OSS Kafka couldn’t save them. See how data streaming came to the rescue! | Watch now
Introducing Derivative Event Sourcing
First, what is event sourcing? Here’s an example.
Consider your bank account: viewing it online, the first thing you notice is often the current balance. How many of us drill down to see how we got there? We probably all ask similar questions such as: What payments have cleared? Did my direct deposit hit yet? Why am I spending so much money at Sephora?
We can answer all those questions because the individual events that make up our balance are stored. In fact, it’s the summation of these events that result in our current account balance. This, in a nutshell, is event sourcing.
Event sourcing: primary vs. derivative
Now imagine event sourcing in the context of an online order system: you place an order and are able to get status updates when your order is confirmed, fulfilled, and shipped. Just like a bank balance, current order status is calculated by consulting the individual events for a given order. The diagram below depicts the event flow for a single order service.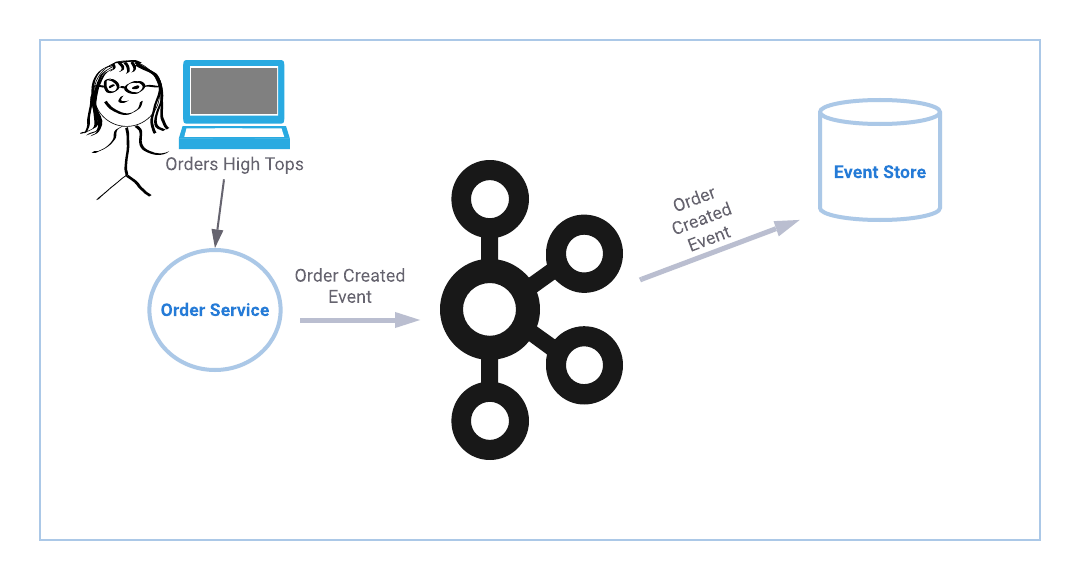 If you happen to be the proud owner of a single order service, then you are all set to begin.
If you happen to be the proud owner of a single order service, then you are all set to begin.
But what if you have more than one order service?
Something that tends to happen at companies that have been around for more than a sprint is the accumulation of technical debt. Sometimes that debt takes the form of duplicate applications. Mergers happen and you adopt other applications that, for reasons beyond your control, cannot be retired or rewritten right away. In other words, sometimes you end up with more than one order service—enter derivative event sourcing!
An observational approach to the event sourcing pattern
Try to picture implementing event sourcing for the following company: the Cabot Cove Detective Agency has been in business for over 20 years. They began as a small agency with primarily walk-in business before growing into the leading supplier of online background checks worldwide. In order to comply with international laws and facilitate growth, they acquired several companies that were already active overseas, resulting in a diverse mix of technical assets.
Today, their online order space is broken down into five different services written in a variety of programming languages. Each service handles a different geographic region, and all were written or acquired at different times. Their oldest order service is nine years old, lives in CVS, and requires an interpretive dance about Angela Lansbury in order to compile. It is also the only order service that is certified to do business in Portugal.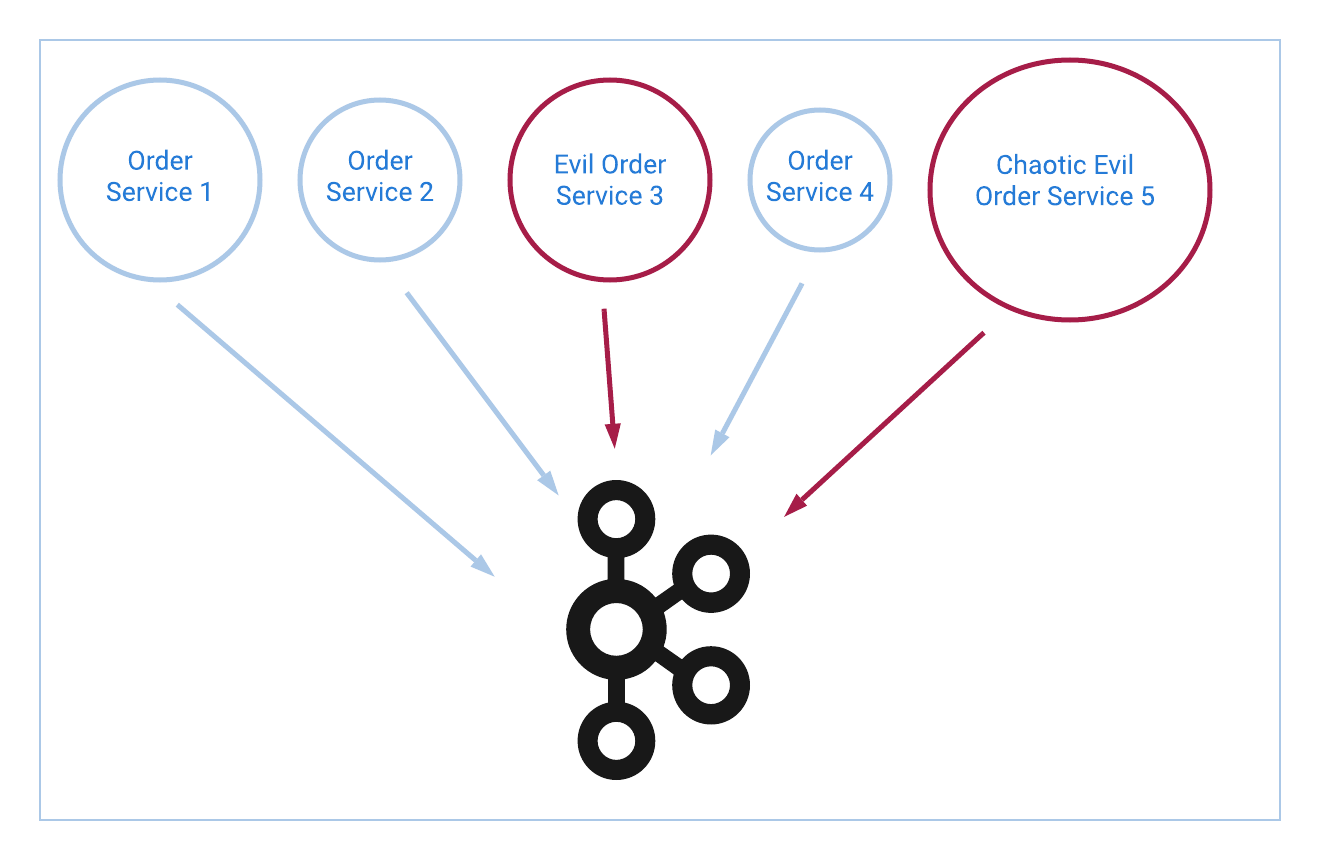
Let’s use the order created event as an example. In the above scenario, we would have to update all five services to connect to Apache Kafka®, create the event in all the appropriate places inside each service, and then produce that event to a Kafka topic. If you have experience maintaining legacy applications, feel free to start sweating now.
The first point to consider is if connecting to Kafka from all services is even possible. The older services may not be compatible with any of the available APIs. Upgrading that service to be compatible is an enormous amount of effort for a service you’re hoping to retire. Furthermore, even if you do manage to produce events from all five services, what happens when you need to add to or change the schemas? Having to incorporate legacy applications in the current world of CI/CD can be a nightmare for change management, especially when that change requires a coordinated multi-service push.
Maintaining a mixed environment like this can be a huge impediment to implementing event sourcing. This situation is what the derivative event approach is designed for and where you get the largest return on investment.
Complex environments can be simplified using derivative event sourcing
Derivative event sourcing is quite literally deriving events from something that has been observed. This differs from the more common practice of emitting events directly from the service where the event took place. Change data capture (CDC) is currently the most prevalent source to derive events, though user and application logs are also valid options.
If you are interested in more details about change data capture, see this excellent blog post by Robin Moffatt: No More Silos: How to Integrate Your Databases with Apache Kafka and CDC.
Let’s see how to handle multiple order services using derivative event sourcing.
Derivative event sourcing can be modeled by the following flow: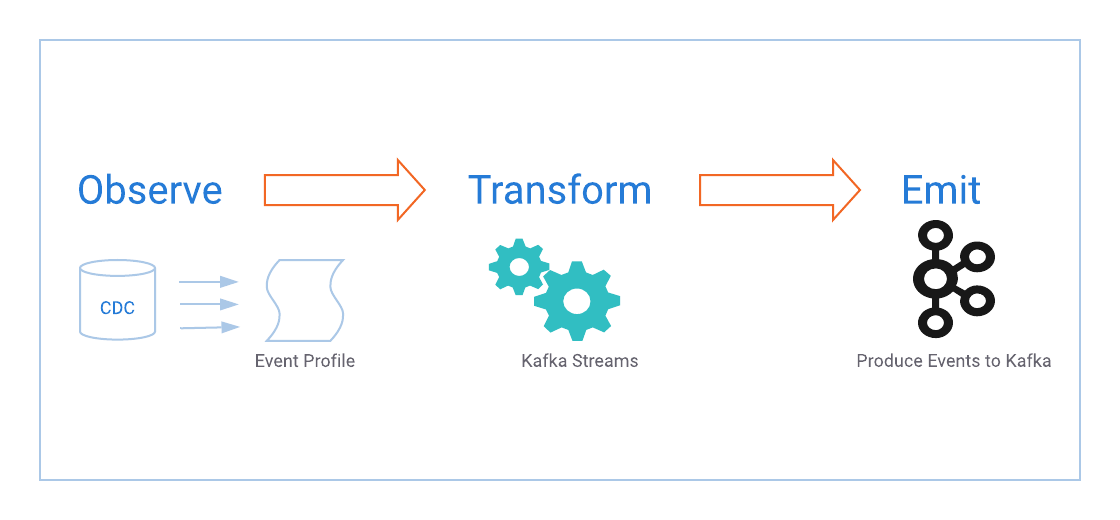
Observe
Create a source and define what to look for
- Find/create a durable event source to observe; this can be change data produced from the database that the application writes to, an application log, or any other source that contains the event profile you need to observe
- Define an event profile: create a unique set of conditions that can be applied to identify the event you want to observe
As an example, create a durable event source for orders: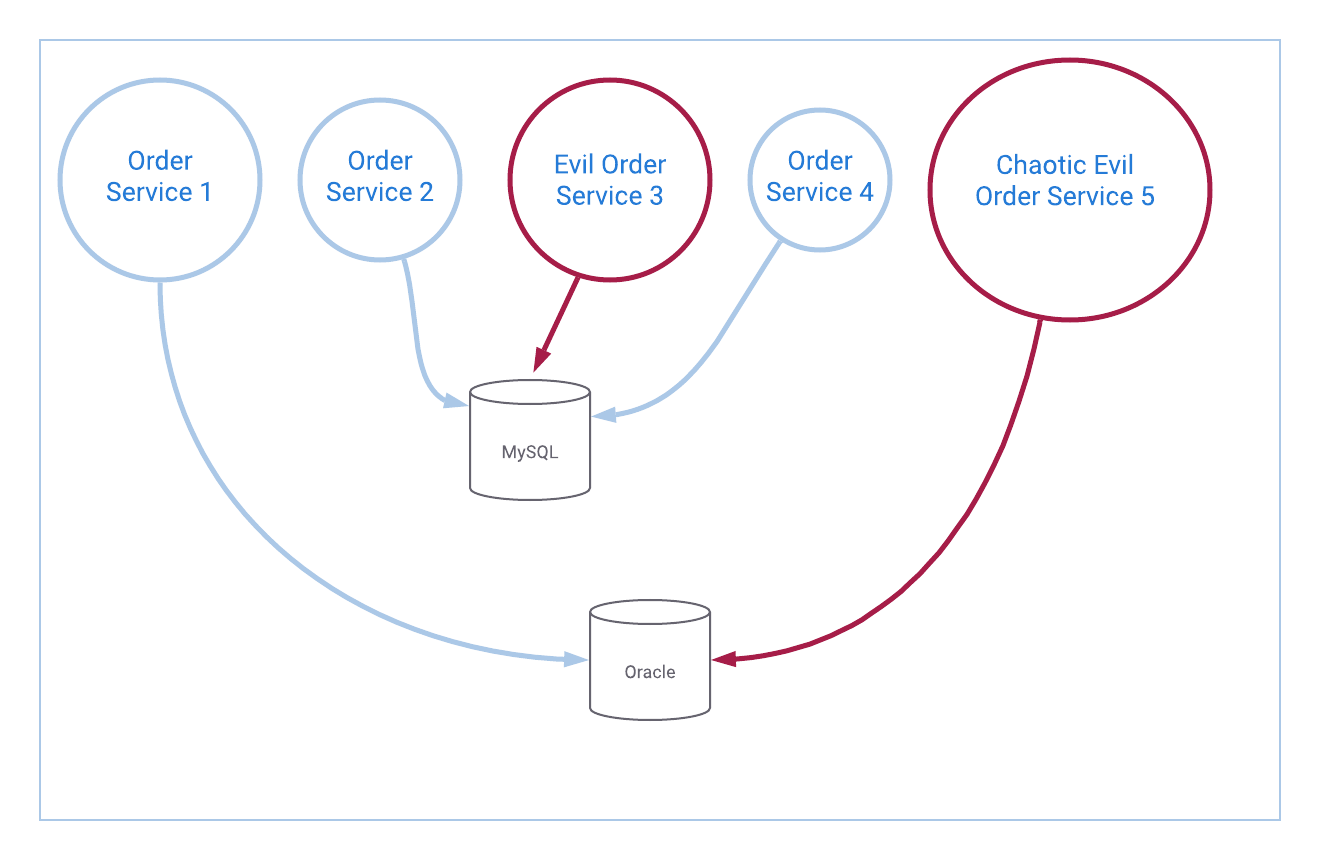
Take a look at the backend stores for our order services. We find that Order Service 1 and Order Service 5 write to the same Oracle database, while the remaining services use MySQL. Oracle GoldenGate is a product that will allow us to produce messages to Kafka for every single activity that happens in the database—updates, inserts, deletions—we’ll get them all. Debezium is a similar offering that works with MySQL as well as many other datastores.
Using Oracle for our example, we set up GoldenGate, and now have access to every single event happening in the database. The primary developer tasked with supporting the oldest service stares at the change data messages flowing into Kafka, free from the tyranny of supporting an age-old application she jams out to the Hamilton soundtrack, alarming several bystanders and her UPS lady.
The same process would be followed to set up Debezium for MySQL, though we will continue to focus on the Oracle services for brevity.
Next, define the order created event profile.
Order Service 1 and Order Service 5 both use the same Oracle table to store their orders. This table, oddly enough, is named ORDERS. Now that GoldenGate is set up to produce all database changes to Kafka, we can look at the DB.ORDERS topic and see every insert, update, and delete that happens to the ORDERS table.
Even though both services write to the same table, they do so in different ways. In other words, the profile we need to look for to know that a new order has been created is different for Order Service 1 and Order Service 5. This happens for a number of reasons, the simplest being technology differences—one service may use the Java Persistence API and commit all changes at once, while another might insert a new row and then perform updates.
For our target services, the above is indeed true. The following event profiles for detecting when a new order has been created are defined as such:
Order Service 1:
Any Message received on the DB.ORDERS topic that has an insert operation type where ORDER_NUMBER is not null.
GoldenGate Message:
{"table":"DB.ORDERS","op_type":"I","op_ts":"2019-10-16 17:34:20.000534","current_ts":"2019-10-16 17:34:21.000000","pos":"00000001490000018018","after":{"ORDER_NUM":8675309,..."MORE_COLUMNS":""}}
Order Service 5:
Any message received on the DB.ORDERS topic that has an update operation type and ORDER_NUMBER is null before the update and not null after the update.
GoldenGate Message:
{"table":"DB.ORDERS","op_type":"U","op_ts":"2019-10-16 17:34:20.000534","current_ts":"2019-10-16 17:34:21.000000","pos":"00000001490000018023","before":{"ORDER_NUM":null,..."MORE_COLUMNS":""},"after":{"ORDER_NUM":42,..."MORE_COLUMNS":""}}
For all the remaining services, we can create event profiles such that all services are defined.
Now the sources are ready to observe, and we know what we’re looking for. The next step is to transform the observed events into the events we need.
Transform
Transformation is simply taking the message that has been observed and transforming that into the event you need with the relevant details
There are a number of frameworks that lend themselves for use in the transformation step. My personal favorite is Kafka Streams. Using Kafka Streams as the transformation vehicle gives you the ability to rekey events, manipulate time, and most importantly, create complex event aggregates. You also get exactly once semantics in a lightweight Java library, which should alone be enough to tip the scales for many use cases.
Returning to our example we use Kafka Streams to create a new central event service that consumes from the DB.ORDERS topic. Since we don’t have any dependencies between our order services, we can use the following flow. Again, using the two Oracle services:
- Create a KStream named baseOrderStream from the DB.ORDERS topic
- Using baseOrderStream as the source, create an orderService1 KStream, apply the filters determined for the Order Service 1 event profile, and map the source message to create the derived event
- Using baseOrderStream as the source, create an orderService5 KStream, apply the filters determined for the Order Service 5 event profile, and map the source message to create the derived event
The flow ends up looking like the glorious example shown below:
KStream<String,JsonNode> baseOrderStream = builder .stream(DB.ORDERS, Consumed.with(stringSerde, jsonSerde));
KStream<String, JsonNode> orderService1 = baseOrderStream .filter(isInsert) .filter(hasNonNullOrderNumber) .map((key,value) -> KeyValue.pair(value.path("after").path("ORDER_NUMBER").asText(), createOrderCreatedEvent(value, ORDER_SERVICE_1)));
KStream<String, JsonNode> orderService5 = baseOrderStream .filter(isUpdate) .filter(hasNewNonNullOrderNumber) .map((key,value) -> KeyValue.pair(value.path("after").path("ORDER_NUMBER").asText(), createOrderCreatedEvent(value, ORDER_SERVICE_5)));
The central event service consumes a message that matches the event profile for Order Service 1: a row that is inserted into the orders table with a value that is not null in the ORDER_NUMBER field. Next, compose an order created event message that contains the relevant details about the new order, possibly including which service the event originated from. We do the same when consuming a message that matches the event profile for Order Service 5.
For the MySQL services, we would create a similar flow and end up with a KStream representing each order service.
Emit
Produce the transformed event message to a Kafka topic
For this use case we want to combine the order created events from all services into a single topic. This means that we need to merge all of the individual KStreams and output them to a Kafka topic. In a reveal that will surprise no one, the merge function from the Kafka Streams API allows us to do just that. Merging several streams can have offset order implications that may or may not be desirable. I recommend following the golden rule of, “When in doubt, ask Matthias J. Sax on Stack Overflow.”
| Regarding JSON, when dealing with a legacy application, you may find that Avro fits easily into your stack; you may also find it does not. When it comes to legacy applications, I use JSON, the Swiss Armesque format for transforming even the worst data structures. Again, this choice comes down to effort—why spend time modeling a legacy data structure you no longer want to exist? If using Avro for your change data provides advantages, then by all means use it, but if not, JSON is a perfectly valid choice for your durable event source. As you are most likely aware, this choice does not preclude you from using Avro for the emitted events. In fact, handling incoming messages as JSON while outputting transformed events as Avro allows you to move forward with the concept of schemas as an API, while still minimizing the amount of effort spent on legacy services. | ||
Going back to our example, create a new Kafka topic called event-order-placed and produce all messages that match the event profiles for the OrderCreatedEvent to this new topic. We will see messages for orders placed in all five order services in the same topic.
Note: it is important to design your event schema to include the right information. If you designed your schema to include the service the order originated from, it may be of use to downstream consumers who only need a portion of the orders or wish to vary behavior based on region.
The code to emit derived events from all five order services is:
orderService1.merge(orderService2)
.merge(orderService3)
.merge(orderService4)
.merge(orderService5)
.to(event-order-created,Produced.with(stringSerde,avroSerde));
Conclusion
Derivative event sourcing is awesome.
The diagram below contains the finished design for our order services example and illustrates all three steps in the derivative event sourcing approach.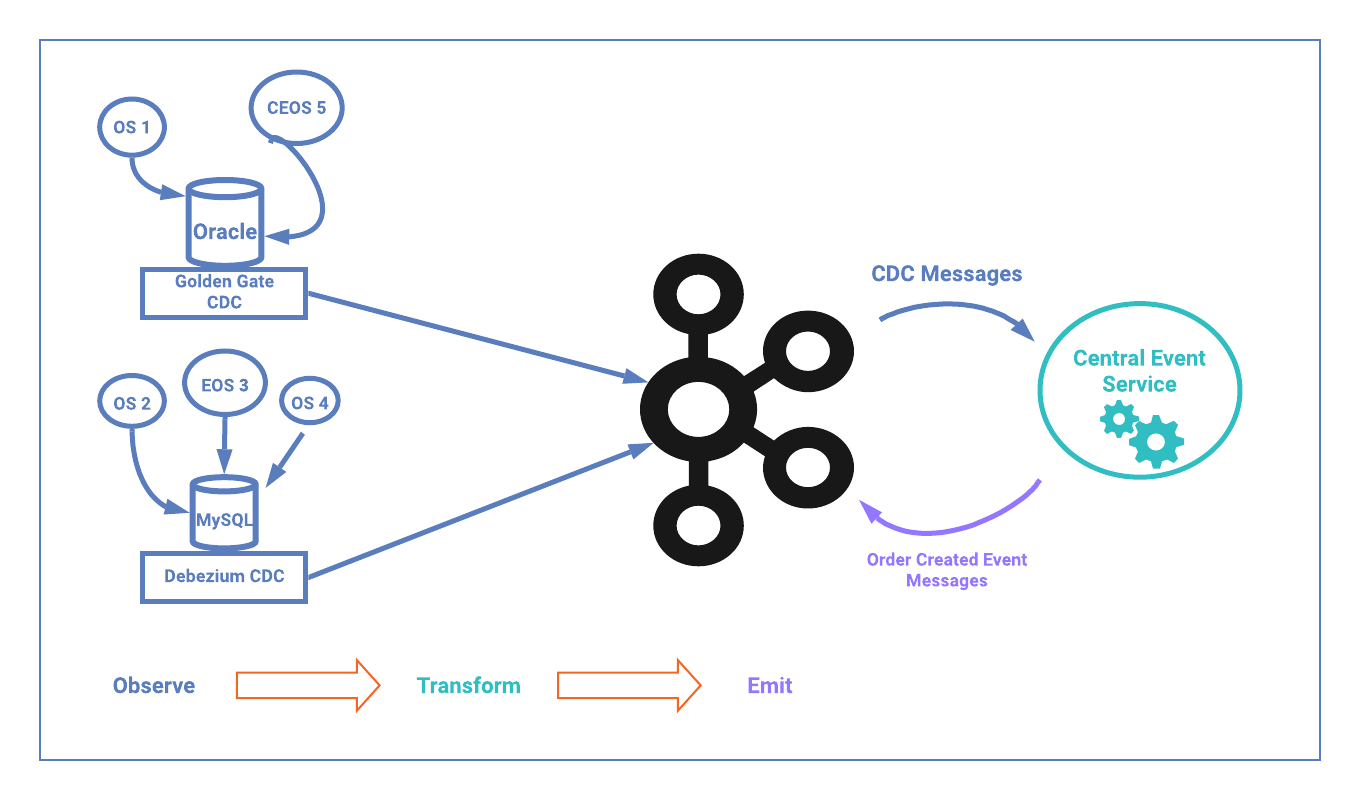 Note the extra benefits of decoupling. Let’s say there’s a critical issue with order fulfillment, resulting in the need to temporarily pause order events. We can pause or stop the central event service, and orders can continue to be placed in the customer-facing Order Services. The change data messages will continue to be produced to Kafka and upon resolution of the fulfillment issue, the central event service is able to pick up right where it left off. This decoupling is a direct benefit of having durable event sources and using Kafka Streams for our centralized event service.
Note the extra benefits of decoupling. Let’s say there’s a critical issue with order fulfillment, resulting in the need to temporarily pause order events. We can pause or stop the central event service, and orders can continue to be placed in the customer-facing Order Services. The change data messages will continue to be produced to Kafka and upon resolution of the fulfillment issue, the central event service is able to pick up right where it left off. This decoupling is a direct benefit of having durable event sources and using Kafka Streams for our centralized event service.
The multiple order service scenario is a simple, straightforward example of the derivative event sourcing pattern. However, it is not relegated to simplistic use cases. Derivative event sourcing can also be applied in highly complex environments that require multi-table or even multi-source event aggregates.
In my Kafka Summit San Francisco talk titled Using Kafka to Discover Events Hidden in Your Database, I dive into some of the more complex scenarios. If you are interested in more information about derivative event sourcing, including how to define event profiles, best practices for event schemas, event transformation tips, and handling complex event aggregates, I encourage you to check it out!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Developer Experience in the Age of AI: Developing a Copilot Chat Extension for Data Streaming Engineers
AI is bringing changes in developer experience… we shared what we learned in this article about creating our new GitHub Copilot chat extension for data streaming engineers.


5 Steps to Building With AI: What It Can Do Reliably (and How to Start)
This post introduces the VISTA Framework, a structured approach to prioritizing AI opportunities. Inspired by project management models such as RICE (Reach, Impact, Confidence, and Effort), VISTA focuses on four dimensions: Business Value, Implementation Speed, Scalability, and Tolerance for Risk