New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Introducing KSQL: Streaming SQL for Apache Kafka
I’m really excited to announce KSQL, a streaming SQL engine for Apache Kafka®. KSQL lowers the entry bar to the world of stream processing, providing a simple and completely interactive SQL interface for processing data in Kafka. You no longer need to write code in a programming language such as Java or Python! KSQL is distributed, scalable, reliable, and real time. It supports a wide range of powerful stream processing operations including aggregations, joins, windowing, sessionization, and much more.
A Simple Example
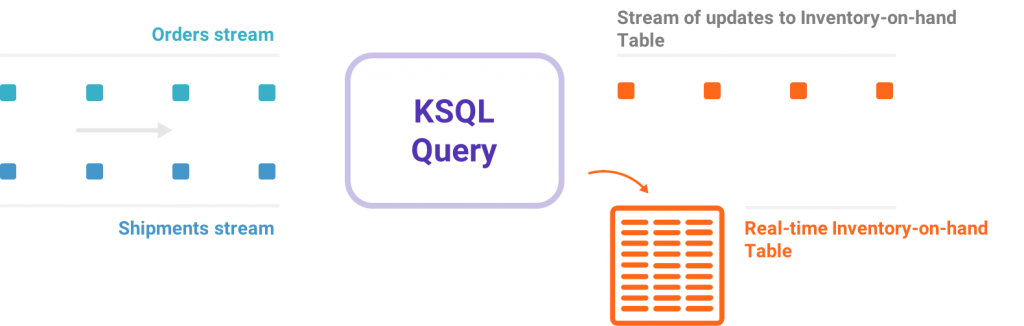
What does it even mean to query streaming data, and how does this compare to a SQL database?
Well, it’s actually quite different to a SQL database. Most databases are used for doing on-demand lookups and modifications to stored data. KSQL doesn’t do lookups (yet), what it does do is continuous transformations— that is, stream processing. For example, imagine that I have a stream of clicks from users and a table of account information about those users being continuously updated. KSQL allows me to model this stream of clicks, and table of users, and join the two together. Even though one of those two things is infinite.
So what KSQL runs are continuous queries — transformations that run continuously as new data passes through them — on streams of data in Kafka topics. In contrast, queries over a relational database are one-time queries — run once to completion over a data set—as in a SELECT statement on finite rows in a database.
What is KSQL Good For?
Great, so you can continuously query infinite streams of data. What is that good for?
1. Real-time monitoring meets real-time analytics
CREATE TABLE error_counts AS SELECT error_code, count(*)FROM monitoring_stream WINDOW TUMBLING (SIZE 1 MINUTE) WHERE type = 'ERROR'
One use of this is defining custom business-level metrics that are computed in real-time and that you can monitor and alert off of, just like you do your CPU load. Another use is to define a notion of correctness for your application in KSQL and check that it is meeting this as it runs in production. Often when we think of monitoring we think about counters and gauges tracking low level performance statistics. These kinds of gauge often can tell you that your CPU load is high, but they can’t really tell you if your application is doing what it’s supposed to do. KSQL allows defining custom metrics off of streams of raw events that applications generate, whether they are logging events, database updates, or any other kind.
For example, a web app might need to check that every time a new customer signs up a welcome email is sent, a new user record is created, and their credit card is billed. These functions might be spread over different services or applications and you would want to monitor that each thing happened for each new customer within some SLA, like 30 secs.
2. Security and anomaly detection
CREATE TABLE possible_fraud AS SELECT card_number, count(*) FROM authorization_attempts WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY card_number HAVING count(*) > 3;
A simple version of this is what you saw in the demo above: KSQL queries that transform event streams into numerical time series aggregates that are pumped into Elastic using the Kafka-Elastic connector and visualized in a Grafana UI. Security use cases often look a lot like monitoring and analytics. Rather than monitoring application behavior or business behavior you’re looking for patterns of fraud, abuse, spam, intrusion, or other bad behavior. KSQL gives a simple, sophisticated, and real-time way of defining these patterns and querying real-time streams.
3. Online data integration
CREATE STREAM vip_users AS SELECT userid, page, action FROM clickstream c LEFT JOIN users u ON c.userid = u.user_id WHERE u.level = 'Platinum';
Much of the data processing done in companies falls in the domain of data enrichment: take data coming out of several databases, transform it, join it together, and store it into a key-value store, search index, cache, or other data serving system. For a long time, ETL — Extract, Transform, and Load — for data integration was performed as periodic batch jobs. For example, dump the raw data in real time, and then transform it every few hours to enable efficient queries. For many use cases, this delay is unacceptable. KSQL, when used with Kafka connectors, enables a move from batch data integration to online data integration. You can enrich streams of data with metadata stored in tables using stream-table joins, or do simple filtering of PII (personally identifiable information) data before loading the stream into another system.
4. Application Development
Many applications transform an input stream into an output stream. For example, a process responsible for reordering products that are running low in inventory for an online store might feed off a stream of sales and shipments to compute a stream of orders to place.
For more complex applications written in Java, Kafka’s native streams API may be just the thing. But for simple apps, or teams not interested in Java programming a simple SQL interface may be what they’re looking for.
Core Abstractions in KSQL
KSQL uses Kafka’s Streams API internally and they share the same core abstractions for stream processing on Kafka. There are two core abstractions in KSQL that map to the two core abstractions in Kafka Streams and allow you to manipulate Kafka topics:
1. STREAM: A stream is an unbounded sequence of structured data (“facts”). For example, we could have a stream of financial transactions such as “Alice sent $100 to Bob, then Charlie sent $50 to Bob”. Facts in a stream are immutable, which means new facts can be inserted to a stream, but existing facts can never be updated or deleted. Streams can be created from a Kafka topic or derived from existing streams and tables.
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR)
WITH (kafka_topic='pageviews', value_format=’JSON’);
2. TABLE: A table is a view of a STREAM or another TABLE and represents a collection of evolving facts. For example, we could have a table that contains the latest financial information such as “Bob’s current account balance is $150”. It is the equivalent of a traditional database table but enriched by streaming semantics such as windowing. Facts in a table are mutable, which means new facts can be inserted to the table, and existing facts can be updated or deleted. Tables can be created from a Kafka topic or derived from existing streams and tables.
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR)
WITH (kafka_topic='users', value_format='DELIMITED');
KSQL simplifies streaming applications as it fully integrates the concepts of tables and streams, allowing joining tables that represent the current state of the world with streams that represent events that are happening right now. A topic in Apache Kafka can be represented as either a STREAM or a TABLE in KSQL, depending on the intended semantics of the processing on the topic. For instance, if you want to read the data in a topic as a series of independent values, you would use CREATE STREAM. An example of such a stream is a topic that captures page view events where each page view event is unrelated and independent of another. If, on the other hand, you want to read the data in a topic as an evolving collection of updatable values, you’d use CREATE TABLE. An example of a topic that should be read as a TABLE in KSQL is one that captures user metadata where each event represents latest metadata for a particular user id, be it user’s name, address or preferences.
KSQL in Action: Real-time clickstream analytics and anomaly detection
Let’s get down to a real demo. This demo shows how you can use KSQL for real-time monitoring, anomaly detection, and alerting. Real-time log analytics on clickstream data can take several forms. In this example, we flag malicious user sessions that are consuming too much bandwidth on our web servers. Monitoring malicious user sessions is one of many applications of sessionization. But broadly, sessions are the building blocks of user behavior analysis. Once you’ve associated users and events to a particular session identifier, you can build out many types of analyses, ranging from simple metrics, such as count of visits, to more complex metrics, such as customer conversion funnels and event flows. We end this demo by showing how you can visualize the output of KSQL queries continuously in real-time on a Grafana dashboard backed by Elastic.
You can also follow our instructions to step through the demo yourself and see the code, too.
A Look Inside
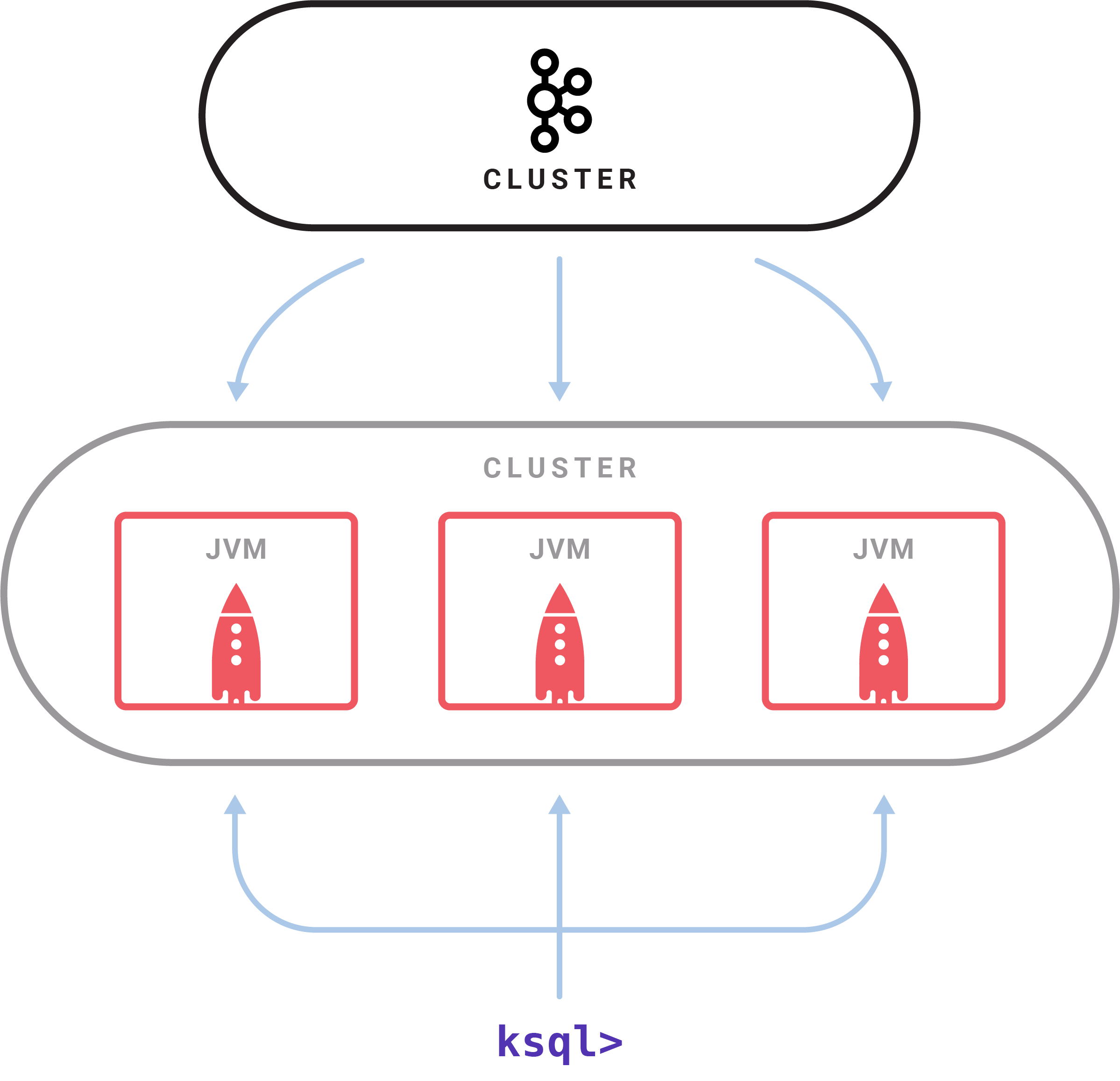 There is a KSQL server process which executes queries. A set of KSQL processes run as a cluster. You can dynamically add more processing capacity by starting more instances of the KSQL server. These instances are fault-tolerant: if one fails, the others will take over its work. Queries are launched using the interactive KSQL command line client which sends commands to the cluster over a REST API. The command line allows you to inspect the available streams and tables, issue new queries, check the status of and terminate running queries. Internally KSQL is built using Kafka’s Streams API; it inherits its elastic scalability, advanced state management, and fault tolerance, and support for Kafka’s recently introduced exactly-once processing semantics. The KSQL server embeds this and adds on top a distributed SQL engine (including some fancy stuff like automatic byte code generation for query performance) and a REST API for queries and control.
There is a KSQL server process which executes queries. A set of KSQL processes run as a cluster. You can dynamically add more processing capacity by starting more instances of the KSQL server. These instances are fault-tolerant: if one fails, the others will take over its work. Queries are launched using the interactive KSQL command line client which sends commands to the cluster over a REST API. The command line allows you to inspect the available streams and tables, issue new queries, check the status of and terminate running queries. Internally KSQL is built using Kafka’s Streams API; it inherits its elastic scalability, advanced state management, and fault tolerance, and support for Kafka’s recently introduced exactly-once processing semantics. The KSQL server embeds this and adds on top a distributed SQL engine (including some fancy stuff like automatic byte code generation for query performance) and a REST API for queries and control.
Kafka + KSQL turn the database inside out
We’ve talked in the past about turning the database inside out, now we’re making it real by adding a SQL layer to our inside-out DB.
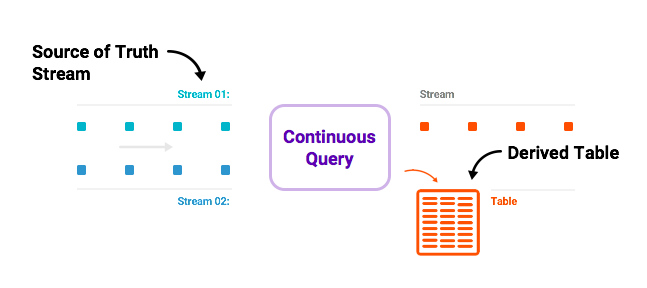
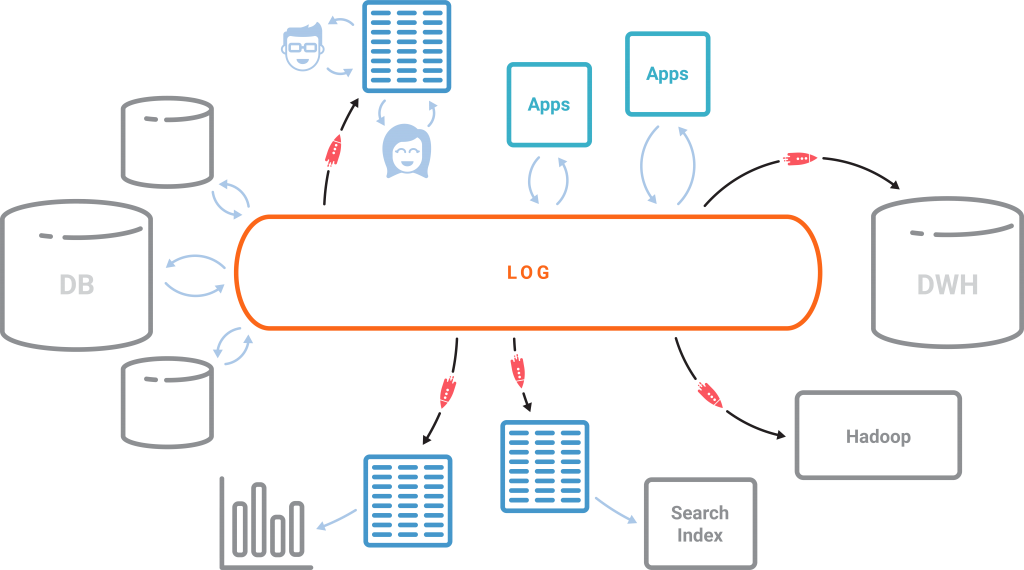
In a relational database, the table is the core abstraction and the log is an implementation detail. In an event-centric world with the database is turned inside out, the core abstraction is not the table; it is the log. The tables are merely derived from the log and updated continuously as new data arrives in the log. The central log is Kafka and KSQL is the engine that allows you to create the desired materialized views and represent them as continuously updated tables. You can then run point-in-time queries (coming soon in KSQL) against such streaming tables to get the latest value for every key in the log, in an ongoing fashion.
Turning the database inside out with Kafka and KSQL has a big impact on what is now possible with all the data in a company that can naturally be represented and processed in a streaming fashion. The Kafka log is the core storage abstraction for streaming data, allowing same data that went into your offline data warehouse is to now be available for stream processing. Everything else is a streaming materialized view over the log, be it various databases, search indexes, or other data serving systems in the company. All data enrichment and ETL needed to create these derived views can now be done in a streaming fashion using KSQL. Monitoring, security, anomaly and threat detection, analytics, and response to failures can be done in real-time versus when it is too late. All this is available for just about anyone to use through a simple and familiar SQL interface to all your Kafka data: KSQL.
What’s Next for KSQL?
We are releasing KSQL as a developer preview to start building the community around it and gathering feedback. We plan to add several more capabilities as we work with the community to turn it into a production-ready system from quality, stability, and operability of KSQL to supporting a richer SQL grammar including further aggregation functions and point-in-time SELECT on continuous tables–i.e., to enable quick lookups against what’s computed so far in addition to the current functionality of continuously computing results off of a stream.
How Do I Get KSQL?
You can get your hands dirty by playing with the KSQL quick start and the aforementioned demo. We’d love to hear about anything you think is missing or ways it can be improved: chime in on the #ksql channel on the Confluent Community Slack with any thoughts or feedback, and file a GitHub issue if you spot a bug; we’d love to work really closely with early adopters kicking the tires so don’t be shy. We look forward to collaborating with the rest of the open source community to evolve KSQL into something fantastic.
If you’re interested in what KSQL can do:
- Watch the introductory video of KSQL
- Learn about KSQL on the Streaming Audio podcast
- Get started with KSQL in Confluent Cloud and receive $400 to spend within Confluent Cloud during your first 60 days, plus an additional $60 of free usage when you use the promo code CL60BLOG*
Finally, if you’re interested in stream processing and want to help build KSQL, Confluent is hiring 🙂
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.