New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building Confluent Cloud – Here’s What We’ve Learned
In July 2017, Confluent launched a private preview of what would later be known as Confluent Cloud. This platform as a service product has grown rapidly; less than three years after its inception, Confluent Cloud is offered on all major cloud providers, spans numerous regions, and hosts thousands of Apache Kafka® brokers. Along the way, we have continuously enhanced the architecture, grown the team rapidly, and learned a lot! This brings us here, where we’ll explore the current architecture of Confluent Cloud, how our experience with the product has benefitted both Apache Kafka and Kafka in Confluent Cloud, and finally some of the lessons we’ve learned.
If you are new to Confluent Cloud or just need a refresher, I recommend starting by reading Announcing Confluent Cloud: Apache Kafka as a Service, where Neha Narkhede describes how Confluent Cloud is easy to use within a source-available ecosystem, provides a cloud-agnostic solution, grants early access to features, offers operational expertise from Confluent, and more. For an overview of what to expect from a managed Kafka service, see The Rise of Managed Services for Apache Kafka by Ricardo Ferreira.
Our current architecture
The architecture of Confluent Cloud can be broken into two major pieces: the control plane and the data plane. We’ll discuss these one at a time, starting with the data plane. Specifically, we’ll focus on the data plane’s network architecture.
Data plane network
A data plane network architecture includes everything needed to enable your applications to communicate with a hosted product. For Confluent Cloud, this varies slightly depending on the type of physical cluster it is exposing (e.g., Kafka, Confluent Schema Registry, ksqlDB, or Kafka Connect). We’ll focus here on a physical Kafka cluster (PKC). The following diagram gives a high-level outline of the Kafka data plane.
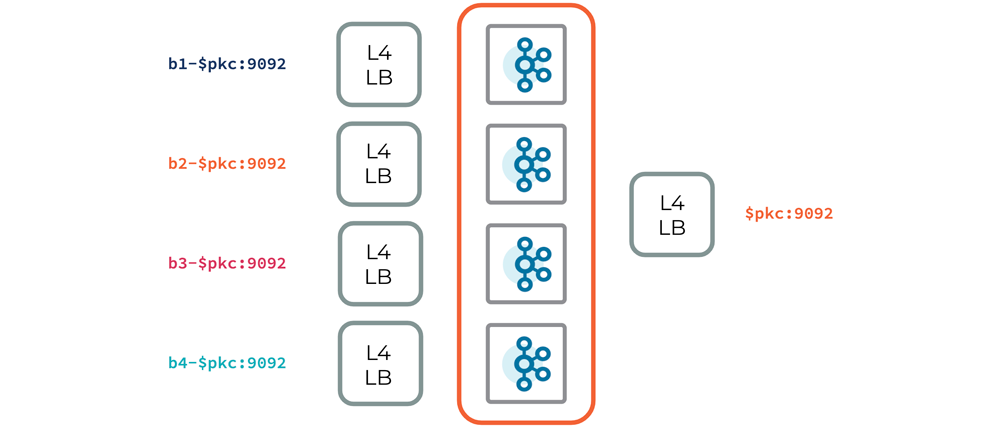
As illustrated, each broker is exposed via a layer 4 load balancer, which is addressable with a DNS record. But this in itself isn’t a good experience for a managed Kafka cluster—we want to abstract away the brokers altogether so that a client doesn’t have to include each individual broker in its configuration. This allows us to dynamically scale clusters in response to changing workloads, without requiring configuration changes in the client.
To accomplish this abstraction, we use an additional layer 4 load balancer for each Kafka cluster. Unlike the others, this load balancer will proxy traffic to a randomly chosen, healthy broker, instead of a single static broker. This load balancer is then given a broker abstract DNS record, which will be used by all logical Kafka clusters that are scheduled on this multi-tenant, physical Kafka cluster.
One benefit of this network architecture is its simplicity: without the complexity of a routing layer, we eliminate potential issues that may arise with having to manage dynamic configuration, availability of additional infrastructure, bad actor scenarios, etc. This is especially important for a data plane, as availability is paramount. This architecture doesn’t currently support cloud-provider-specific solutions, such as AWS PrivateLink, because we expose each broker with its own load balancer. However, we’re actively working on adding this support.
Control plane
It’s important to understand the scope of the data plane. Each physical cluster has its own isolated data plane, so you can think of this data plane as the sum of many micro data planes. In Confluent Cloud, we have thousands of physical clusters. We need a mechanism that can handle provisioning, status propagation, self-healing, upgrades, maintenance, and more. This is the responsibility of the control plane.
The control plane consists of two main components: the mothership and the satellites. These components communicate with each other via Kafka. The mothership is a group of applications responsible for receiving API requests, making scheduling decisions, monitoring the environment, sending the desired state to satellites, and summarizing the actual state received from satellites. A satellite is an abstraction that is scoped to a single Kubernetes (K8s) cluster and hosts one or more physical clusters (e.g., Kafka, ksqlDB, or Connect). Each satellite connects to the mothership during its startup process and is responsible for managing the lifecycle of the physical clusters that it hosts, as well as reporting the clusters’ status to the control plane. You can see a visual representation of the control plane below.
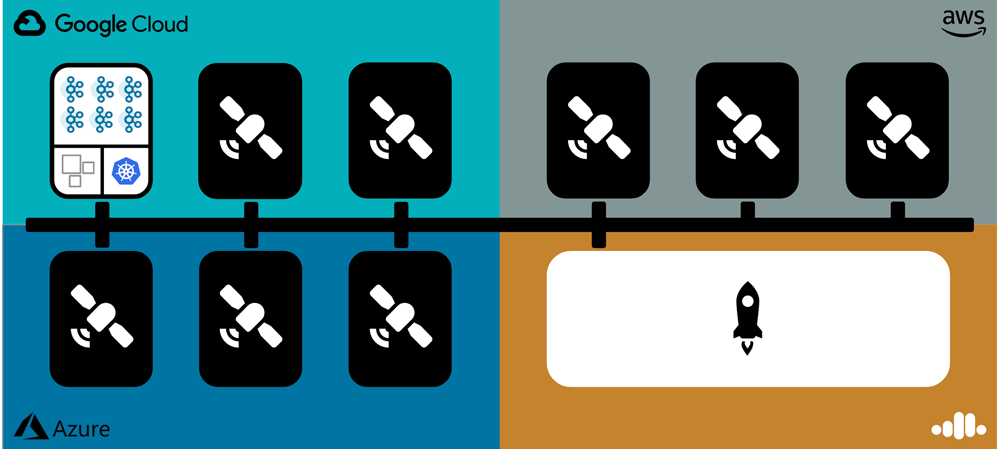
In general, there is one satellite per region. In practice, there are usually multiple satellites to meet availability and physical or network isolation requirements.
The physical clusters hosted by each satellite are encapsulated in a Kubernetes custom resource called the physical stateful cluster (PSC). Each satellite contains an instance of Confluent Operator, which manages the lifecycle of these resources. The PSC declaratively describes the desired state of a physical cluster, and the Operator materializes this into Kubernetes-native objects such as Services, StatefulSets, ConfigMaps, PersistentVolumes, and more.
The satellite receives PSCs from the mothership. In this article, we’ll focus on the provisioning workflow. How does the mothership process an external request to create a Kafka cluster, and how is that request fulfilled by a satellite?
The short answer to this is fairly simple: an external request is transformed into a PSC, which is sent via Kafka to the destination satellite. The Operator then creates the physical cluster and its data plane based on the PSC. The interesting part is how a PSC is created from an external request. A PSC is, to put it nicely, a verbose data model. It describes complete broker configuration, zone placement, bootstrap address, etc., the majority of which is not provided in the actual API request. Abstracting away details like these is fundamental to any hosted platform. So the question then becomes: where do these values come from?
The reality is that the Control Plane Team at Confluent is separate from the team that knows how best to configure and run Kafka. The Control Plane Team needs to be able to give our Core Kafka Team a partially configured PSC and let them fill in the pieces (e.g., broker version, disk type, disk size, and other configurations). Many of these values are not static but based on ever-improving algorithms.

Now that we’ve taken a brief journey into the inner workings of Confluent Cloud, let’s see how all of this work has benefitted Kafka itself.
Our improvements to Kafka
Before we released our cloud product, the software lifecycle for the individual components that make up Confluent Platform—Kafka, ksqlDB, Schema Registry, Connect, etc.—was designed for quarterly releases and targeted on-premises enterprise installations. If a customer discovered a subtle issue that wasn’t uncovered in our robust testing, we had to wait for the customer to report the issue, then attempt to reproduce it, implement a fix, release a patch, and finally wait for the customer to upgrade. This lengthy process could take months or years to complete—and sometimes never would come to fruition if the customer felt that it was too risky to upgrade.
A slow lifecycle like this stunts the evolution and improvement of a product like Confluent Platform. In addition, even with our comprehensive test suites and awesome performance lab where we run simulated workloads on a nightly basis to automatically detect performance regressions, there are still subtle issues that we might never discover without observing specific workloads.
Confluent Cloud solves both of these limitations. We’ve quickly become a cloud-first organization: new features first appear in Confluent Cloud, where they can be tested against one of the largest Kafka installations in the world, running an extremely diverse set of workloads. If we discover an issue, we can deploy a fix in days instead of months. This also helped make one of our other products, Confluent Platform, much more resilient.
As our cloud product matured and our customers have begun to run more diverse workloads, we’ve discovered improvements that we can make to Kafka itself to make it function better in a cloud-native environment. In fact, there are so many opportunities for improvements that we created a dedicated team at Confluent just to focus on this. Let’s explore some of these improvements in depth.
TLS certificate renewals no longer require broker restarts
This is a perfect example of something that isn’t necessarily an issue until you run one of the largest Kafka installations in the world! In the past, a cluster operator might have written a script to carefully execute a zero-downtime rolling upgrade of a Kafka cluster, restarting the brokers with the new certificate. But this process can be tedious and error prone. If an issue arose, it could be catastrophic. At Confluent, we need to renew certificates for thousands of clusters, so this quickly became a problem worth solving. In the process, we eliminated potential outages, disruption in client latency, and hundreds of hours of operational work.
Multi-tenant Kafka
This has been a part of Confluent Cloud since the early days. Not only does it reduce operational scope, but it makes managed Kafka affordable no matter how small the workload. In contrast to the provisioned capacity of a dedicated cluster, multi-tenancy enables pure pay-per-use and supports bursts of up to 100 MB/s. To guard against bad actors and to enforce requirements such as throughput limits and throttling, we introduced multi-tenant quotas, resulting in a better experience for customers. Unless you are using our dedicated product, your Kafka cluster is provisioned as a logical tenant on these multi-tenant clusters.
All IPs in a DNS record are used by clients
This improvement has been merged into Apache Kafka, and more details can be found in the JIRA. This has improved fault tolerance in Confluent Cloud.
Clients re-resolve DNS when reconnecting to brokers
This is another improvement made in Apache Kafka (see the JIRA). This is very important for Confluent Cloud—we’re not only able to recycle infrastructure but can also change the underlying data plane without interruption.
Lessons learned
We’ve learned so many valuable lessons since the inception of Confluent Cloud. Many of these aren’t specific to our use case and may prove helpful to you as you make the cloud an integral part of your organization.
Think early about your API story
When you’re first bootstrapping a product such as Confluent Cloud, it’s easy to overlook best practices in API design. You can simply turn to the engineer next to you and tell them that you won’t be including this field in your data model any more. But when your product is mature and spans numerous teams, you can’t take shortcuts. Though there’s no one perfect time to begin treating your API as its own product, earlier is better than later.
Third-party software has bugs too
When you’re using software that you didn’t write, it’s easy to treat it as a black box and just assume it’s always going to work as expected. For example, Kubernetes is an amazing declarative framework, and we can’t overlook the difficulty of writing such a system ourselves. But just like any other piece of software, Kubernetes has bugs, some of which are subtle and may only be detected in edge cases. We found that the Amazon Web Services (AWS) cloud provider plugin, when updating load balancers, would delete and re-add all listeners regardless of whether they had actually changed.
If we rolled out a Confluent Operator change that mutated a Kubernetes service, the listeners for all load balancers scoped to that Kubernetes cluster would be simultaneously removed and re-added; hitting an AWS rate limit during this window could delay that process and cause an outage. The takeaway: if your project depends on third-party software, ensure that you have a plan to quickly mitigate any issues you suddenly encounter in that software.
Harden testing frameworks before onboarding engineers
When you’re building a cloud service, it quickly becomes too complex for any one person to understand in full. As the organization grows with more engineers contributing features, it becomes easier to accidentally break the system because of a lack of context. Your testing solutions should be robust enough to catch these types of issues before the development of the system becomes very broadly distributed.
Build solid abstractions
When we first released Confluent Cloud, Kafka was the only product that we offered as a managed service—we technically didn’t need the PSC abstraction that we discussed earlier in this article. We could have just called it a “Kafka cluster” and still would have been successful. But when we wanted to start offering our other products as a service, we would have had to either create an abstraction then, retrofitting “Kafka cluster” to that abstraction, or create a different way to handle each product. Our current PSC abstraction won’t last forever, but by taking time to consider future use cases up front, we’ve saved ourselves a lot of engineering effort later on.
Walk the line between automation and manual effort
No one would argue that manual processes are better than automation, but sometimes the ROI doesn’t justify the engineering work needed to automate a process, and you’re left with a runbook. We initially thought that this was the case with our VPC peering product. We didn’t expect it to be as popular as it has become, so we began with a manual provisioning process. However, we quickly learned from this and automated provisioning before it got out of hand.
The cloud isn’t free
It turns out that cloud providers want a payment method on file so that they can charge you for what you use. It also turns out that engineers don’t traditionally think much about cost in their designs. But when you reach a certain scale, even a small increase in cost can represent a very large sum of money, especially if your service is network intensive. Because of this, we found it helpful to introduce exhaustive cost modeling into our design process.
Clouds have limits
You’ve probably run into a cloud limit before. When this happens, you send an email to request a higher limit, and when your request is approved a few hours or days later, you continue your work. This process isn’t well suited to an automated workflow, so we’ve had to become smarter about increasing these limits, predicting when we’ll reach a limit and requesting an increase in advance.
Summary
Building Confluent Cloud has been an exciting journey, but it is by no means over. Stay tuned for future articles as we continue to enhance our architecture to provide you with the best serverless experience for Kafka.
You can also sign up for Confluent Cloud to get $50 of free usage per month for the first three months.
See this post in presentation form on YouTube.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.