New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Predicting Flight Arrivals with the Apache Kafka Streams API
Kafka Streams makes it easy to write scalable, fault-tolerant, and real-time production apps and microservices. This post builds upon a previous post that covered scalable machine learning with Apache Kafka, to demonstrate the power of using Kafka’s Streams API along with a machine learning application.
Kafka Streams will be used to predict whether an airline flight will arrive on-time or late. While this type of prediction is common in machine learning, this post presents a way to do this by leveraging the Kafka Streams API.
This post is not about choosing the appropriate machine learning algorithm or building the perfect machine learning model, but rather it is about how you can do online training and updating by applying machine learning models with Kafka’s Streams API.
At a high level, this application will have one “stream processing” topology that consumes simulated data from flights that are about to take off, and this data will be used to predict whether the flight will arrive on time for a given airport. Simultaneously, there will be another topology that consumes historical data and makes updates to the model in real-time as the application runs.
In summary, the online model will be updated in real-time after enough data has been collected. This will continually improve predictions based on the updated data.
The following image shows the type of results we can expect from a previous run of the online-prediction application:
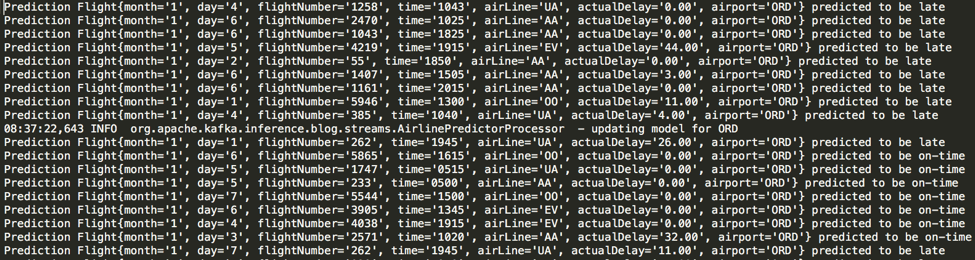
Online Prediction Results – notice predictions are better after model update
In the previous image, you can see that the success rate of the “actualDelay” field compared to the forecast is not good. But after the model is updated (while the streaming application is running!), the prediction rate jumps from 50% to 100%. For this application, you can expect anywhere from 80% to 90% improvement after the model updates for any given airport. This real-time approach represents a departure from how most machine learning applications are currently operating, where the model is built and updated offline.
You can do this all with a minimal amount of code, as you’ll see in later sections. But first, let’s discuss the Kafka Streams features that enable this approach.
KTables and GlobalKTables
Kafka Streams introduced a several new abstractions, including KTable and GlobalKTable classes. You’ll remember from Tables and Streams are Dual that streams can always be transformed into tables, and tables into streams. The KTable is a collection of keyed facts that are continuously updated, but also behind the scenes there is a changelog stream that tracks of the updates backing the KTable. This abstraction allows you to perform joins and aggregations on the streaming data.
The KTable handles frequently changing data and keyed facts that can be partitioned based on the keys, the GlobalKTable handles data that is static and small enough to fit entirely in memory. GlobalKTables aren’t partitioned, so each stream task is guaranteed to have a full copy of all data regardless of the key of the incoming record.
With this structure, the GlobalKTable opens up possibilities for enriching or even transforming the records that you have in your event stream.These are the key features of Kafka Streams and a GlobalKTable that are the main point of this blog post. GlobalKTables are used to hold the coefficients of a machine learning model. A KStream of records are joined against the GlobalKTable to predict the outcome of a particular event, based on the application of coefficients to the data in the records.
You can do this with any Java application that leverages the Streams API, and thanks to the Streams API this application will be elastic, highly scalable, and distributed; and it can be run on containers, VMs, bare-metal, on-premise, or in the cloud. Notably, you don’t need to install and operate a separate Big Data processing cluster that contains another processing framework to make the predictions. This greatly simplifies your architecture and allows you to seamlessly integrate this application into existing processes and workflows for software development, testing, deployment, monitoring, and operations.
Predicting On Time or Late Flight Arrivals
You’re going to simulate a stream of flight events by feeding flight data into a Kafka topic that serves as a source of a KStream keyed by the airport code for the origin airport. You’ll then join your KStream against a GlobalKTable keyed by airport codes, and the values are the model generated using Logistic Regression.
Logistic regression is used because the predictions only have two possible outcomes, on-time or late. A flight is considered late if its arrival time is 1 minute beyond the scheduled arrival time.
Additionally, behind the scenes, another stream of flight data will be processed with the Processor API. After enough information is collected, the model will be retrained and then a new record is published for each airport code as its key and the new online regression model (serialized to a byte array) as an update to the prediction model. These updates are applied to the same Kafka topic that feeds the GlobalKTable. In summary, the online model is updated in real time after enough data is collected. The result is continuously improved predictions based on updated data.
A Stream Processing Approach to Machine Learning
Traditional models for machine learning are built offline, then provided to the clusters utilizing the machine learning algorithms. New data is collected offline for a specified period, then at some point a new model is generated and delivered to the machine learning cluster. Mostly this still a batch mode approach to machine learning applications.
Kafka Streams provides a real-time approach to machine learning. The model is regenerated once up front, but after that point the data is continuously collected and new models are published as you go, taking a stream processing approach to machine learning. The next section discusses how to set up your application.
The Data
To build this application, you will use flight data collected from the FAA (Federal Aviation Administration). The data is restricted to the 15 busiest airports in the United States, as determined by counting the total number of flights by the originating airport in the downloaded data files.
You are going to initially use features such as the originating airport and the time of day the flight is scheduled to leave.
Data from 2014 is downloaded (chosen at random) for the initial training set. The data is grouped by airport code and then a model is built for each airport. Because an entire year’s worth of data for the airports is quite large, this post uses only a percentage for building the initial model.
Building the Model
Now it’s essential to state at this point; this blog post is not about choosing the best machine learning algorithm or proper model building, but rather it demonstrates how you can take an initial model and store it in a GlobalKTable. As more data is collected, you will see how you can train and update the model live, in a streaming manner, to improve prediction results by leveraging new training data that is collected in real-time.
The Apache Mahout OnlineLogisticRegression class is used to perform logistic regression as a library both for training the initial model and for the subsequent updates as you collect more data. An OnlineRegression object is generated for each airport in our data, and then the results are published to a Kafka topic with the key of the airport code and a serialized OnlineRegression object for the value. This object is the newly generated model for the respective airport, which we’ll use for the online prediction.
The key point is that you can update your models in a streaming way so that you can continuously update or refine your model without having to wait for a batch training job to finish completion. As soon as you have enough data for any given airport, you’ll refresh the model for that airport in real-time.
The application involves two steps:
- Apply the model online to make predictions.
- Collect data and train a new model online
The next section describes how we can use Kafka’s Streams API and its GlobalKTables to enable predictions and to update the model in a streaming manner.
Performing the On-Line Predictions
This section describes how to apply the model online to make predictions.
The KStream abstraction from Kafka’s Streams API is used for the prediction portion of the application. The approach is to read from a Kafka topic supplied with a simulated live stream of pending flights. The flight data is read into this KStream and joined against the GlobalKTable that contains the serialized OnlineRegression by airport code.
While this may sound complicated, you only need the following lines of code to implement the online prediction step:
That’s all it takes! Now let’s walk through the code in more detail.
Line 2 sets up the KStream instance that consists of flight data keyed by the airport code.
Line 4 creates our GlobalKTable that contains trained models keyed by airport code.
Line 8 sets up to join the GlobalKTable. Because you’ve keyed the incoming stream by airport code (so that the join operation can match the data in the stream with the data in the global table based on the airport code), you supply a simple “key identity” function for the KeyValueJoiner, in this case, a Java 8 lambda function. The final part of the join method is the ValueJoiner, which in this case creates a new instance of a DataRegression object, which acts as a container for the flight data from the incoming KStream and the OnlineRegression object from the GlobalKtable.
In the next step, the flight data and the OnlineRegression is used to predict whether the flight will arrive on time. The prediction is wrapped in a mapValues operation:
Line 4 provides a lambda expression Predictor::predict for the ValueMapper. The Predictor#predict method accepts an instance of a DataRegression object and returns a String that contains the original flight data and the results of the prediction (on time or not).
Although the point of this blog is not the actual machine learning, it is helpful to see how you can predict from within the application. To get a better understanding of how the application works, here is a look at the Predictor#predict method:
Line 2 creates an empty (no coefficients) OnlineLogisticRegression object. Line 4 adds the coefficients from the byte array resulting from the join with the GlobalKTable. Line 5 makes the actual prediction and converts the result to a string on the next line. The return statement uses another custom class, Flight, to format the flight data to make it easier to read. Line 4 logs exceptions, and then returns null.
Here is the completed code example.
A filter (in line 3) is used to remove any null values from our stream as a result of an exception coming from the prediction (as described in the previous section). Finally, the results are printed to the console (in line 4) and the results are written to a topic in line 5.
The next section describes how to update the model in a streaming application.
Retraining a Model
This final section describes how to update the model in a streaming manner. In practice, you would run the data stream update in a separate application, but for demonstration purposes, the two procedures are combined. For this portion of the application, a the “lower level” part of Kafka’s Streams API is used, the Processor API.
The approach is to create a state store to hold flight data as it arrives, keyed by airport code. You’ll have a processor schedule a punctuate call, and check whether enough records are collected to update the model. If you have collected enough data, you will instantiate a new OnlineLogisticRegression object, train a new model, and publish the results to the topic that backs the GlobalKTable.
For clarity, the building of the Processor API sub-topology is skipped and the action in the AirlinePredictorProcessor#punctuate method is described, since this where the heart of updating the model is. To see all of the details, see the full example code.
Note: This blog and application uses the latest stable version of Kafka 0.11.0, and thus uses the older Processor#punctuate method which has has been deprecated. You should use its successor Punctuator#punctuate when Kafka 1.0 is released in October.
Here’s a look at the code used to update the model:
In the punctuate method, you’re iterating over the contents of the state store, and checking whether you’ve accumulated enough data to do an update to the coefficients of the model. The number 100 (line 10) is arbitrarily selected, with the intent of observing the updates to the model in the GlobalKTable in a timely manner. Line 12 makes a call to a custom class ModelBuilder which trains a new OnlineLogisticRegression object that contains new coefficients and returns the serialized coefficients from the training process.
With the updated training and serialized coefficients completed, all that is left is to push the updated model to the topic backing our GlobalKTable, which is done in line 13. Now incoming flight data will start making predictions/inferences with the latest available model.
Run the Application!
This post has described how the online inferencing application is built, but to see the impact you need to run the application.
At a high level, you will run three executables. The first one will train our initial model and populate the GlobalKTable. This step needs to be run only once—it will not be continuously running like steps 2 and 3. The second executable runs the Kafka Streaming application making the predictions. The third executable writes to a topic that the “updating” portion of the application uses to retrain the model and publish updates to the GlobalKTable. This approach is neatly decoupling and separating responsibilities, and very amenable to running in a microservices fashion.
For full instructions on how to run the application, see the GitHub repository.
Initially, you’ll see rather poor predictions ~50%, similar to a coin flip. But as you collect more data, including better features, you build a new model and publish it to the GlobalKTable for making future predictions. As you watch the results on the screen, after an update for a given airport is printed on the console, you’ll start to see better prediction rates, between 80-90%, as a result of building a better model.
Using Kafka Streams provides the ability to update the model and coefficients in real-time in an application. There is no longer a requirement to have a separate, slow batch training job that requires reloading—instead, you can live-update the model as you go.
Conclusion
This post has demonstrated how we can leverage the power of the Kafka Streams API and its GlobalKTables component to both train and apply machine learning models in an online, streaming manner, where before we would need to train the models in a batch-oriented way. With Apache Kafka you can implement real-time machine learning use cases end-to-end.
About Apache Kafka’s Streams API
If you have enjoyed this article, you can learn more about the Apache Kafka Streams API with the following resources:
- Get started with the Kafka Streams API to build your real-time applications and microservices.
- Walk through the Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications





