OSS Kafka couldn’t save them. See how data streaming came to the rescue! | Watch now
Property Based Testing Confluent Cloud Storage for Fun and Safety
Confluent uses property-based testing to test various aspects of Confluent Cloud’s Tiered Storage feature. Tiered Storage shifts data from expensive local broker disks to cheaper, scalable object storage, thereby reducing storage costs, rebalancing times, and improving elasticity. However, if Tiered Storage is not implemented correctly, the result can be significant data loss.
Property-based testing is highly effective when used in combination with traditional testing techniques, such as example-based testing, integration testing, and so on. This post describes some of the property-based testing that Confluent performs on the log-orientated storage layer of Confluent Cloud and how we test the integration of Tiered Storage with Apache Kafka®’s traditional storage layer.
Property-based testing aims to test several key behaviors of the log to ensure the following:
- Data must never be prematurely deleted due to the different forms of retention or other log operations
- Data must never be exposed incorrectly to follower brokers or consumers
- We should not tier data that may potentially be truncated due to Apache Kafka’s replication protocol
To implement a stateful property test for the log layer, we used ScalaCheck’s stateful testing functionality.
Here are the relevant terms to know:
- Log: the log that stores replica data for a partition
- System Under Test (SUT): the real system being modelled, which is a log in this case
- Log model: the modeled state for the system under test (SUT)
- Log segment: a unit of zero or more record batches; consists of a .log file and associated indices
- Active segment: the segment with the highest base offset and to which new appends will be written
- Retention: the process by which users control the size of a topic’s partitions by duration, size, or triggered deletions
- Log start offset: the inclusive lower bound offset for the log
- Log end offset: the exclusive upper bound offset for the log
Initial state generator
Every property test run must start with an initial state—in this case, a model of the log. To create this initial state, we define an initial state generator. The primary behavior that we are testing for is the correct behavior of retention logic. Two critical configurations for this behavior are retention.ms (retention according to time) and confluent.tier.local.hotset.ms (hotset retention). See below for a visualization of how hotset retention causes a Tiered Storage based log to span the tiered set and the local hotset data. Our initial state generator will generate configurations for these settings and an initial state.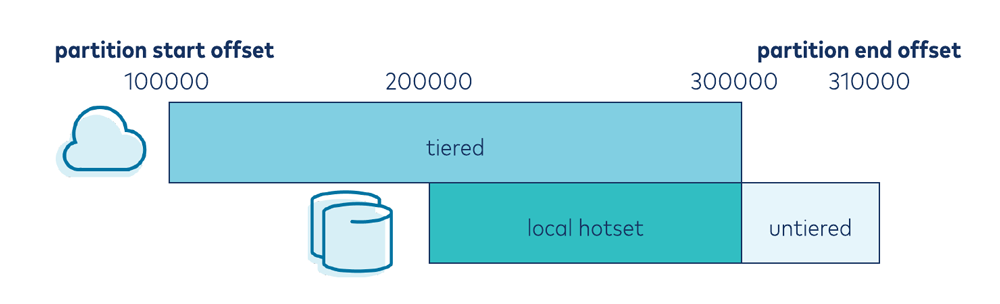
Generator:
retentionMs <- Gen.chooseNum[Long](0, 200)
hotsetRetentionMs <- Gen.chooseNum[Long](0, 50) config = Map("retention.bytes" -> Long.MaxValue,
"retention.ms" -> retentionMs,
"confluent.tier.local.hotset.ms" -> hotsetRetentionMs)
SUT:
log = new Log(generatedConfig)
Model state:
logStartOffset = 0
logEndOffset = 0
config = generatedConfig
segments = [SegmentState(baseOffset = 0, nextOffset = 0, maxTimestamps = None)]
deletedLocalSegments = []
tieredSegments = []
deletedTieredSegments = []
committedEndOffset = -1
Action generator
The log property tests generate different sub-actions at various frequencies, ensuring that more common operations are performed more frequently in proportion to the number listed for each action. Descriptions of these actions will follow.
Gen.frequency( (20, Append), (20, AdvanceHighWatermark), (20, Read), (10, AdvanceTime), (10, IncrementLogStartOffset), (10, TierUploadSegment), (10, RollSegment), (10, CommitTierState), (10, Retention), (10, TierRetention), (1, CloseAndReopen))
Append
Append generates a record batch of different record types, with a bounded range of timestamps and various compression choices. The generated record batch is then appended to the SUT log. The model state is updated to advance the log end offset and accumulate the records that have been appended.
Action: Append(generatedRecords):
Generators: CompressionType: Gen.oneOf(CompressionType.NONE, CompressionType.SNAPPY, CompressionType.GZIP, CompressionType.LZ4)
Record: timestamp <- Gen.chooseNum[Long](baseTimestamp, minTimestamp) key <- Gen.oneOf(Gen.alphaNumStr.map(_.getBytes(StandardCharsets.UTF_8)), Gen.const(null)) value <- Gen.oneOf(Gen.alphaNumStr.map(_.getBytes(StandardCharsets.UTF_8)), Gen.const(null))
RecordBatch: magic <- Gen.oneOf(RecordBatch.MAGIC_VALUE_V0, RecordBatch.MAGIC_VALUE_V1, RecordBatch.MAGIC_VALUE_V2) records <- Gen.nonEmptyListOf(Record) compressionType <- CompressionType
SUT action: log.appendAsLeader(generatedRecordBatch)
Model action: activeSegment.append(generatedRecordBatch) records.add(generatedRecordBatch) logEndOffset = logEndOffset :+ generatedRecordBatch.size
AdvanceHighWatermark
AdvanceHighWatermark simulates the movement of the high watermark (HWM). In Apache Kafka, high watermark increases occur as follower replicas fetch data from the leader. The high watermark affects several behaviors of the log. For example, it dictates the upper bounds of allowable retention, segments eligible for tiering, and log start offset movement resulting from DeleteRecords API calls.
Due to how Apache Kafka performs offset translation, we limit high watermark movements such that they align with record batch base offsets or the log end offset. The reason for this will be discussed later.
Action: AdvanceHighwatermark(newHighwatermark):
SUT action: log.updateHighWatermark(newHwm)
Model: hwm = newHwm
RollSegment
RollSegment forces a segment roll on the SUT’s log. This is necessary because we set segment.bytes and segment.ms to their maximum possible values, given that this logic is currently unimplemented in the model. When it is implemented, this action will no longer be required.
Action: RollSegment()
Log action: Log.roll()
Model: Create a new empty active segment if the existing active segment is empty
TierUploadSegment
TierUploadSegment checks whether any segments meet the necessary conditions for tiering and then simulates an upload of the segment to object storage. The candidate segment must meet the following conditions:
- The segment must not be the active segment
- The segment end offset must be greater than the log start offset
- The segment is the first tierable segment that has not otherwise been tiered
- The segment end offset must be below the high watermark
Action: TierUploadSegment()
Log action: simulateUpload(firstTierableSegment)
Model: tieredSegments.add(firstTierableSegment)
CommitTierState
Tiered logs contain local state consisting of metadata for tiered segments. Confluent Cloud achieves safety of the overall log by preventing deletion of any local segment covered by tiered segments until after this state has been safely committed (flushed).
Action: CommitTierState()
Log action: log.tierPartitionState.flush()
Model: committedEndOffset = tieredSegments.last.endOffset
IncrementLogStartOffset
The IncrementLogStartOffset action simulates two behaviors in Apache Kafka. The first is when an application or user uses the DeleteRecordsAPI to advance the log start offset. The second is when a leader has a higher log start offset than the follower, which will trigger the advance of the log start offset via the replication protocol.
Action: IncrementLogStartOffset(newLogStartOffset: Long) Generated: newLogStartOffset <- Gen.chooseNum(state.logStartOffset, state.highWatermark)
Log action: log.maybeIncrementLogStartOffset(newLogStartOffset, ClientRecordDeletion)
Model: logStartOffset = newLogStartOffset
Retention
Retention applies Apache Kafka’s local log retention to the SUT in the following order of application:
- retention.ms
- retention.bytes
- log start offset
In the case of log start offset retention, any segments lower than the log start offset will be deleted. The retention action must be careful not to delete any local segments that are not deletable due to data that has been tiered. For example, if any tiered segments past the start offset are not deletable, then any following local segments will not be deletable.
Action: Retention()
Log action: log.deleteOldSegments()
Model: Apply retention time retention Advance the log start offset if any local segments have been deleted Apply log start offset retention Apply hotset time retention
TierRetention
The TierRetention action performs retention for the tiered portion of the log. TierRetention is similar to normal log retention, except it is responsible for deletion of the section of the log that has been tiered.
Action: TierRetention()
Log action: log.tierDeleteOldSegments()
Model: Delete the first tiered segment if it is below the log start offset or if maxTimestamp < currentTimeMs - retention.ms
CloseAndReopen
CloseAndReopen closes the log and reopens it. It is important to test the opening of the log as it re-initializes critical variables and may perform log recovery if the log was not closed cleanly. If the generated recover variable is true, the log will be forced to perform log recovery from the beginning of the log as if it were not closed cleanly. This rebuilds in-memory epoch and producer states from local segments rather than restoring them from checkpointed states on disk.
Action: CloseAndReopen(recover: Boolean)
Log action: log.close() new Log(recoveryOffset)
Model: No action
Read
Read performs a read of the log starting at an offset under a particular isolation mode. The offset affects the starting point of the read, and isolation action affects the data that is allowed to be returned by the fetch. For example, for FetchHighWatermark, only records below the high watermark are allowed to be returned.
Read is implemented here as an action rather than as a property check for two reasons. The first is that checking every potential combination of fetchOffset and isolation after every action will be expensive. Secondly, reads can affect the behavior of the log by advancing high watermarks, triggering values to be cached, etc.
Action: Read(fetchOffset: Long, isolation: FetchIsolation)
Generator: fetchOffset <- Gen.chooseNum(0, state.logEndOffset + 1) isolation <- Gen.oneOf(FetchHighWatermark, FetchLogEnd, FetchTxnCommitted)
Log action: log.read(fetchOffset, maxLength = 100, isolation = isolation, minOneMessage = true)
Model action: No action
Checked properties
Afterward, every action the model and the SUT are checked for discrepancies. If any of the following checks fail, the test will ultimately fail:
- Log start, log end, and high watermark offsets must match
- Committed offsets for the tiered log state must match
- Every local log segment must match offset ranges and max timestamp
- Every tiered log segment must match offset ranges and max timestamp
- No segments with a maxTimestamp within the retention window was deleted unless it was due to a specific log start offset update (e.g., DeleteRecords)
- No segments with offsets greater than the high watermark should be tiered
The Read action performs some additional property checks:
- An OutOfRangeException must be thrown if the fetchOffset < logStartOffset and must not be thrown if otherwise
- Records with offset < fetchOffset must not be returned unless necessary for the consumer to correctly advance the fetch offset.
- Records with offset > fetchUpperBound must not be returned
Current limitations
Retention according to retention.bytes is not currently implemented. Given that interactions between retention modes increase complexity, we are looking into supporting this soon. As mentioned earlier, time-based and size-based segment rolls are currently turned off to simplify the log model. Next, we will implement our own auto roll logic by tracking the size of each segment.
Interesting findings
Property tests quickly reveal hidden aspects in your system as they will fail if your model does not sufficiently match the SUT.
High watermark in the middle of batch
The V1 and V2 log format writes records in batches. When the property test advances the high watermark to the middle of a batch, messages are prematurely exposed. This occurs because the log’s offset translation can only work at batch boundaries, which means that the effective high watermark would be the end of the batch. In practice, this is not an issue as followers trigger high watermark advances, and they do not break up batches unless down-converting to older record batch formats.
Segment rolls due to retention
Initially, we did not set up our model to delete the active segment due to retention time. However, we quickly realized that Apache Kafka will force the roll of any segments that are deletable due to time retention. This allows long-standing segments to be deleted. Although this is a known behavior, it was not one that we had considered prior to implementing the model and the realization of this improved our understanding of the system.
Retention is not (currently) idempotent
As described earlier, Apache Kafka today applies retention in the following order:
- Time
- Size
- Log start offset
When retention is performed by time, any segment which has a maximum timestamp within the retention window will block deletion of any segment with a higher offset. If an application uses the DeleteRecords API to increase the log start offset, it may delete segments that are currently non-deletable due to retention time. Therefore, it is possible that log start retention may unblock deletion of additional segments via time retention. This is a minor problem as further deletions will be unblocked in the next retention iteration. However, deletion could be achieved more promptly if log start offset retention is performed prior to time and size retention, making retention idempotent. See KAFKA-12177 for more details.
Learnings
Property-based tests are code and thus need to be tested to demonstrate that they truly work. This is true of many aspects of testing, from microbenchmarks to example-based testing, and it is especially true here. Along these lines, it is useful to make complex tests more debuggable by allowing logging to be turned on.
Ideally, property tests should be fast. It may be worth profiling your property tests to see if you can improve their performance with some small changes. The faster they run, the more examples that you can test.
Certain behaviors of your system can only be discovered after testing a large number of model iterations. There is a trade-off between testing a large number of test iterations in your build system and increasing test times. To gain the most benefit from our property tests, we plan to look at a secondary continuous integration setup where we can increase the size of these runs without slowing down development time for everyone.
Future work
There are numerous ways to improve the functionality and properties tested in our log model to further test interactions between additional topic configurations. Along these lines, we will be implementing retention.bytes retention and automatic segment rolls based on segment.ms and segment.bytes. We also plan to test future implementations of compaction of tiered topics with this model.
Learn more about Tiered Storage
If you enjoyed reading this article and would like to know more about Tiered Storage, check out the documentation for more details.
Thank you to Gardner Vickers for your work on the models and generators extended by this work.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



New With Confluent Platform 8.0: Stream Securely, Monitor Easily, and Scale Endlessly
This blog announces the general availability (GA) of Confluent Platform 8.0 and its latest key features: Client-side field level encryption (GA), ZooKeeper-free Kafka, management for Flink with Control Center, and more.
Introducing the Next Generation of Control Center for Confluent Platform: Enhanced UX, Faster Performance, and Unparalleled Scale
This blog announces the general availability of the next generation of Control Center for Confluent Platform