New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Oracle CDC Source Premium Connector is Now Generally Available
One of the most common relational database systems that connects to Apache Kafka® is Oracle, which often holds highly critical enterprise transaction workloads. While Oracle Database (DB) excels at many things, organizations often find that they want to use the data that it stores elsewhere, such as their analytics platform or for driving real-time applications. Change data capture (CDC) solves this challenge by efficiently identifying and capturing data that has been added to, updated, or removed from tables in Oracle. It then makes this change data available to the rest of the organization.
There has been an increasing demand for a CDC solution for Oracle Database. We’ve interviewed various enterprise customers who run businesses on Oracle databases across multiple industries, including financial services, retail, higher education, and telecommunications. Many of these customers have tried other solutions, but they often present challenges, such as the following:
- Introducing redundant components when downstream applications or services are not covered by out-of-the-box integrations
- Prohibitive licensing costs of capturing high-value Oracle DB change events
In addition, anyone who has built an in-house solution 5–10 years ago eventually realizes that updating, supporting, and maintaining the in-house solution results in costly technical debt.
Today, we are excited to announce the release and general availability (GA) of Confluent’s Oracle CDC Source Connector. This connector allows you to reliably and cost-effectively implement continuous real-time syncs by offloading data from Oracle Database to Confluent. By leveraging Confluent’s Oracle CDC Source Connector alongside other Confluent components like ksqlDB and sink connectors for modern data systems, enterprises can enable key use cases like data synchronization, real-time analytics, and data warehouse modernization that power new and improved Customer 360, fraud detection, machine learning, and more.
Here are just a few of the benefits introduced by the Oracle CDC Connector, as shared by our customers:
- “We can potentially save a few million dollars by using Confluent’s connector instead of a solution we use today.”
-Chief Architect of a Higher-Education Institution - “Because of its licensing model, if we go out of the current license model for a third-party solution, we need to take a second mortgage to pay for an additional license. It won’t be the case with Confluent’s connector.”
-A Large Retailer - “We can simplify our current data pipeline with the Oracle CDC Source Connector, removing redundant components and services .”
-A Large Airline in Latin America
Oracle version compatibility
Confluent’s connector for Oracle CDC Source v1.0.0 uses Oracle LogMiner to read the database’s redo log. It also requires supplemental logging with ALL columns either for tables that you are interested in or for the entire database. The connector supports Oracle Database 11g, 12c, 18c, and 19c, and either starts with a snapshot of the tables or starts reading the logs from a specific Oracle system change number (SCN) or timestamp.
Confluent’s Oracle CDC Connector in action
Let’s now look at how you can create a CDC pipeline between Oracle Database and BigQuery with Confluent’s self-managed connector for the Oracle CDC Source and fully managed BigQuery Sink Connector. While this demo focuses on writing the data to BigQuery, you can use the Oracle CDC Source Connector to write to other destinations like Snowflake, MongoDB Atlas, and Amazon Redshift.
Demo scenario
Your company—we’ll call it Blue Mariposa—is a big Oracle shop and runs lots of Oracle databases to store almost everything related to the business. You’re a data engineer on the newly minted Data Science team charged with helping to improve topline revenue by building an internal application to surface upsell opportunities to account teams. The Data Science team wants to harness existing customer data and apply the latest machine learning technologies and predictive analytics to enrich historical customer data with real-time context from the application. However, there are three challenges:
- Your DBAs likely don’t want the Data Science team to directly and frequently query the tables in the Oracle databases due to the increased load on the database servers and the potential to interfere with existing transactional activity
- The Data Science team doesn’t like the transactional schema anyway and really just wants to write queries against BigQuery
- If your team makes a static copy of the data, you need to keep that copy up to date in near real time
Confluent’s Oracle CDC Source Connector can continuously monitor the original database and create an event stream in the cloud with a full snapshot of all of the original data and all of the subsequent changes to data in the database, as they occur and in the same order. The BigQuery Sink Connector can continuously consume that event stream and apply those same changes to the BigQuery data warehouse.
Set up Kafka Connect
You can run the connector with a Kafka Connect cluster that connects to a self-managed Kafka cluster, or you can run it with Confluent Cloud.
| ℹ️ | If you’d like to get started with Confluent Cloud, sign up and you’ll receive $400 to spend within Confluent Cloud during your first 60 days. In addition, you can use the promo code CL60BLOG for an additional $60 of free Confluent Cloud usage.* |
For our example, we’re using Confluent Cloud. The first step is to create a configuration for your Connect workers that tells Connect to use Confluent Cloud. Confluent Cloud can create a proper worker configuration for you. All you need to do is go to Tools & client config > Kafka Connect in Confluent Cloud.
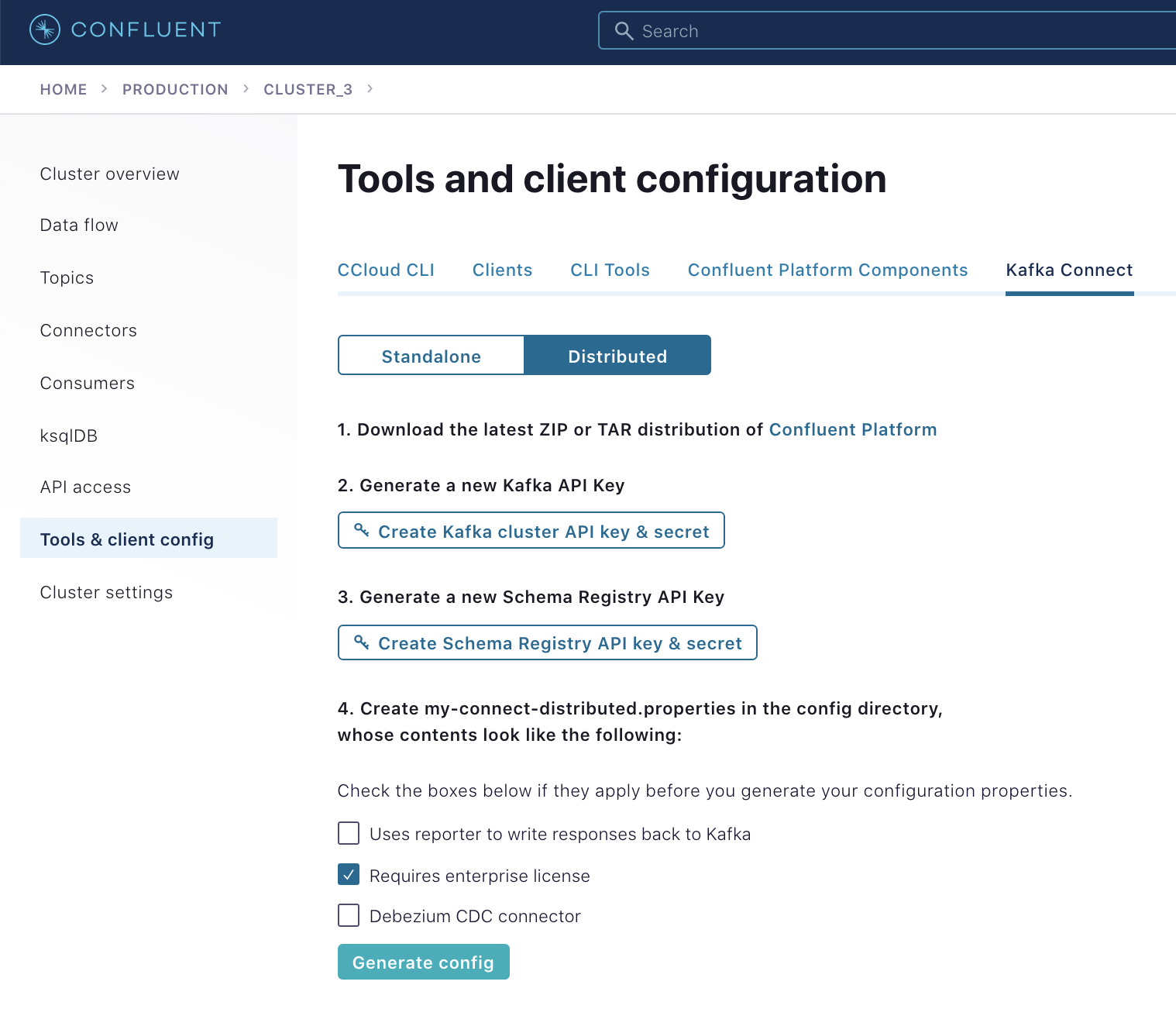
In the Kafka Connect worker configuration, be sure that the plugin.path has a path in which you’ve installed Confluent’s Oracle CDC Source Connector, and topic.creation.enable is set to true so that Connect can create the topics where the source connector will write its change events.
Once the Connect worker config is ready, you can start the connector worker with the following command:
./bin/connect-distributed ./etc/my-connect-distributed.properties
Configure Oracle for CDC
Our Oracle database is Amazon Relational Database Service (Amazon RDS) for Oracle 12c, and the DBAs can follow the documented steps to make the Oracle Database ready for CDC.
Create the connector configuration
Then create a configuration for the connector:
{
"name": "OracleCDC_Mariposa",
"config":{
"connector.class": "io.confluent.connect.oracle.cdc.OracleCdcSourceConnector",
"name": "OracleCDC_Mariposa",
"tasks.max":3,
"oracle.server": "",
"oracle.port": 1521,
"oracle.sid":"ORCL",
"oracle.username": "",
"oracle.password": "",
"start.from":"snapshot",
"redo.log.topic.name": "oracle-redo-log-topic",
"redo.log.consumer.bootstrap.servers":"",
"redo.log.consumer.sasl.jaas.config":"org.apache.kafka.common.security.plain.PlainLoginModule required username=\"\" password=\"\";",
"redo.log.consumer.security.protocol":"SASL_SSL",
"redo.log.consumer.sasl.mechanism":"PLAIN",
"table.inclusion.regex":"ORCL.ADMIN.MARIPOSA.*",
"table.topic.name.template": "${databaseName}.${schemaName}.${tableName}",
"lob.topic.name.template":"${databaseName}.${schemaName}.${tableName}.${columnName}",
"connection.pool.max.size": 20,
"confluent.topic.replication.factor":3,
"redo.log.row.fetch.size": 1,
"numeric.mapping":"best_fit",
"topic.creation.groups":"redo",
"topic.creation.redo.include":"oracle-redo-log-topic",
"topic.creation.redo.replication.factor":3,
"topic.creation.redo.partitions":1,
"topic.creation.redo.cleanup.policy":"delete",
"topic.creation.redo.retention.ms":1209600000,
"topic.creation.default.replication.factor":3,
"topic.creation.default.partitions":5,
"topic.creation.default.cleanup.policy":"compact",
"confluent.topic.bootstrap.servers":"",
"confluent.topic.sasl.jaas.config":"org.apache.kafka.common.security.plain.PlainLoginModule required username=\"\" password=\"\";",
"confluent.topic.security.protocol":"SASL_SSL",
"confluent.topic.sasl.mechanism":"PLAIN",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"io.confluent.connect.avro.AvroConverter",
"value.converter.basic.auth.credentials.source":"USER_INFO",
"value.converter.schema.registry.basic.auth.user.info":":",
"value.converter.schema.registry.url":""
}
}
There are a few config parameters to highlight:
- table.inclusion.regex identifies the regular expression that identifies tables that this connector will capture
- table.topic.name.template specifies the rule for the names of the topics to which the events are written
- Since we have a few tables, including a CLOB data type, we also use lob.topic.name.template to specify the names of the topics where LOB values are written
- We also have a few columns with NUMERIC data types in Oracle Database, and with "numeric.mapping":"best_fit"; the connector will store them as an integer, a float, or a double in Kafka topics rather than as arbitrarily high precision numbers
The last group of configuration parameters uses the functionality added in Apache Kafka 2.6 to define how Connect creates topics to which the source connector writes. The following parameters create a redo log topic called oracle-redo-log-topic with one partition and create other topics (used for table-specific change events) with five partitions.
"topic.creation.groups":"redo", "topic.creation.redo.include":"oracle-redo-log-topic", "topic.creation.redo.replication.factor":3, "topic.creation.redo.partitions":1, "topic.creation.redo.cleanup.policy":"delete", "topic.creation.redo.retention.ms":1209600000, "topic.creation.default.replication.factor":3, "topic.creation.default.partitions":5, "topic.creation.default.cleanup.policy":"compact",
When the connector is running, it logs that it cannot find a redo log topic if there are no changes (INSERT, UPDATE, or DELETE) in the database five minutes after it completes a snapshot. To prevent this from happening, you can increase redo.log.startup.polling.limit.ms, or you can create a redo log topic before running the connector.
ccloud kafka topic create oracle-redo-log-topic --partitions 1 --config cleanup.policy=delete --config retention.ms=120960000
Now you can create the connector by submitting the configuration to your Kafka Connect worker, assuming that you’ve written the above JSON configuration to a file called oracle-cdc-confluent-cloud.json:
curl -s -H "Content-Type: application/json" \ -X POST \ -d @oracle-cdc-confluent-cloud.json \ http://localhost:8083/connectors/
Once you’ve created the connector, make sure that it’s running:
curl -s "http://localhost:8083/connectors/OracleCDC_Mariposa/status"
You should get output that looks like this:
{"name":"OracleCDC_Mariposa","connector":{"state":"RUNNING","worker_id":"kafka-connect:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"kafka-connect:8083"}],"type":"source"}
| ℹ️ | If you don’t see RUNNING under both the connector and tasks elements, then you’ll need to inspect the stack trace using the REST API or from the Kafka Connect worker log. |
Once the connector is running, you can check Kafka topics to see whether records are coming from Oracle Database. Blue Mariposa has a table called MARIPOSA_ORDERDETAILS that stores 1,000 order records.
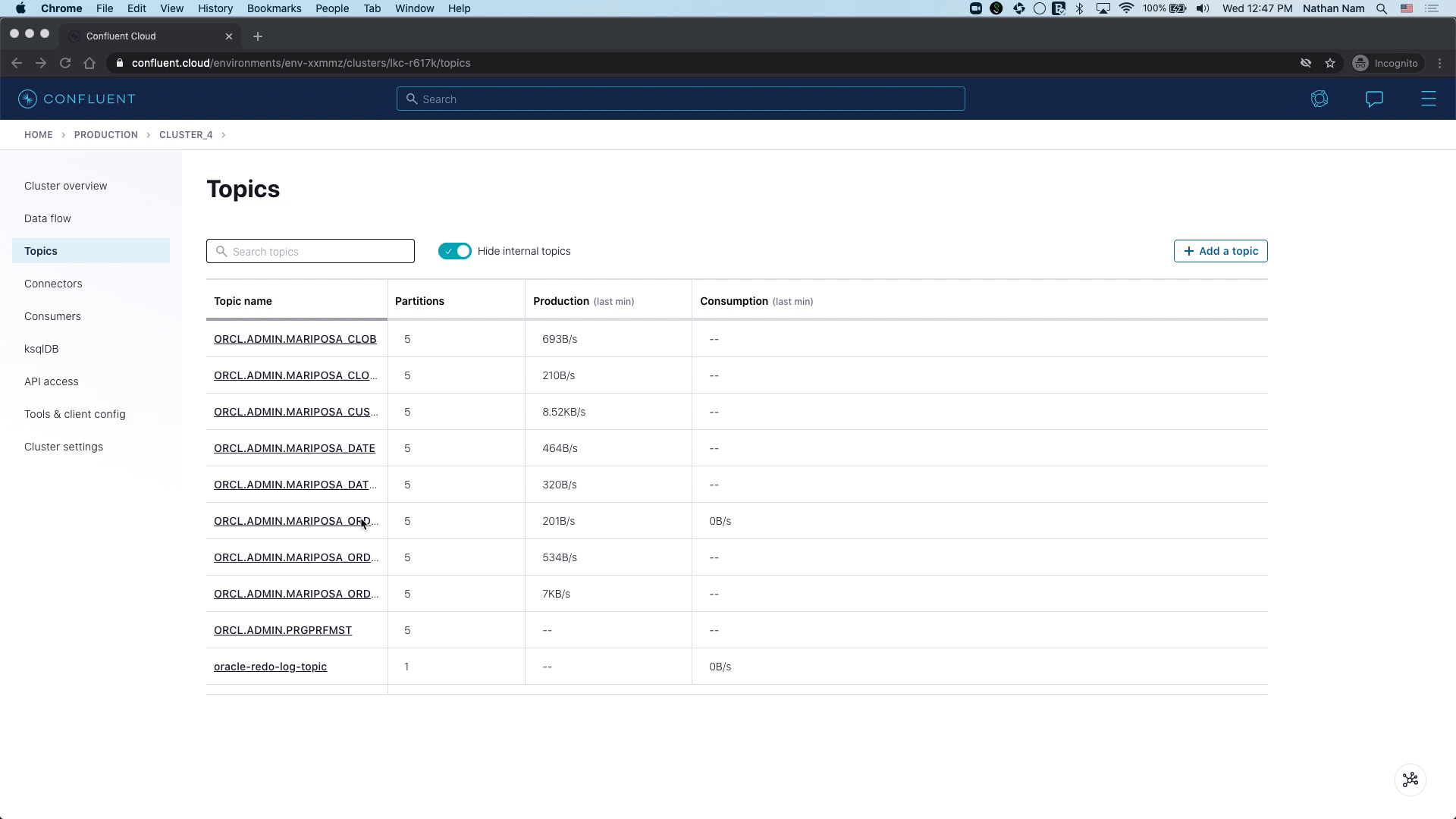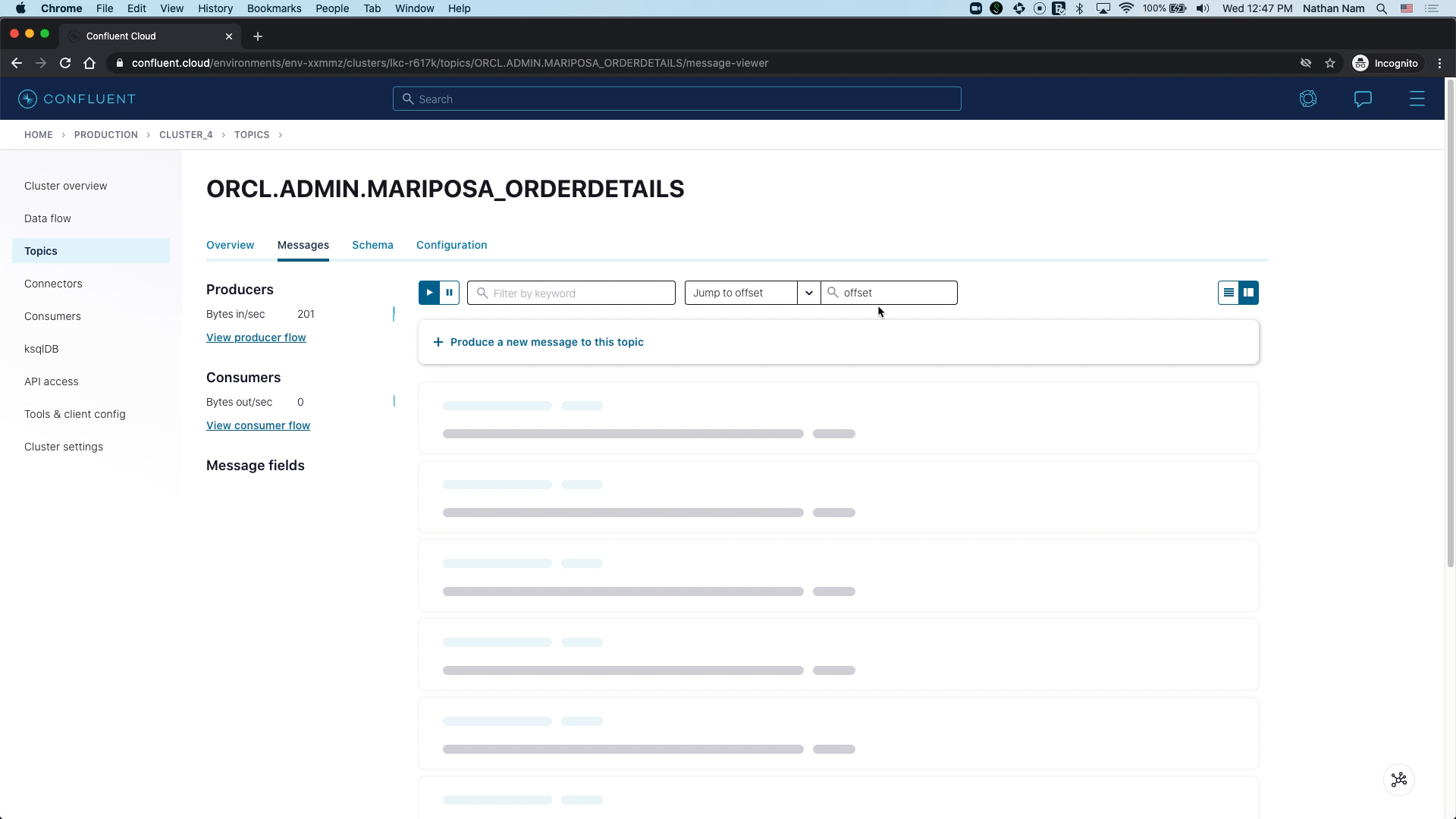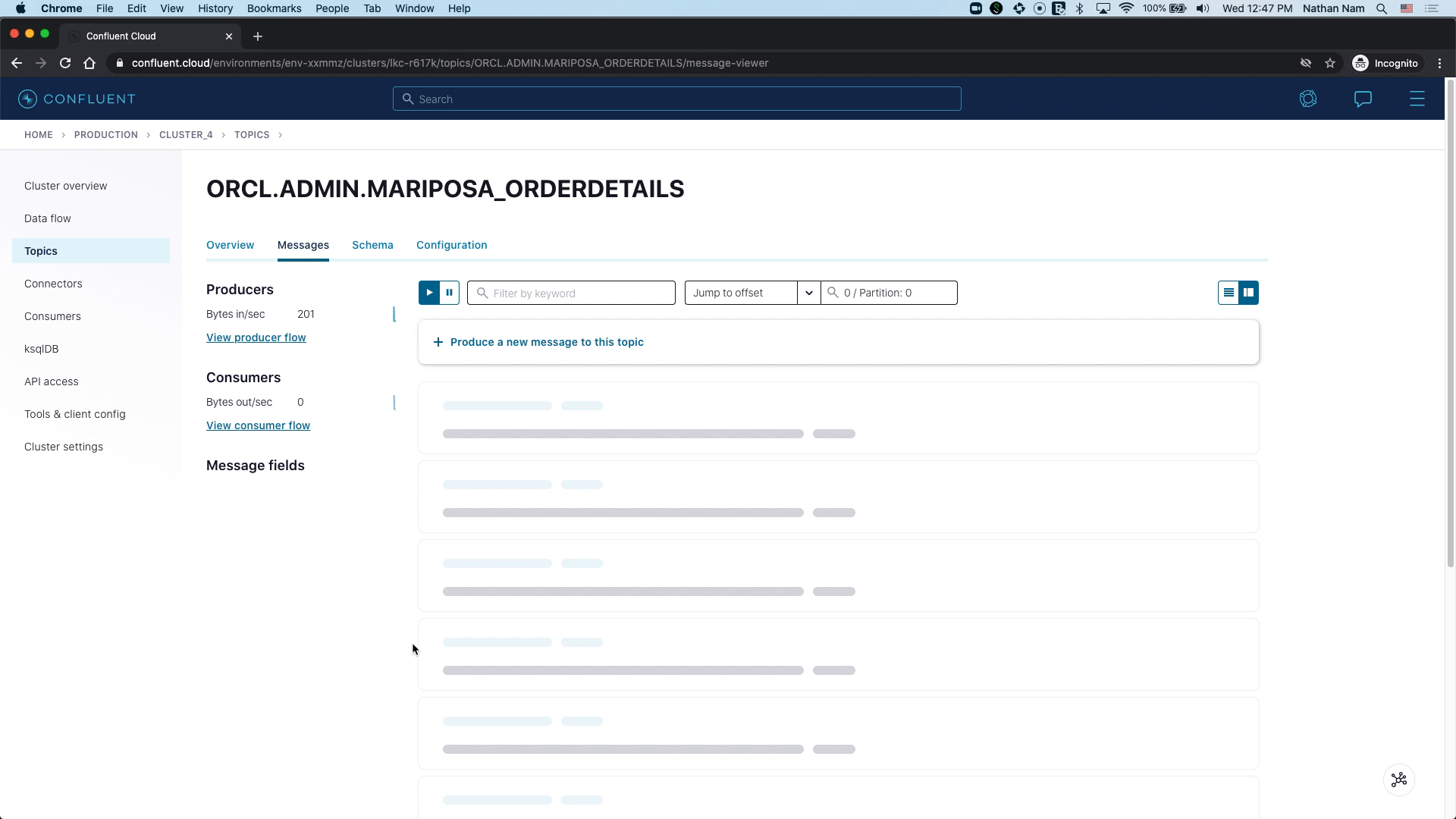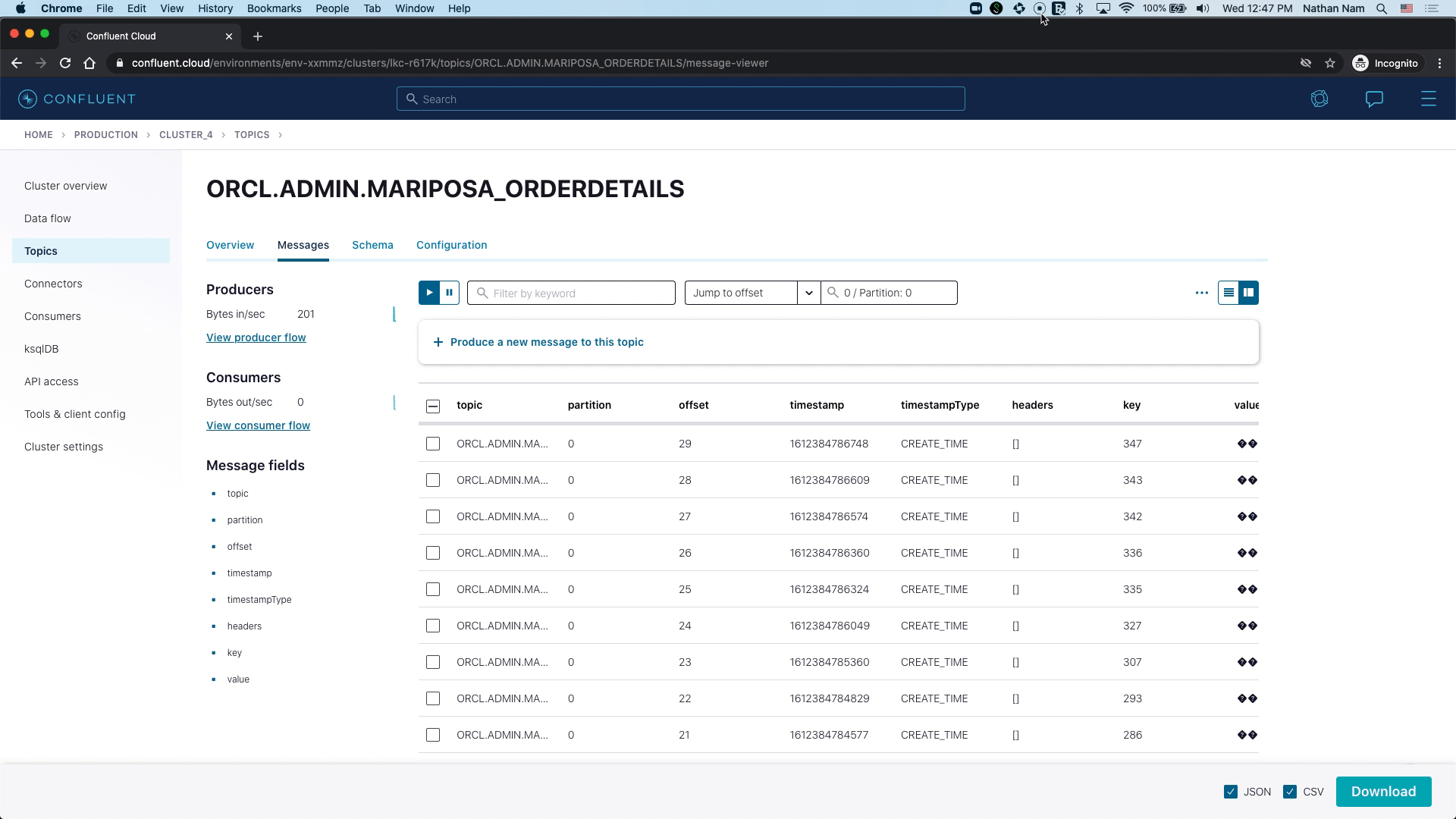
As new orders are coming to the Oracle table MARIPOSA_ORDERDETAILS, the connector captures raw Oracle events in the oracle-redo-log-topic and writes the change events specific to the MARIPOSA_ORDERDETAILS table to the ORCL.ADMIN.MARIPOSA_ORDERDETAILS topic.
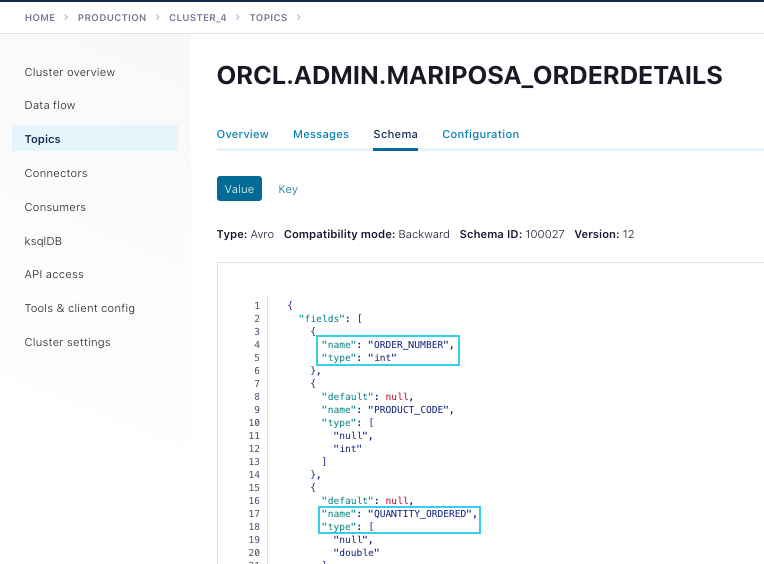
With "numeric.mapping":"best_fit", you will notice that the ORDER_NUMBER and QUANTITY_ORDERED fields from the source table (both NUMERIC type) are written to the Kafka topic as INT and DOUBLE, respectively:
Now that we have a stream of all of the data from the Oracle MARIPOSA_ORDERDETAILS table in Kafka, we can put it to use. In our scenario, we were required to populate BigQuery for our Data Science team, so we’ll do that using the BigQuery Sink Connector. Because we’re using Confluent Cloud, we can take advantage of the fully managed connector to do this.
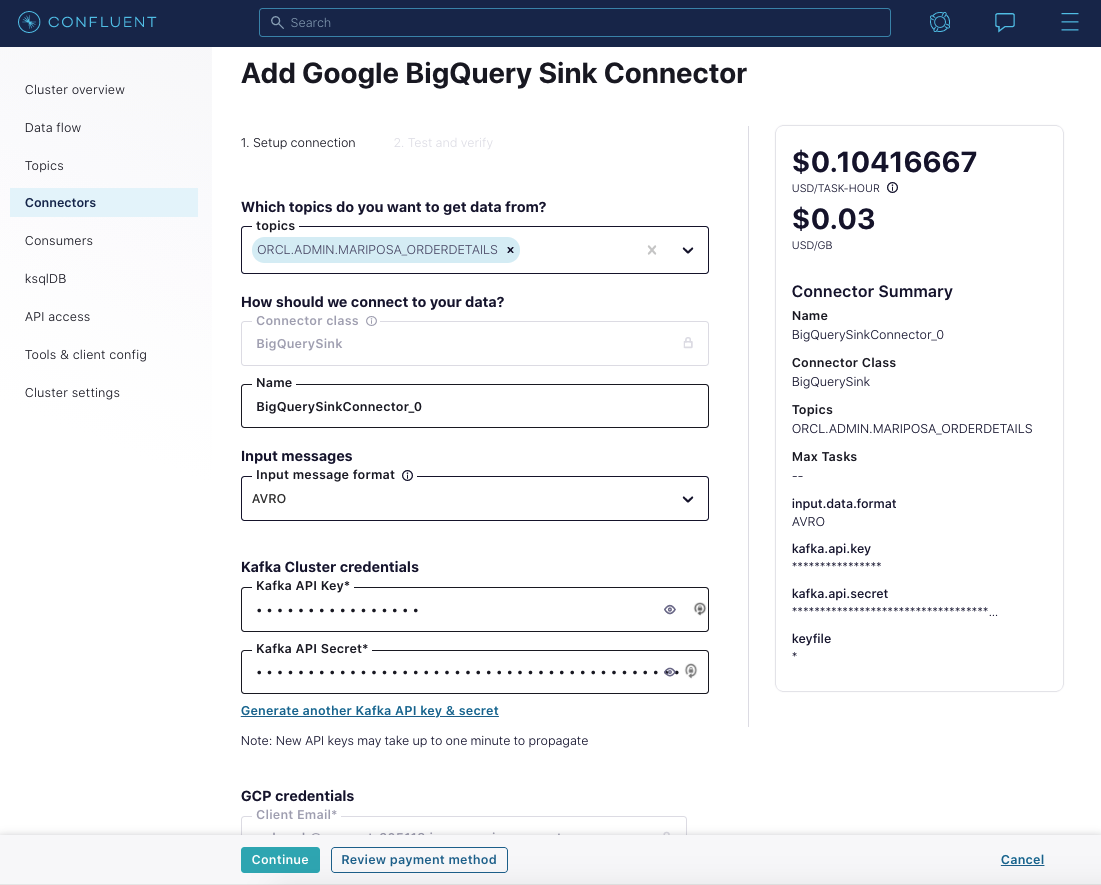
Heading over to BigQuery, you’ll see the ORCL_AMDIN_MARIPOSA_ORDERDETAILS table populated with data.
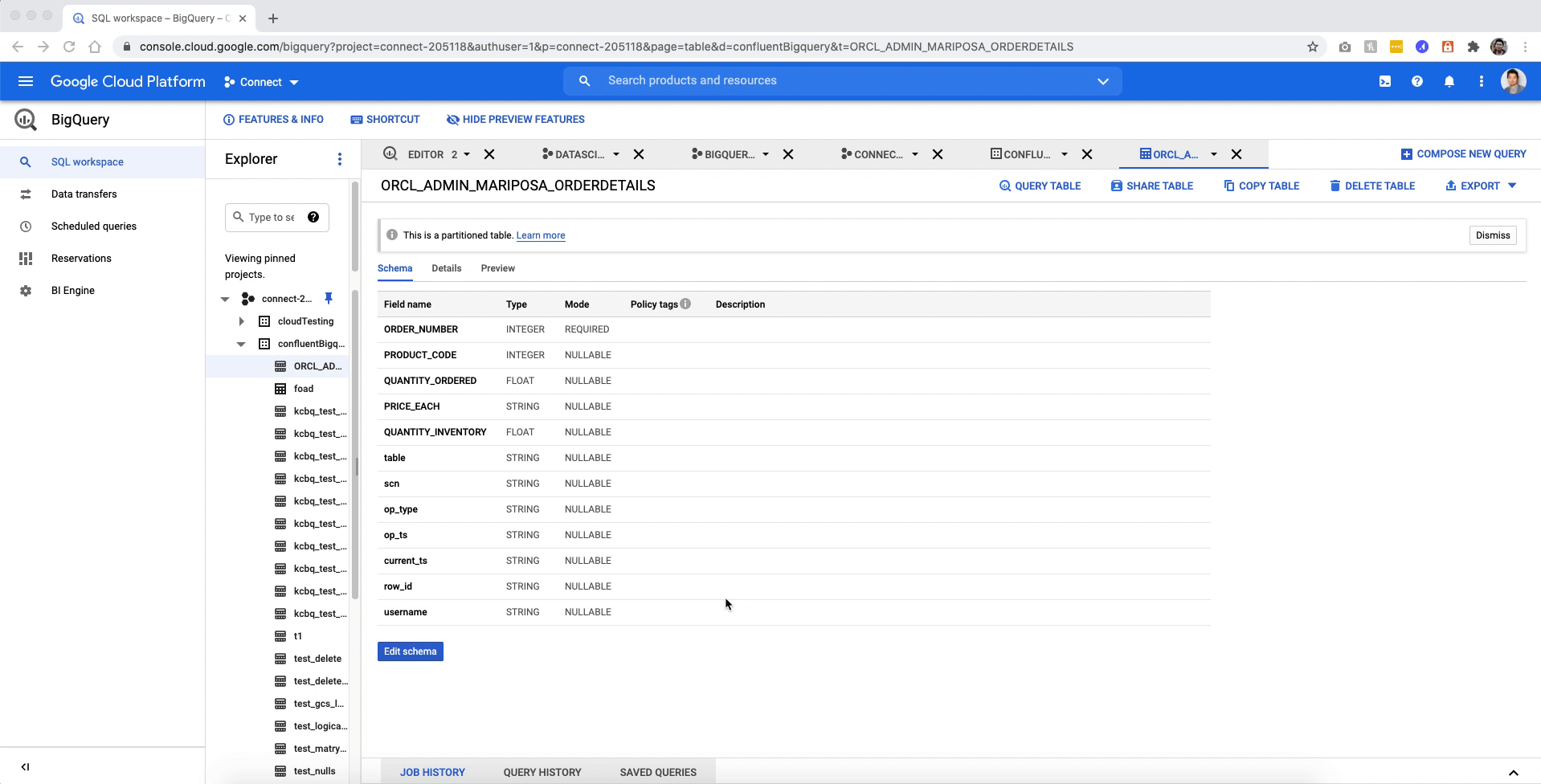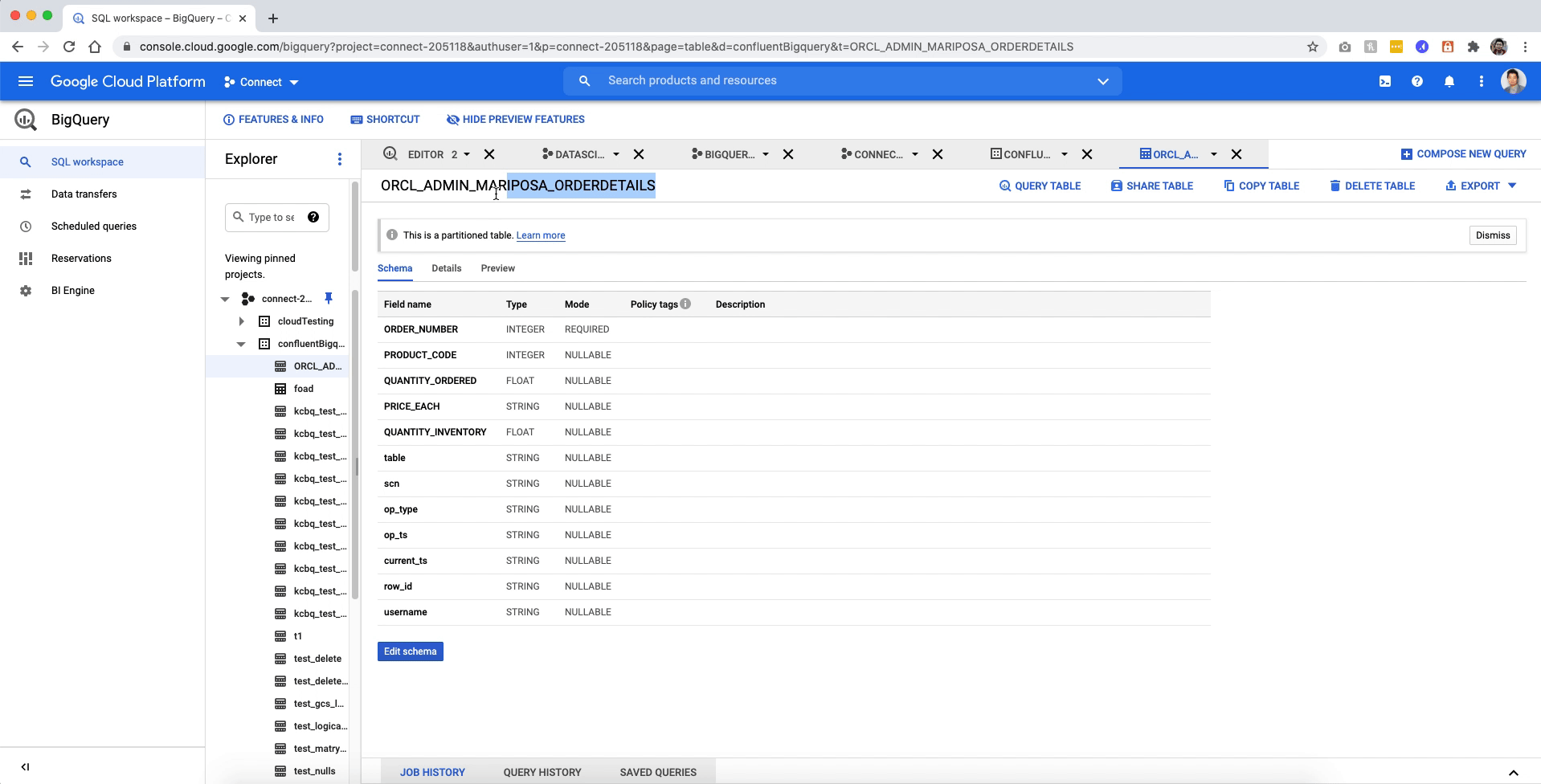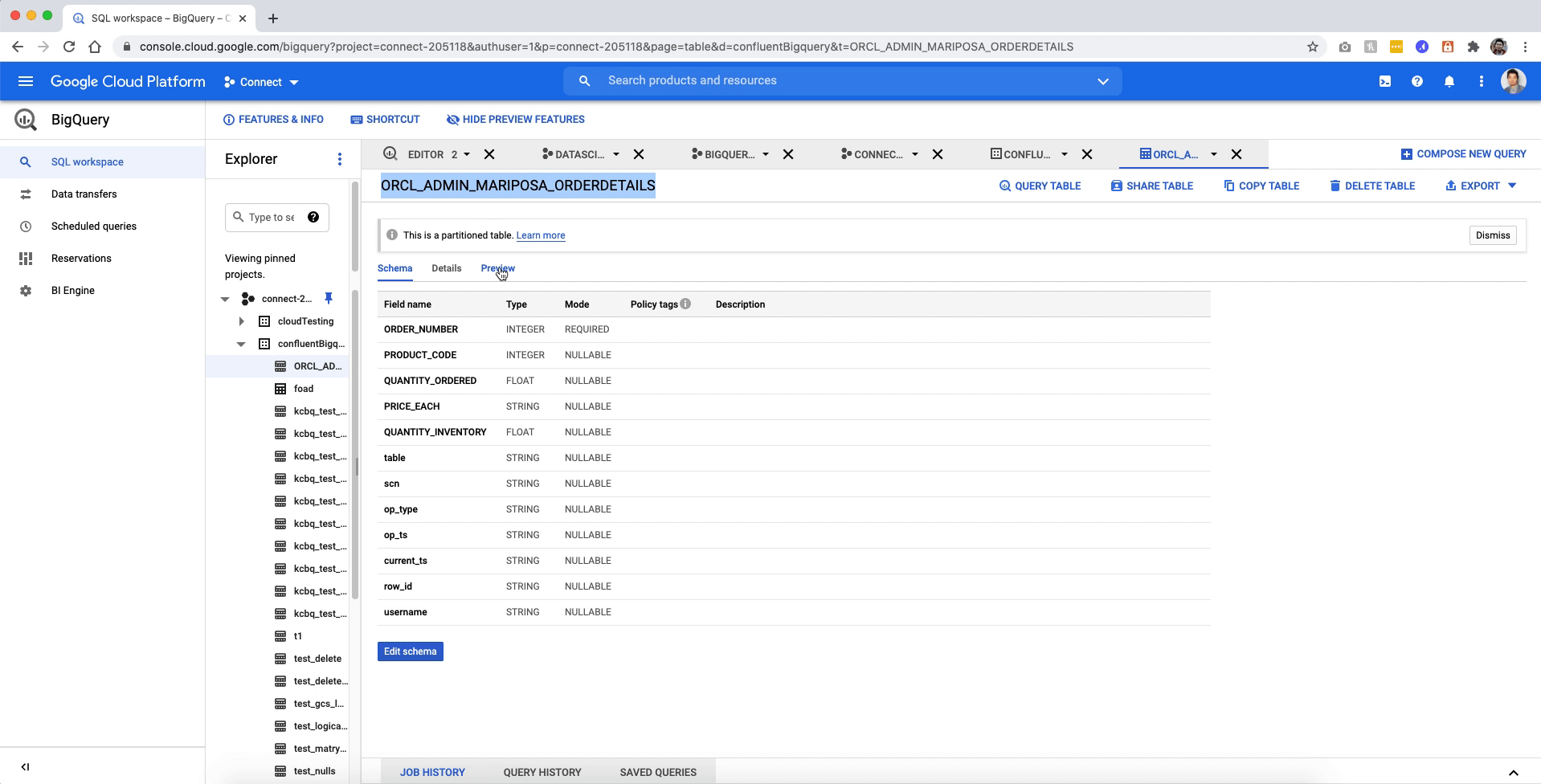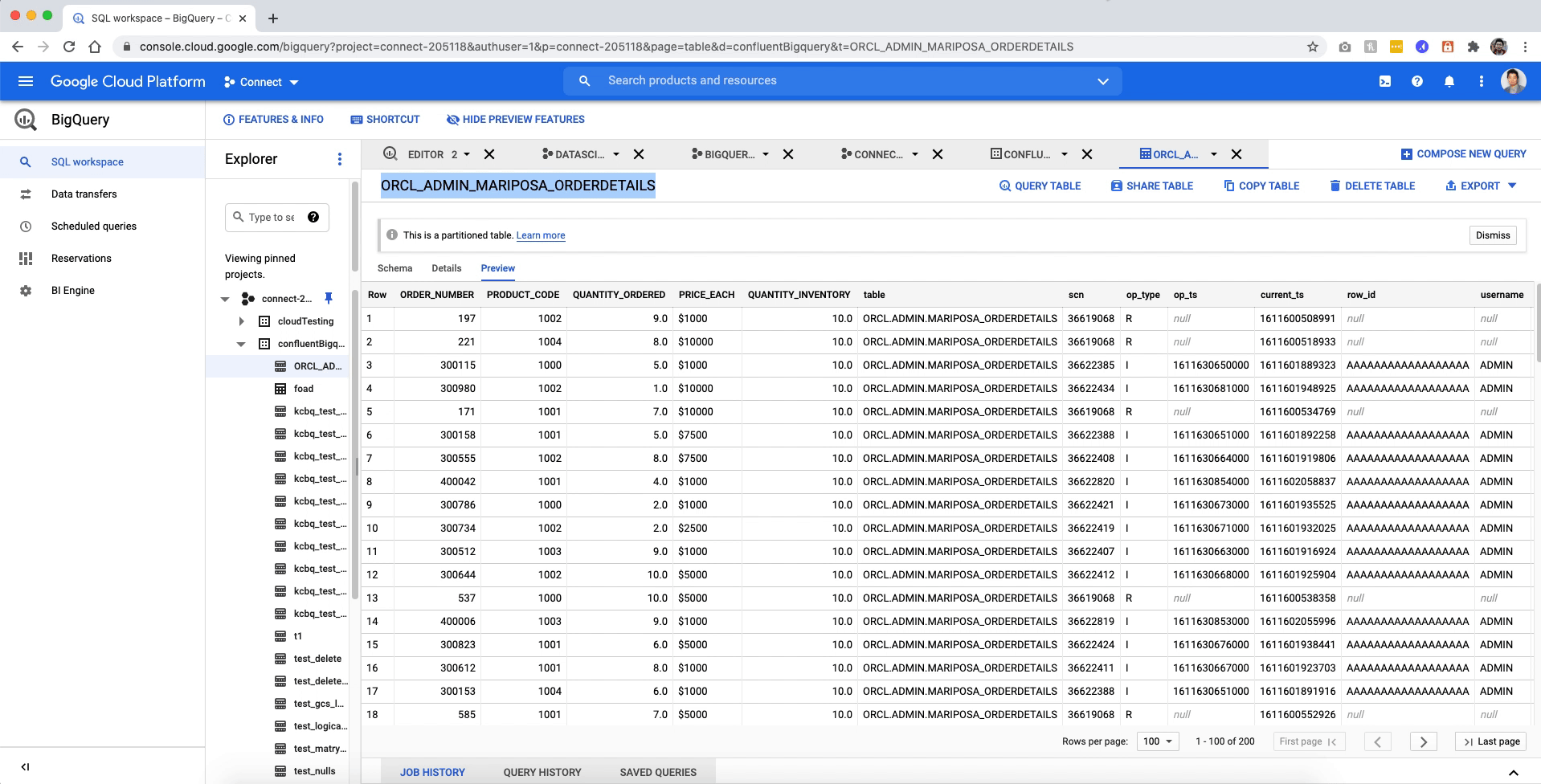
You now have a working data pipeline from an Oracle database through to BigQuery using Confluent’s self-managed Oracle CDC Connector.
Learn more about the Oracle CDC Source Connector
To learn more about Confluent’s Oracle CDC Source Connector, please register for the online talk, where we will feature a demo and technical deep dive.
If you haven’t tried it yet, check out Confluent’s latest Oracle CDC Source Connector on Confluent Hub or this Dockerized example to get familiar with various configuration parameters.
Further reading
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.