New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
How to Write a Connector for Kafka Connect – Deep Dive into Configuration Handling
Kafka Connect is part of Apache Kafka®, providing streaming integration of external systems in and out of Kafka. There are a large number of existing connectors, and you can also write your own. Developing Kafka connectors is quite easy thanks to the features of the Kafka Connect framework, which handles writing to Kafka (source connectors) and reading from Kafka (sink connectors).
If you are developing a source connector, your job is to fetch data from an external source and return it to Kafka Connect as a list of SourceRecord instances. With sink connectors, the Kafka Connect framework fetches data from a Kafka cluster and passes it to the connector. The job of a sink connector developer is then to write that data to the external system. In neither case does the connector have a responsibility to produce to or consume from Kafka directly.
When writing a connector for Kafka Connect, handling configuration correctly is of utmost importance. Read on to find out more!
Kafka connector configuration
Whether you are developing a source or sink connector, you will have some configuration parameters that define the location of the external system as well as other details specific to that system, for example, authentication details. The user provides these parameters when deploying the connector. Because this process is prone to human error, it is very important to validate them.
The Kafka Connect framework allows you to define configuration parameters by specifying their name, type, importance, default value, and other fields.
Here is an example:
ConfigDef config = new ConfigDef();
config.define (
"hostname",
ConfigDef.Type.STRING,
"",
ConfigDef.Importance.HIGH,
"Hostname or IP where external system is located"
);
There are several overrides of the ConfigDef.define() method that receive different combinations of required and optional arguments.
Validators
For validation purposes, you can provide a validator for any config parameter and pass it as an argument to the ConfigDef.define() method. You can use built-in validators or implement a custom one. The validator’s ensureValid() method receives the name and the value currently provided for a specific config and should throw a ConfigException if the value is not valid.
public class CustomValidator implements ConfigDef.Validator {
public void ensureValid(String name, Object value) {
if ( isValueInvalid() ) {
throw new ConfigException( "Invalid value: " + value);
}
}
}
One limitation of the ConfigDef.Validator API is that it only sees the value of the config it validates, but not other config values. This can be problematic in some cases where the validity of a config depends on the values of other configs.
Recommenders
Besides validators, you can also provide an implementation of ConfigDef.Recommender for individual config parameters. Its purpose, as the name suggests, is to recommend valid values for a specific config. This is useful in cases when there is a final set of valid values for a certain config. Furthermore, in some cases, valid values of a config parameter can vary depending on the current values of other configs.
Let’s say you are building a source connector that fetches data from a web service using SOAP requests. To allow the connector deployer to choose the authentication type appropriate for this use case, you can define a config parameter called auth_type. However, the config value provided by the deployer has to match one of the values that you specified as supported authentication types.
For simplicity, imagine that there are three types of authentication supported: NONE (no authentication), BASIC (username and password based), and SSL_CERT (which uses an SSL client certificate). However, SSL_CERT authentication only works if you use the HTTPS protocol, which you would specify using another Boolean parameter called use_https.
The implementation of a recommender might look like this:
public class AuthTypeValidator implements ConfigDef.Recommender {@Override public List<Object> validValues(String name, Map<String, Object> parsedConfig) { Boolean useHttps = (Boolean) parsedConfig.get(“use_https”); if(useHttps) return Arrays.asList("NONE", "BASIC", "SSL_CERT"); else return Arrays.asList("NONE", "BASIC"); }
@Override public boolean visible(String name, Map<String, Object> parsedConfig) { return true; } }
The validValues() method returns a list of valid values for the config with the name provided as the first argument. The second argument is a map of all parsed config values, where you can see any other config required for evaluating valid values. Returning an empty list from this method has “any value allowed” semantics, meaning that the recommender does not suggest any specific config values. This makes sense in case the recommender is only used to determine visibility (relevance) of the config, as discussed next.
The second method, visible(), is used to determine whether the config is relevant at all, considering other configuration parameters. In this example, auth_type config visibility does not depend on any other config. In other words, it is always relevant, so true is returned. However, other configs, such as username and password, would only be relevant if the auth_type config value is set to BASIC.
The Kafka Connect framework allows you to specify inter-config dependencies by providing a list of dependents with any config definition. In this example, auth_type should be passed as dependent to the use_https config definition.
Validation process
Validators provided as a part of a config definition are used by the Kafka Connect framework to validate configuration before the connector instance can be created. Both SourceConnector and SinkConnector extend the abstract class Connector, which provides a default implementation of the validate() method:
public Config validate(Map<String, String> connectorConfigs) {...}
As you can see, this method receives a map of configs provided by the user, with config values passed in String form. It also returns Config instance, which is basically just a wrapper for a list of ConfigValue instances, evident from the Config class source code:
public class Config {
private final List configValues;
public Config(List configValues) {
this.configValues = configValues;
}
public List configValues() {
return configValues;
}
}
For every config parameter defined in the connector config definition, configValues list will contain a ConfigValue instance, which wraps the value parsed from the user input. If the value is not provided by the user, the default value will be used.
If the config parameter definition includes a validator, it will be used to validate the value. In the event that the value is invalid, a ConfigValue instance for that parameter will include an error message. Also, if a recommender is included in the config parameter definition, the corresponding ConfigValue instance will contain a list of recommended valid values.
The validate() method is called when you attempt to create an instance of a connector using Kafka Connect’s REST API request “POST /connectors”. If you provide invalid configuration values, the response will contain an error message of ConfigException, thrown by a validator. Here is an example:
{
"error_code": 400,
"message": "Connector configuration is invalid and contains the following 1 error(s):\nInvalid authentication type: XXXXX\nYou can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`"
}
Besides the error message, such a response suggests using another REST API endpoint: /connector-plugins/{connector-type}/config/validate, which validates the provided config for a given connector type without creating an instance of that connector. It returns detailed information about each configuration parameter, including its definition, current value (parsed from the input or default value), validation errors, recommended values, and visibility.
This is used by GUI applications such as Confluent Control Center, which provides input forms for deploying connectors. Recommended values for a config parameter, if available, can be used to provide drop-down menus containing only valid values for that parameter.
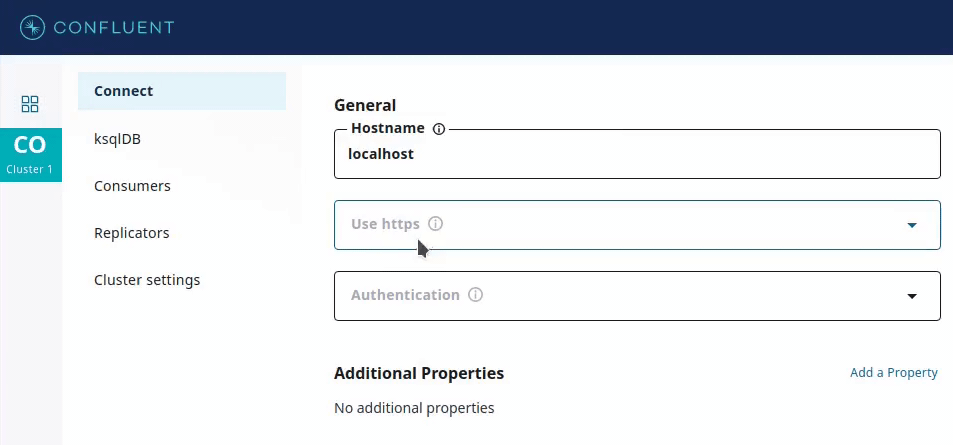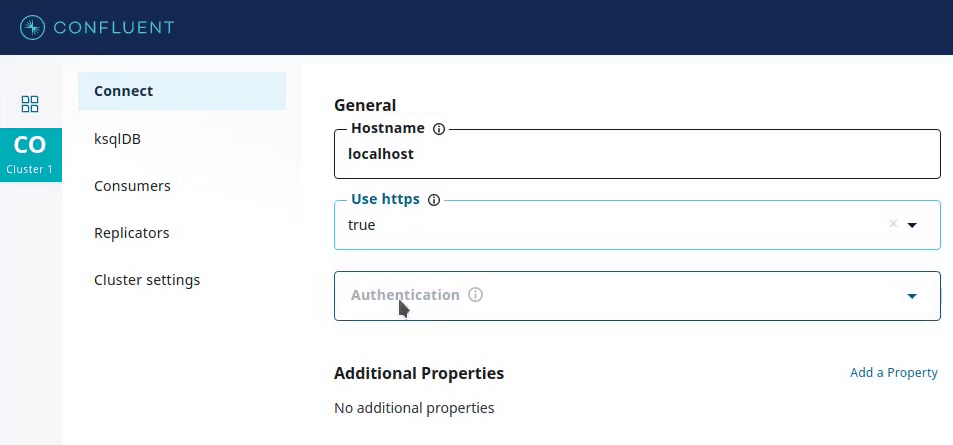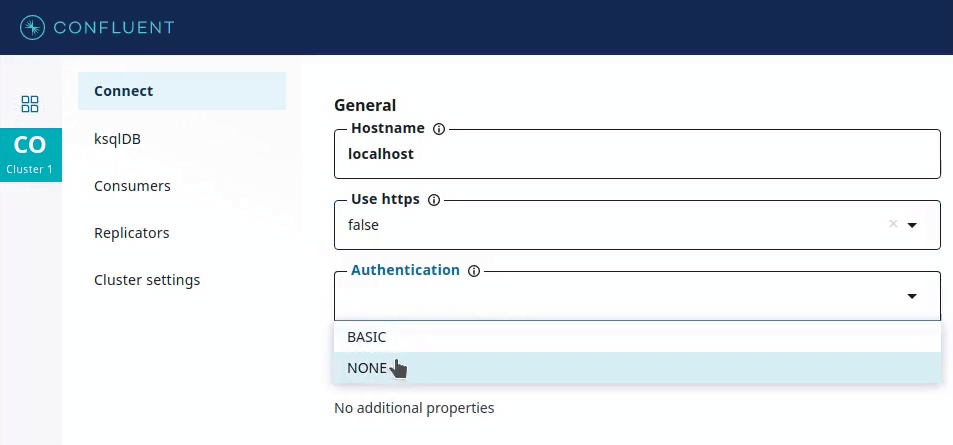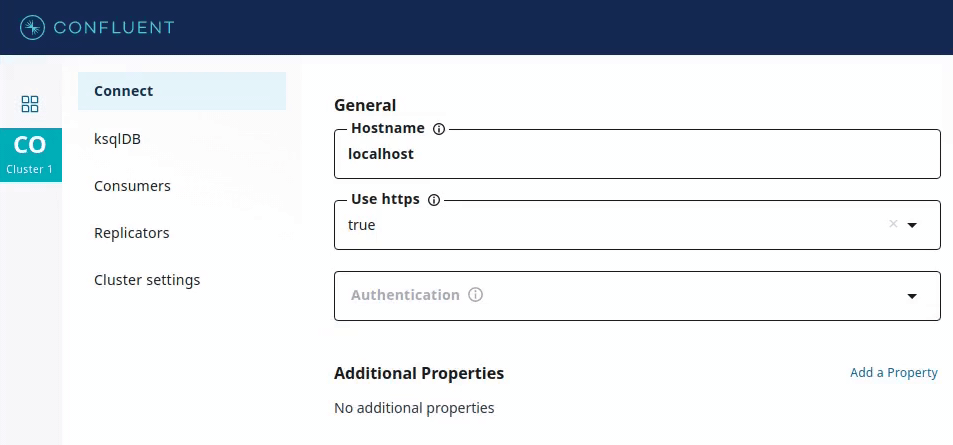
In addition, the recommender can specify visibility to show or hide corresponding form fields.
Validation of dependent configs
As described in the section on recommenders, in some cases, config validity depends on the values of other configs.
A shortcoming of the ConfigDef.Validator API is its unawareness of recommenders that could be provided for the config. The API also lacks access to config values other than the one that it validates. This means that validators can only be used for configs where validity of the config value doesn’t depend on other config values. Currently, the only way to deal with this situation is to override the connector’s validate() method and validate such configs “manually” instead of using a validator.
However, the default implementation of the validate() method does some heavy lifting—it parses the values to appropriate types and sets default values where value is not provided, which you probably don’t want to do from scratch.
Calling super.validate() from the overridden method, then re-validating only dependent fields manually, and finally updating the validation result before you return it seems like an optimal solution. This way, validators can still be used for independent fields; you only need to deal with dependent fields manually. Also, the recommender is still used to provide recommended values for the dependent config.
@Override
public Config validate(Map<String, String> connectorConfigs) {
Config config = super.validate(connectorConfigs);
ConfigValue authTypeCfg = getConfigValue(config,"auth_type");
Object authTypeValue = authTypeCfg.value();
if (!authTypeCfg.recommendedValues().contains(authTypeValue)) {
authTypeCfg.addErrorMessage("Invalid auth type: " + authTypeValue);
}
return config;
}
private ConfigValue getConfigValue(Config config, String configName){
return config.configValues().stream()
.filter(value -> value.name().equals(configName) )
.findFirst().get();
}
Conclusion
Connector configuration can consist of one or more configs with a limited set of valid values, and sometimes these values depend on other config values. The Kafka Connect framework provides a recommender API as a way to plug in custom logic so that you can calculate permitted values while taking other config values into account.
Validators are not aware of recommenders or any config values other than the one that they should validate, so in cases where valid values depend on other configs, they cannot provide the required functionality. For such configs, final validation is done by overriding the validate() method of the connector.
Start building with Apache Kafka
If you want more on Kafka and event streaming, check out Confluent Developer to find the largest collection of resources for getting started, including end-to-end Kafka tutorials, videos, demos, meetups, podcasts, and more.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





