New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Infrastructure Modernization with Google Anthos and Apache Kafka
The promise of cloud computing is simplicity, speed, and cost savings. But what about workloads that can’t move to the cloud? Are they stuck using expensive legacy tooling and practices? If you can’t bring these workloads to the cloud, perhaps you can bring the benefits of the cloud to these workloads. Google Anthos offers Google Cloud’s technology and best practices in the datacenter, other clouds, and the edge—all as a single pane of glass. When you want to modernize your applications and infrastructure but can’t or don’t want to migrate to the cloud, moving to Anthos is the answer.
Having a consistent, modern infrastructure across environments is a key first step toward modernizing applications, but there’s more work to be done. According to Kelsey Hightower:
There’s a ton of effort attempting to “modernize” applications at the infrastructure layer, but without equal investment at the application layer, think frameworks and application servers, we’re only solving half the problem.
— Kelsey Hightower (@kelseyhightower) April 14, 2020
Infrastructure management, container management, service management, and policy management across environments provide a strong, unified foundation for data infrastructure and applications to rest upon. These capabilities provide a solid footing for application modernization and pave the way for us to refactor applications into microservices.
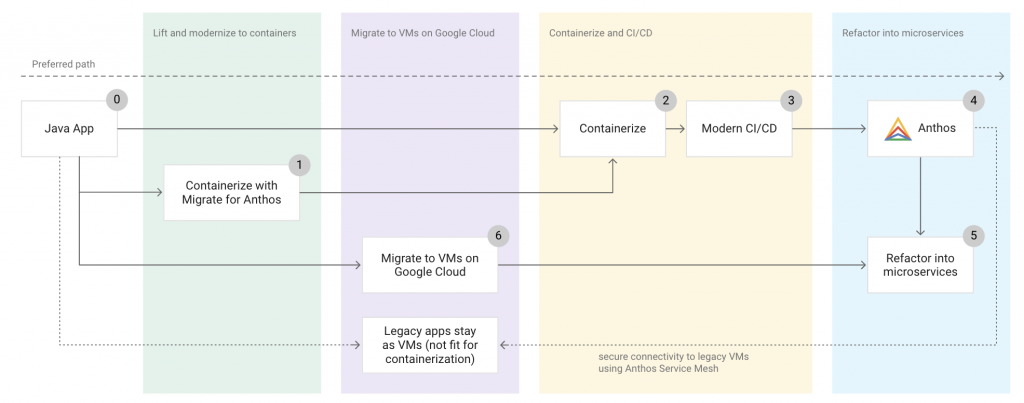
Before you refactor your applications, consider your data infrastructure and data movement. You need to enable consistent data access across environments. In the same way that Anthos unifies lower-level infrastructure across environments, Confluent unifies data infrastructure on top of Anthos.
As part of Project Metamorphosis, Confluent announced the ability to build a globally connected Apache Kafka® cluster with Cluster Linking (in preview). This means that you can now deploy Confluent Platform and Confluent Cloud across clouds and on premises and link those clusters together, effectively creating a hybrid data plane across global environments. As we continue to build a thoughtful physical and data infrastructure stack that spans environments, we’re setting the stage for the kind of unified application development that we’d expect in the cloud, except now we get that benefit everywhere.
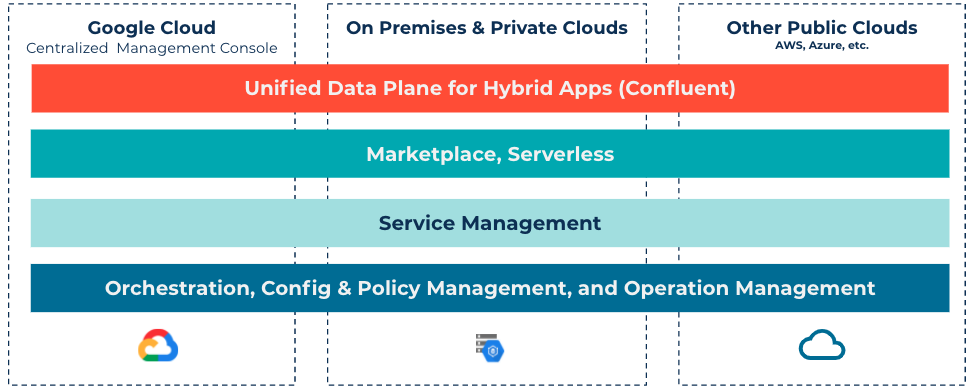
Refactoring applications
The final step in modernization is rewriting applications to take advantage of modern application development frameworks and practices. Event-driven architectures are an increasingly popular strategy for decoupling microservices. Microservices produce and consume events to and from Kafka, rather than communicating directly and synchronously.
When you build or refactor your apps to microservices, it’s ideal to remove the dependency on legacy data stores. It’s a common pattern to connect databases or legacy systems to Kafka and have applications pull data from Kafka or a modern data store being fed by Kafka, rather than directly accessing the database or legacy system. This approach has many benefits. First, it makes the data from the source system available as a stream across all environments and to all microservices. Second, it allows you to abstract the system behind Kafka and, in the case of modernizing your applications, it allows you to move away from your legacy system in the future.
Imagine a simple architecture where Kafka is used as the data plane across multiple environments, connecting applications and data stores on premises and in the cloud. Once this architecture is established, you can build applications in a modern way rather than focusing on infrastructure and data.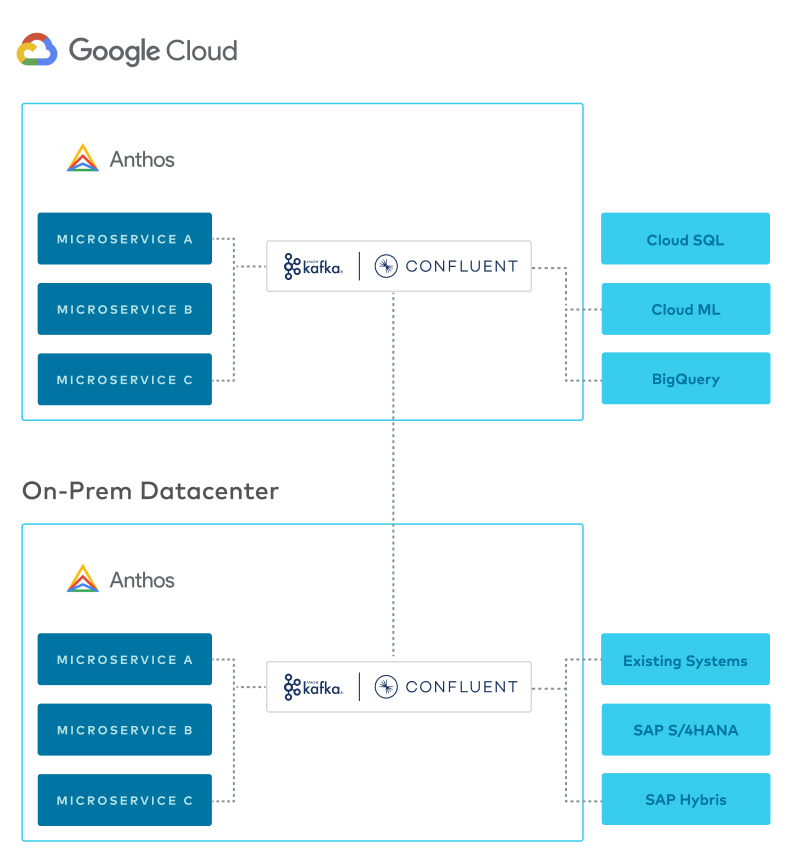
Anthos and Kafka at the edge
It’s common for hybrid architectures to extend to the “edge,” in addition to private datacenters and the cloud. The definition of “edge” is broad. Here are a few examples:
- Manufacturing plants continuously analyzing streams of data from industrial robots to enable real-time fault prevention
- Cruise ships aggregating data from local machines to the cloud after returning to port
- Apartment buildings collecting sensor data from IoT devices to monitor hardware performance & send alerts when something goes wrong
- Retail point-of-sales devices syncing sales data back into a centralized system for realtime inventory management & dynamic pricing models
These examples demonstrate collecting and processing near the data but not directly on the devices. Often, this becomes a hub-and-spoke architecture where you want to do some local aggregation and processing, and also want some of that data to land in the cloud or datacenter.
Deploying across edge sites and providing a consistent environment is important when you have a few datacenters and clouds. However, it becomes a requirement when you are deploying to tens or even thousands of geographically distributed sites. The ability to monitor, update, and secure your applications in a consistent way allows these architectures to be sustainable.
Edge processing might not seem like a good fit for Kafka initially. Many think of Kafka as a heavy distributed system that is “too much” for the edge and hard to manage. Using tools like Confluent Operator on Anthos to ease the management burden, Kafka provides a lot of value and has number of features that make it well suited for edge deployments:
- Persistent storage: Edge sites often have inconsistent connections to the cloud or datacenter. Kafka stores data durably, enabling replay at the time of connectivity.
- Stream processing: It’s often desired to do some amount of stream processing at the edge, like filtering, anomaly detection, or streaming ETL, before sending curated streams back to centralized systems
- Connecting systems: Edge deployments typically have a requirement to consume data from a variety of data sources. The ecosystem of connectors for Kafka and Confluent allows seamless integration.
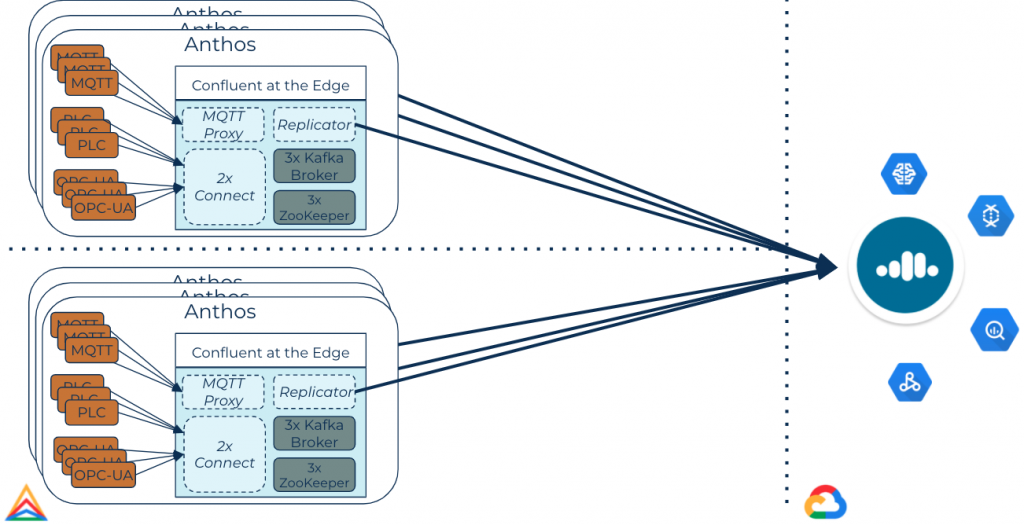
Edge manufacturing scenario
Imagine a manufacturing company with multiple plants around the world that build widgets using advanced robots, each equipped with sensors to track various performance metrics. This company wants to anticipate component failures and preemptively order replacement parts to avoid downtime and maximize productivity and safety. To enable this capability, sensor data from the robots flows to Kafka at the plant, via Kafka Connect à la MQTT, PLC, OPC-UA, or something similar.
Kafka Streams applications are running at the plant doing real-time stream processing and looking for anomalies or wear patterns. Alerts get triggered from the Streams app whenever anomalies are detected, saving time and money. Curated streams are pushed to Confluent Cloud in near real time for further processing and analytics. Data flows seamlessly back to the edge via Kafka. Of course, this is all running on Anthos, where you can deploy, monitor, and manage the applications and infrastructure from Google Cloud.
You don’t have to only imagine a scenario like this, but you can make it happen.
Make it your own
The world is increasingly moving to the cloud, but that movement will not happen overnight, nor will it ever happen entirely. The future is not a binary state of either cloud computing or legacy on-prem infrastructure. It is an ever-evolving symphony of databases, applications, and data processing systems that harmoniously ebb and flow to the tune of the constantly changing requirements of its users, wherever they may be. It is a hybrid future. Combining Anthos and Kafka set the stage for this symphony to be conducted, with you as the conductor.
Take Anthos and Confluent Cloud for a free test drive with Google Cloud’s sample Anthos environment or with a free trial, and start writing your magnum opus for hybrid infrastructure today!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.