New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Featuring Apache Kafka in the Netflix Studio and Finance World
Netflix spent an estimated $15 billion to produce world-class original content in 2019. When stakes are so high, it is paramount to enable our business with critical insights that help plan, determine spending, and account for all Netflix content. These insights can include:
- How much should we spend in the next year on international movies and series?
- Are we trending to go over our production budget and does anyone need to step in to keep things on track?
- How do we program a catalog years in advance with data, intuition, and analytics to help create the best slate possible?
- How do we produce financials for content across the globe and report to Wall Street?
Similar to how VCs rigorously tune their eye for good investments, the Content Finance Engineering Team’s charter is to help Netflix invest, track, and learn from our actions so that we continuously make better investments in the future.
Embrace eventing
From an engineering standpoint, every financial application is modeled and implemented as a microservice. Netflix embraces distributed governance and encourages a microservices-driven approach to applications, which helps achieve the right balance between data abstraction and velocity as the company scales. In a simple world, services can interact through HTTP just fine, but as we scale out, they evolves into a complex graph of synchronous, request-based interactions that can potentially lead to a split-brain/state and disrupt availability.
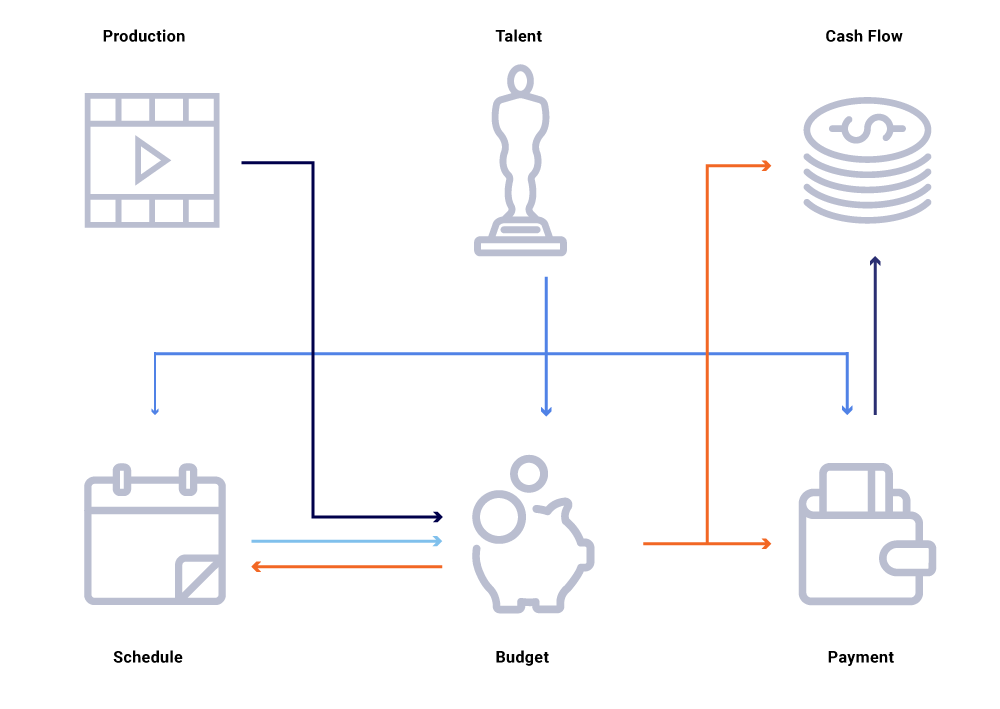
Consider in the above graph of related entities, a change in the production date of a show. This impacts our programming slate, which in turn influences cash flow projects, talent payments, budgets for the year, etc. Often in a microservice architecture, some percentage of failure is acceptable. However, a failure in any one of the microservice calls for Content Finance Engineering would lead to a plethora of computations being out of sync and could result in data being off by millions of dollars. It would also lead to availability problems as the call graph spans out and cause blind spots while trying to effectively track down and answer business questions, such as: why do cash flow projections deviate from our launch schedule? Why is the forecast for the current year not taking into account the shows that are in active development? When can we expect our cost reports to accurately reflect upstream changes?
Rethinking service interactions as streams of event exchanges—as opposed to a sequence of synchronous requests—lets us build infrastructure that is inherently asynchronous. It promotes decoupling and provides traceability as a first-class citizen in a web of distributed transactions. Events are much more than triggers and updates. They become the immutable stream from which we can reconstruct the entire system state.
Moving towards a publish/subscribe model enables every service to publish its changes as events into a message bus, which can then be consumed by another service of interest that needs to adjust its state of the world. Such a model allows us to track whether services are in sync with respect to state changes and, if not, how long before they can be in sync. These insights are extremely powerful when operating a large graph of dependent services. Event-based communication and decentralized consumption helps us overcome issues we usually see in large synchronous call graphs (as mentioned above).
Netflix embraces Apache Kafka® as the de-facto standard for its eventing, messaging, and stream processing needs. Kafka acts as a bridge for all point-to-point and Netflix Studio wide communications. It provides us with the high durability and linearly scalable, multi-tenant architecture required for operating systems at Netflix. Our in-house Kafka as a service offering provides fault tolerance, observability, multi-region deployments, and self-service. This makes it easier for our entire ecosystem of microservices to easily produce and consume meaningful events and unleash the power of asynchronous communication.
A typical message exchange within Netflix Studio ecosystem looks like this:
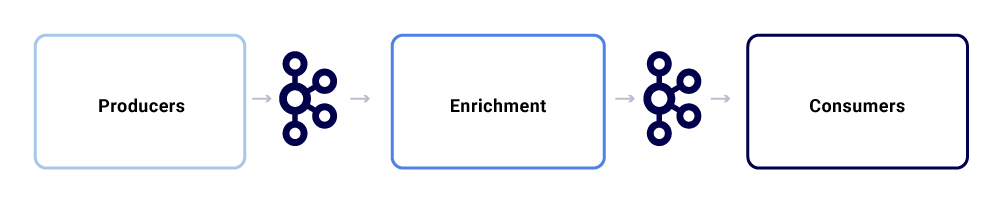
We can break them up as three major sub-components.
Producers
A producer can be any system that wants to publish its entire state or hint that a critical piece of its internal state has changed for a particular entity. Apart from the payload, an event needs to adhere to a normalized format, which makes it easier to trace and understand. This format includes:
- UUID: Universally unique identifier
- Type: One of the create, read, update, or delete (CRUD) types
- Ts: Timestamp of the event
Change data capture (CDC) tools are another category of event producers that derive events out of database changes. This can be useful when you want to make database changes available to multiple consumers. We also use this pattern for replicating the same data across datacenters (for single master databases). An example is when we have data in MySQL that needs to be indexed in Elasticsearch or Apache Solr™. The benefit of using CDC is that it does not impose additional load on the source application.
For CDC events, the TYPE field in the event format makes it easy to adapt and transform events as required by the respective sinks.
Enrichers
Once data exists in Kafka, various consumption patterns can be applied to it. Events are used in many ways, including as triggers for system computations, payload transfer for near-real-time communication, and cues to enrich and materialize in-memory views of data.
Data enrichment is becoming increasingly common where microservices need the full view of a dataset but part of the data is coming from another service’s dataset. A joined dataset can be useful for improving query performance or providing a near-real-time view of aggregated data. To enrich the event data, consumers read the data from Kafka and call other services (using methods that include gRPC and GraphQL) to construct the joined dataset, which are then later fed to other Kafka topics.
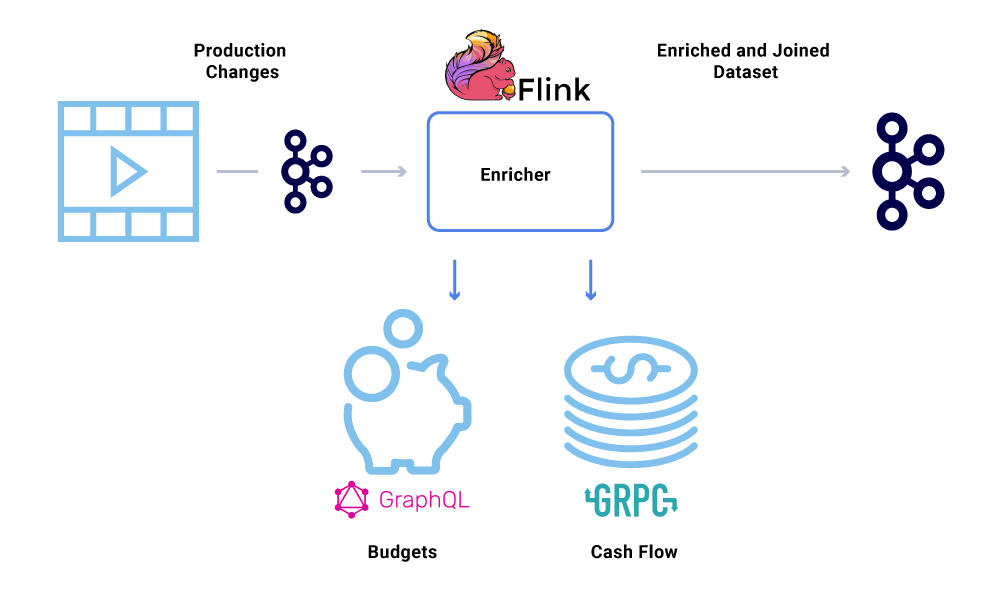
Enrichment can be run as a separate microservice in it of itself that is responsible for doing the fan-out and for materializing datasets. There are cases where we want to do more complex processing like windowing, sessionization, and state management. For such cases, it is recommended to use a mature stream processing engine on top of Kafka to build business logic. At Netflix, we use Apache Flink® and RocksDB to do stream processing. We’re also considering ksqlDB for similar purposes.
Ordering of events
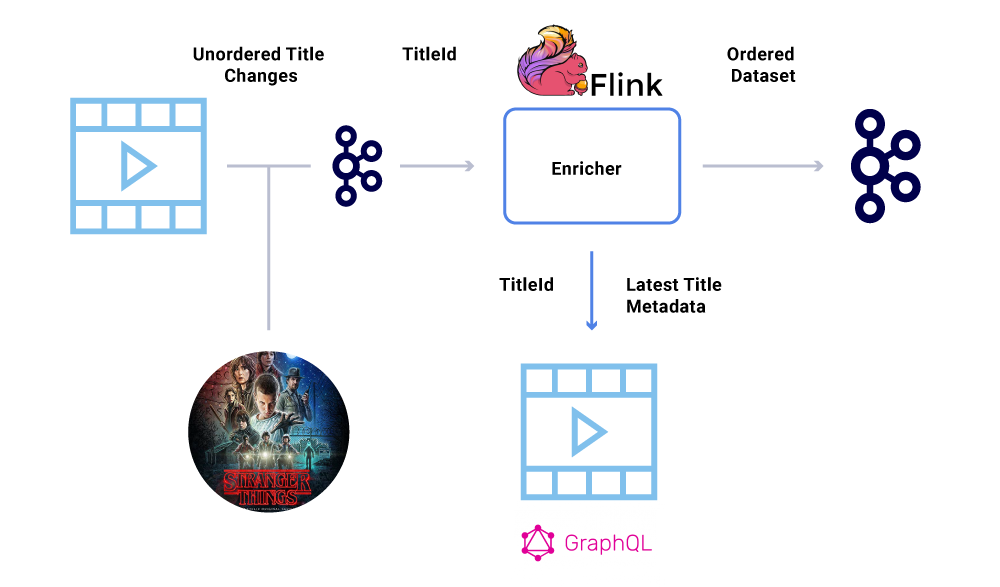
One of the key requirements within a financial dataset is the strict ordering of events. Kafka helps us achieve this is by sending keyed messages. Any event or message sent with the same key, will have guaranteed ordering since they are sent to the same partition. However, the producers can still mess up the ordering of events.
For example, the launch date of “Stranger Things” was originally moved from July to June but then back from June to July. For a variety of reasons, these events could be written out in the wrong order to Kafka (network timeout when producer tried to reach Kafka, a concurrency bug in producer code, etc). An ordering hiccup could have heavily impacted various financial calculations.
To circumvent this scenario, producers are encouraged to send only the primary ID of the entity that has changed and not the full payload in the Kafka message. The enrichment process (described in the above section) queries the source service with the ID of the entity to get the most up-to-date state/payload, thus providing an elegant way of circumventing the out-of-order issue. We refer to this as delayed materialization, and it guarantees ordered datasets.
Consumers
We use Spring Boot to implement many of the consuming microservices that read from the Kafka topics. Spring Boot offers great built-in Kafka consumers called Spring Kafka Connectors, which make consumption seamless, providing easy ways to wire up annotations for consumption and deserialization of data.
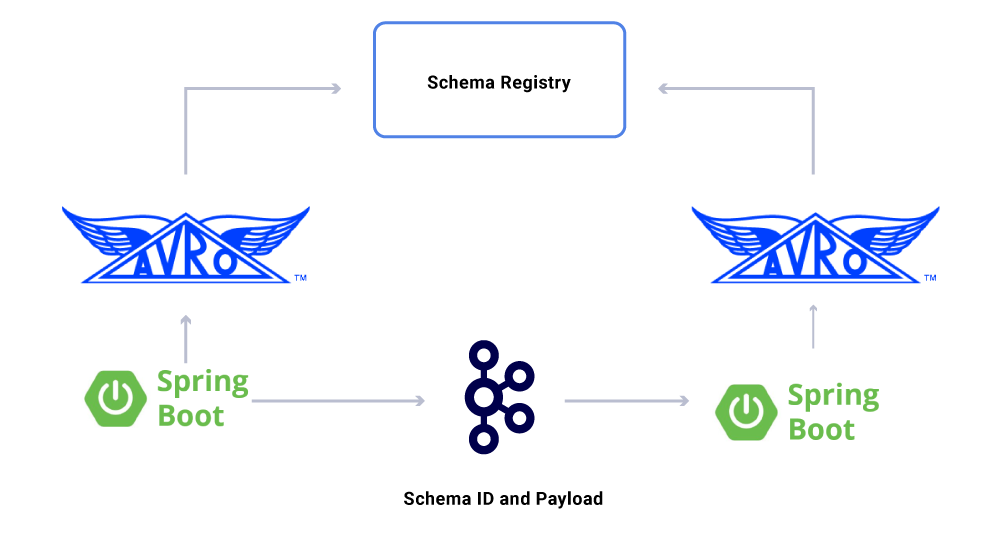
One aspect of the data that we haven’t discussed yet are contracts. As we scale out our use of event streams, we end up with a varied group of datasets, some of which are consumed by a large number of applications. In these cases, defining a schema on the output is ideal and helps ensure backward compatibility. To do this, we leverage Confluent Schema Registry and Apache Avro™ to build our schematized streams for versioning data streams.
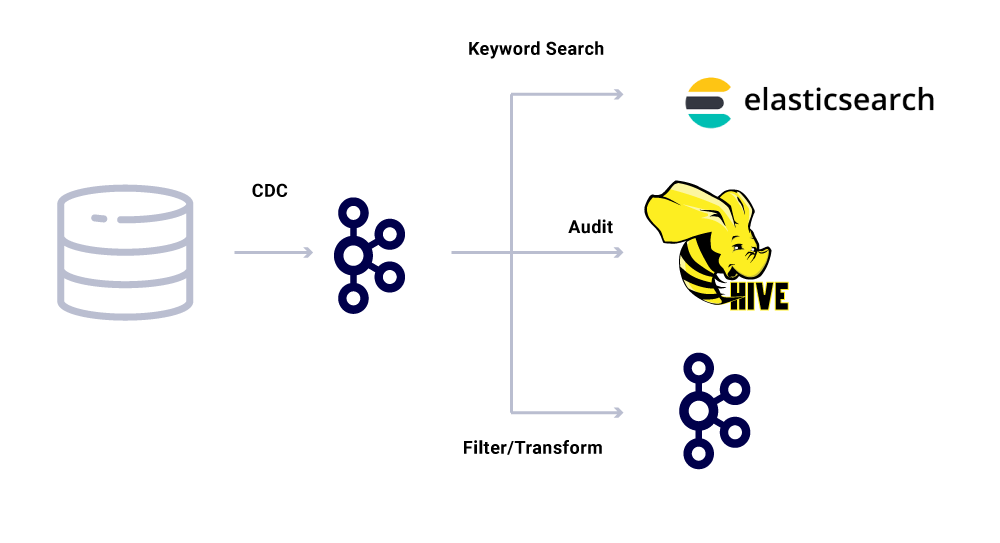
In addition to dedicated microservice consumers, we also have CDC sinks that index the data into a variety of stores for further analysis. These include Elasticsearch for keyword search, Apache Hive™ for auditing, and Kafka itself for further downstream processing. The payload for such sinks is directly derived from the Kafka message by using the ID field as the primary key and TYPE for identifying CRUD operations.
Message delivery guarantees
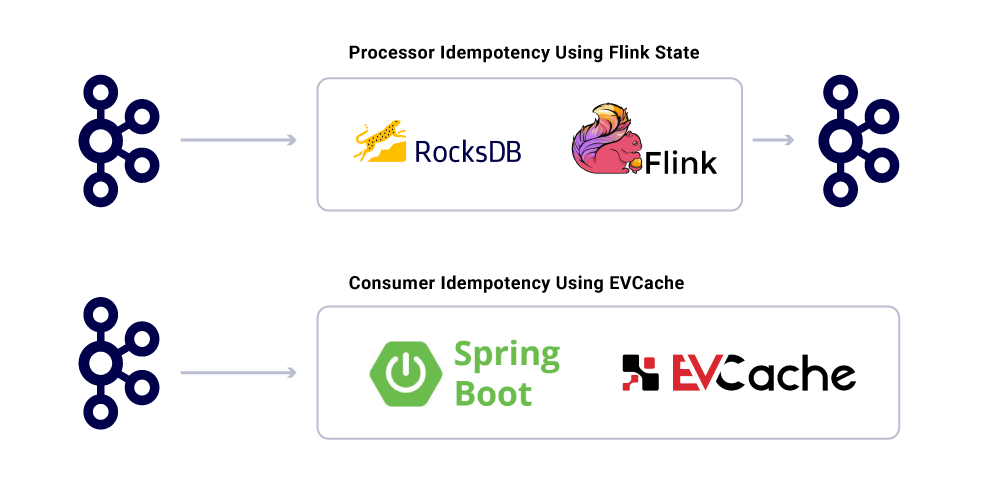
Guaranteeing exactly once delivery in a distributed system is nontrivial due to the complexities involved and a plethora of moving parts. Consumers should have idempotent behavior to account for any potential infrastructure and producer mishaps.
Despite the fact that applications are idempotent, they should not repeat compute heavy operations for already-processed messages. A popular way of ensuring this is to keep track of the UUID of messages consumed by a service in a distributed cache with reasonable expiry (defined based on Service Level Agreements (SLA). Anytime the same UUID is encountered within the expiry interval, the processing is skipped.
Processing in Flink provides this guarantee by using its internal RocksDB-based state management, with the key being the UUID of the message. If you want to do this purely using Kafka, Kafka Streams offers a way to do that as well. Consuming applications based on Spring Boot use EVCache to achieve this.
Monitoring infrastructure service levels
It’s crucial for Netflix to have a real-time view of the service levels within its infrastructure. Netflix wrote Atlas to manage dimensional time series data, from which we publish and visualize metrics. We use a variety of metrics published by producers, processors, and consumers to help us construct a near-real-time picture of the entire infrastructure.
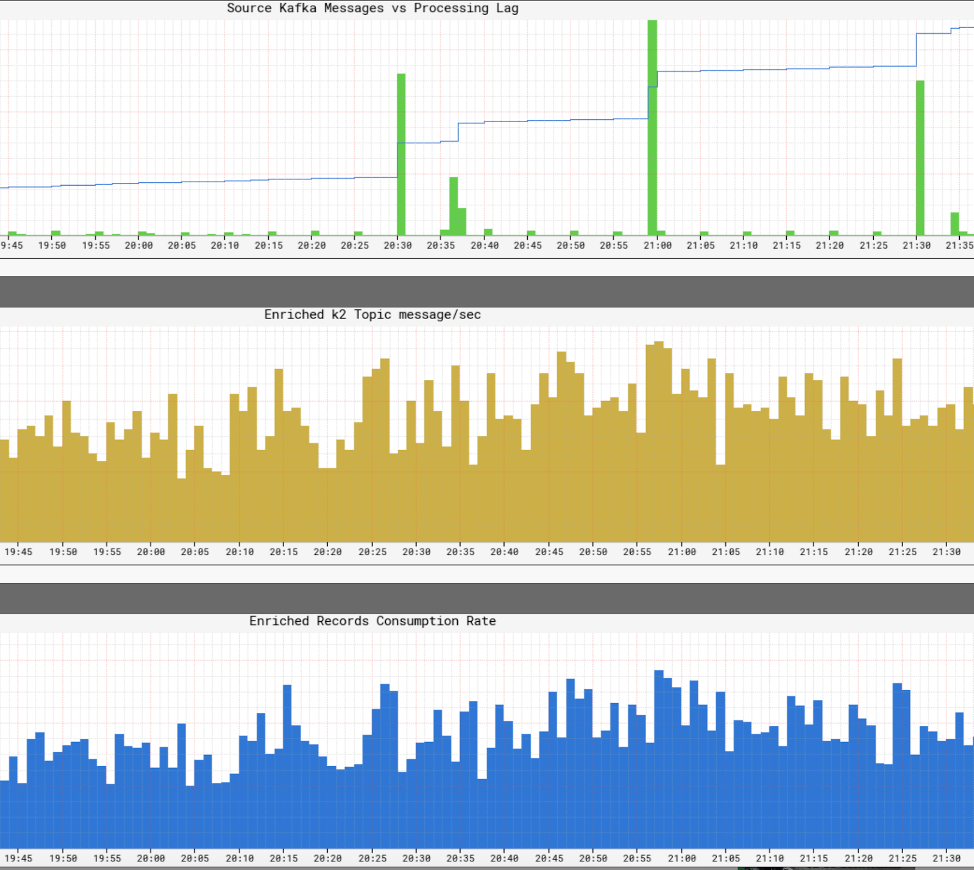
Some of the key aspects we monitor are:
- Freshness SLA
- What is the time end to end from the production of an event until it reaches all sinks?
- What is the processing lag for every consumer?
- Max transfer rate
- How large of a payload are we able to send?
- Should we compress the data?
- Partitioning and parallelism
- Are we efficiently utilizing our resources?
- Can we consume faster?
- Failover and recovery
- Are we able to create a checkpoint for our state and resume in the case of failures?
- Backpressure
- If we are not able to keep up with the event firehose, can we apply backpressure to the corresponding sources without crashing our application?
- Load distribution
- How do we deal with event bursts?
- Are we sufficiently provisioned to meet the SLA?
Synopsis
The Netflix Studio Productions and Finance Team embraces distributed governance as the way of architecting systems. We use Kafka as our platform of choice for working with events, which are an immutable way to record and derive system state. Kafka has helped us achieve greater levels of visibility and decoupling in our infrastructure while helping us organically scale out operations. It is at the heart of revolutionizing Netflix Studio infrastructure and with it, the film industry.
Interested in more?
If you’d like to know more, you can view the recording and slides of my Kafka Summit San Francisco presentation Eventing Things – A Netflix Original!





