New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Under the Hood of Real-Time Analytics with Apache Kafka and Pinot
Real-time analytics has become the need of the hour for modern internet companies. The ability to derive internal insights around business metrics, user growth and adoption as well as security incidents from all raw logs is crucial for day-to-day operations. Even more critical is enabling access to usage analytics for millions of customers, which is non-trivial to achieve. A good example of this is LinkedIn’s “Who viewed your profile,” which allows all 700 million+ users to slice and dice their page view data.
Another example is Uber’s Restaurant Manager, which enables restaurant owners across the globe to gain insights around menu preference, sales metrics, busy hours, and so on. All such user-facing analytical applications need an analytical store that can support thousands of complex queries per second at millisecond-response-time granularity while ingesting millions of events/second. Most transactional databases are unable to fulfill such stringent requirements. Enter Apache Pinot™.
Apache Pinot is a distributed analytics data store that is rapidly becoming the go-to solution for building real-time analytical applications at scale. Pinot stands out due to its ability to deliver low-latency performance for high-throughput analytical queries. The aforementioned use cases – LinkedIn’s “Who Viewed Your Profile” and Uber’s “Restaurant Manager” are a few examples of powerful analytical applications being powered by Apache Pinot in production.
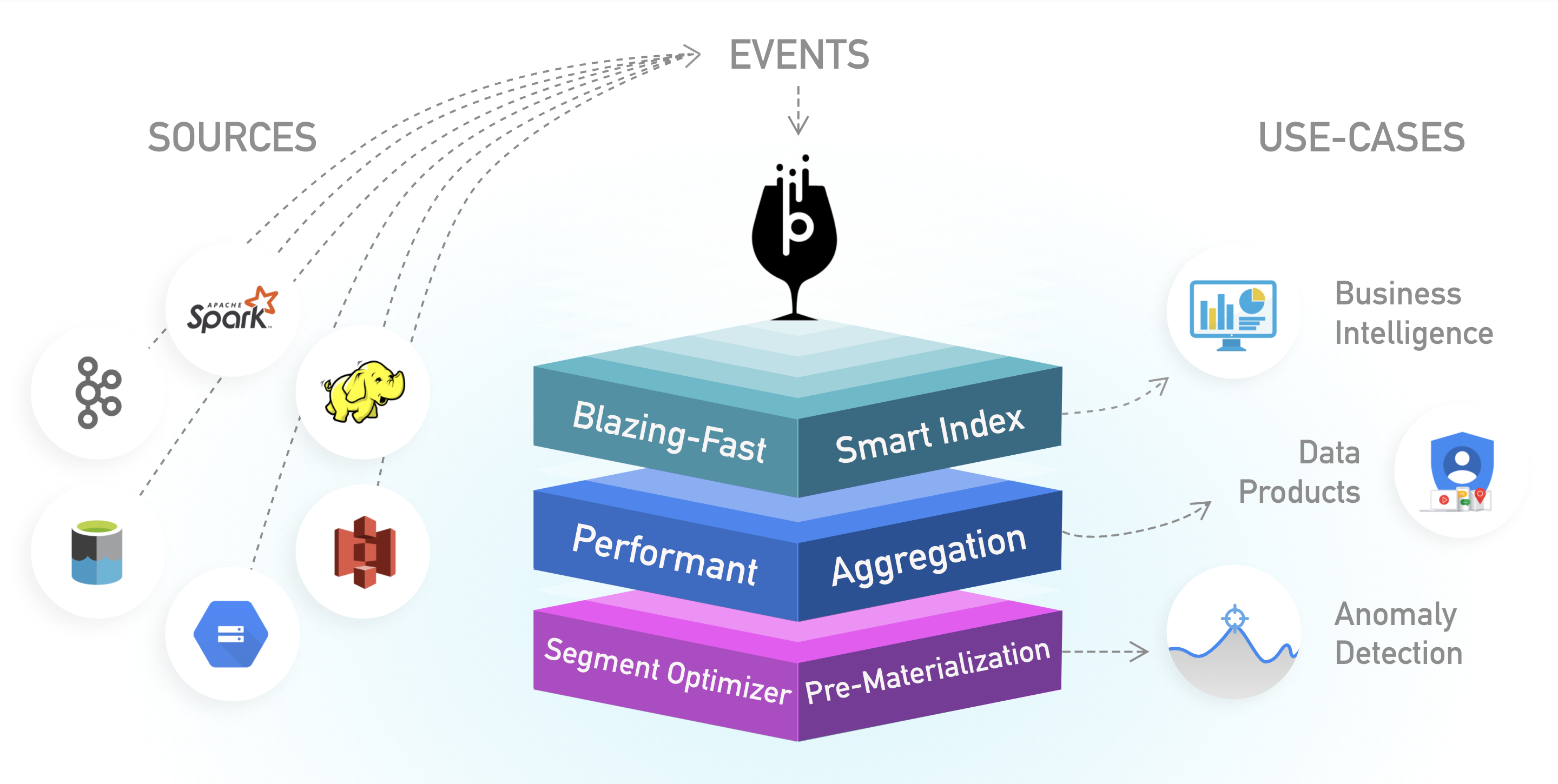
Source: Apache Pinot™ (Incubating)
As shown in the diagram above, Pinot can ingest data from a wide variety of data sources, including event streaming systems like Apache Kafka® and batch data systems like Hadoop Distributed File System (HDFS) or Amazon S3. This blog post details how Pinot integrates with Kafka to deliver fast analytics on streams of data. Fast refers to both data freshness as well as query latency. This post then elaborates on how input Kafka data is partitioned, replicated, and indexed within Pinot, and it describes how a distributed Pinot query processes all of this data. Finally, it talks about memory management of Pinot servers consuming data from Kafka and how it affects overall performance.
High-level Pinot architecture
Below is a diagram of Pinot’s distributed architecture:
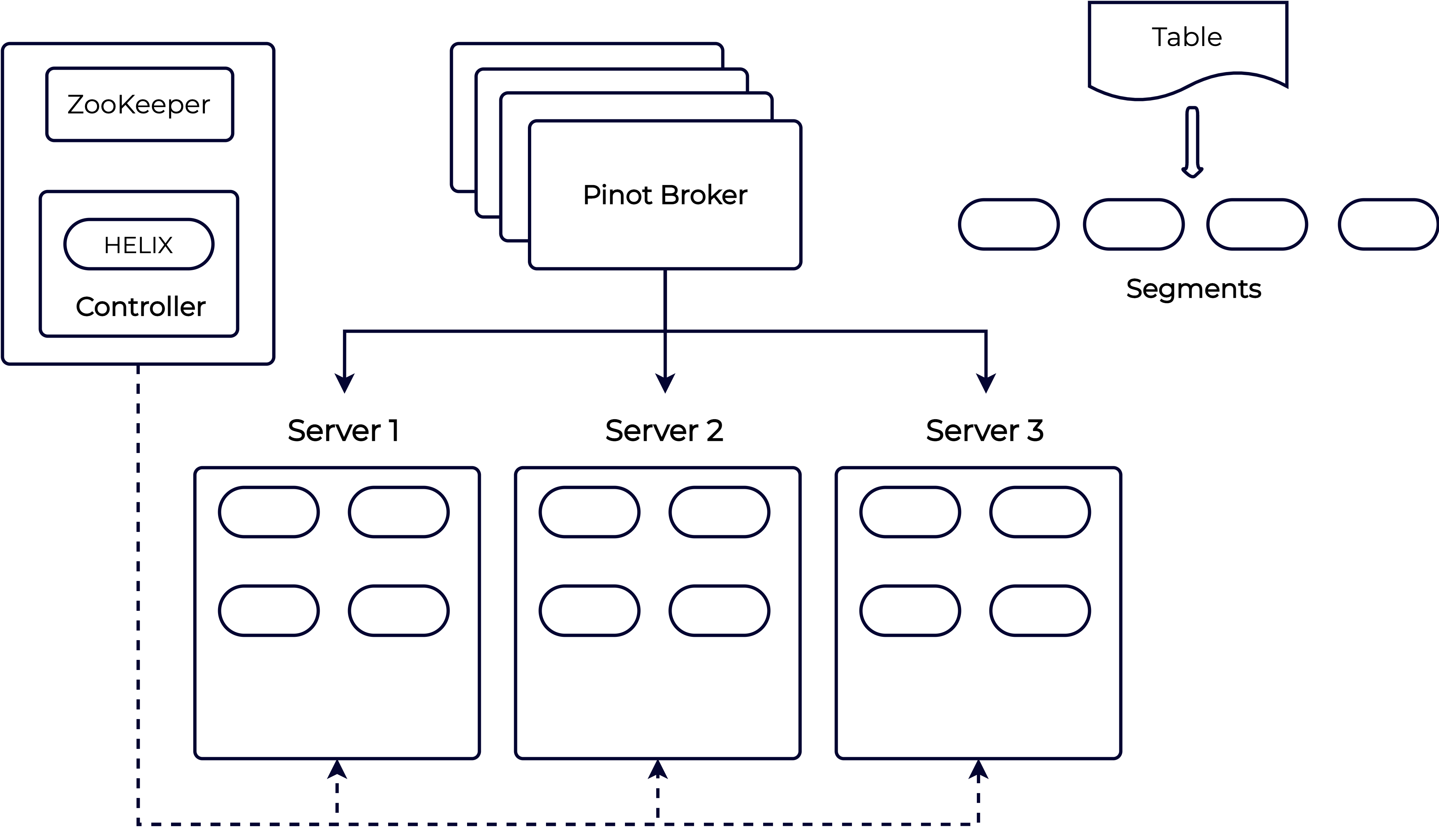
A Pinot table is composed of a set of Pinot segments that are distributed across Pinot servers. A Pinot segment is a unit of partitioning, replication, and query processing that represents a subset of the input data along with the specified indices. The Pinot controller uses Apache Helix to define how segments are assigned to different servers and how they’re replicated. The Pinot broker then uses this information to scatter queries to individual servers and gather them back together. Please refer to the Pinot documentation to learn more about the architecture.
Real-time ingestion with Kafka
This section describes how Pinot consumes data from Kafka topics and creates the corresponding data segments to make it available for real-time queries. For the purpose of this illustration, we will set up a real-time Pinot table ingesting data from a Kafka topic with four partitions in our Pinot cluster and four servers. To create such a table within Pinot, we need to specify two elements:
- Pinot schema: Specifies the dimensions and metrics columns within the Pinot table. It also designates one of the columns as the time column. This is typically derived from the original Kafka schema. Refer to the documentation for a sample Pinot schema.
- Table config: Specifies properties of this Pinot table (such as replication, retention, quotas, indexing config, and so on). The most important part of this config is the ingestion properties that define the source of data for this table. In the case of Kafka, the ingestion properties are defined as follows:
"REALTIME": {
"tableName": "pinotTable",
"tableType": "REALTIME",
"segmentsConfig": {
"schemaName": "pinotTable",
...
}
},
"tableIndexConfig": {
...
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "<topic-name>",
"stream.kafka.broker.list": "<broker-list>",
...
}
},
...
}
For more information, please refer to this stream ingestion tutorial.
Creating the schema and table config notifies the Pinot controller to start ingesting data for this table. At this point, the Pinot controller discovers the four partitions from Kafka and determines the starting offset from which to start consuming the data. This starting offset can be configured within the table config and defaults to “largest”—that is, the latest message in each partition. It then creates corresponding segment metadata in ZooKeeper for each of the four partitions and assigns the segments to the four Pinot servers. This in turn triggers the servers to start fetching data from the corresponding Kafka partition and create a local segment as shown below:
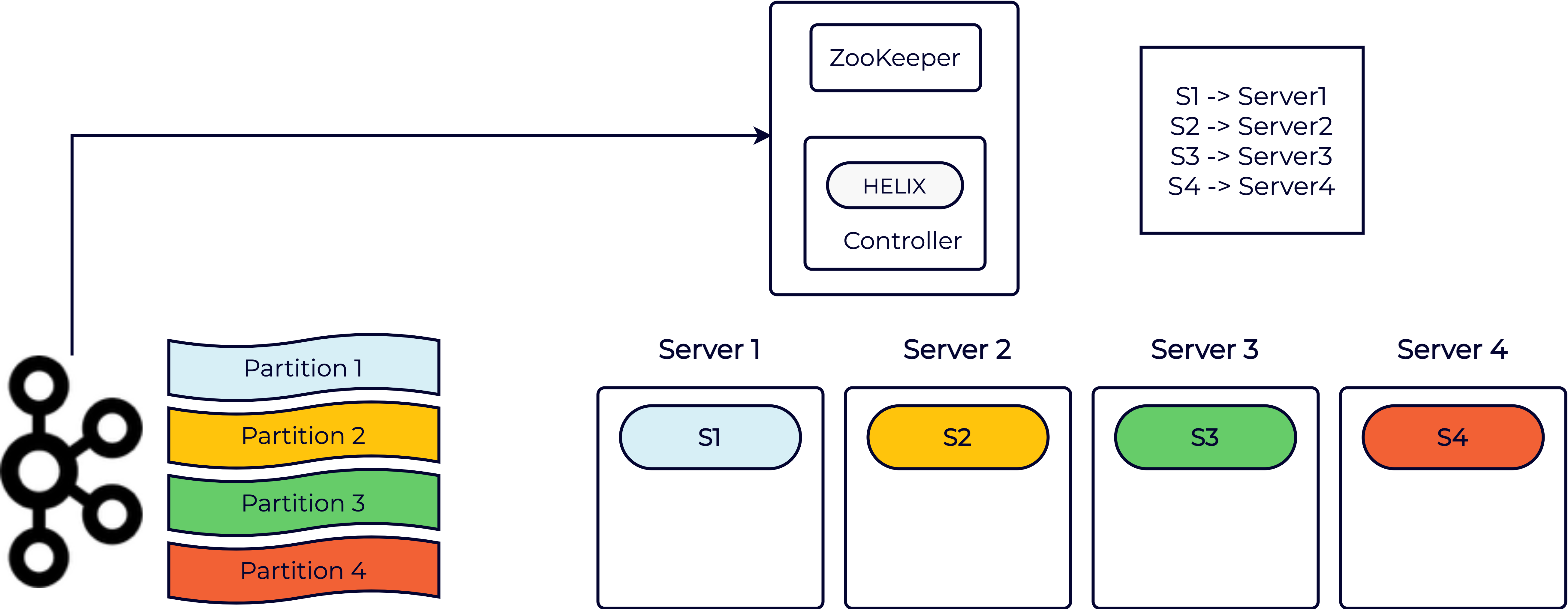
Mutable segments
The segments mentioned above are known as “mutable” segments and are stored in memory in the CONSUMING state (please refer to the Helix segment state machine for more details). Each mutable segment organizes the incoming data into a columnar format and updates the required indices in real time (for instance, inverted or text indexes). The mutable segments are available for query processing immediately as they’re being built. Thus, the data freshness of Pinot matches that of Kafka given that the ingestion overhead is very low.
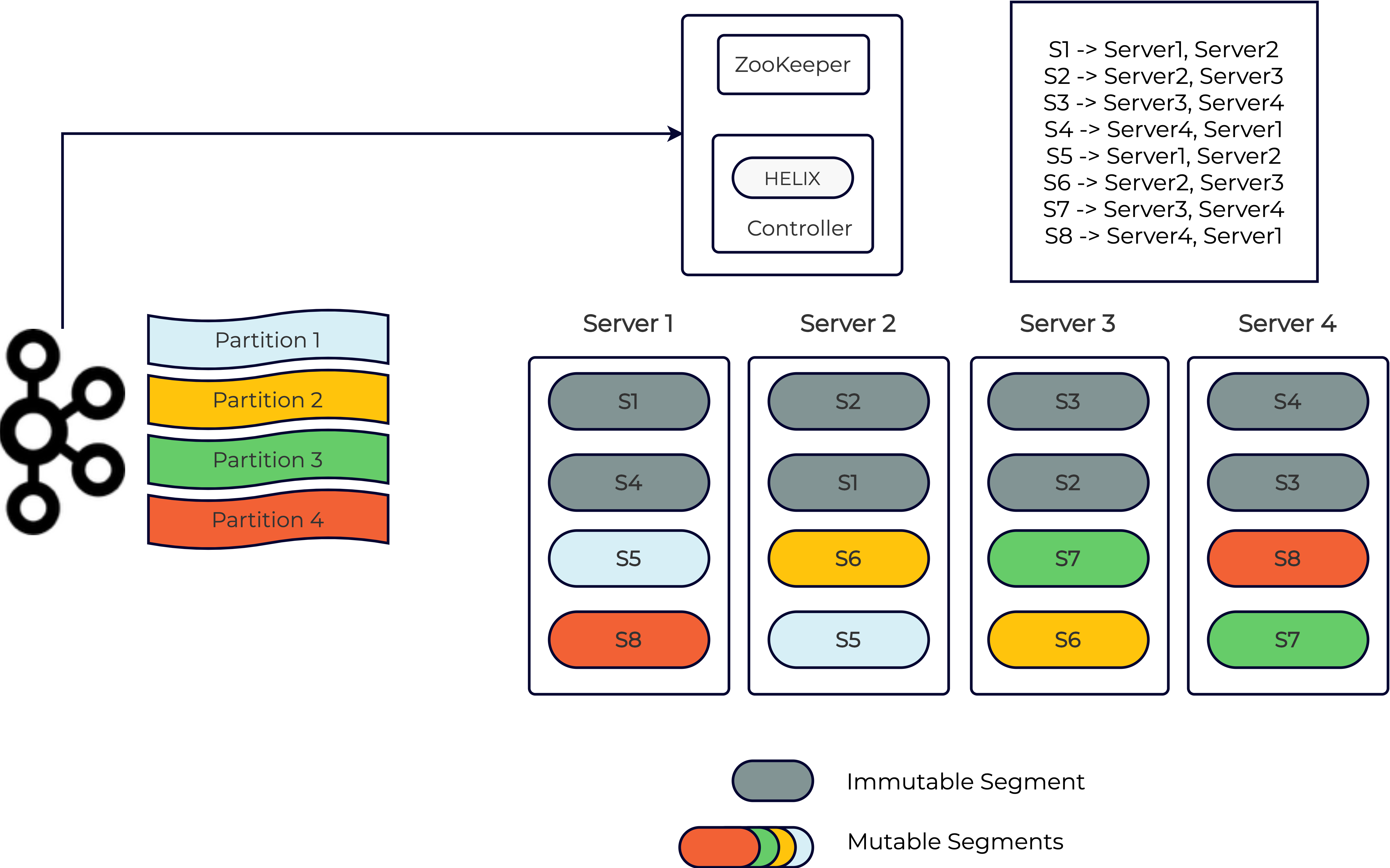
With any good distributed system, we want to ensure that the data is replicated. So let’s configure a replication factor of two for this real-time Pinot table. The Pinot controller ensures that each segment is replicated on two distinct servers. The replicas independently consume data from the corresponding Kafka partitions and create local copies of the segment as shown below:
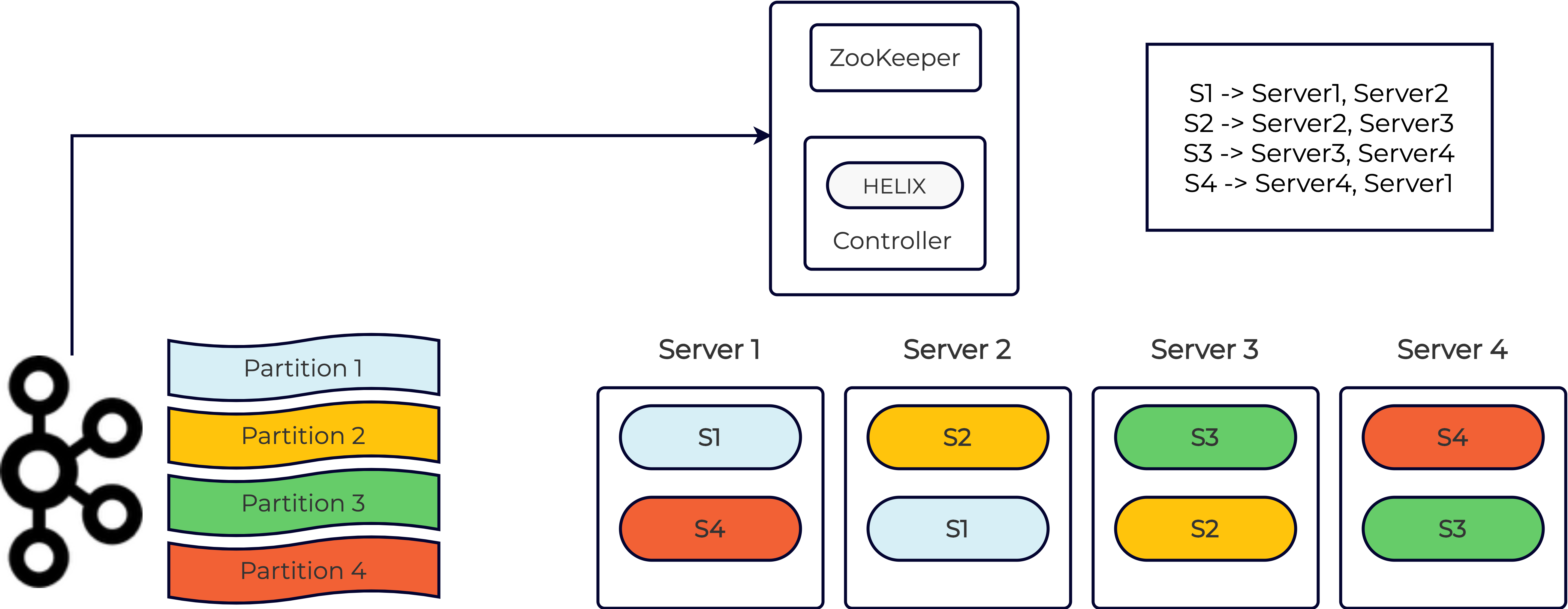
Immutable segments
At some point, the servers independently determine that it’s time to persist the corresponding in-memory segments and flush them to disk based on some criteria. Such on-disk segments are known as “immutable” segments. The criteria used for creating immutable segments can either be the amount of time elapsed since the segment was initially created or the number of rows consumed. Since different replicas may arrive at this independently (in the case of time-based completion), we need to ensure that all of them agree on the same end Kafka offset. This is done using a segment completion protocol between the replicas and the Pinot controller. The high-level idea is as follows:
- Pick one of the replicas as the pseudo leader based on some condition (for instance, the highest Kafka offset consumed so far).
- The pseudo leader then constructs an immutable segment from the mutable segment. A number of things happen at this point, including flushing all the in-memory data to on-disk structures and building specialized indices, such as a star-tree index, range index, and bloom filter.
- The pseudo leader then “commits” this immutable segment to an external store such as HDFS or Amazon S3 where it is archived for disaster recovery purposes.
- Remaining replicas can either organically catch up to the pseudo leader (in terms of the Kafka offset) or simply download the committed segment if they’re too far behind.
Needless to say, this is a complex coordination process and involves lots of edge cases that need to be handled. For more information, please refer to this design document.
For a given Kafka partition, when the current mutable (consuming) segment is fully persisted, the Pinot controller creates the next mutable segment for this Kafka partition and assigns it to some set of Pinot servers. The starting offset of this new mutable segment is one more than the ending offset of the last committed segment.
Querying a real-time Pinot table
The job of query processing is done by a stateless service known as the Pinot broker. A typical Pinot cluster has one or more such brokers deployed, and the client application can query any one of these. When the broker receives a query, it identifies which Pinot segments are needed to get the result, including both mutable and immutable segments. It then looks up the segment assignment or “routing” information via Helix and scatters the request to the corresponding servers. Each server locally executes this request, processing data from its local segments and sending the intermediate response to the broker. The broker then aggregates all the results and sends the final response back to the client.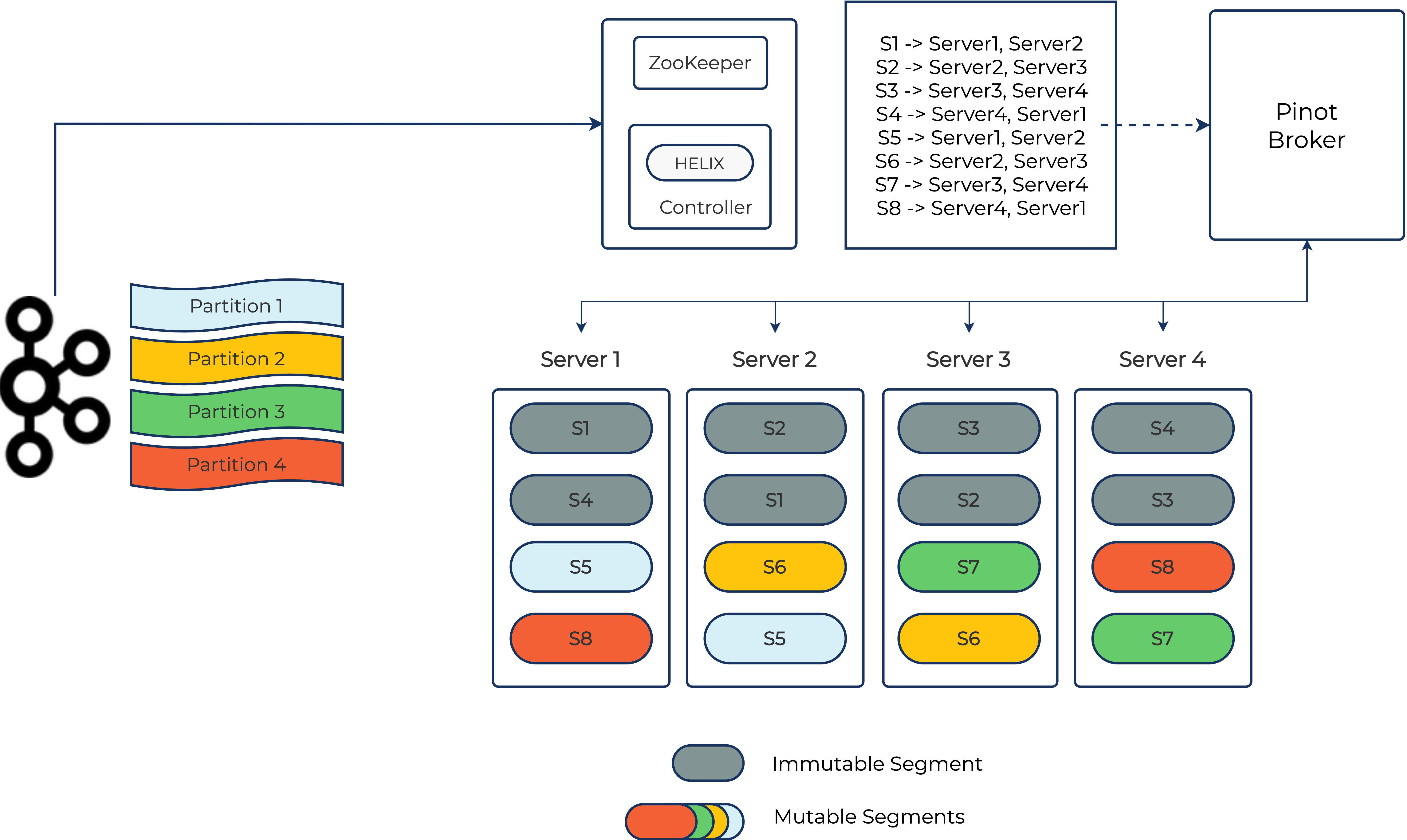
By default, the Pinot broker selects all of the available segments for processing a given query and the individual Pinot servers prune segments based on the query filter criteria. Although this works for most cases, for high data volume Pinot tables with a lot of segments, the broker might end up contacting many Pinot servers. A large query span increases the probability of hitting a slow server and hence impacts query latency. To avoid such scenarios, you can prune segments at the broker layer by pre-partitioning.
You can pre-partition your Kafka data using something like ksqlDB by applying ''PARTITION BY'' on a high-cardinality column used frequently in the WHERE clause. You can then provide a hint to Pinot that the input data is already partitioned on this column using the segmentPartitionConfig field inside the Pinot table config. The broker uses this information to narrow down the Pinot segments that need to be queried. This is illustrated in the diagram below:
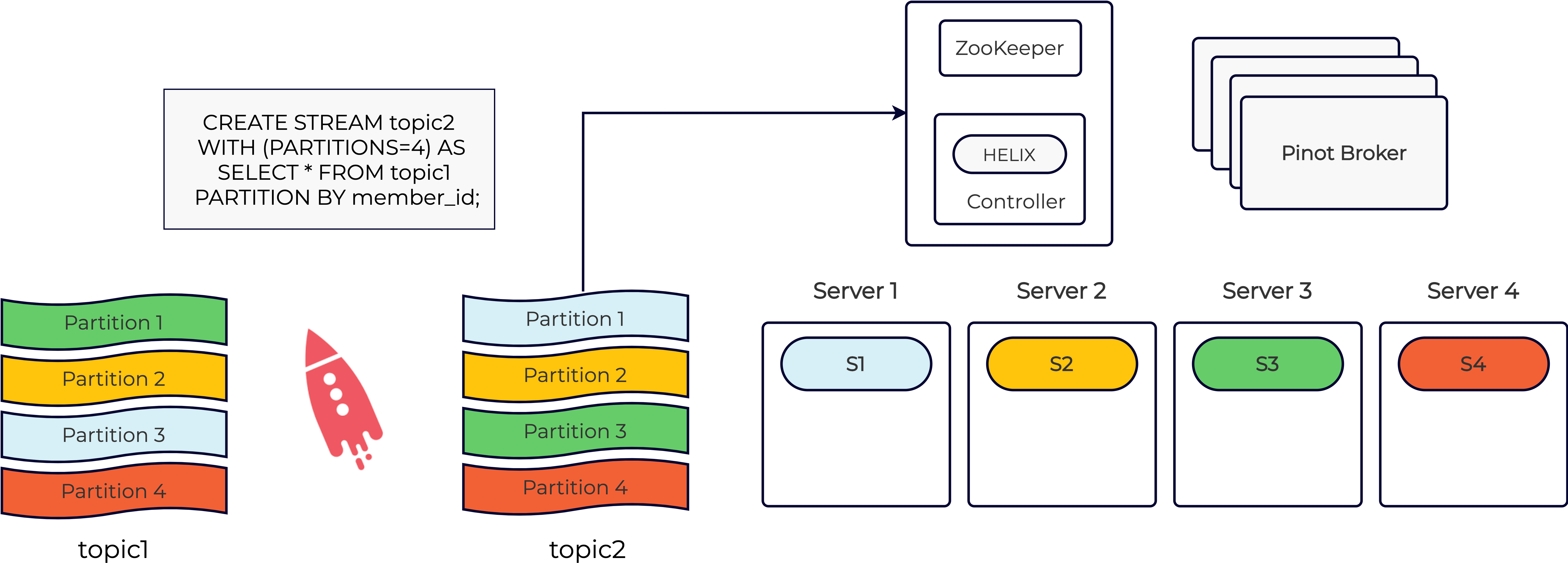
In the above diagram, data from topic1 is re-partitioned into topic2 based on the chosen column called ‘member_id’. In this case, we’ve created a Pinot table that ingests data from topic2. With this setup, let’s assume that we get a Pinot query like this:
select count(*) from pinot_table
where member_id = 123 and
<... other filter criteria ...>
Let’s also assume that all records with member_id = 123 belong to partition 1 of Kafka topic2. In this case, the Pinot broker only needs to query segment S1 and therefore results in a very low query latency. For more details on data partitioning in Pinot, please refer to the Pinot documentation.
Memory management for real-time Pinot tables
In the original design of Pinot, the mutable segment was managed entirely in heap memory. This made implementation easy in the case of data structures, such as dictionaries and forward and inverted indices. Naturally, this led to large memory consumption on Pinot hosts and increased the probability of running into garbage collection (GC) issues. To alleviate this problem, we came up with the following approaches:
- Off-heap memory: Most of the data structures utilized by the mutable segment can now use off-heap memory (except for the inverted index). This drastically reduces the memory pressure on consuming hosts and improves the stability of real-time Pinot tables.
- Migrate immutable segments: Even with off-heap allocation, mutable segments still end up using more resident memory than immutable segments. Pinot allows you to move immutable segments to different hosts than the hosts consuming data from Kafka. This enables accurate provisioning of resources on these hosts and thus reduces the overall cost of the cluster.
To learn more about the memory management and performance tuning of Pinot’s real-time tables, please refer to this document.
Conclusion
This blog post shared the internal workings of Pinot’s real-time data ingestion from Kafka. As described above, Pinot leverages Kafka to ensure minimal coordination between its replicas. The two different segment formats enable data to be queried immediately yet at the same time have compact, efficient, on-disk representation. We also discussed advances in off-heap memory management within Pinot’s mutable segment, which makes the real-time tables resource efficient and increases the stability of the cluster.
Learn more about Pinot and Kafka
If you’re interested in learning more about Pinot, we invite you to become a member of our open source community by joining our Slack community, following us on Twitter, and subscribing to our mailing list.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





