New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Confluent for Startups: Get It Right from the Start
Great businesses are built on making the right tradeoffs, and that’s particularly true for startups. At an early stage, a startup’s choices around how and where to deploy its limited capital, people, and time can make or break a business. These considerations yield what’s come to be viewed as a pretty standard compromise for startup CTOs build quick, easy, and cost-effective to start, knowing you’ll probably need to re-architect later.
Until recently, when it comes to key data infrastructure, that notion of “quick, easy, and cost-effective” was into “batch, centralized, and in a closed ecosystem.” Startup CTOs have to choose between hiring a team of Kafka experts to build-out a DIY data streaming platform, or managing a batch solution with static data for easier operations.
Today, to remove the tradeoff and make data streaming easier for startups, we’re thrilled to announce the launch of the Confluent for Startups Program. This is more than just a credits program (though there are credits!) You’ll also be able to get off to a fast start with help from our deep bench of Kafka and data streaming expertise, and you’ll get the advice you need along the way to tackle any challenge or architectural decision.
Confluent Cloud is a fully managed data streaming platform that is as easy as batch, doesn’t take an army to implement, and can take your product to market in weeks vs. months. We’re seeing startups turn to Confluent to help them get their infrastructure right – right for today, and right for tomorrow.
“Confluent Cloud has enabled us to scale Kafka quickly and easily to keep up with the fast pace of our customer growth,” says Kevin Liu, co-founder & CEO of Metronome. “. We’ve been able to deploy new real-time use cases in weeks rather than months, while making sure that our valuable engineering time stays focused on delivering product value. With its usage-based billing, we only pay for what we’ve used, which is perfect for startups like us to run different experiments and scale anytime we need, without paying for over provisioned infrastructure.”

Confluent for Startup Program Details
If you’d like your business to become part of the program, you can apply now using this short form and jump-start your data streaming journey with us. Read on to learn more about how Confluent and our startup program can help you get up and moving.
Apply Now to Confluent for Startups
Power your startup’s infrastructure – and avoid compromises – with Confluent’s data streaming platform
One of the benefits (and curses) of founding or joining an early-stage startup is the opportunity to choose and build your tech stack from scratch. Startup CTOs have to juggle a myriad of considerations, including time, costs, talent, and how forward-looking or future-proof their initial tech stack will be. There’s an obvious tension here: startups need to be more nimble than their established competitors, but this infrastructure can make that difficult, and it’s hard to know when opportunity or competition will require you to pause to re-architect to support product development.
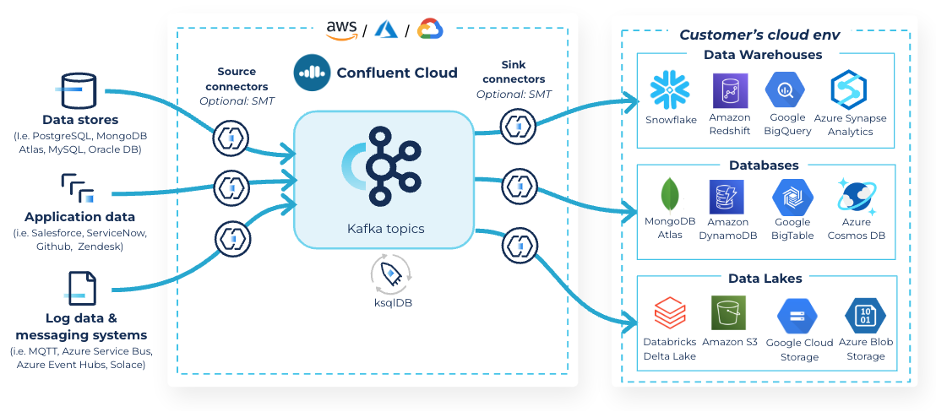
The good news is that with Confluent Cloud, these compromises and considerations can fall by the wayside. Confluent’s data streaming platform makes it quick, easy and cost-effective to turn your data platform into a data streaming platform, which gives you the advantages of real-time data, a decentralized infrastructure, and a system that can connect any source and sink. And with Confluent, that data streaming platform is built on Apache Kafka, the industry’s de facto standard for data streaming.
Let’s explore each of those advantages in more depth, and how Confluent makes it possible:
From batch to real-time
Reality isn’t static, and it’s hard to meet customer expectations when your data is living in the past with batch operations, especially for critical applications such as fraud detection, IoT analytics, personalization engine. Operating in real time enables more precision, yielding better customer experiences and smoother operations, which allows you to differentiate and stand out from the competition.
The challenge with streaming was that, historically, you needed more expertise, more infrastructure capacity, and the time to design and implement what was mostly available as a DIY (do-it-yourself) system. With Confluent Cloud, we remove the burdens of managing your data streaming platform’s infrastructure and allow you to focus on your business logic, making it quick, easy, and cost-effective to choose real-time over batch.
From a closed to an open ecosystem
As a startup, it’s hard to know what tools to use today, and almost impossible to know what tools you’ll need to use tomorrow. You want flexibility in your data infrastructure. However, opting into a closed ecosystem – a “does it all vendor” – has historically been easier because their components are built to work with each other, leading you down a specific path that’s hard to unwind.
However, with Confluent Cloud, you can opt into an open platform—both open source and agnostic to data source/sink—and that is just as easy to use and fast to deploy as the bundled offerings that might come from your CSP or warehouse/data lake provider of choice. This allows you to experiment more, find the right tools for your use cases, and do that without any need to rewind your infrastructure or build out new data pipelines.
“We use Confluent to add a layer of an improved data architecture to process real-time large-scale mission-critical data pipelines without having to worry about managing, maintaining, and installing Kafka services,” says the vice president of engineering at Ambee.. “Confluent Cloud also extends the flexibility we desire for an ever-changing business scale, demand-driven, and data-driven distribution-centric infrastructure at Ambee.”
From centralized integrations to decentralized integrations
Most (but not all!) startups begin with a limited number of data sources they pull data from and sinks they push data into. This makes it quick, easy, and cost-effective to default into building direct data pipelines that move data directly from a single source into a single sink.
However, no company, regardless of size, ever stays that simple as its use cases grow. The need to tap into new and existing sources of data alike inevitably stresses the notion of point-to-point pipelines, managed centrally. Confluent Cloud, via easy-to-use managed connectors and simple data discovery tools, helps you take advantage of a pub/sub structure that is no harder to implement or maintain, but infinitely easier to expand upon as sources, sinks, and data transformations expand alongside your business.
Get jumpstarted with our new Confluent for Startups Program
While Confluent Cloud’s product makes it just as quick, easy, and cost-effective to deploy a next-gen data streaming platform as it would be to deploy a standard batch system, our new startup program takes that even further so that you can:
- Relieve initial OpEx burden with up to $20,000 credit to experiment and deploy in Confluent Cloud for free for one year
- Start your data streaming architecture off on the right foot with a two-hour consultation with a Confluent architect expert, $500 in developer support, $2,000 worth of training credits, and weekly office hours
- Increase brand awareness and build a referral network through joint go-to-market activities with Confluent
- Gain access to an exclusive community of other Confluent for Startups program members, curated by Confluent, to help navigate you through common infrastructure and business challenges
In addition to the above, since Confluent runs in every cloud and can connect to any system, we can help you maximize credit usage across ISVs through our connector portfolio, and even across clouds through Cluster Linking’s easy replication capabilities.
We’re excited about the next generations of innovation startups are driving. Apply now and we’ll help you maximize your business’s potential on the market’s best data streaming platform.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Confluent Cloud for Government Achieves FedRAMP Moderate: Mission-Ready Data Streaming for Federal Agencies
Confluent Cloud for Government has achieved FedRAMP Moderate authorization, allowing federal, state, and local agencies to deploy secure, fully managed data streaming. By eliminating the operational burden of self-managed Kafka, the platform helps agencies break down data silos, modernize legacy...



Confluent Recognized in 2025 Gartner® Magic Quadrant™ for Data Integration Tools
Confluent is recognized in the 2025 Gartner Data Integration Tools MQ. While valued for execution, we are running a different race. Learn how we are defining the data streaming platform category with our Apache Flink® service and Tableflow to power the modern real-time enterprise.