[Demo] Design Event-Driven Microservices for Cloud → Register Now
How to Better Manage Apache Kafka with Improved Topic Inspection via Last-Produced Timestamp
This blog post is the third in a four-part series that discusses a few new Confluent Control Center features that are introduced with Confluent Platform 6.2.0. It focuses on inspecting Apache Kafka® topics better with a newly added last-produced timestamp column in the Control Center UI. The series highlights the following new features that make managing clusters via Control Center an even smoother experience:
- Create Kafka messages (with key and value) directly from within Control Center
- Export Kafka messages in JSON or CSV format via Control Center
- Improved topic inspection by showing the last time that a message was produced to a topic
- Remove residue data from old Control Center instances with a cleanup script
If you are not too familiar with Control Center, you can always refer to the Control Center overview first. Having a running Control Center instance at hand helps you explore the features discussed in this blog series better.
Now that you are ready, let’s delve into the third feature here in part 3: improved topic inspection via last-produced timestamp.
- What “improved topic inspection” is: A description of the feature and its usage
- How it works internally: Learn more about the internal implementation and about the feature’s limitations
What “improved topic inspection” is
The “Topics” overview page gives a summary—health, throughput—of all the topics for a cluster. Confluent Platform 6.2.0 introduces a new column, “Last produced,” which reports the timestamp of the latest message produced to each topic. Using this report, you can easily compare and identify the topics that have not been produced in a long time.
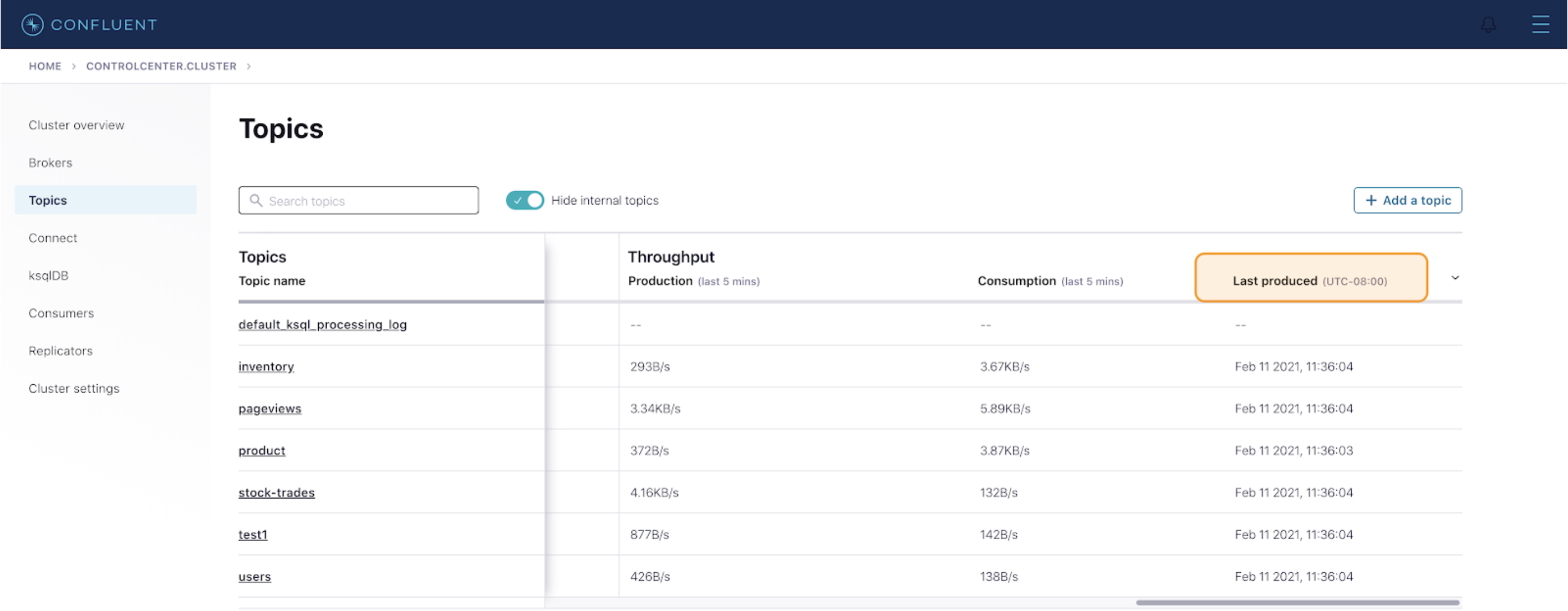
There are a few important caveats to note:
- The timestamp is only refreshed when you refresh the “Topics” overview page
- You currently cannot sort by the “Last produced” column
- -- means that no timestamp was obtained within a certain timeout
The following section provides the technical rationale behind these specific limitations.
How it works internally
Currently, KafkaConsumer does not provide a direct way of accessing the last message, or its timestamp, produced to a topic. Therefore, Control Center uses an internal KafkaConsumer to actually consume messages and find the last produced timestamp for each topic.
To obtain a last-produced timestamp, the internal Control Center consumer performs the following:
- Finds the end offsets for a set of partitions, using KafkaConsumer::endOffsets().
- Seeks the end offsets for the partitions, using KafkaConsumer::seek().
- Polls messages from the partitions and finds the latest timestamp from the messages returned, using KafkaConsumer::poll(). It’s important to note that poll(Duration timeout) either returns immediately if there are any messages available from the given partitions, or it waits until timeout.
The internal Control Center consumer performs the above procedure to obtain the last-produced timestamp per topic, giving each topic—active or dormant—an equal amount of time to poll and return a valid timestamp (dormant means that no messages or rarely any messages are produced to a topic). More importantly, the internal Control Center consumer performs the above procedure asynchronously for each topic, such that if one dormant topic’s poll is awaiting timeout, it would not hinder other topics’ poll to return valid timestamps.
There are specific reasons behind the three caveats described earlier:
- The timestamp is only refreshed when you refresh the “Topics” overview page.
Because KafkaConsumer::poll() could timeout in the case of dormant topics, obtaining the last-produced timestamp is a relatively expensive API call. Therefore, we only obtain new timestamps when necessary, for example, a page refresh.
- The UI does not support sorting by “Last produced” column.
The Control Center UI does not currently support sorting on a column, where its values are obtained separately per topic. Because we obtain the last-produced timestamp asynchronously per topic, we do not currently support sorting the topics by this column.
- -- means that no timestamp was obtained within a certain timeout.
Currently, the timeout of KafkaConsumer::poll() is set to five seconds in the internal Control Center consumer. This means that if no messages are returned by poll within five seconds, we assume that fetching the last-produced timestamp failed for this topic. This could happen to any dormant topic. We do not try to obtain the last-produced timestamp for this topic until the next time that the page is refreshed.
Summary
In summary, improved topic inspection via last-produced timestamp is a beta feature that allows you to better distinguish dormant versus active topics by seeing when a message is last produced. Enhancements are on the way for future releases to eliminate all the current limitations.
Other articles in this series
To learn about other new features of Control Center 6.2.0, check out the remaining blog posts in this series:
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Amazon OpenSearch Ingestion Adds Support for Confluent Cloud as Source
Discuss how to use OpenSearch Ingestion to integrate Confluent with Amazon OpenSearch.


Best Practices for Confluent Terraform Provider
The blog post delves into best practices and recommendations for utilizing the Confluent Terraform Provider. It offers insights on efficiently provisioning resources within Confluent Cloud infrastructure while ensuring adherence to industry standards. Additionally, it provides a GitHub repository...