New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Consistency and Completeness: Rethinking Distributed Stream Processing in Apache Kafka
Stream processing has become an important part of the big data landscape, a new programming paradigm bringing asynchronous, long-lived computations to unbounded data in motion. But many people still think of stream processing as a complementary or auxiliary architecture—one that is real time and low latency, but as a result, is potentially transient, approximate, or lossy.
Recently, however, some streaming engines, such as Apache Kafka® and its ecosystem component Kafka Streams, have been able to claim strong correctness guarantees, with the primary dual metrics being consistency, a guarantee that a stream processing application can recover from failures to a consistent state such that final results will not contain duplicates or lose any data, and completeness, a guarantee that a stream processing application does not generate incomplete partial outputs as final results even when input stream records may arrive out of order.
Consistency: Ensuring unique and extant records
Imagine that a record is being processed in a streaming data pipeline, but just before it is committed, the process crashes. Upon system recovery, the same record will be fetched and processed again. The state will then have been updated twice, generating inconsistent output. This scenario is known as at-least-once semantics. In contrast, if the record is only committed once even when the process fails, the stream processor has successfully propagated exactly-once semantics, a key component of consistency.
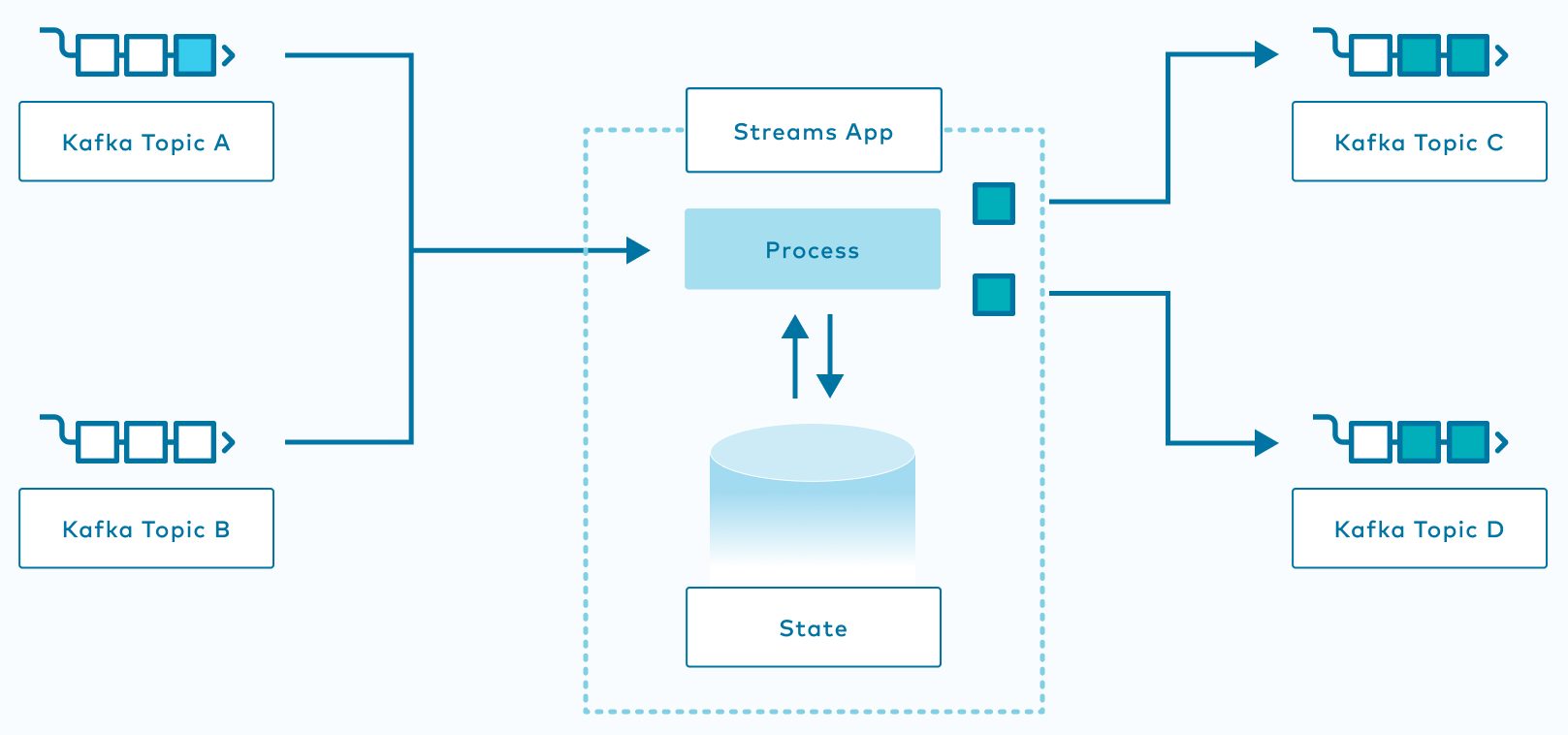
Completeness: Ensuring the correct order of records
On the happy path, the moment a record is created, known as its event time, and when a record is received and processed, known as its processing time, are the same. However, in production, this is often not the case because system clocks can be skewed, and records can be delayed at their sources or over the wire. In these cases, records are out of order in the data streams. Completeness means that even if a data stream arrives out of order, the results will ultimately be in order.
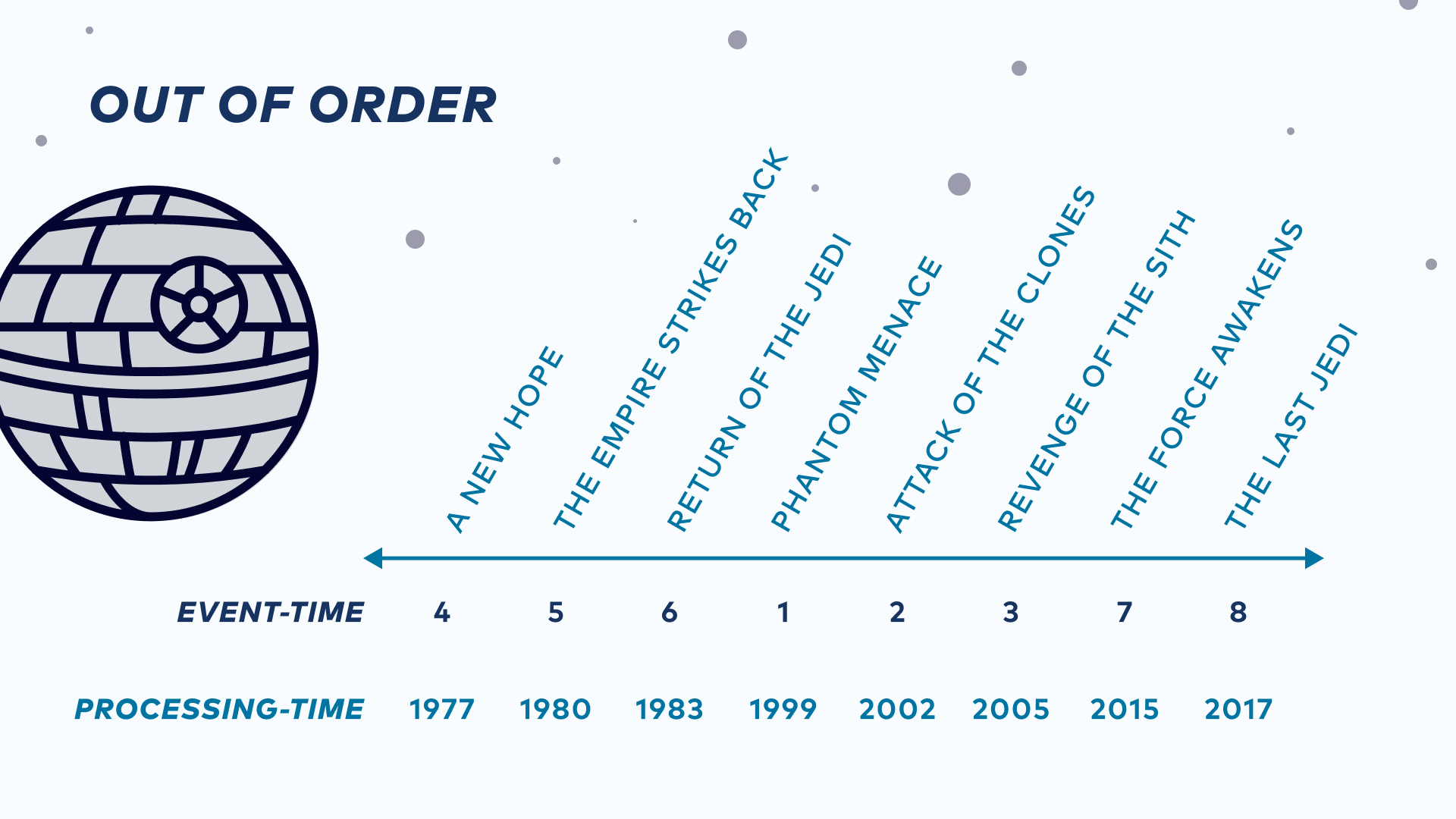
Consistency and completeness in Kafka
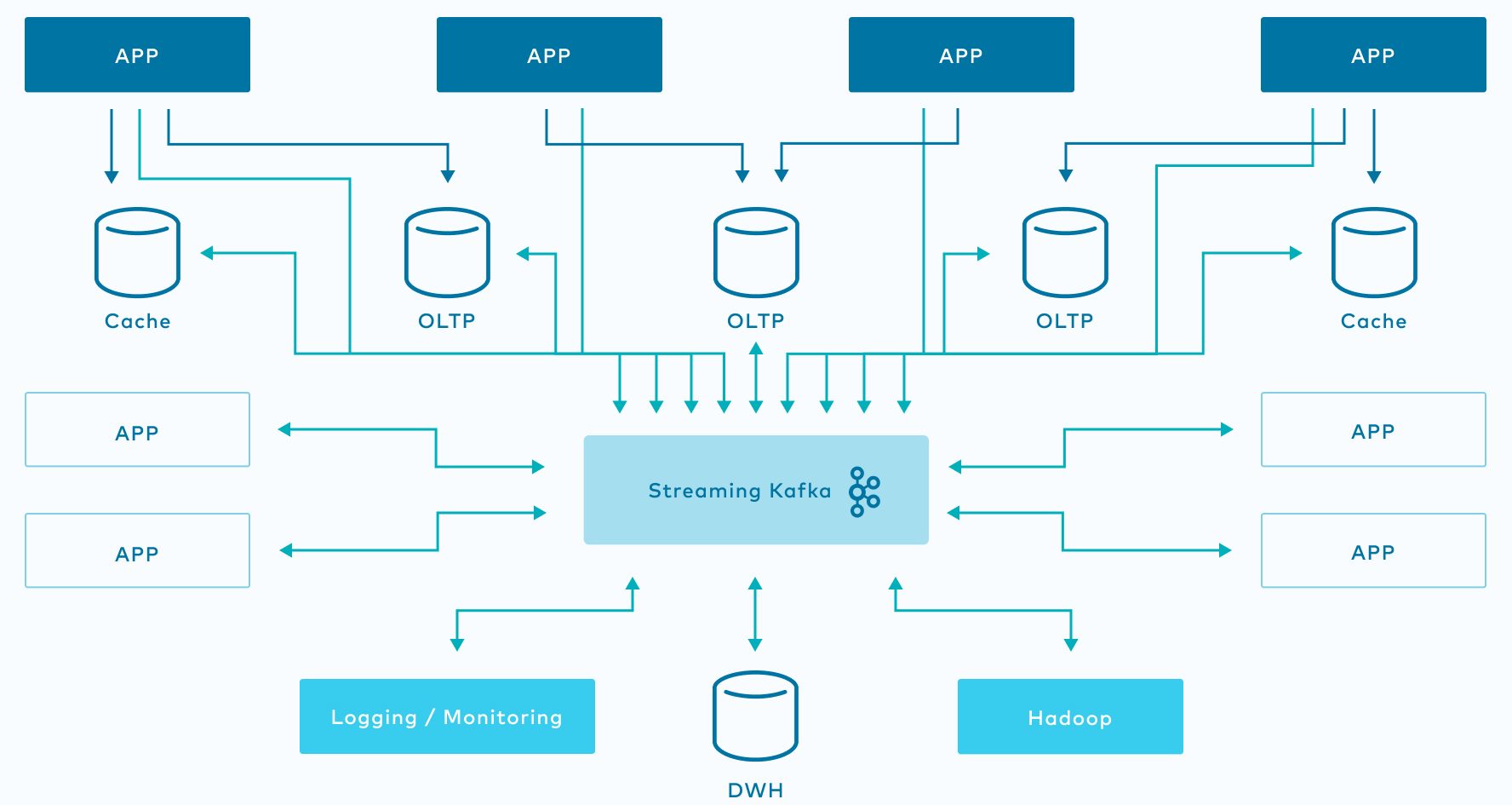
Apache Kafka addresses the dual correctness challenges by integrating stream processing with persistent logging. The key idea is that by paying a modest cost to persist streaming data, more flexible mechanisms aiming for both correctness and performance can be implemented. Kafka stores all continuous data streams as replicated append-only logs, which allows it to simplify the streaming consistency and completeness challenges by using ordered transactional log appends and replays.
Consistency and completeness in Kafka Streams
Kafka Streams, a scalable stream processing client library in Apache Kafka, decouples the consistency and completeness challenges and tackles them with separate approaches: idempotent and transactional writes for consistency, and speculative processing with revision for completeness.
The read-process-write cycles in Kafka Streams are translated as record appends to a set of Kafka logs, and a two-phase commit protocol is employed to enable idempotent and transactional appends to support exactly-once semantics. A separate speculative approach is applied to provide completeness, with revision-based mechanisms on the subset of operators that are ordering-sensitive to handle out-of-order data. Compared to many streaming frameworks that rely on a unified approach that may result in unnecessary end-to-end latencies due to intra-processor coordinations, Kafka’s log-based approach enables you to decouple the fundamental trade-off decisions between latency, throughput, and correctness guarantees.
To learn more about consistency, completeness, Kafka, and Kafka Streams, and large-scale Bloomberg and Expedia deployments, including insights regarding Kafka’s flexible and low-overhead trade-offs, download the white paper Consistency and Completeness: Rethinking Distributed Stream Processing in Apache Kafka. As a joint work between Confluent, Bloomberg, and Expedia, the white paper was recently presented at the ACM SIGMOD International Conference on Management of Data (SIGMOD) in Xi’an, Shaanxi, China, one of the most important events in the data management research field.
Next steps
- View the slides from SIGMOD 2021
- Check out these related reads:
- Enabling Exactly-Once in Kafka Streams by Guozhang Wang
- Transactions in Apache Kafka by Apurva Mehta and Jason Gustafson
- Streams and Tables: Two Sides of the Same Coin by Matthias J. Sax and Guozhang Wang
- VLDB 2015 paper on Kafka’s log replication mechanism
- BIRTE 2019 paper on the stream-table duality and processing function monotonicity
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.