Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
6 Ways Data Streaming is Transforming Financial Services
It should come as no surprise that financial services (FinServ) organizations are fiercely driven when it comes to earning market share. After all, the FinServ industry is projected to reach a whopping market size of $28.5 trillion by 2025 (up from $22.5 trillion in 2021). But with the potential for massive reward comes the inevitable challenge of staying one step ahead of competitors seeking to carve out their own profitable niche. So what solutions do FinServ companies have at their disposal to elevate their business strategy and solidify a strong advantage against industry rivals?
The answer lies, as it so often does in modern, technology-driven marketplaces, in the realm of the digital. A majority of FinServ organizations rely on massive amounts of data to power their business models. By quickly deriving value from their data, FinServ companies can reap enormous benefits, including more personalized customer experiences, increasingly accurate market forecasts, predictive fraud analysis, and much more. But as the volume of data generated by all this activity continues to increase, legacy data systems are struggling to keep up, and a new paradigm of modern data platforms and architectures is emerging. In addition, FinServ regulators continue to set advanced goals around governance, auditability, and transparency, leading to complex technical challenges for businesses in this industry. As a result, many FinServ companies have begun to utilize data streaming platforms and event-driven architecture to process and access their data in real time for a variety of transformative use cases that are driving value and giving them a leg up in the marketplace.
Keep reading to discover how event-driven architectures and data streaming platforms are transforming financial services by enabling faster, more innovative software development. Learn how the world’s largest banks, payment processors, and FinTech companies are utilizing Apache Kafka via Confluent Cloud to support their customers, streamline internal operations, and satisfy regulatory requirements for data privacy in production.
You’ll see how FinServ organizations can benefit by adopting technology that fuels:
- Know Your Customer with personalization of applications
- Real-time analytics and fraud detection
- Cybersecurity and regulatory compliance
- Trading platform and market data as a service
- Customer tracking, alerts, and notifications
- And much more
Here are the six top areas of FinServ where data streaming is making an impact.
1. Data Streaming Platforms Unlock Opportunities in Consumer Banking
Consumer banking includes some of the world’s largest financial institutions with checking, savings, mortgage, and credit card divisions, as well as challenger banks and FinTech services. Traditional banks have historically encountered numerous difficulties with scalability and security when managing all of their customers on a single platform. Adopting Apache Kafka architecture helps mitigate some of these challenges and assists in becoming cloud-native.
Online account management, loan applications, anti-fraud scanning, credit report analysis, brokerage, accounting, risk management, stress testing, and historical reporting are all examples of areas of active software development for consumer banking companies.
Challenger banks have less of the traditional infrastructure and physical business operations that define more traditional consumer banking groups. Rather, these businesses focus on building new software that delivers consumer banking services via user-friendly mobile applications and websites. By focusing on ease of use and accessibility, challenger banks are able to take market share from more established industry leaders.
FinTech companies are developing platforms for consumer banking that include cryptocurrencies and distributed ledger blockchain solutions. FinTech organizations are also innovating in online payments, yield farming, and derivatives trading platforms. Cryptocurrencies like Bitcoin and Etherium have disrupted traditional financial services and led to the rise of new forms of art with NFT platforms. Consumer banks, startups, and FinTech companies all share common requirements for custom software development that can be streamlined with Confluent Cloud.
Real-time data streaming platforms like Confluent Cloud, leverage Apache Kafka streaming architecture to modernize the way consumer banks process and use their data. With Confluent Cloud, these organizations are able to leverage Kafka for an enterprise-grade experience, empowering IT teams to easily access data as real-time streams, integrate data silos, and unlock legacy data. Data streaming architecture based on Apache Kafka, and optimized by Confluent Cloud, allows consumer banks to build innovative applications that deliver:
- A cutting-edge IT infrastructure
- Comprehensive security controls
- Advanced fraud prevention systems
- Instantaneous payments solutions
- Responsible management of personal data and identity information
- And much more
2. Confluent Cloud Helps Deliver a Seamless Payments Experience
The volume of digital payments conducted online was $6.75 trillion in 2021 and is expected to grow to $12.55 trillion by 2027. Event data about each individual customer, business provider, product, and relevant platform activity can be aggregated by Apache Kafka for ecommerce analytics, anti-fraud scanning, business intelligence, shipping, and logistics. Confluent received top awards at Bank of America’s 11th annual Technology Innovation Summit for enabling the FinServ company to leverage Apache Kafka for these types of high-impact use cases.
Confluent Cloud scales to support the collection of fine-grained data at the levels required by online payment applications in ecommerce and B2B networks. Developers can also build apps with microservices that access event data for the automation of platform activity and allow for personalization that is based on each user account. This enables FinServ companies to deliver better, more customized services to individual customers.
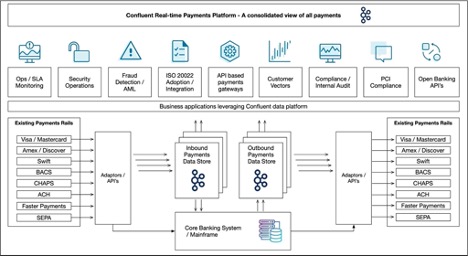
Some of the advantages the fully managed Confluent Cloud platform offers payment processors are:
- The ability to feed optimized data to data lakes
- Modernize the application stack by building microservices that communicate over a common technology in Apache Kafka
- Developing data pipelines for ML processing of information
- Anti-fraud, network analysis, monitoring, and real-time metrics
- Best-of-breed tools for financial regulatory compliance
- Best-of-breed tools for cybersecurity and cloud governance
- The ability for online payment processors to reliably scale across all levels and fluctuations of user traffic
3. Real-Time Data Elevates Fraud Fusion
Many of the world’s largest corporations have already adopted Apache Kafka architecture as the basis for fraud protection and developed internal fusion centers for threat monitoring that shares real-time data across platforms. The event data collected by Apache Kafka from platform activity is also used to automate approaches to e-commerce security, provide real-time decisions on loan approvals, analyze historical user data, and optimize risk management policies.
The ability to batch process data with machine learning (ML) is accomplished through custom data pipelines to cloud hardware via APIs and queues. Data lakes allow fusion centers to pool information from different domains, brands, and platforms into a common source for statistical analysis. The grouping of data into topics by Kafka speeds the processing and storage of data to enable real-time network monitoring with ML interpretation and AI modeling. So Confluent connectors coupled with stream processing allow customers to source, route, clean, and validate data from various sources, and feed correct data to ML training data sets.
Those Kafka topics make the data available to microservices, which can be composed to build modern, scalable applications. This opens up the ability to build custom software for fusion center displays with charts, analytics, alerts, and graphs that capture various aspects of network activity in real-time. Network administrators in fusion centers can automate threat response based on data-driven logic to enforce organizational security policies across domains.
4. Data Streaming Drives Deeper Insight Into Complex Capital Markets
Consumer banks with investment finance divisions have complex IT requirements and regulations related to the trading of stocks, bonds, and other securities in international capital markets. The modeling of simulations of complex market activity by artificial intelligence and machine learning is leading to advances in risk management and trading strategies in financial groups.
Data streaming architecture is transforming trading markets in areas like:
- Portfolio valuation
- Calculating exposures relative to limits
- Comparing critical ratios like hit and fill ratios across venues
- Monitoring round-trip times
- Optimizing collateral
- Managing margins
- Establishing guardrails for risk teams
The event-driven architecture provided by Apache Kafka, and optimized by Confluent Cloud, is ideal for developing internal analytics that monitor stock, bonds, and investments for complex financial institutions under strict banking regulations. Hedge funds and private equity groups use Kafka for quantitative trading, historical simulations of market activity, and the development of high-frequency trading software.
Financial institutions that offer brokerage services to customers, including cryptocurrency trading platforms, use Kafka and Confluent Cloud to build apps that offer real-time information related to post-trade processing, settlement, and clearing. These trading apps rely on real-time data and extremely low latency to accurately confirm account balances when purchases have occurred less than a second beforehand. And, because Confluent Cloud enforces security policies across data pipelines and data lakes, developers are able to build these trading apps while complying with regulatory requirements for their sector of operations.
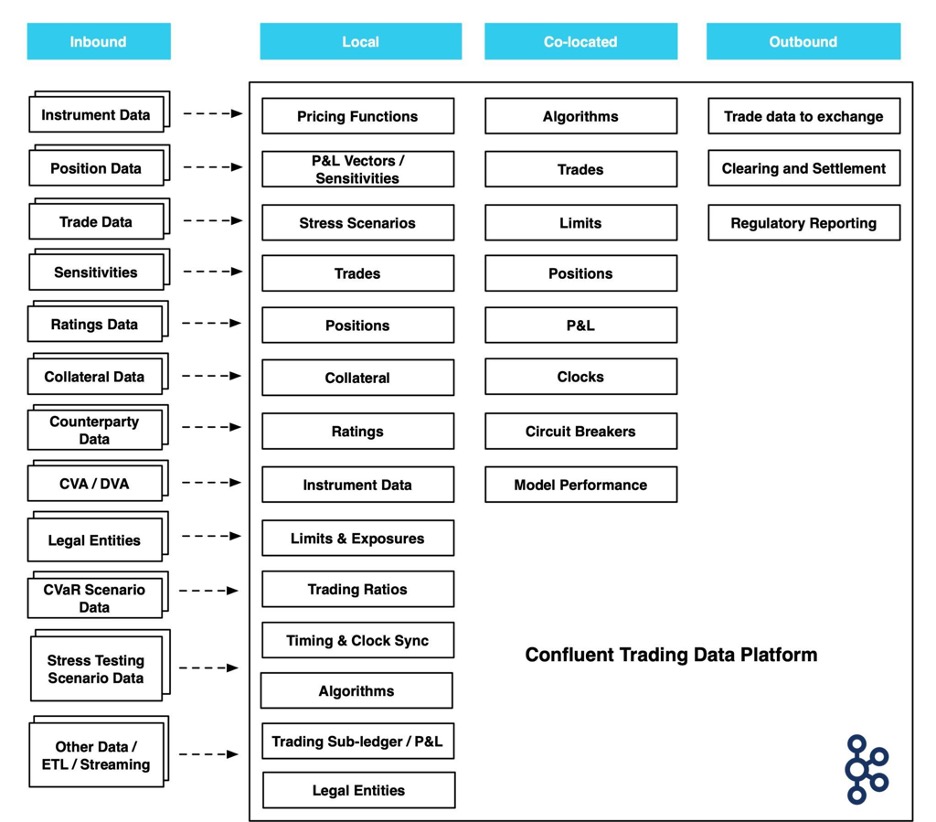
Integrated Trading Ecosystems: Learn how you can build an integrated trading ecosystem with data in motion. Download the free white paper that covers use cases for financial services, including how connectors sync systems and create streaming data pipelines.
The Euronext stock exchange chose the Confluent Platform as the basis of the Optiq event-driven trading platform that provides a tenfold increase in capacity and an average performance latency of 15 microseconds for roundtrip orders and market data. Euronext operates regulated securities and derivatives markets in Amsterdam, Brussels, Lisbon, Paris, Ireland, and the UK. Confluent provided expert support for the development of the project.
5. Real-Time Data Processing Revolutionizes Risk Management
The modeling tools used by finance and insurance companies to perform risk management assessments are optimized through the use of real-time data with low latency. The ability to receive time-stamped data from IoT devices at scale allows for the monitoring of weather, seismic, tidal, and satellite sensors, which yield data that can be processed on cloud software and used by research groups.
By building custom analytics that aggregate this data with charts, alerts, and metrics, companies can control the display of data streams to make the information actionable. The same techniques are used by sensors in self-driving vehicle navigation, shipping, logistics, supply level tracking, etc. in other industries. By breaking down data silos and processing data from event streams, real-time risk can be modeled with statistical methods and ML analysis for the requirements of most sectors.
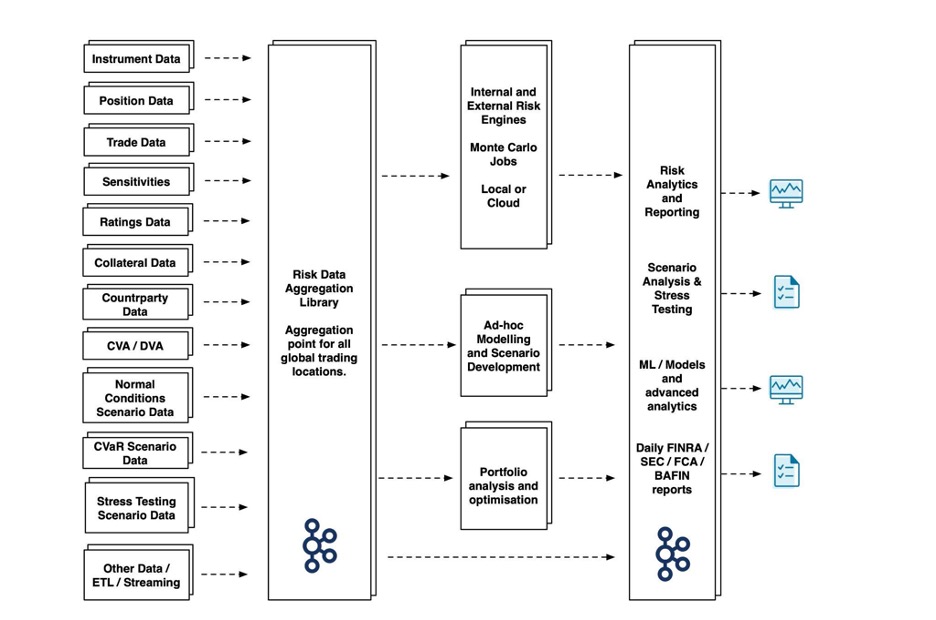
Confluent Cloud includes the Identity API and Risk Engine for easier implementation of common risk management solutions in enterprise software development. The Identity API automates user authentication, token management, and security authorization on network connections. The Risk Engine conducts an analysis of data streams and implements a triggered response to apply security policies where required. Confluent Connectors build a bridge to legacy software.
Companies like Tesco use these solutions for risk management in retail operations. The application of risk management strategies to live trading markets can be built on ksqlDB with Databricks data lake integration or using any cloud service provider like AWS, GCP, or Azure.
6. Data-Driven Insights Lead to Innovation in the Insurance Sector
Insurance companies are pursuing digital transformation to become more data-driven. This includes the adoption of cloud-native software solutions, like Confluent Cloud, that manage separate divisions of operations with unified data lakes for centralized processing, risk management, and AI simulations. Customer account management, automated payments, accounting, and billing are separated from risk modeling, stress tests, financial analysis, and asset management. Data streaming architecture enables insurance companies to break down data silos and utilize data pipelines for insight.
Underwriting teams now use machine learning and statistical analysis of data to account for a wide range of financial variables when calculating risk. Some insurance companies use techniques similar to the banking sector to fight platform fraud and customer claims inflation. Others have adopted IoT devices to monitor production, supply, and safety in real time.
For examples of how insurance groups have adopted Confluent Cloud and Apache Kafka architecture to build innovative solutions for their operations, see the Generali Switzerland case study. Humana shows how health care insurance providers can benefit from data streaming to improve interoperability. Confluent also has two ebooks you can download on the subject:
- Insuring the Future Through Data
- The Ongoing Disruption of Insurance: A Shift to Real-Time Streaming Data
Financial Services Case Studies: A World of Opportunity Awaits
To learn more about how FinServ organizations are evolving to meet the demands of an increasingly fast-paced, digital marketplace, we recommend taking a look at some of the following resources. You’ll discover how developers in the sector have applied Apache Kafka and Confluent to transform their approach to a variety of high-impact use cases:
- Goldman Sachs: Transaction Banking
- Citigroup: Banking and Regulations
- New York Mellon: Data Distribution Hub
- Capital One: Risk Insights
- ING Bank: Real-Time Fraud Protection
- RBC: Data and Analytics (DNA)
- Nationwide Building Society: Open Banking
- KeyBank: Digital Bank Initiative
For even more information on how data streaming is paving the way to innovation in FinServ, you can download the free whitepaper to go into more depth: “10 Ways Confluent Drives Transformation in Financial Firms” or browse seminars, articles, and podcasts about Confluent Cloud.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.