream processing tools of choice be able to process the data? How will you load the results to HBase or Impala?
Every stream processing project I’ve seen was forced to re-invent a solution to the schema management problem, just like my older ETL projects did.
Every project needing to implement some hack sooner or later points to a global need that must be addressed at the platform level. This is why we believe that Schema Registry is a must-have component for any data storage and processing platform, and especially for stream processing platforms.
This need manifests itself in various ways in practice – For example, Hive with Avro requires the schema as a parameter when creating a table. But even if an application doesn’t require the schema, the people who write the application need to know what is the fifth field and how to get the username out of the record. If you don’t provide all the developers a good way to learn more about the data, you will need to answer those questions again and again. A good schema registry allows large number of development teams to work together more efficiently.
This is why Confluent’s stream data platform includes a Schema Registry. We don’t want to force anyone to use them, and if you decide that Schemas are not applicable for your use-case, you can still use Kafka and the rest of the stream processing platform. But we believe that in many cases, a schema registry is a best practice and want to encourage its use.
Because our Schema Registry is a first-class application in the Confluent Platform, it includes several important components that are crucial for building production-ready data pipelines:
- REST API, that allows any application to integrate with our schema registry to save or retrieve schemas for the data they need to access.
- Schemas are named, and you can have multiple versions of the same schema – as long as they are all compatible under Avro’s schema evolution rules. The Schema Registry will validate compatibility and warn about possible issues. This allows different applications to add and remove fields independently, which means the development teams can move faster and the resulting apps are better decoupled.
- Serializers: Writing Avro records to Kafka is as simple as configuring a producer with the Schema Registry serializers and sending Avro objects to Kafka. Schemas are automatically registered, so the whole process of pushing new schemas to production is seamless. Same goes when reading records from Kafka. You can see examples here: https://github.com/confluentinc/examples
- Formatters: Schema Registry provides command line tools for automatically converting JSON messages to Avro and vice-versa.
Having the Schema Registry in the Confluent Platform means that from now on we can focus on making our Schema Registry better, rather than keep implementing the same thing again and again. And our customers can focus on the data and its uses, rather than reimplementing basic data infrastructure.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...