OSS Kafka couldn’t save them. See how data streaming came to the rescue! | Watch now
Announcing ksqlDB 0.18.0
We’re pleased to announce ksqlDB 0.18.0! This release includes pull queries on table-table joins and support for variable substitution in the Java client and ksqlDB’s migration tool. We’ll step through the most notable changes, but check out the changelog for a complete list of features and fixes.
Pull queries on even more tables
In ksqlDB 0.17.0, we released pull queries on materialized views created using the CREATE TABLE AS SELECT statement. We are now extending pull queries to materialized views created using table-table joins. Here is an example of fetching the current state of your materialized view INNER_JOIN by using a pull query:
CREATE TABLE LEFT_TABLE (id BIGINT PRIMARY KEY, name VARCHAR, value BIGINT) WITH (kafka_topic='left_topic', value_format='json', partitions=4);CREATE TABLE RIGHT_TABLE (id BIGINT PRIMARY KEY, f1 VARCHAR, f2 BIGINT) WITH (kafka_topic='right_topic', value_format='json', partitions=4);
CREATE TABLE INNER_JOIN AS SELECT L.id, name, value, f1, f2 FROM LEFT_TABLE AS L JOIN RIGHT_TABLE AS R ON L.id = R.id;
You can fetch the current state of your materialized view INNER_JOIN by using a pull query:
SELECT * FROM INNER_JOIN [ WHERE where_condition ];. For more information on pull queries, read the documentation.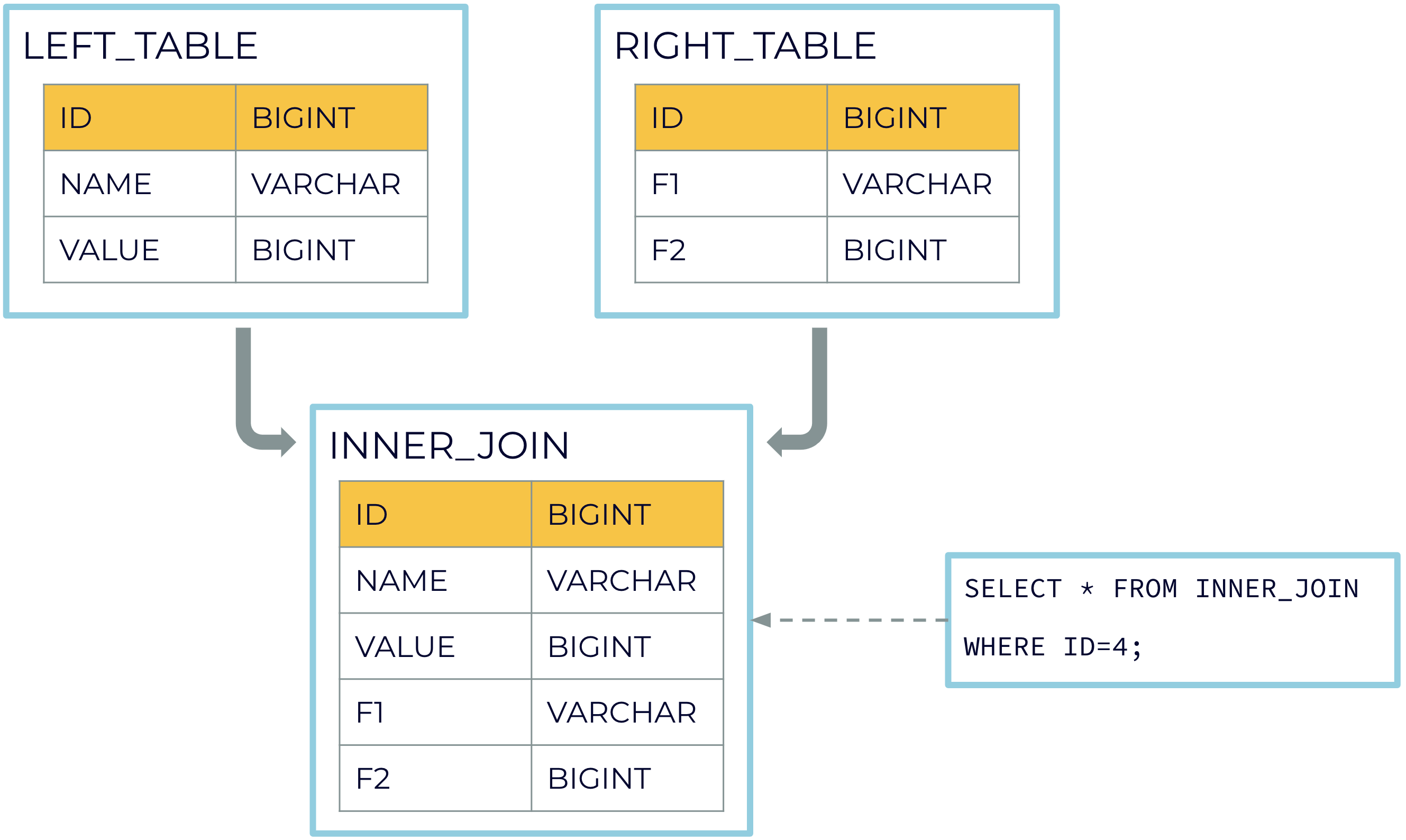
More ways to substitute variables
You can now use variable substitution in the Java client and the ksqlDB migration tool.
The Java client now contains two methods, define and undefine, which work similarly to ksqlDB’s DEFINE and UNDEFINE statements. Here is an example of how they can be used:
// Define some variables
client.define("topic", "people");
client.define("format", "json");
// Execute the statement with all the variables replaced. This is equivalent to executing
// CREATE STREAM S (NAME STRING, AGE INTEGER) WITH (kafka_topic='people', value_format=’json’);
client.executeStatement("CREATE STREAM S (NAME STRING, AGE INTEGER) WITH (kafka_topic='${topic}', value_format=’${format}’);");
// Undefine a variable
client.undefine("topic");
// Return a map of all defined variables. This will return the map {“format”, “json”}
Map<String, Object> variables = client.getVariables();
To define variables in a migration, you can either add DEFINE statements in your migration file, or you can pass the --define flag when running the migration tool’s apply command.
Consider the following migration file:
DEFINE FIELD=’NAME’;
CREATE STREAM S (${FIELD} STRING, AGE INTEGER) WITH (kafka_topic='${topic}', value_format=’${format}’);
If you run ksql-migrations --config-file /my/migrations/project/ksql-migrations.properties apply --next --define topic=people --define format=json to apply the above migration, the tool will execute the resulting statement:
CREATE STREAM S (NAME STRING, AGE INTEGER) WITH (kafka_topic='people', value_format=’json’);
Get started with ksqlDB
ksqlDB 0.18.0 widens support for pull queries and variable substitution. For a complete list of changes, refer to the changelog.
Get started with ksqlDB today, via the standalone distribution or with Confluent, and join the community to ask a question and find new resources.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.