New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Crossing the Streams: The New Streaming Foreign-Key Join Feature in Kafka Streams
Companies adopt streaming data and Apache Kafka® because it provides them with real-time information about their business and customers. In practice, the challenge is that this information is spread across the organization and across different systems, databases, and applications. A fundamental operation in streaming data (and in traditional databases) is enriching data from multiple sources using joins. When a data system provides only primary-key join support, then the result is unneeded code complexity for developers as well as inefficient resource usage at application runtime. In this blog post, we describe in detail the foreign-key joins first released in December 2019 as part of Apache Kafka 2.4 and Confluent Platform 5.4. We use a running example application to discuss the new implementation in detail, and also cover internal optimizations and testing.
Background
To understand how this feature works and why it is interesting, it’s important to understand a few basics about Kafka Streams first. Streams offers a dual stream-table processing model. This model has been discussed at length, but what it means in a nutshell is that although Kafka Streams is a “stream processing” framework (that is, it computes continuously over infinite inputs), there are different sets of abstractions that make sense when you need to describe computations over sequences of unique events (a stream) or materialized views over continuously updating records (a table). Kafka Streams offers the KStream abstraction for describing stream operations and the KTable for describing table operations. The foreign-key join is an advancement in the KTable abstraction.
Kafka Streams is also a distributed stream processing system, meaning that we have designed it with the ability to scale up by adding more computers. Of course, you can always scale up a data system by swapping in better computers (faster CPUs, more memory, and more disk), but it’s also essential to be able to scale out by adding more computers, particularly for cost savings and resiliency. Kafka Streams fully exploits this design to provide high availability for both the streaming computation and ad hoc queries of the results. What this means for foreign-key joins in particular is that Streams can’t expect to have both sides of the join available on the same computer. It can’t even assume that both sides of the join would fit on the same computer. As with many of the operations Streams provides, the system encapsulates all the complex logic required to perform distributed foreign-key joins so that your code can be simpler and cleaner.
Before 2.4.0, the absence of foreign-key joins in Kafka Streams was palpable. As soon as you have a KTable abstraction, you start to think of relational-DB-esque things that you’d like to do with it, and joining two tables is near the top of the list. In addition, Kafka users often started out by implementing change data capture (CDC) of their main database tables, resulting in the production of normalized record streams reflecting the database model. These records often contain foreign-key references, requiring you to either denormalize entirely within your source database (which can be quite expensive), or handle them downstream in your consumer. The ability to compute denormalization on the fly is exactly in the sweet spot of use cases for Kafka Streams.
In versions prior to 2.4, there were workarounds available to compute a foreign-key join, using the ability to transform the table, filter it, aggregate on properties, and join on primary keys. But these workarounds were complex, prone to bugs, and not very efficient. A concrete plan to implement first-class support for this crucial operation was first put together when Jan Filipiak proposed KIP-213 in 2017. Adam Bellemare took over driving the proposal in 2018 and brought it to a conclusion in time for the 2.4.0 release.
This problem is quite complex. There are many ways to approach it and many primary and secondary factors to consider. What is notable about this process, though, is that neither Jan nor Adam are paid contributors. They are skilled software engineers who use Kafka Streams, saw the utility of this feature, and had the creativity and tenacity to bring an exceptionally complex piece of technology to life.
Example use case: An online marketplace
This post will use the running example of a marketplace application with two primary datasets: merchants who sell in the marketplace and the Products that they sell. To build out the example, we’ll be working with the following schema:
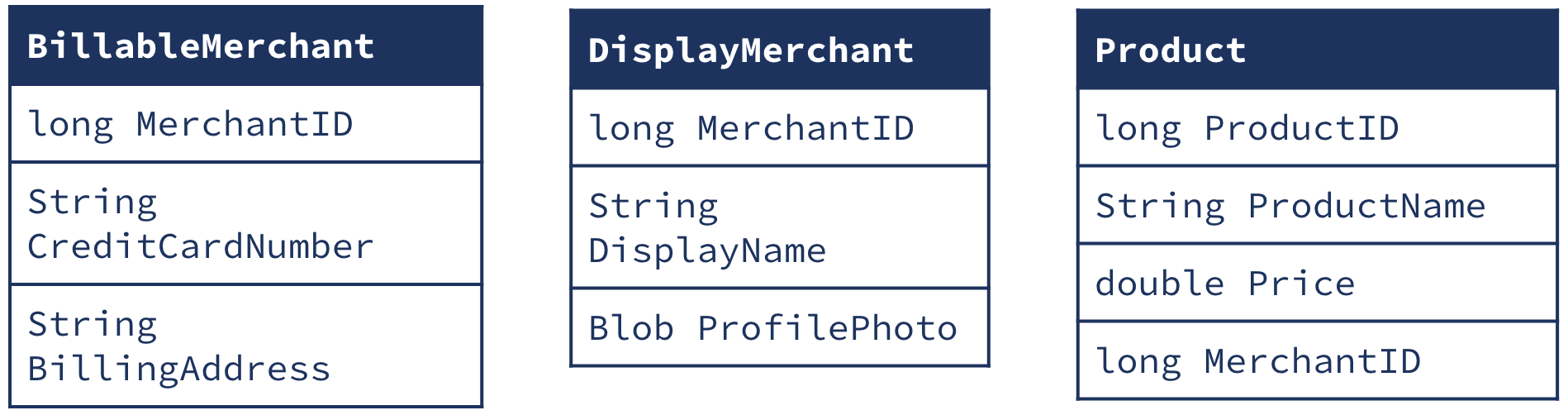
Joining KTables
A KTable is a materialization of the event stream. Each row in the KTable data structure is based on the unique key of the event. When a new record is received for that key, the value of the KTable is overwritten, and the updated row is propagated downstream to the subsequent operators.
myTable = builder.table("Input Topic")
result = myTable.mapValue(x -> x*2)
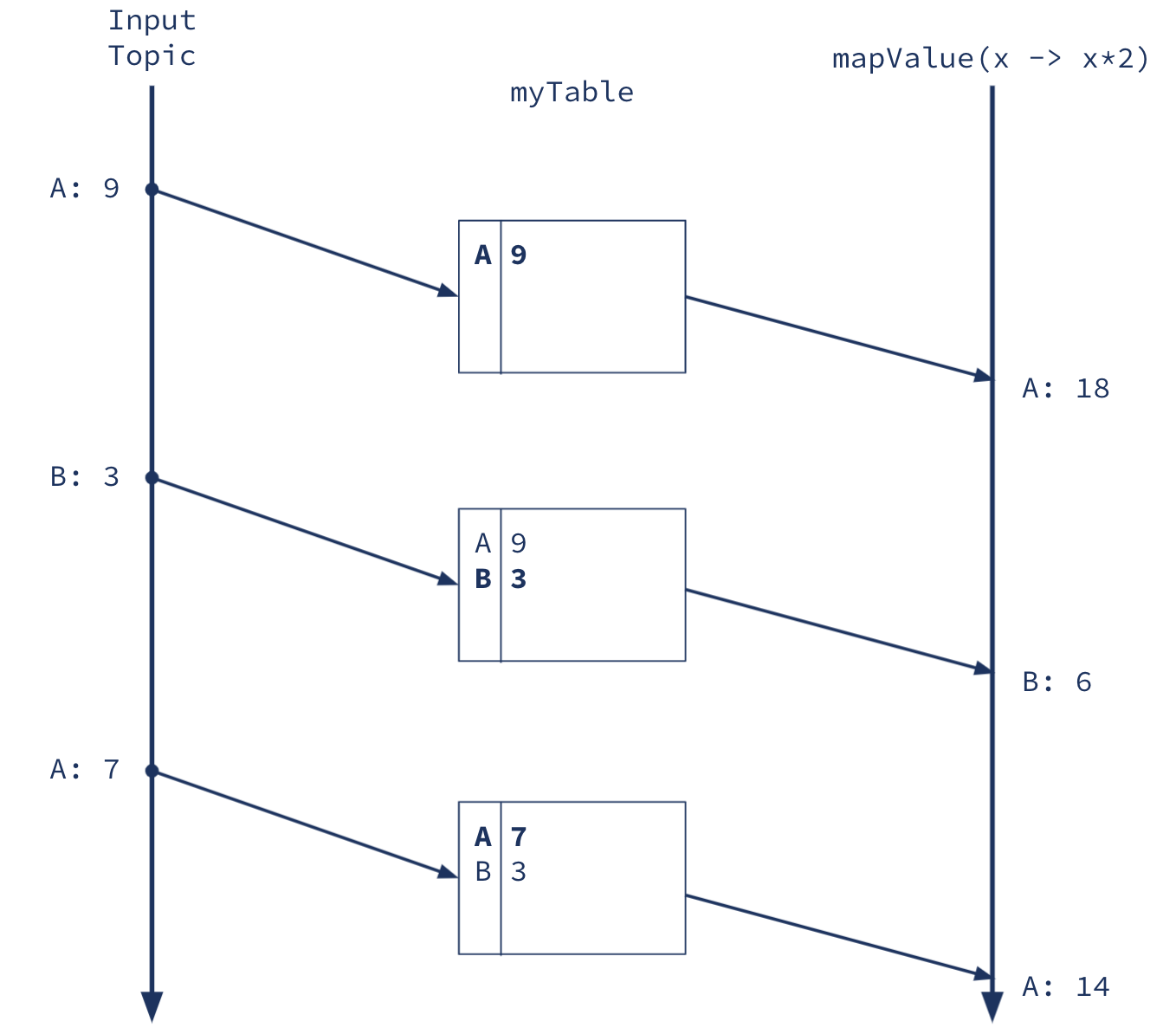
Figure 1. Above is a logical timeline view of building a table from an input topic and then forwarding it downstream to a mapValue operation. Note that whether the table is physically materialized depends on the needs of the application, but this is the right way to think logically about the operation
KTables are useful because they enable Kafka Streams applications to maintain state. KTables can be used for all kinds of relational-DB-style table operations, and they can also be queried from outside the application via the Interactive Query (IQ) API.
Note that even though the KTable is logically a single table, the data is actually partitioned based on the key. Kafka Streams is a “big data” stream processing system, which means that it needs to be able to store and operate on partitioned datasets in case the full data can’t fit on a single machine. Much of How Real-Time Materialized Views Work with ksqlDB, Animated is directly applicable to understanding KTables.
How primary-key joins work
Kafka Streams has included primary-key joins in the KTable API since the first release (0.10.0). This operation joins records from two KTables where the key of both records is the same. KTable-KTable joins enable an important set of stateful operations within the event-driven world. The easiest practical use case to imagine is assembling an entity out of information from different domains.
For example, in our marketplace application, we might factor billing into a separate system from the display application. We would then have two separate tables for merchants:
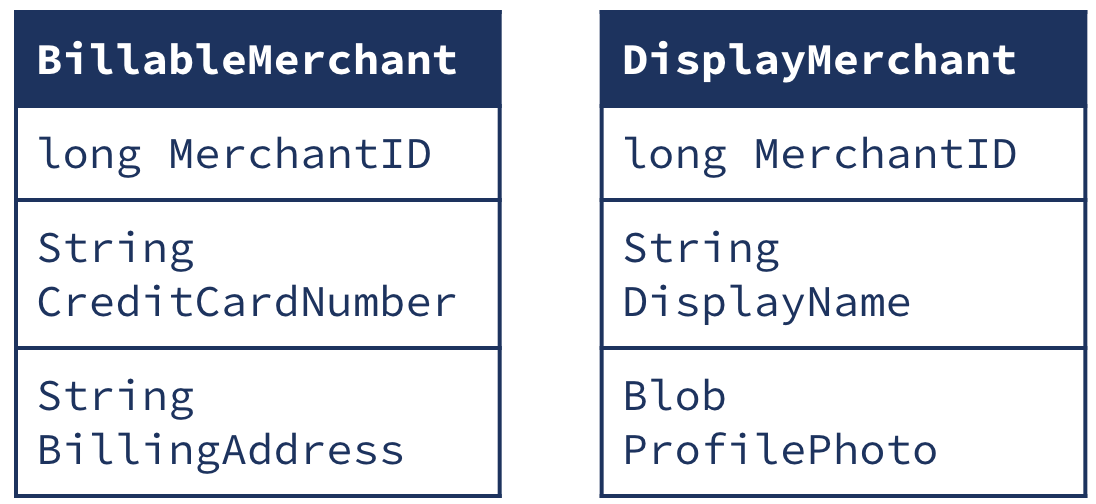
This could be a good design because the main marketplace page only needs the fields from DisplayMerchant and the payments processing system only needs the fields from BillableMerchant. However, when generating an invoice, we might want to include the DisplayName and ProfilePhoto from DisplayMerchant, along with the other fields from BillableMerchant. For this, we can use a primary-key join, as both tables share the same key.
KTable<Long, BillableMerchant> billableMerchantTable = … KTable<Long, DisplayMerchant> displayMerchantTable = …
KTable<Long, Merchant> completeMerchant = billableMerchantTable.join(displayMerchantTable, completeMerchantJoiner)
The reason that Kafka Streams historically limited joins to an equal-primary-key condition is simply that it’s relatively easy to compute this join in a distributed stream processing system. Recall that KTables are partitioned based on their record keys, so to compute a primary-key join, we can simply assign the same partitions of both tables to each compute node, and that node can locally compute the join result for each record:
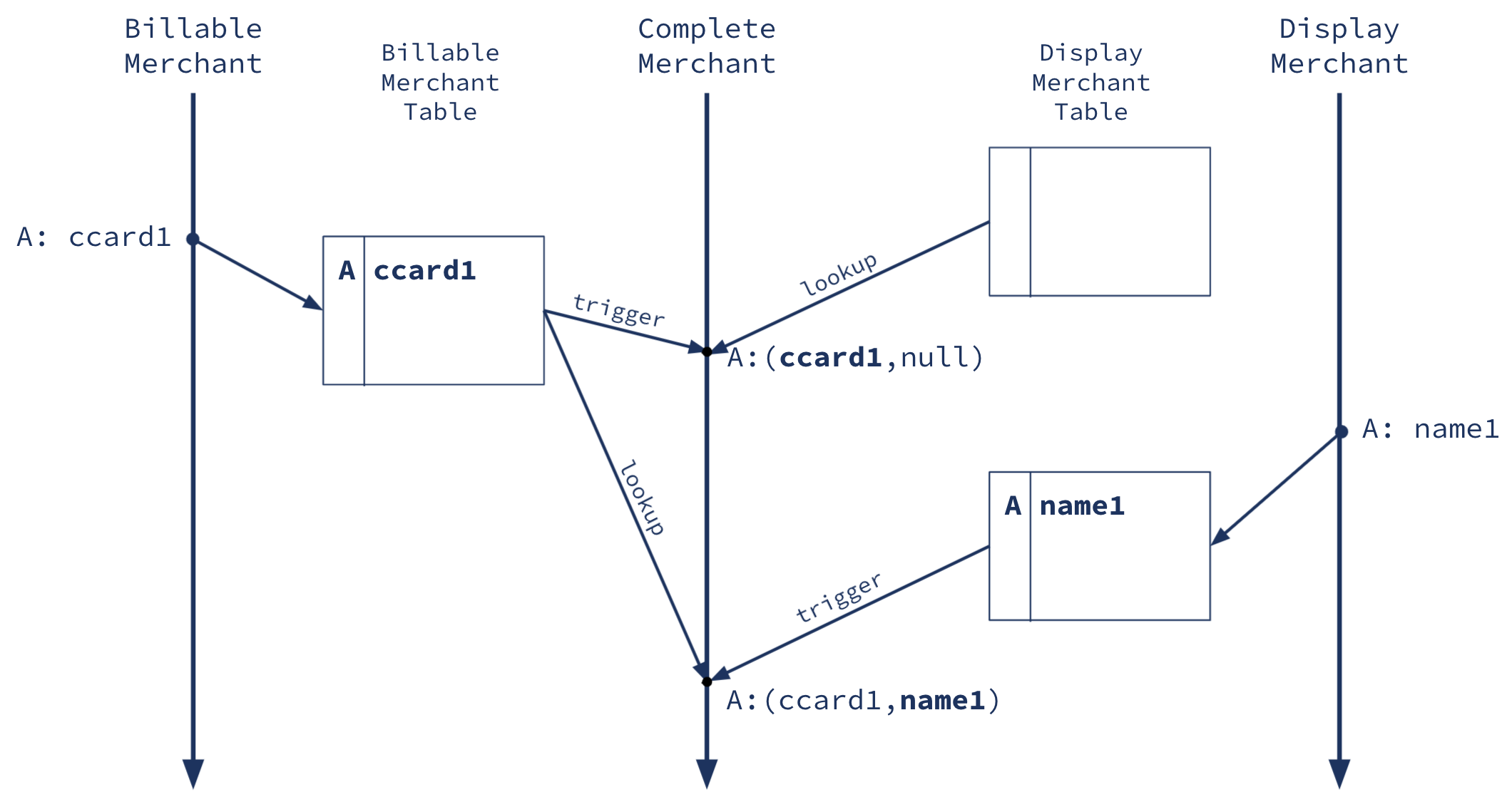
Figure 2. Above is a depiction of a primary-key join of two KTables (left table and right table). Those tables are built from their respective left topic and right topic (just as in Figure 1). On each update from either side, we do a lookup to the other side’s materialized table to compute the join result. Note that the result may or may not be materialized, depending on the needs of the application, but it is still logically also a KTable.
This works because the two tables are co-partitioned (identically partitioned), such that all records for a particular key, say Merchant1, are in the same partition, say Partition2, in both tables. Note that the primary-key join result for Merchant1 doesn’t depend on any other key, so, as long as we assign partition2 of both the BillableMerchant and the DisplayMercant tables to the same node, that node will be able to compute the join correctly just using local data.
Why foreign-key joins don’t work the same way as primary-key joins
Unlike the primary-key join, foreign-key joins involve two differently keyed and partitioned tables. There’s no simple scheme like “assign the same partitions of both tables” that enables us to route all the input data to the correct nodes.
Going back to our example, imagine our Product table has two partitions (1 and 2) and our Merchant table has three partitions (1, 2, and 3). It’s obviously not possible to assign the “same” partitions of these tables to the same nodes, as there is a partition3 of the Merchant table and not the Product table. An even deeper issue, though, is that we might have a dataset like this:

There are products in both partitions of the product table that both need to be joined with the same merchant (MerchantX). Naively, this would mean that we have to assign all the partitions of both tables to the same node to compute the join, which violates the nature of Kafka Streams as a distributed big-data stream processing system (as described above).
What we need to do here is repartition our dataset so that it is co-partitioned. Kafka Streams has two mechanisms that we can try to use for this purpose:
- Broadcasting the Merchant data using a GlobalKTable join
- Using GroupBy to co-partition the Product data with the Merchant data
Workaround: Broadcast the Merchant with a GlobalKTable join
One alternative to a first class foreign-key join feature is to make a copy of the Merchant table available on each node. While this may be possible for some datasets, it isn’t a general-purpose solution.
Consider that while it is possible that only a limited subset of Merchant data would be required to handle a single partition of Product joins, the upper requirement is a full copy of the entire Merchant dataset. This is a basic broadcast join strategy.
There are two main limitations of this approach:
- Limited usability for joining two very large datasets. It may be impossible to fit a full copy of one dataset in one node.
- Kafka Streams doesn’t have a DSL operator for a KTable-GlobalKTable join, so the workaround would have to implement the join on top of the KStream-GlobalKTable join, adding in some stateful processing to treat the KStream as a “table.”
- We cannot execute joins made by updates to Merchant, as stored in the GlobalKTable. In the current implementation, KStream-GlobalKTable joins can only be triggered on the KStream (Product) side. Without making changes to the framework, we would have to use a punctuator to check for Merchant-side updates, further complicating the implementation.
Workaround: Use a primary-key join for foreign keys
If we can somehow re-key the Product table so that it has a MerchantID as the key, we can use the existing primary-key join. Since there’s a one-to-many relationship between Merchant and Product, what we would have to do is collect a list of products sold by each merchant. Kafka Streams allows us to do this using the groupBy and aggregate operations.
KTable<MerchantID, Merchant> merchants = ... KStream<ProductID, Product> products = ...
KTable<MerchantID, Map<ProductID, Product>> productsByMerchant = stream .selectKey( (productID, product) -> product.merchantID ) .groupByKey() .aggregate( () -> new HashMap(), (merchantID, product, map) -> map.put(product.ID, product) );
KTable<MerchantID, Map<ProductID, JoinedProduct>> joinedResults = productsByMerchant.join( merchants, (merchantID, productsForMerchant, merchant) -> productsForMerchant.map(product -> new JoinedProduct(product, merchant)) );
This approach solves the partitioning problem by repartitioning the Product data to match the Merchant data. After the groupByKey operation, the productsByMerchant table has three partitions, the keys are MerchantIDs, and the values are all the products sold by that merchant. Now, the dataset looks like this:
ProductsByMerchant Partition 1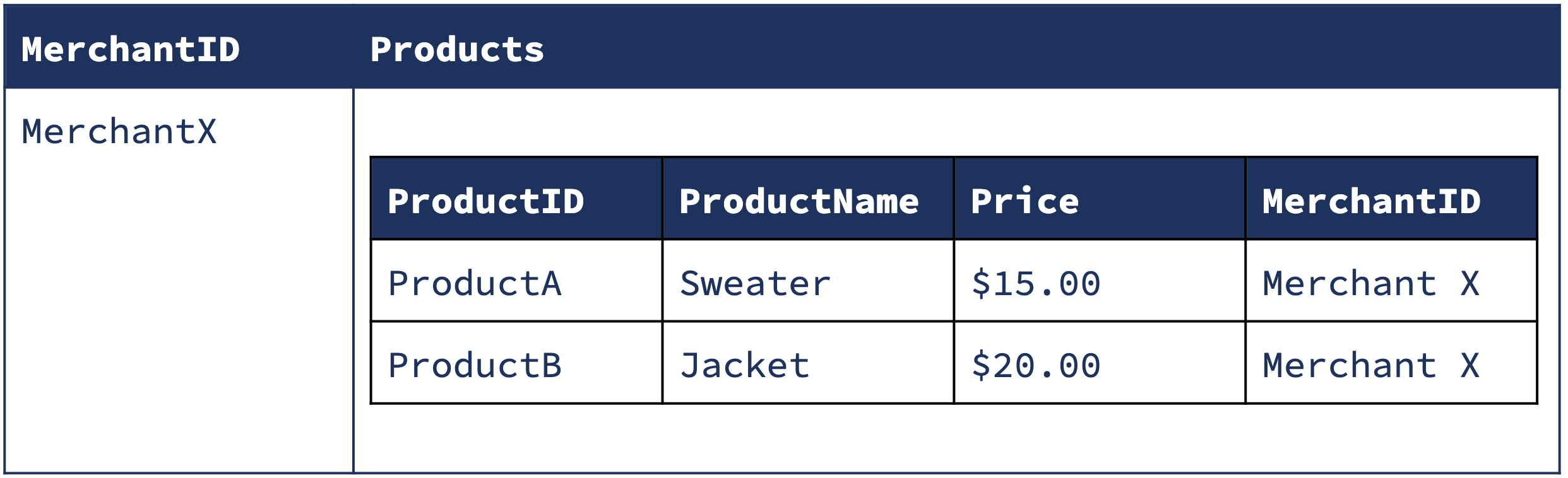
DisplayMerchant Partition 1
Now, we can compute a distributed join correctly by assigning partition 1 of both ProductsByMerchant and DisplayMerchant to the same node, as all the records related to MerchantX are now guaranteed to be in partition 1 of both tables.
The problems with using a primary-key join for foreign keys
This solution scales much better than simply assigning all the data to a single node for joining, as we can keep the data partitioned throughout the computation. But we have traded this scalability for a different scale problem: Each record in ProductsByMerchant may become arbitrarily large. If we have 1 million merchants and each one has 10 products, we should be fine. But if we have a single merchant with a million products, we will wind up storing all 1 million products in a single row in ProductsByMerchant!
This leads to three major issues.
1) Store I/O performance impact
When the number of records in the aggregated data structure are small, reads and writes are fast. However, as the number of records written and deleted grows, the read and write performance of the application begins to suffer significantly.
Consider the case where we have 999,999 entries in the aggregate data structure. Adding just one more entry, the 1,000,000th, will require:
- Loading the prior record, probably in the GB size range. At these sizes, we’re probably forced to use on-disk storage, and caching is probably ineffective, so this is a high-latency operation.
- Appending the single entry to the record.
- Saving the new record back to the store. Again, the size of the record means that caching is probably ineffective, so we have to pay the latency penalty for flushing to disk right away.
What is particularly dangerous about this pattern is that as the number of records in the aggregate increases, both the probability of modifying the structure and the performance impact of doing so increase correspondingly. For very large datasets, it is possible that it is being nearly continuously updated, with very expensive flushes occurring over and over. It would be better to split up these store operations.
2) Changelog message size
The default record size maximum in Kafka is 1 MB, and this is quickly reached by many use cases. For instance, consider that with 500-byte product records, we only need a single merchant with 2,000 products to exceed 1 MB. The maximum record size is configurable, but you would have to set it to a huge number to ensure you won’t just bump into the limit next week. Also, the purpose of that limit is to ensure that the Kafka brokers remain responsive and predictable. Writing huge records to Kafka can also result in latency spikes on the brokers, which your Kafka operators probably won’t appreciate. On the other hand, if we split up that record into smaller chunks, Kafka can easily store and transmit the same volume of data.
3) Recomputing unnecessary join results
Whenever a change occurs to a KTable in the Kafka Streams DSL, only the updated value is propagated. Thus, the aggregate structure will always just show the current state at the time the join logic is triggered. This is particularly problematic because we have no way to detect what has been added or updated, and so we must output the join results for each and every record in the aggregate. This results in another significant performance impact to the producer and all consumers of the resultant event stream as they must consume each and every output event.
Deletions also prove to be difficult to track. For one, a deletion means that there is no entry for it in the aggregate, and so by definition it cannot be joined on and emitted. Proper handling requires tombstone records within the aggregate, which then leads to more complexity regarding when to clean up tombstones.
With these issues in mind, it is clear that the workaround of using GroupByKey and primary-key join is insufficient for enabling foreign-key joins. A scalable and performant implementation is necessary to address these issues and enable Kafka Streams foreign-key joins to have efficient changelogging and caching, as well as good ergonomics.
Adding foreign-key joins to Kafka Streams
The difficulty in maintaining the aggregate data structure is the most substantial issue preventing efficient foreign-key joins using the GroupBy method. This issue stems from the requirement that all records belonging to the same key must be grouped together into a single record. Our implementation of native foreign-key KTable joins in Kafka Streams remedies this issue efficiently and scalably.
Solving the record size issues
This is not the complete solution, but to start with, we will address the problem of keeping the full list of all a merchant’s products in a list in the value. This solution will give us a solution that we can build on to get the full algorithm.
With our naive GroupBy solution, we need to load and store all of a merchant’s products when any of its products change. The current Kafka Streams state store interface requires stores to support sorted key/value access patterns and doesn’t enable modification of the value/row at finer levels of granularity (such as adding or removing only one Product to the set of all Products in the row). Though we could remedy this issue by adding data store support for localized row modifications (such as is permitted in Cassandra), this would be an extensive change and would require significant modification to the Kafka Streams codebase. Additionally, this approach also runs into its own scalability issues when the number of records in a row grows very large.
A better solution is to decompose a Merchant‘s set of related products into separate rows, which we can do by using a composite key like (MerchantID, ProductID). The composite key is formed by extracting the foreign-key (ProductId) out of the value. Each product has its own row with its own new composite key, which looks something like this:
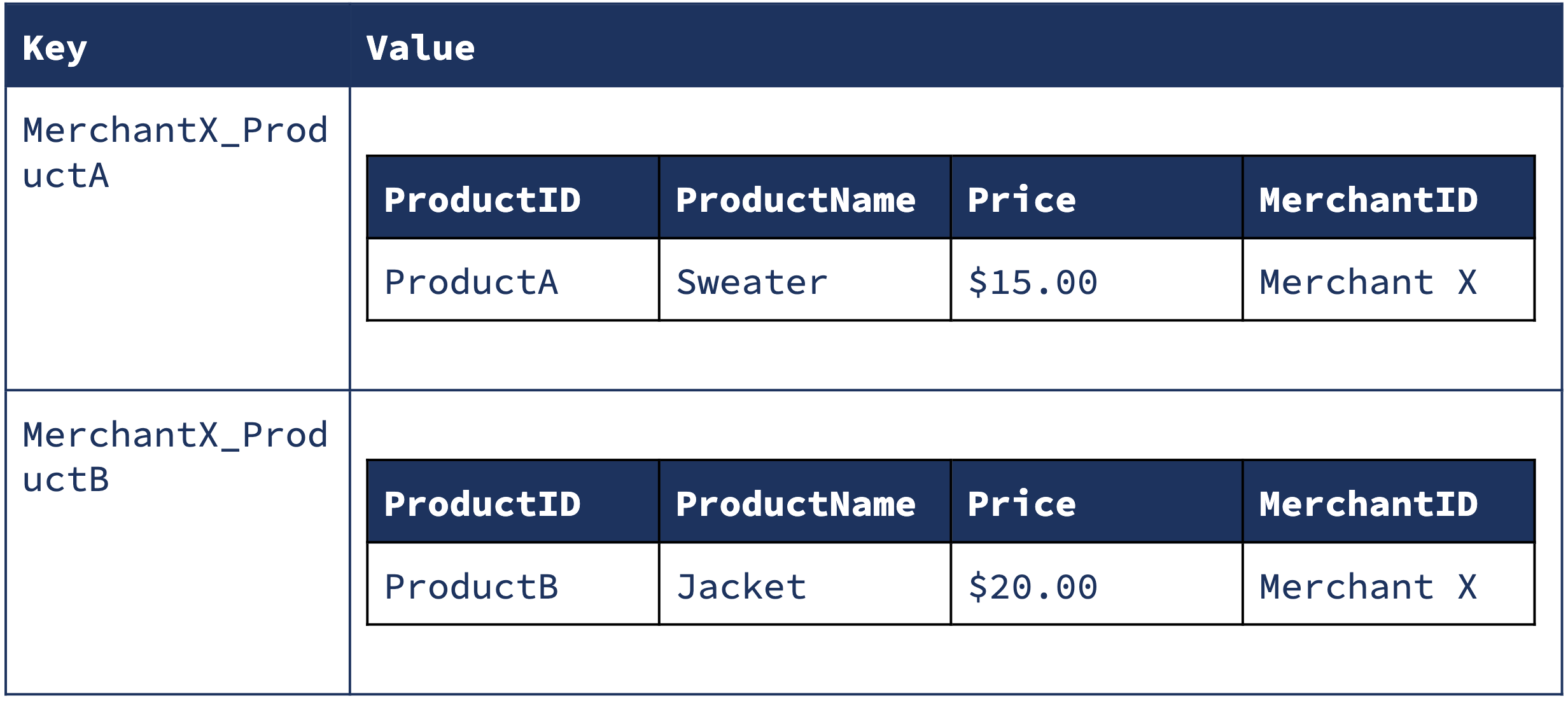
This data structure enables us to colocate the Product and Merchant, and compute the join from the right-hand side using the following dataflow:
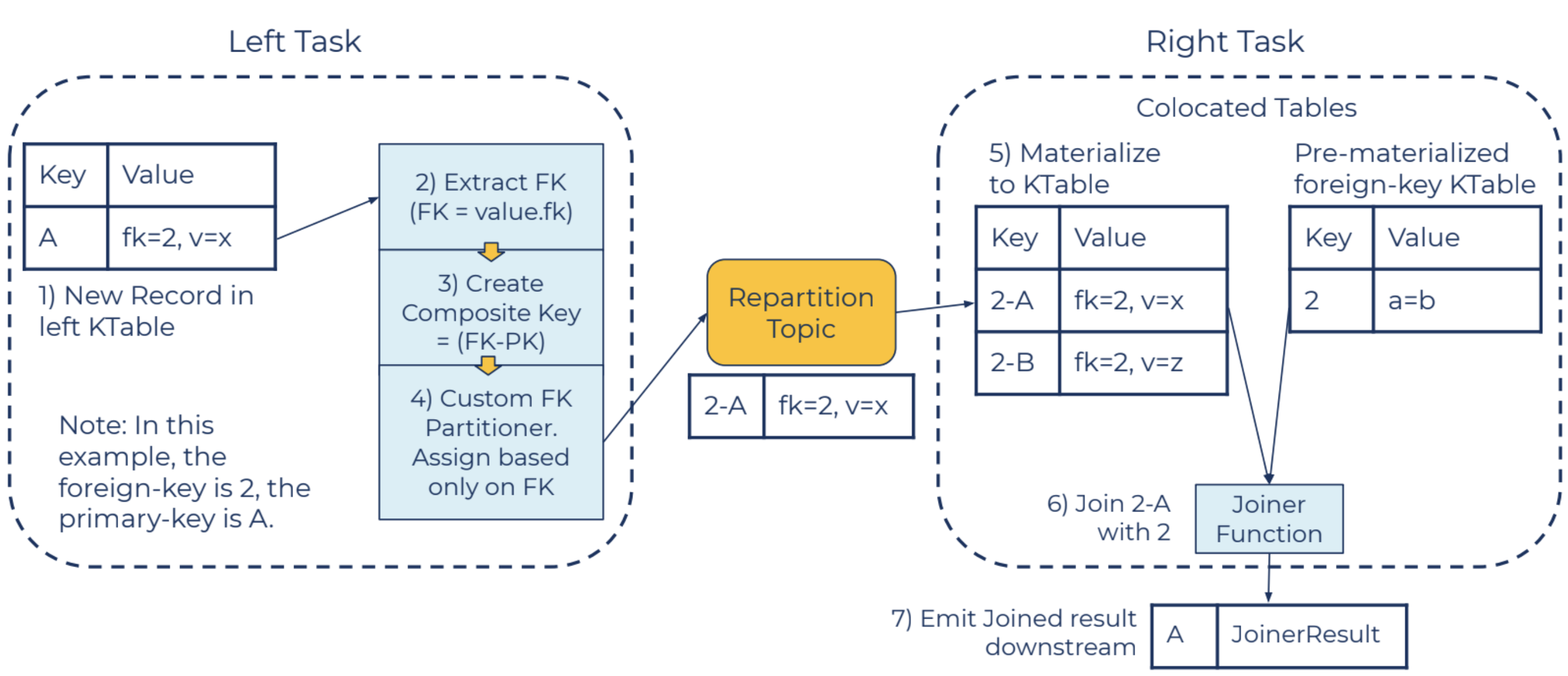
Figure 3. The data flow if we send the left-hand-side records to the right-hand task for processing
A new record is inserted into the left KTable (1). The foreign key is subsequently extracted using the foreignKeyExtractor (2), and a composite key is created (3). The composite key format prepends the foreign key to the primary key. This will be used for joins from the right table updates, as covered in the next section.
The left record with the new composite key is written to an internal repartition topic (4), using a custom hash partitioner. This partitioner assigns records to partitions based only on the foreign key of the composite key, such that all records of the same foreign key end up in the same partition. This ensures co-partitioning with the right KTable so that we can co-locate the composite and right table.
The consumer of this repartition topic materializes the records into a composite table (5). The joinerFunction is executed after each new record is materialized, using the foreign-key to look up the value from the right KTable (6). The result of the join is emitted, keyed only on the original primary key of the left KTable record (7).
A join triggered by an upsert to the right KTable depends on the materialization of composite records (5), as illustrated in the previous section. Figure 4 shows the workflow of the right-triggered joins.
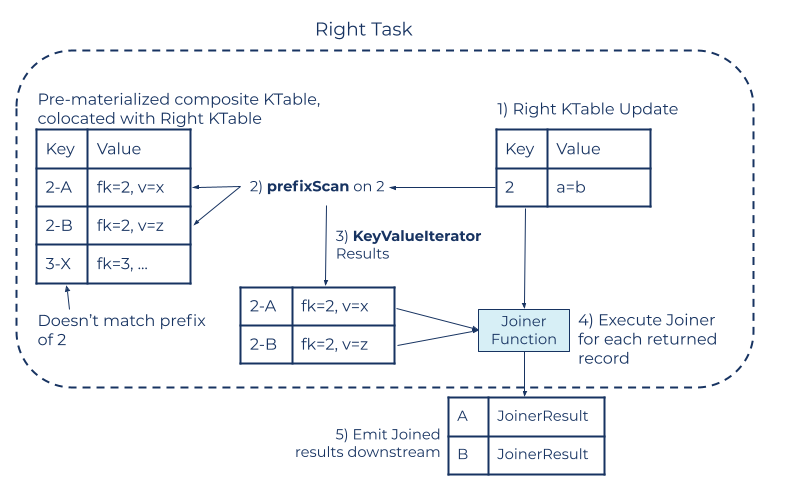
Figure 4. The right-hand task computing new join results when it gets an update on rightTable
With a right-triggered join, a new event is upserted into the right KTable (1). Next, a prefixScan (2) is performed on the composite table, where all events matching that prefix are returned in a KeyValueIterator (3). This dataflow relies on the state store implementing ordered storage of the values, as is part of the current state store Interface. The JoinerFunction is executed (4) for each element in the KeyValueIterator, using the value from the right record at the time the prefixScan was issued. Finally, a record is emitted for each matching key (5). The result record is keyed by the left record’s key (the ProductID in our example).
This approach solves most of our problems, but it still means that we need to make a full copy of the Product table as we send a copy of each Product to be co-located with the Merchant data. In primary-key joins, Kafka Streams collects the full dataset that it needs on both sides of the join so that it can compute the join result locally on each partition. This normally doesn’t require making an extra copy of either table, as the tables are already co-partitioned. But for foreign-key joins, as we’ve seen, we are going to have to re-partition one of the tables to compute the join. Does this force us to make a full copy of that table? No!
Solving data copying with subscriptions and message passing
The implementation that we ultimately used for foreign-key joins uses a message passing algorithm in which we think of the left and right tables as belonging to two different tasks on two different machines. These tasks can use internal topics to send messages to each other, and they work together, using these messages, to produce the correct join result.
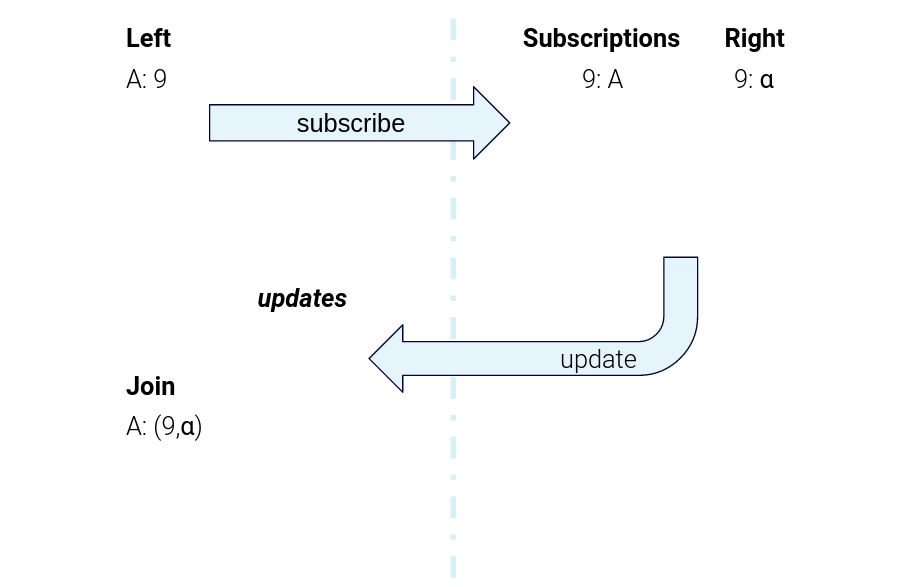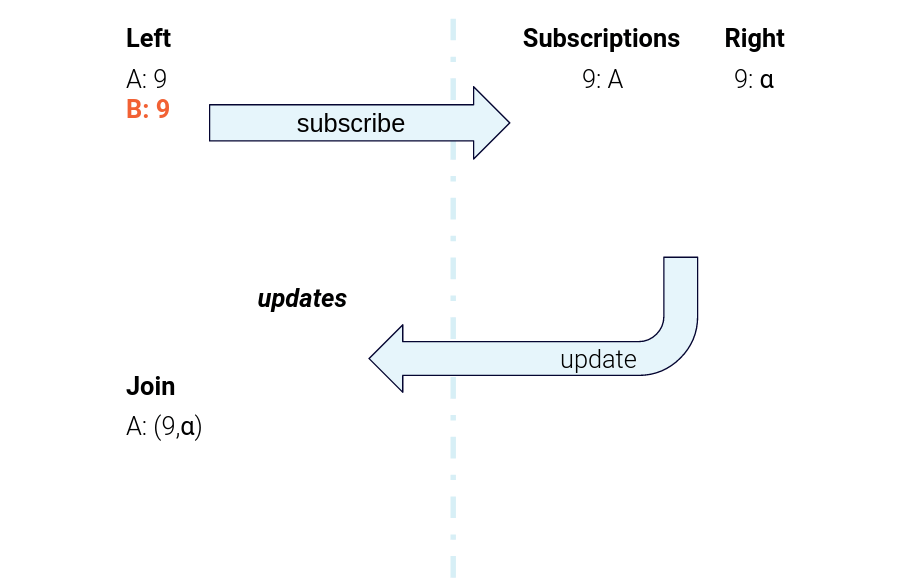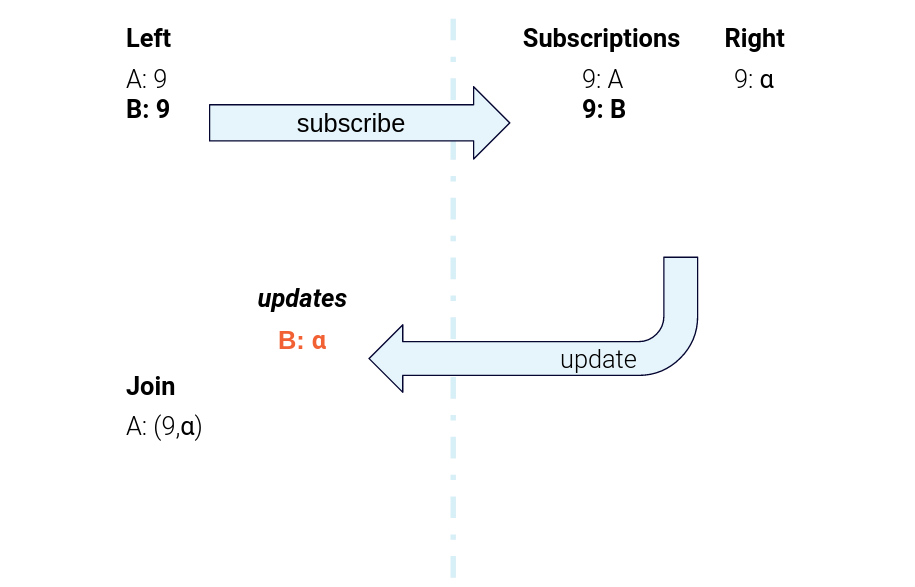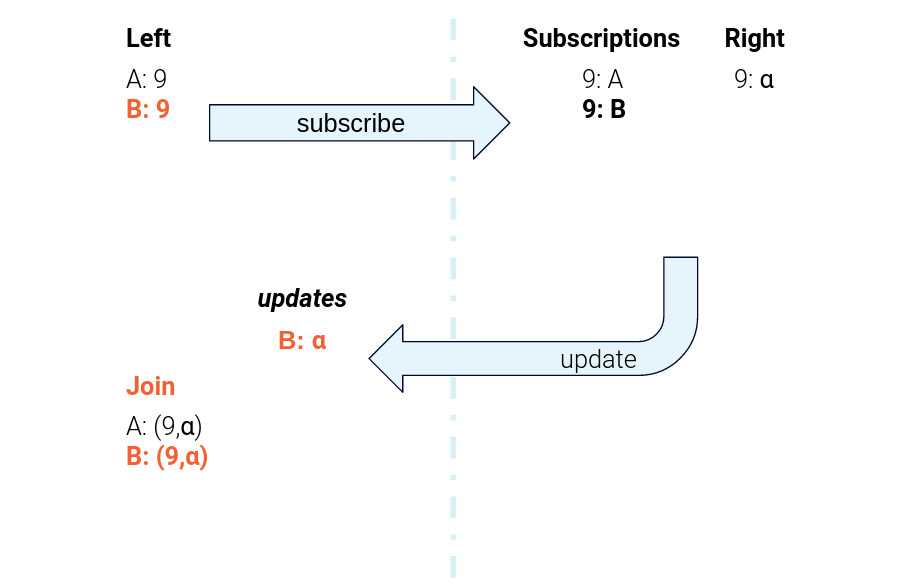
Figure 5. The data flow for sending subscription messages from the left task to the right task and sending right-hand-side updates back to the left-hand task for joining
As an overview, when the Product task gets an update, it sends a “subscription” message to the Merchant task. The Merchant task makes a note of the fact that this particular Product is interested in that particular Merchant. Then, it sends back a “response” message containing the data for the relevant Merchant. The Product task gets that response and computes the join using the local Product record and the Merchant record from the “response” message.
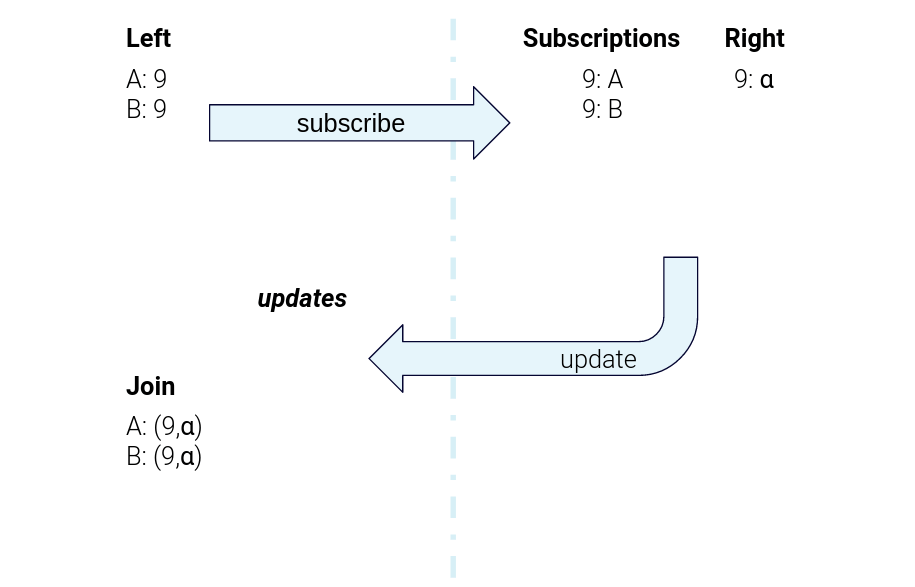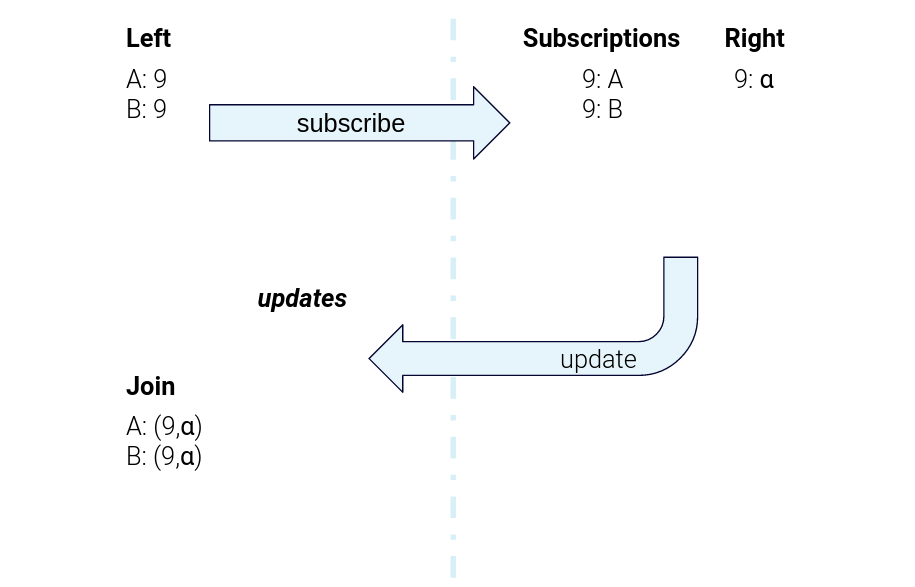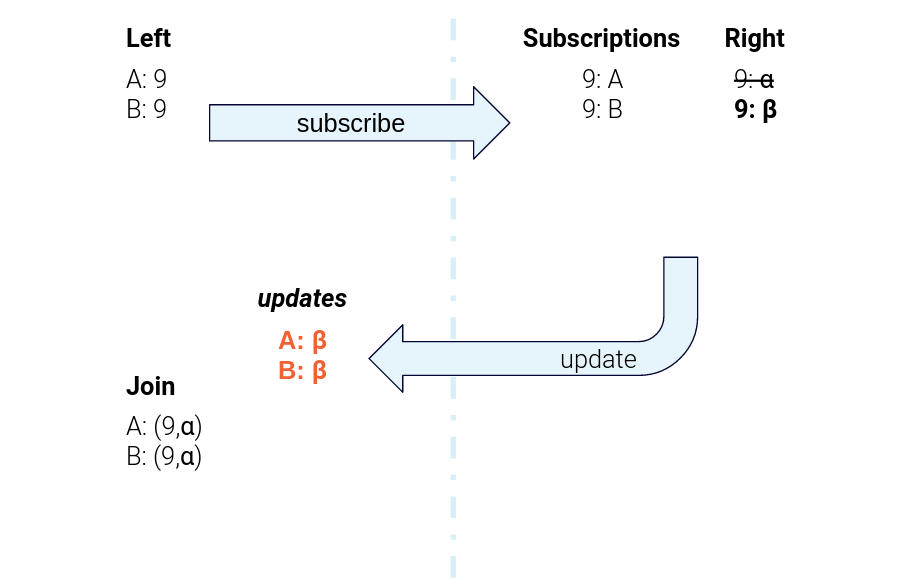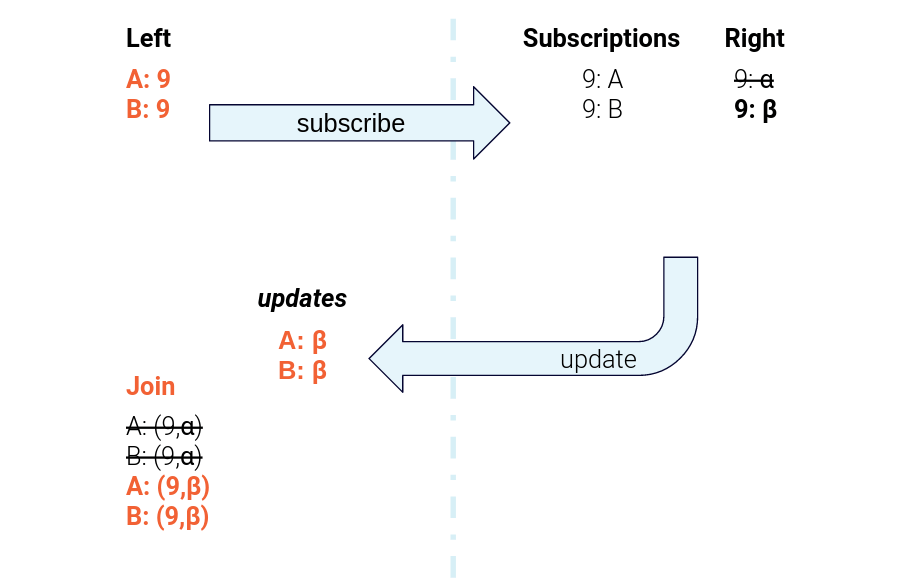
Figure 6. The data flow for sending subscription messages from the left task to the right task and sending right-hand-side updates back to the left-hand task for joining
Similarly, when there is an update on the Merchant table, the Merchant task scans over its subscription table and sends a new “response” message to every Product that has registered an interest. Upon receipt, the Product task computes a new join result for each of those response messages.
To make it more concrete, if you refer to the example dataset, you’ll see that ProductA and ProductB both reference MerchantX. When we insert or update those Products, those tasks send subscription requests like "key: MerchantX, value: ProductA," indicating that ProductA is interested in updates from MerchantX. These messages are keyed with the MerchantID, and this internal subscription topic is co-partitioned with the Merchant table, so the subscription message is guaranteed to get routed to the Streams task that also has that key in its local Merchant store.
The Merchant task receives that subscription and stores it in a special subscription table using the composite key strategy that we identified above, but this time, we don’t need to store the whole Product row, just a reference:

Note that the composite key itself tells us everything that we need to know, so the value is just a placeholder. Later on, we will use the value to solve a tricky race condition.
Each time one of these requests comes in, or the referenced Merchant record changes, the Merchant task sends an update back to the Product task, like this:
"key: ProductA, value: {MerchantID: MerchantX, DisplayName:Cozy Creations, ProfilePhoto: (photo)}"
If we delete ProductA, then we need to send an “unsubscribe” message so the Merchant task can remove that subscription. Likewise, if ProductA‘s MerchantID changes from MerchantX to MerchantY, we can simply send an “unsubscribe” to MerchantX and a “subscribe” to MerchantY.
One last problem: Race conditions
For a distributed system, Kafka Streams has to deal with surprisingly few race conditions. Most of its processing is single threaded and partition local. However, the asynchronous messages in our subscription/response algorithm open us up to race conditions like this:
- Add ProductA(ref=MerchantX)
- send Subscribe(MerchantX,ProductA)
- Update ProductA(ref=MerchantY)
- send Unsubscribe(MerchantX,ProductA)
- send Subscribe(MerchantY,ProductA)
- MerchantY processes Subscribe(MerchantY,ProductA)
- send Response(ProductA, MerchantY)
- ProductA processes the response from MerchantY and computes a join result
- emit Result(ProductA, MerchantY)
- MerchantX processes Subscribe(MerchantX,ProductA)
- send Response(ProductA, MerchantX)
- ProductA processes the response from MerchantX and computes a join result
- emit Result(ProductA, MerchantX)
- MerchantX processes Unsubscribe(MerchantX,ProductA)
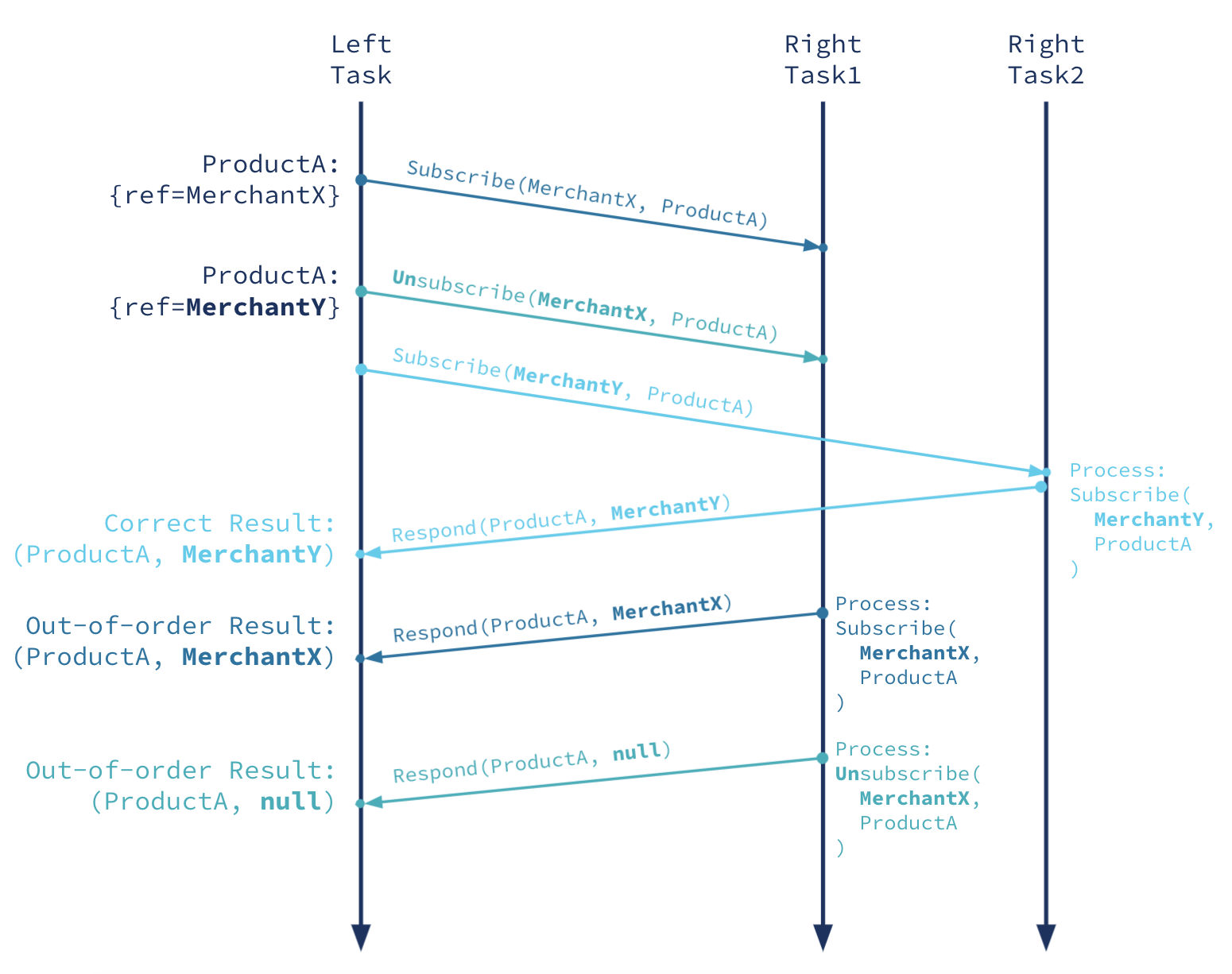
Figure 7. Above is a race condition when right-hand-side processing for two different merchants is handled by different nodes. Note that the correct final result would be (ProductA, MerchantY), but we get (ProductA, null).
The final state of ProductA is that it references MerchantY, but the final state of the join result is that ProductA is joined with MerchantX. This happens because the subscription messages can be handled by different tasks on different threads on the Merchant side, which can be arbitrarily delayed. In this particular ordering, even though we sent the MerchantX messages first, they were handled last, resulting in the disordered results.
We considered fixing this problem by transmitting a counter along with the subscription requests, which would let us discard the out-of-order subscription responses. However, we can do even better. Both the Product and Merchant records can be updated in rapid succession, resulting in multiple Subscribe, Unsubscribe, and Response messages stacking up in the internal topics. Even if we process all the responses in the right order, we only have the latest version of the Product record available to compute the join, resulting in non-deterministically generated intermediate join results that don’t make sense.
Our solution is to encode a hash of the Product record along with the subscription message, and send it back in the response, so that when the Product task handles the response, it can compare that hash with the current version of the Product to decide whether that response is still relevant or not. The current implementation uses a murmur3 128-bit hash function, which replaces the subscription value with just 8 bytes of data.
This algorithm was selected for several reasons:
- It provides very high uniqueness probabilities between pairs.
- It distributes hashed values across the output domain fairly evenly.
- It is sensitive to slight changes in the input value, such that any minute modification (e.g., a record update where a single field is changed from 14 to 15) results in a completely new hash value.
- There is already a precedent in using the Murmur2 hash in Kafka Streams partitioners.
- It’s fast. It must be executed for each issued SubscriptionWrapper, as well as for each SubscriptionResponseWrapper received.
As a minor note, in addition to the Product document’s hash, we also store a special “instruction” field that further optimizes the Merchant task’s responses in the case of different join types (inner vs. left*) and the specific optimization (delete vs. changing foreign key).
*We chose to defer outer and right foreign-key joins to future work because our foreign-key join results use the left-hand-side keys. Any result that’s missing the left-hand-side record would have a null key. We believe solutions are possible, but it was better to ship inner and left joins first.
The final version of the Subscription table looks like this:

The Instruction field allows us to implement some important but very implementation-specific optimizations. For example, if a product document’s foreign-key reference changes from MerchantX to MerchantY, we need to send an “unsubscribe” message to MerchantX, but we know that we won’t need the response (because it would be immediately invalidated by the join result with MerchantY). Therefore, we use the instruction field to tell the merchant processor to update the subscription store but not send us back the typical response.
Summary of the solution
With all of the above innovations, we arrive at a system to compute foreign-key joins that:
- Correctly handles differently partitioned left- and right-side tables
- Does not make an extra copy of either table
- Stores small records in all tables, suitable for efficient disk and network I/O, as well as Kafka changelog records
- Only computes the necessary join results (for example, when one product changes, only one result is updated, instead of all products for the same merchant as in the first workaround)
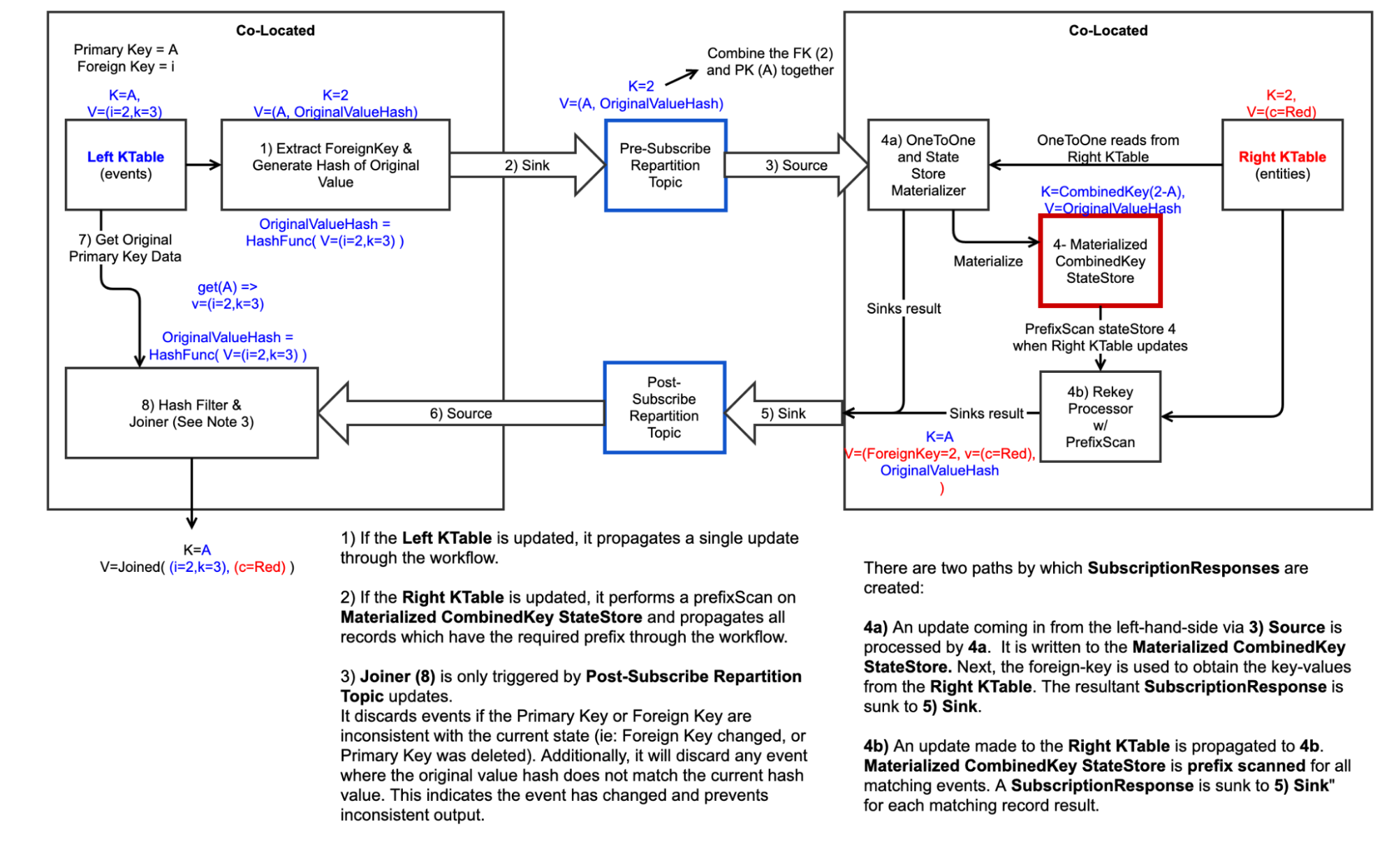
Figure 8. The full-detail data flow for a foreign-key join.
Foreign-key join in practice
The beauty of this feature is that, as complicated as the implementation is, it is extremely simple to use in your applications.
Using foreign-key joins
As a reminder, here is how it has always looked to use a primary-key join:
final StreamsBuilder builder = new StreamsBuilder();
final KTable<MerchantID, BillableMerchant> billableMerchants =
builder.table("BillableMerchant");
final KTable<MerchantID, DisplayMerchant> displayMerchants =
builder.table("DisplayMerchant");
final KTable<MerchantID, Merchant> merchants = billableMerchants.join(
displayMerchants,
(billableMerchant, displayMerchant) -> new Merchant(billableMerchant, displayMerchant)
);
And this is how to use a foreign-key join:
final KTable<ProductID, Product> products = builder.table("Product");
final KTable<ProductID, DisplayProduct> displayProducts = products.join(
displayMerchants,
Product::getMerchantID,
(product, displayMerchant) -> new DisplayProduct(product, displayMerchant)
);
displayProducts.toStream().to("DisplayProducts");
The only difference is that you have to define how to extract a foreign key from the left-hand side (Product::getMerchantID). Once you start the Kafka Streams application with this topology, all of the above machinery will go into motion to compute your displayProducts join results.
Testing
For the majority of tests, we recommend using the TopologyTestDriver. This allows you to test your application logic by running it in a fast, deterministic framework that doesn’t need to spin up a Kafka cluster or deal with queueing delays.
Testing a foreign-key join is no different than any other Kafka Streams application:
try (final TopologyTestDriver driver = new TopologyTestDriver(builder.build())) {
// create the test harness (pseudo-topics to pipe input and collect output)
final TestInputTopic<MerchantID, DisplayMerchant> displayMerchants =
driver.createInputTopic(
"DisplayMerchant",
MerchantID.serializer(),
DisplayMerchant.serializer()
);
final TestInputTopic<ProductID, Product> products =
driver.createInputTopic(
"Product",
ProductID.serializer(),
Product.serializer()
);
final TestOutputTopic<ProductID, DisplayProduct> displayProducts =
driver.createOutputTopic(
"DisplayProducts",
ProductID.deserializer(),
DisplayProduct.deserializer()
);
// Input the test data
final MerchantID merchantX = new MerchantID("MerchantX");
displayMerchants.pipeInput(
merchantX,
new DisplayMerchant("Cozy Creations", "http://www.example.com/merchantXphoto.jpeg")
);
final ProductID productA = new ProductID("ProductA");
products.pipeInput(
productA,
new Product("Sweater", 15.00, "USD", merchantX)
);
// define the expected join result
final DisplayProduct expectedProduct =
new DisplayProduct(
"Sweater",
15.00, "USD",
merchantX,
"Cozy Creations",
"http://www.example.com/merchantXphoto.jpeg"
);
// assert that we get the expected result
assertThat(
displayProducts.readKeyValuesToMap(),
is(Collections.singletonMap(productA, expectedProduct))
);
}
Because the result is logically a table, it makes sense to make assertions against displayProducts.readKeyValuesToMap() to avoid having to worry about any intermediate results. The TopologyTestDriver should exercise most aspects of your application, both the functional ones (whether your joiner works, for example) and the non-functional ones (like whether the serializers and deserializers work).
However, as discussed in Testing Kafka Streams: A Deep Dive, after you are thoroughly convinced that your code is correct because all your TopologyTestDriver tests pass, it’s also a good idea to add some integration tests to your verification suite as well. Similar to the example above with TopologyTestDriver, you will find that there is nothing particularly special about integration-testing an application that uses foreign-key joins.
Operational considerations
Operating a foreign-key join is not much different than operating any Kafka Streams application. You’ll want to be familiar with the data flow diagrams above so that you can interpret the topology. There are no foreign-key-join specific metrics. The topology contains two repartition topics and three state stores, which are the main components that you should monitor.
As an example, here is a foreign-key join copied from one of the unit tests:
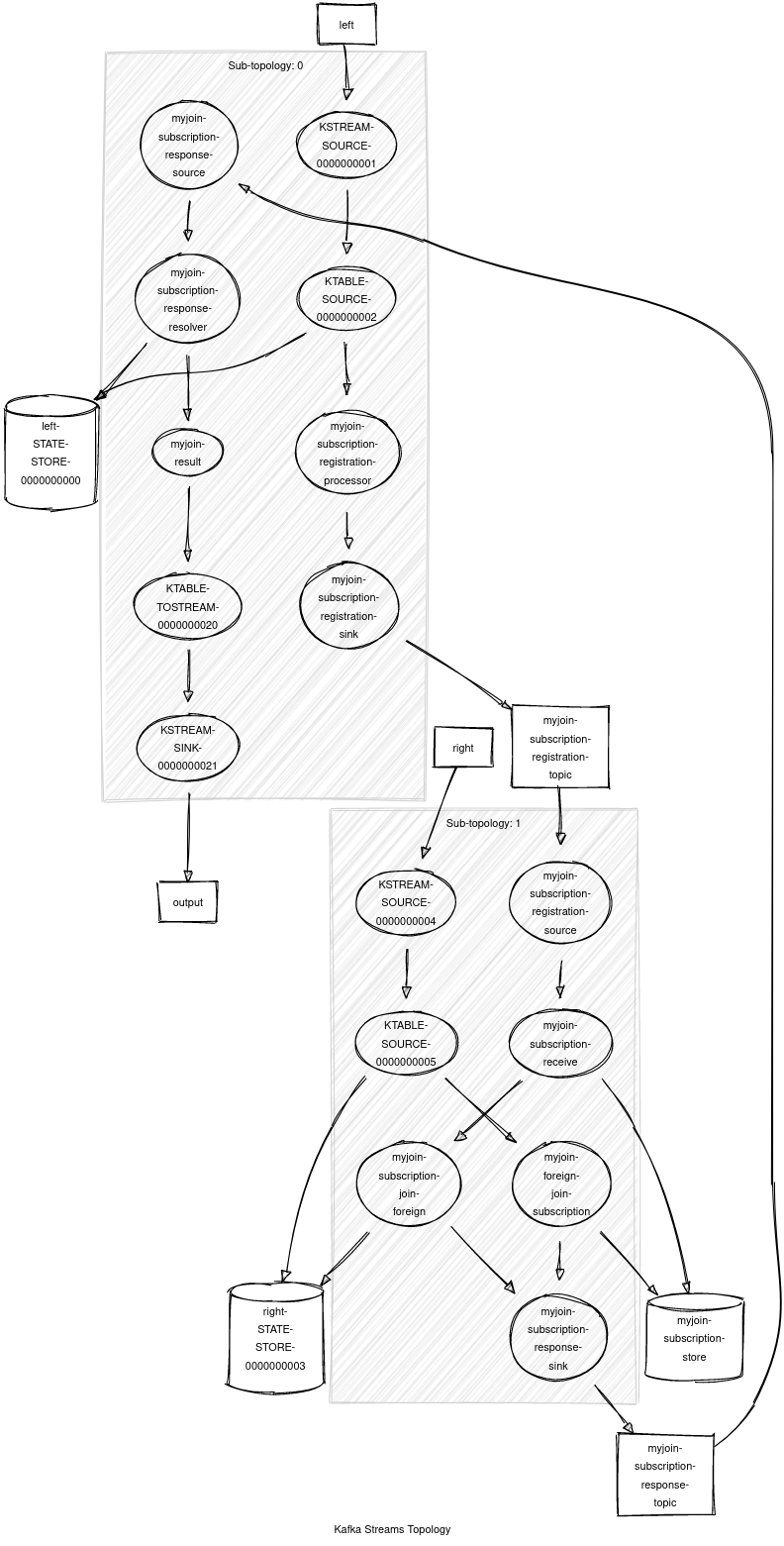
Figure 9. A depiction of a real foreign-key topology
There are two input tables: left and right. We always recommend using the Named.as(...) config option with stateful operations to help you track your internal topics and state stores. In this case, the join is Named.as("myjoin").
You can see the two internal repartition topics:
- myjoin-subscription-registration-topic: The subscription topic; regardless of the operation name, these topics are always suffixed -subscription-registration-topic.
- myjoin-subscription-response-topic: The response topic; regardless of the operation name, these topics are always suffixed -subscription-response-topic.
You will want to monitor the lag on those topics to understand if your application is keeping up. A healthy application should tend not to lag on internal topics, although the system is designed to be able to accomodate bursts of data by buffering records in the repartition topics.
The three state stores involved are:
- left-STATE-STORE-0000000000: The left-hand-side KTable store.
- right-STATE-STORE-0000000003: The left-hand-side KTable store.
- myjoin-subscription-store: The subscription store for the join. This is the new data structure discussed above. Regardless of the operation name, this store is always suffixed -subscription-store. Note for your capacity planning that this store will also have a corresponding changelog, called myjoin-subscription-store-changelog.
The two KTables are just regular KTable stores, whose access patterns and performance characteristics should be in line with your existing experience with KTable stores.
As we discussed above, the subscription store is designed to be lightweight and efficiently support the operations we need, but it is still a relatively new addition to the operational domain of Kafka Streams. It is a regular state store, so you can use the same metrics to monitor its performance, but it is unique in the Kafka Streams DSL because the processor will perform range queries on the underlying store. Note that if you want to monitor store range query performance, you will need to enable debug-level metrics.
One other metric to keep an eye on is skewness in the sizes of the subscription store partitions. As discussed above, the subscription store is designed to have a small key/value record size, but it remains the case that each Merchant (in the examples above) has a subscription stored for every Product that references it. If your data has highly skewed join cardinality, then you will also see skewed partition sizes in the subscription store. Each record is roughly the size of the serialized primary key, the serialized foreign key, and an 18-byte overhead. For example, if each key is a UUID, then the size per reference is about 50 bytes. For example, if a Merchant has 1 billion Products, then it will contribute about 50 GB to the subscription store. If you have several of such high-cardinality records, you may want to customize the partitioner and partition count to ensure your high-cardinality records are distributed evenly over your partitions.
There is one noteworthy log message (which may originate from several loggers in the package org.apache.kafka.streams.kstream.internals.foreignkeyjoin): “Skipping record due to null foreign key.” This is a warn-level log message that usually means the foreign-key extractor function returned null. Although the SQL spec does define a result for joining on a NULL reference, the key-partitioned semantics of Kafka Streams operations made it more sensible to treat null foreign-key references as invalid data. In addition to the warning log, these occurrences are captured in the dropped-records metrics.
One final operational note is that, as of Apache Kafka 2.8, the subscription store is hard coded to use RocksDB for the underlying storage engine. KIP-718 proposes to change this default and also to allow choosing a storage engine for the subscription store independently from the KTable stores.
Conclusion
Foreign-key joins were a long time coming to Kafka Streams, and it was an exciting feature to design and implement. Part of this excitement came from the challenging technical problems to solve, but a major part was the knowledge that we were bringing to life a piece of technology that would improve the lives of our users, and by extension, their users.
Adding foreign-key join to your tool belt means that you can move a lot of complexity from your domain into the Kafka Streams runtime. This is equally true whether you are building an event-driven business intelligence application, turning the database inside out by precomputing your display view, or using Kafka Streams to simplify your implementation of event sourcing microservices.
This feature even lays the groundwork for incrementally maintained foreign-key join views in ksqlDB! ksqlDB uses Kafka Streams as the engine for continuous materialized view maintenance, so it directly benefits from all of the hard work and optimizations that we have discussed. When foreign-key joins are released in ksqlDB 0.19.0, Kafka Streams’ feature comes full circle: inspired by RDBMS joins and ultimately implementing the join logic for an RDBMS.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.