New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Announcing ksqlDB 0.21.0
We’re pleased to announce ksqlDB 0.21.0! This release includes a major upgrade to ksqlDB’s foreign-key joins, the new data type BYTES, and a new ARRAY_CONCAT function. All of these features are now available in Confluent Cloud. We’re excited to share them with you, and we will cover the most notable changes in this blog post. Check out the changelog for a complete list of features and fixes.
Expressions in foreign-key table-table joins
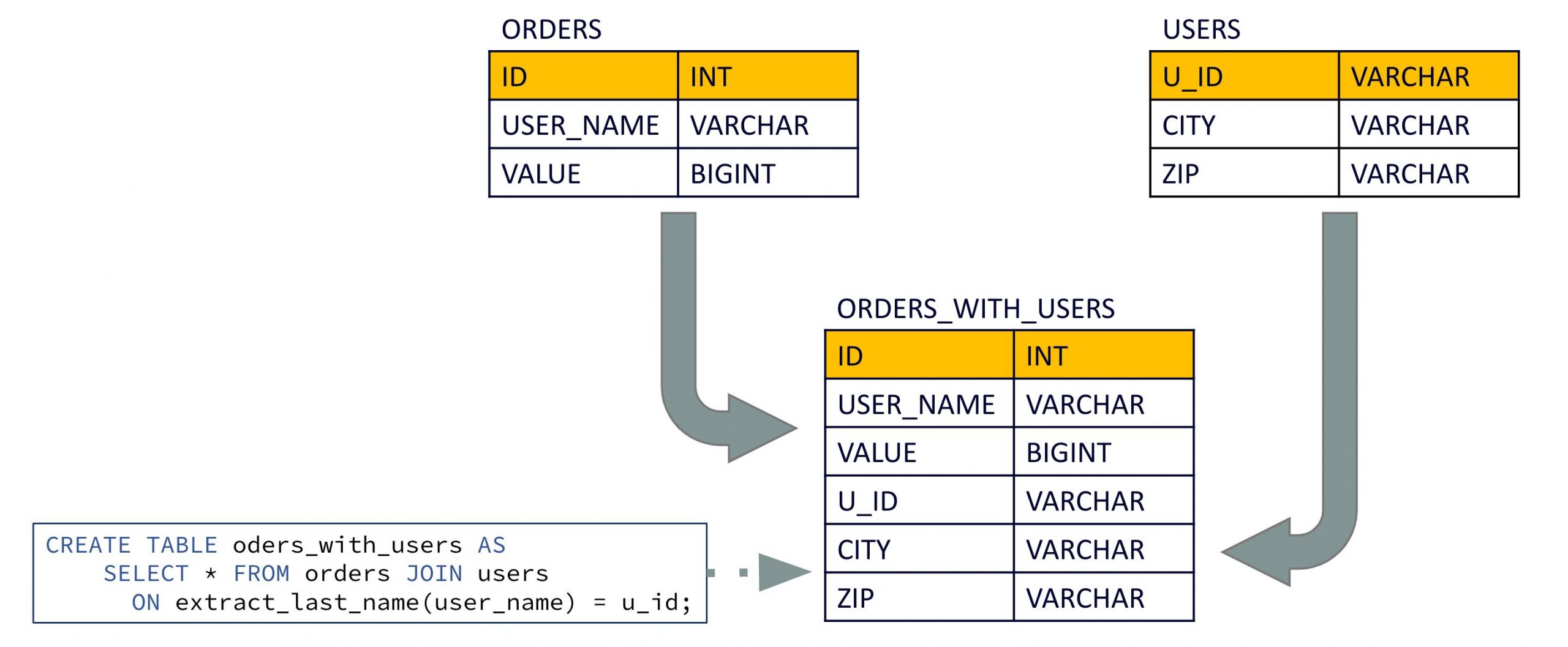
When foreign-key table-table joins were announced in ksqlDB 0.19, they only allowed you to use a column of the left input table as foreign-key reference. With the 0.21 release, you can now use an arbitrary expression to define the foreign key:
CREATE TABLE orders_with_users AS SELECT * FROM orders JOIN users ON extract_last_name(user_name) = u_id EMIT CHANGES;
The above query applies a UDF extract_last_name() to compute the foreign key based on the columns of the left input table.
Represent byte arrays using the BYTES data type
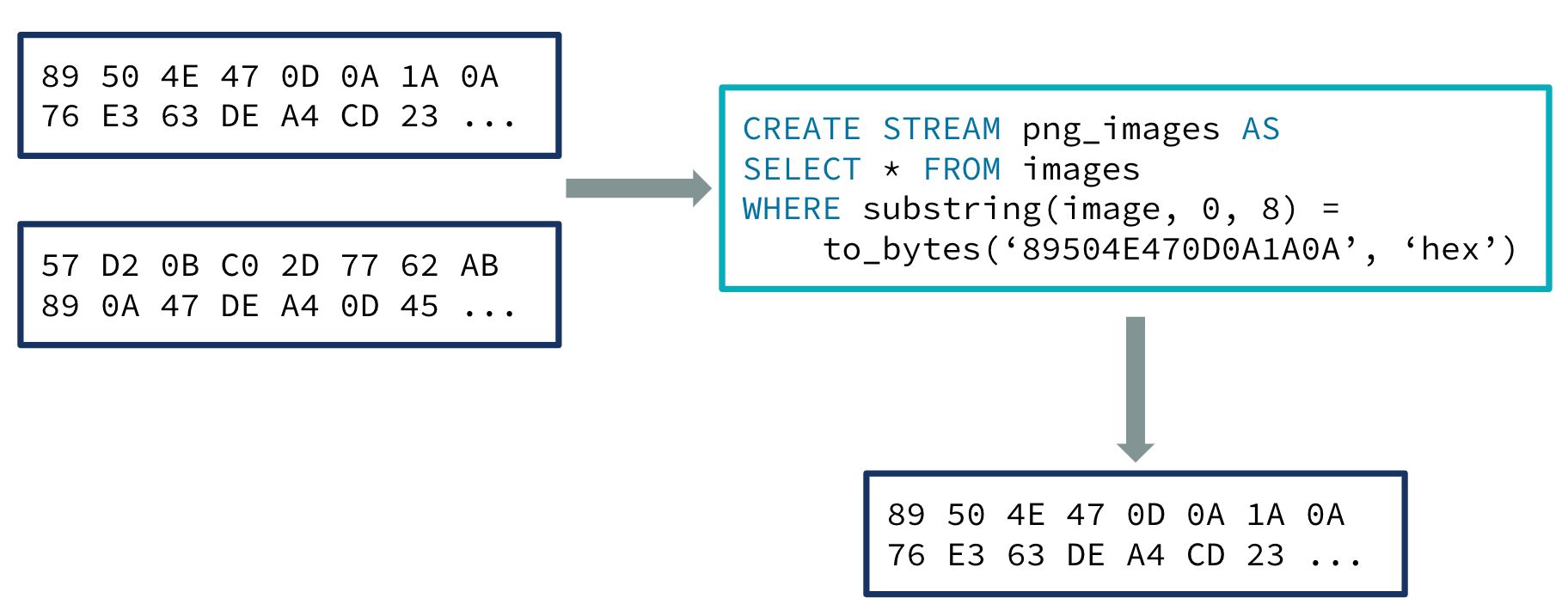
ksqlDB 0.21 includes the BYTES data type, which represents binary strings. It can be used to handle data that doesn’t fit into any of the other supported types, such as images, as well as blob/binary data from other databases.
Most of the STRING functions, such as SUBSTRING and CONCAT, have also been updated to accept BYTES inputs. The new functions TO_BYTES and FROM_BYTES allow conversion between STRING and BYTES data.
Consider the following example, where we use ksqlDB to filter a stream of image data based on the byte signature of the PNG format:
CREATE STREAM images (name STRING, image BYTES)
WITH (kafka_topic='images', value_format='json');
CREATE STREAM png_images AS SELECT * FROM images WHERE SUBSTRING(image, 0, 8) = TO_BYTES('89504E470D0A1A0A', 'hex');
New ARRAY_CONCAT function
We have also added a new user-defined function for arrays, ARRAY_CONCAT, which returns an array representing the concatenation of the input arrays.
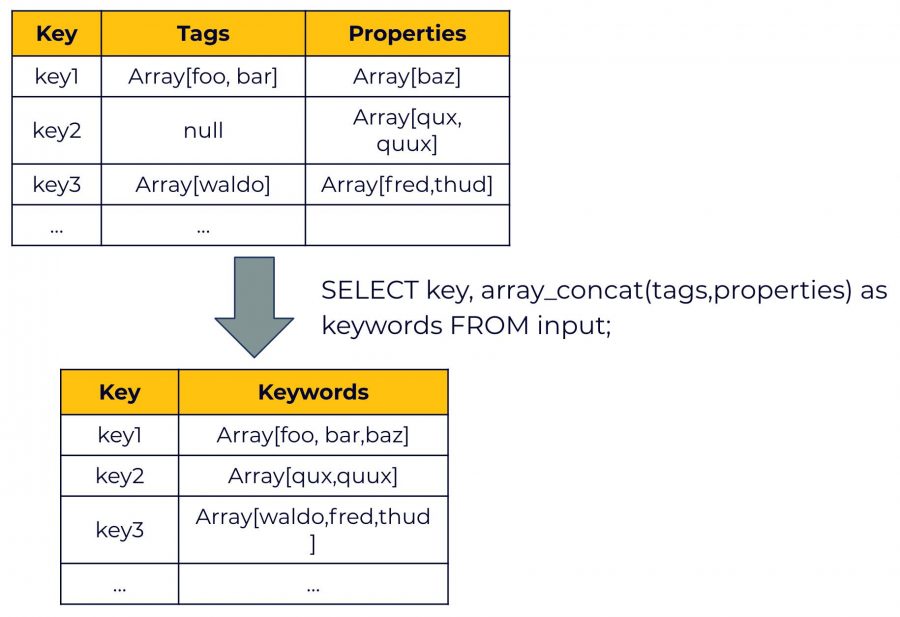
The example below uses ARRAY_CONCAT and REDUCE to flatten a column containing nested arrays. This mimics a “flatMap” transformation for the first level of nesting:
CREATE TABLE INPUT (id STRING PRIMARY KEY, nested_array ARRAY<ARRAY<INT>>) WITH (kafka_topic='test_topic', value_format='JSON', partitions=1);
CREATE TABLE OUTPUT AS SELECT id, REDUCE(nested_array, ARRAY_REMOVE(ARRAY[0],0), (flattened, item) => ARRAY_CONCAT(flattened, item)) as result FROM INPUT;
INSERT INTO INPUT (id, nested_array) VALUES ('first', ARRAY[ARRAY[1,2],ARRAY[3],ARRAY[4,5,6]]);
INSERT INTO INPUT (id, nested_array) VALUES ('second', ARRAY[ARRAY[4,5],ARRAY[5],ARRAY[6,7,7]]);
ksql> select * from OUTPUT;
+---------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------+
|ID |RESULT |
+---------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------+
|first |[1, 2, 3, 4, 5, 6] |
|second |[4, 5, 5, 6, 7, 7]
Note that the example above uses ARRAY_REMOVE(ARRAY[0], 0) to create an empty ARRAY<INT>. In a future release, we plan to introduce syntax to initialize empty arrays without this workaround.
Get started with ksqlDB
Get started with ksqlDB today, via the standalone distribution or with Confluent, and join the community to ask questions and find new resources.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.