[Webinar] Master Apache Kafka Fundamentals with Confluent | Register Now
How Confluent Treats Incidents in the Cloud
An inevitable consequence of rapid business growth is that there will be incidents: even the best, most well-planned systems will begin to fail when you expand them very quickly. The question is, are you doing everything you can to reduce the rate of incidents? And are you doing everything possible to learn from them?
Setting data in motion is no small task, and at Confluent we’re focused on making this possible not only for our own business, but also for all of our customers. We have to consistently rise to meet the challenges of putting data in motion, and as we grow to meet these challenges, our business grows with us. While rapid growth is great, it comes with its own difficulties.
For example, it was necessary for Confluent’s infrastructure to expand rapidly to keep up with growth. With any significant change to infrastructure comes the significant risk of instability. Alongside the infrastructure growth, our customer base is continually expanding as well. Each new customer brings with them the possibility that they could use our systems and services differently than anyone else has before, which has the potential to expose new bugs or bottlenecks we have not previously seen. Finally, Confluent’s employee base is also rapidly growing, bringing with it the possibility of someone doing something differently than has been done before. This could expose shortcomings in processes, or require the creation of new guardrails we’ve never considered before. All of these factors and more make incidents unavoidable in a high-growth scenario.
Incidents are a troublesome phenomenon, but the goal must be to ensure their rate of growth is smaller than that of the organization. Incidents are (at least) these things:
- An indication of a growing, successful company that is moving quickly
- An unplanned lesson in technology and its interactions with people
- Guidance on where to focus efforts: features versus stability
At Confluent, we take incidents seriously. More importantly, we take their lessons to heart. Incident management is a powerful feedback loop. Harness it poorly and you’ll not be in business long, but harness it well and you’ll build some of the most resilient software on the planet. Here are our high-level thoughts and philosophies on incidents and what can be learned from them. If you manage software in production there should be some nuggets of wisdom that will help you too.
Incidents are a symptom of success
This is a hard lesson to take in a positive fashion. It is easy to fall into the trap of thinking that you are failing when the number and severity of incidents is rising. Although you should not become complacent, you should remember that incidents happen when you’re successful.
When there is so much business coming at such a rapid rate, the stability of complex systems will suffer as a result. Even in the case where there is nearly zero feature velocity, simply the additional load on systems from adding customers and others using your technology will begin to push some as-yet-undiscovered envelope of operational stability.
“The good news: incidents are inevitable by-products of the complexity that comes with growing a successful business.”
—Adaptive Capacity Labs
If it is happening to you, it may not feel nice, but if nothing else, take heart: every other successful company has gone through these same growing pains.
Try to remember, as you go through the next sections and learn those lessons, this is partially due to success. When you solve the problem, try not to solve the problem of being successful. There is still an element of business that you’re doing correctly, and you will want to continue doing that part, while still being sure to change what you can to earn the love of your customers.
Part of what it means to be successful is to have a robust feature velocity. This means that you are adding features to your platform that customers find valuable. Some customers will want those features even if they come at the cost of stability. We see this, for example, with customers who are very happy to turn on features for their account before those features hit general availability (or GA, the term used to indicate a feature is at a point that we feel comfortable all customers could use). Other customers will want stability at whatever the cost, including lack of features, and have no interest in pre-GA features. Using the GA designation is one way Confluent helps our customers choose the level of stability versus feature velocity that they prefer.
How quickly a feature (or product) should be given to all customers is a bit of a quandary. When is the right moment? The best way we’ve determined is to use the incident velocity as an indicator. If you have no major incidents in a given product/feature for a month (as an example), this indicates the product/feature is stable and ready for GA. In other words, the number of incidents is guidance as to which backlogs deserve your talented teams’ time and energy: feature backlogs, or tech debt paydown backlogs. See the section below, “Incidents indicate which backlog needs priority” for further guidance here.
Incidents are unplanned lessons about your systems
Incidents feel disruptive because they interrupt your normal flow of progress. But do not let their interruptive nature guide you down the wrong path. One tendency is to think that incidents are proof that your teams are not giving the products and features their due attention. It is better simply to think of incidents as a feedback mechanism; a signal for where you should focus your engineering effort, which we will read more about shortly.
Once you have an incident on your hands, though, you should consider how to maximise the information you can get from it.
“The most important thing to learn about incidents is that you should learn from them. You are paying for the lesson. Take note.”
We have noticed a tendency among incident responders across the industry to feel exasperation when incidents occur; to get into a sort of heightened, nearly manic state in trying to mitigate it. These are natural and normal feelings, for sure, but you must strive to focus on resolving the incident and gain positive learning from the experience.
While it is true you want to react quickly and mitigate the problem quickly, you must also consider that this is not the last time you will experience the same set of circumstances that brought you to this point. In the future, you will want to respond to these circumstances (or, at least, ones similar to them) more quickly and appropriately. Better, you should consider ways you could have computer systems respond to these circumstances automatically, so that no one needs to wake up in the middle of the night or stop eating dinner with their family to address the issues. The pinnacle of planning for the future is to design systems that do not present the same problems in the future given the same circumstances.
What are some things to learn from incidents? First, there are a number of high-level organizational things you can do. These are high-level strategies for learning from multiple incidents when considered in aggregate.
- Identify what themes present themselves over many incidents. At Confluent, we write up the lessons we’ve learned from our incidents regularly so that anyone can read the high-level summary of what was learned from the incidents to notice patterns.
- Analyse incidents using data analysis methods. At Confluent, we have sophisticated dashboards that tell us which incidents are caused by the same underlying problem, which ones have the most action items assigned, whether those action items are finished or unfinished, etc.
- Make decisions based on the data analysis of the incidents. What should we be doing about the incidents we are seeing? Are we running in the right clouds, or engaging the right types of customers?
Some incident lessons are fairly low level and tactical. These lower-level tactical learnings typically result in action items to ensure that these things do not happen again. For example:
- When we introduced feature X, it presented too much instability for the benefit it provides
- Sometimes it’s hard to wake up Joe
- Some of our employees don’t have a very good cellphone plan
- Our VPN can be unstable at some pretty inconvenient moments
- Some of our vendors are no longer providing the stability we need
So when do you sit back, reflect on the incident, and take notes? Some parts, usually the tactical bits, are noticed during the incident, but many more are discovered or synthesised after the incident is done, during the post-mortems.
“The post-mortem is the part where you take notes.”
The primary mechanism for learning from an incident is the post-mortem. Post-mortems can be run in a number of ways, but there is an industry standard called “blameless” that is generally adopted. The goal of a post-mortem is to review the incident once it is resolved, as soon as is reasonably possible, with everyone who was involved. Once completed, the post-mortem results should be used to identify root causes, fix them, and determine how to make responses to future incidents better. For example, how could you:
- Notice outages quicker?
- Fix them faster?
- Make them happen less often?
- Communicate to stakeholders (usually customers) earlier, or more clearly?
When the post-mortem is finished, there should be concrete action items for certain teams or individuals to perform, typically things like “fix these bugs,” or “update these documents/processes,” or “add these monitors,” or “automate these processes.”
Another great mechanism for learning from the incident is the “5 whys” methodology, for determining the ultimate root cause of the problem.
The process for completing post-mortems varies by company, and is highly dependent on your culture, number of employees, and velocity. At Confluent, sometimes an incident will first be written up by one team, where tactical items are created. Then subsequently reviewed by several other teams, where further tactical and some strategic initiatives are born. Then finally reviewed by executive staff to determine strategic shifts, or make certain the originating team learned all it could from the incident.
Incidents indicate which backlog needs priority
If you have “too many incidents,” that tells you that stability velocity is low, which can (and often does) correlate with a high feature velocity. But how many incidents are “too many”?
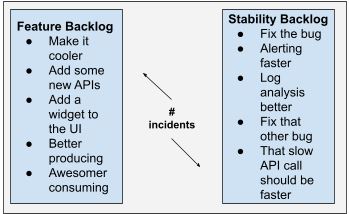
What about one incident per week? Maybe this is so few that you should actually implement more features! Three per week? Maybe this is fine, but getting uncomfortable. Seven? One every single day? Time to prioritise the stability backlog items!
In the previous paragraph, we floated three weekly incident numbers. One, three, and seven. But they could be anything, depending on your customers and teams. If incidents are causing customer dissatisfaction about the stability of your platform, or negatively impacting team velocity, it’s time to take whatever those numbers are for your team and cut them in half. Conversely, what if customers are not noticing your incidents or are strongly asking for features rather than stability? What if team velocity is too low, because some teams are spending too much time prematurely optimising for zero incidents? Double those numbers. Somewhere in between? Use your best judgement to slightly raise or lower the numbers.
You will probably notice early on that not all incidents are created equal. Some are quite awful for the customer experience. At Confluent, we call those “Severity One.” Some are never noticed by any customer at all; you only have them because they are emergent problems that need to be addressed before they become worse. We call those “Severity Four.” The rest fit somewhere in between. The frequency of incidents of a given severity will guide you on how many items to prioritise from the feature/stability backlogs.
To reiterate the earlier “how many incidents” math, a single Severity One incident is probably enough to consider prioritising your stability backlog, but 10 Severity Fours is likely still well within an acceptable range.
Defining precisely what is Severity One to Severity Four is a very difficult task. So far, we have found it useful (albeit not without dissenters) to define these at a high and “human” level. That is, we may say something like “If more than one customer is severely impacted, this is Severity One.” What does “severely” mean? For that matter, what does “customer” mean? Could it be another team at your company?
Unfortunately, this is a human endeavour, and though we’d like to put very precise technical measurements on these things, it isn’t possible. More correctly: it’s possible, but no one will read the 200 pages of technical jargon to figure out precise severity in the heat of the moment, so they’ll make a judgement call. You can always “raise” the severity if it is deemed important. At Confluent, we have settled on a mere one to two pages of fairly non-technical jargon to define our severities.
Specifying an incident severity “too severe” only means that your teams get to practice a high-severity incident when it’s actually low-stakes. This is not a bad thing. Once the incident is over, and the heat is off, you can always lower the severity to what it should have been, then close it out with a brief post-mortem.
Incident strategy when it’s “not your fault”
At Confluent, one incident type we commonly encounter is based on quotas for our cloud products. For example, suppose a customer wants another 200-node cluster in some region on some cloud provider, but we are only allowed to have 12,000 total nodes in that region, and already have 11,900 allocated. Thus their cluster may get stuck in a CREATING state while waiting for another 100 nodes.
We are a rapidly expanding user of three major cloud providers. They each have hundreds of unique and unpredictable quotas. So what can we do about this?
After several incidents where a given quota hit 100%, we decided to automate the quota request process. We have written special software that attempts to keep ahead of quotas. As an example, if our limit is 12,000, and we have 11,900 used, we request our limit be raised to 15,000. But when the software fails, or the cloud provider does not provide API access into the quota, or the cloud provider fails, the quota may get near its max state.
We treat this state as an incident, using the post-mortem process to make sure we capture why the quota increase was not automated, and concrete steps to automating the quota increases.
Most cloud providers have undocumented or hard-coded quotas, or, most maddeningly, regular quotas that aren’t manageable via an API.
When we discover such a quota, we must work with the cloud provider’s TAMs or support system to get support for automating that quota. This can be a multi-quarter ordeal, requiring long-term tracking of requirements. It’s important to have regular calls with your cloud provider to remind them of their shortcomings, to be sure they keep these in their radar for fixing.
Another aspect of having a presence in all three clouds is that sometimes one of them will go down for a component they fully own. One typical example is networking instability in one of the providers’ infrastructure.
It can be tempting to say: “This was their networking infrastructure, nothing can be done,” then skip doing a post-mortem. Resist this temptation! There is nearly always something you and your team can improve upon, even in these situations.
For example, did you notice the networking instability before your customers did? If not, why not? When customers started calling in with problems with your service, were your customer representatives already aware of the situation, and were able to quickly allay your customers’ fears? If not, why not? Was your public status page updated with details of the networking instability shortly after you knew about it? If not, why not?
All these questions are based on incidents we’ve had with cloud providers, based on problems they had that we could “do nothing about,” but in fact, there was plenty we could do, from a non-technical perspective! It turns out, in any given incident, the technical concern of “solving the problem” is only half the point. The other half is communicating what is happening, and what you’re doing to fix it, along with your guesses as to timelines. Be sure communication is a top priority in your incident handling process.
Conclusion
Thanks for reading along. Hopefully, you’ll have learned a little about what you can do about incidents, but more importantly, how you can learn from incidents in your organisation. If there is only one piece of advice I could impart, it would be this:
“Incidents are unplanned lessons. Do not panic, take notes, and learn from them!”
Did you like this blog post? Share it now
Subscribe to the Confluent blog





New With Confluent Platform 8.0: Stream Securely, Monitor Easily, and Scale Endlessly
This blog announces the general availability (GA) of Confluent Platform 8.0 and its latest key features: Client-side field level encryption (GA), ZooKeeper-free Kafka, management for Flink with Control Center, and more.