New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
How Bolt Has Adopted Change Data Capture with Confluent Platform
This article describes why Bolt, the leading European on-demand transportation platform that operates across ride-hailing, food delivery, and e-mobility sectors, has journeyed toward adopting change data capture (CDC). Adopting CDC has allowed us to unleash the power of real-time data and ultimately migrate away from batch data workloads to stream processing. This article also explains why we have chosen Confluent Platform as our company-wide event streaming solution and how all of its components fit into our general architecture.
It all started with data replication
A few years ago, we at Bolt, decided to improve the process we used to replicate data from operational databases and other data sources to a data warehouse. Our process back then involved periodically polling the source database for data that had changed since it was last polled. This process had the following shortcomings:
- It was creating significantly extra load on source databases by constantly querying big volumes of data from them.
- It required every source table to have an index on it to facilitate retrieving new portions of data from it every time. Not only were those indexes consuming extra disk space but they were also slowing down every single operation over the table.
- It could miss data in cases where the field used for querying the table was set to some value outside of the next polling interval range.
- It missed the data that was created and deleted between two subsequent query runs.
Besides fixing all the above-mentioned issues, our new replication pipeline implementation had to also account for these additional requirements:
- It should be linearly scalable. As a growing business, we want to replicate more and more tables and even databases, so it should be easy to set up a new replication data source.
- It should allow us to perform proprietary data transformations. For example, we need to be able to replicate only a specific subset of fields from a given table, not all of them, or obfuscate some fields that contain sensitive data in order to comply with data protection regulations like GDPR.
After starting this project, it was obvious that our simple data replication use case would outgrow itself and transform into a company-wide data bus and event streaming platform. So whichever technology we decided to use would need to be extremely reliable, elastically scalable, and have extensible functionality. We adopted Confluent Platform for this purpose and it now powers most of the data pipelines and flows we have at Bolt.
Getting the data out with CDC
Change data capture (CDC) is a term used to refer to a set of techniques for identifying and exposing changes made to a database. There are two types:query-based CDC and log-based CDC.
Query-based CDC is used to denote a process of periodic polling of a database for changes that have occurred to its data between successive polls. Log-based CDC refers to a process of database management that exposes a sequence of changes applied to its data.
Almost every modern relational database management system (and even some non-relational ones) provide a log-based CDC interface. Throughout this article, I will be referring to log-based CDC.
If we had to pick the greatest advantage that log-based CDC has over a query-based one, it would be that capturing data changes with a log-based approach creates a small to zero extra load on the source database. But it has a few other advantages as well:
- No data loss: All data changes are exposed, including DELETE operations, so downstream subscribers do not miss any data at all (even if data was deleted right after its creation)
- Data change events are exposed in the same order they were applied to the source database
- No data duplicates: Every single change appears only once
- It is real time: A data change is exposed right after it has been applied to the database
- All of it is managed and guaranteed by a database management system, so there is nothing you as an engineer should worry about
Even though the CDC interface itself is usually provided by a database itself, there should be a middleware capable of extracting and processing these data changes. In our case, we have adopted Debezium.
Debezium provides a set of software plugins called connectors that are responsible for capturing data changes from most modern databases.
A Debezium connector translates data change records into JSON format, making them suitable for consumption by backend services. On every database record creation, a modification or deletion connector generates a separate JSON document. Every such document contains metadata about its schema, a type of database operation, the timestamp of the connector processing the change, and a snapshot of the record’s state before and after the operation.
{
"schema": {...}, // information on schema of event
"payload": {
"before": { // state of record before the operation
"id": 1,
"user_id": 2,
"lat": "123.456",
"lng": "426.185",
"state": "RIDE_REQUESTED"
},
"after": { // state of record after the operation
"id": 1,
"user_id": 2,
"lat": "123.456",
"lng": "426.185",
"state": "DRIVER_FOUND"
},
"source": { ... }, // source database metadata
"op": "u", // update operation
"ts_ms": 1465581729546 // timestamp of capturing this change
}
}
These change events can be either consumed once, processed, and discarded or persisted, allowing them to be processed multiple times by different consumers.
Apache Kafka® at the core
When designing the architecture for this project, we decided from the very beginning to use captured data events more than once. An important requirement for a storage layer is absolute ordering of events—it is crucial to store incremental change events in exactly the same order as they have occurred in a source database.
Apache Kafka is an event streaming platform that combines the following properties into a single technology:
- It is distributed and therefore fault tolerant out of the box. It operates as a cluster of machines working together as one.
- It is a high-throughput messaging system.
- It encourages “write once read many” (WORM) semantics by not deleting messages after they have been read and processed the first time but allowing multiple consumers to process the same messages many times.
- It is pretty much infinitely horizontally scalable. You can expand or shrink a Kafka cluster depending on the load.
- Apache Kafka guarantees ordering of messages.
Messages are organized into topics inside Apache Kafka. All data change events from a single database table go to a single topic inside Apache Kafka. Strict ordering of events comes at the price of having single-partitioned topics, as this is the mechanism used by Apache Kafka to provide event ordering.
Kafka Connect for orchestration
Running Debezium connectors require some extra management:
- It would be good to be able to pause the connector and resume later if, for example, the database needs downtime for maintenance.
- The connector needs to be automatically restarted if some transient failure occurs (like network partition or database connectivity loss).
- It has to periodically checkpoint its progress for faster recovery after a restart
Ideally, it should also be running in a cluster setup mode for high availability.
All these features become especially important when you run several CDC processes that capture data from multiple databases. Every database has its own life cycle completely detached from other databases. It can be rebooted, shut down permanently, or migrated to another machine in the cloud. You do not want single database maintenance to interrupt operations for the whole CDC pipeline.
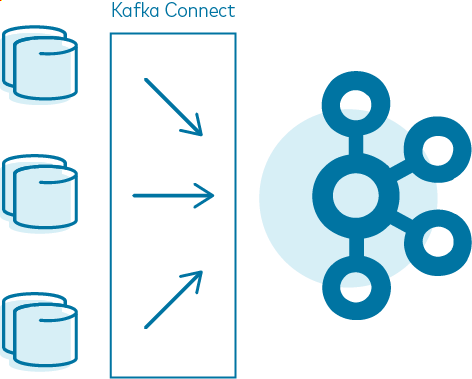
All of it is taken care of by Kafka Connect framework. Kafka Connect operates a number of processes that are responsible for moving data between systems. It is a framework that orchestrates all this maintenance work and is responsible for the life cycle management of “data copying” tasks.
Kafka Connect runs on a cluster of machines called worker nodes and it manages a set of connectors. There are two types of connectors: sources and sinks. Sources are responsible for retrieving data from external systems and ingesting it into Apache Kafka while sinks do the opposite—they get data from Apache Kafka and put it into some other system. In this way, Kafka Connect takes care of all incoming and outgoing data flows around Apache Kafka.
Confluent Schema Registry for schema management
Usually, backend services work with data represented in JSON format. Change data capture is no exception here. But storing millions of JSONs with the same attributes is suboptimal as approximately half of the disk space will be occupied by JSON schema descriptions. These descriptions are usually the same across all events from the same table. There are few data serialization frameworks that address this issue. Avro is one of them. Imagine taking JSON, removing the schema out of it, storing it somewhere external, and creating a pointer to a schema inside of the stripped JSON. Imagine doing this for all the events that share the same schema. That is exactly what Avro and Confluent Schema Registry do.
Schema Registry is a centralized storage of all Avro schemas (other data encoding formats were added in version 5.5.0, like Protobuf and JSON). Schema Registry provides the following benefits:
- It acts as a single source of truth regarding the schema of your data.
It provides an API for other backend services to retrieve and create new data encoding schemas. - Using binary-encoded data causes it to significantly reduce network utilization during data transfer and reduce disk storage used for data persistence.
- It creates a contract between data producers and data consumers,
- It supports schema evolution. Even more, it enforces extra checks on schema evolution. It can check whether a schema change is backward compatible, forward compatible, or fully compatible. This allows engineers to evolve schemas safely while making sure changes don’t break downstream consumers.
To sum it all up, Confluent Schema Registry provides generous disk storage, network throughput, and schema safety checks.
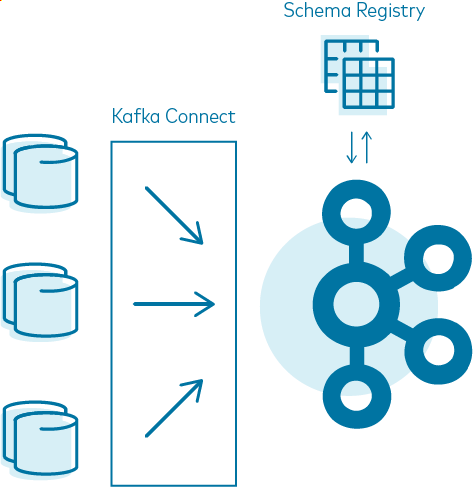
Kafka Streams and ksqlDB for stream processing
Now that we have a scalable and reliable way of capturing data from source systems, persisting its binary representation into Apache Kafka, and ingesting it into several downstream systems, there is one last project requirement left to fulfill: the ability to transform and modify data along the way.
I described how we have adopted ksqlDB for that purpose in my previous blog post. But it might be worth explicitly mentioning that ksqlDB usage does not restrict the pool of technologies that you can use only to itself. Even though ksqlDB is quite powerful on its own, sometimes you might want to have more precise control over how your event streaming application works internally. Kafka Streams is a go-to option in this case. Both Kafka Streams applications and ksqlDB can be processing data from a single Kafka cluster simultaneously. Both technologies are designed to operate in high-availability mode and both are extensible with user-specific functionality if necessary.
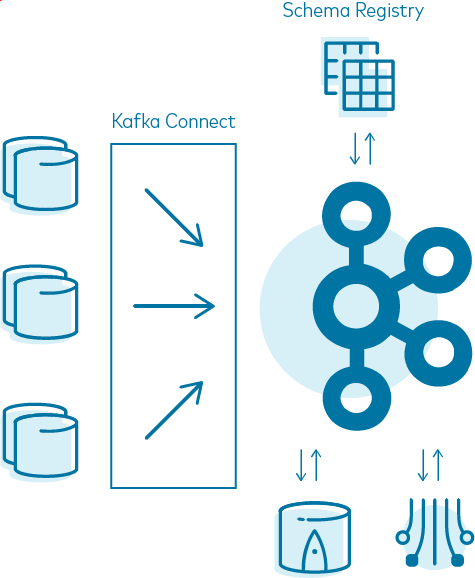
Final setup and future plans
When we combine all these pieces together, here is what our final pipeline for data replication looks like:
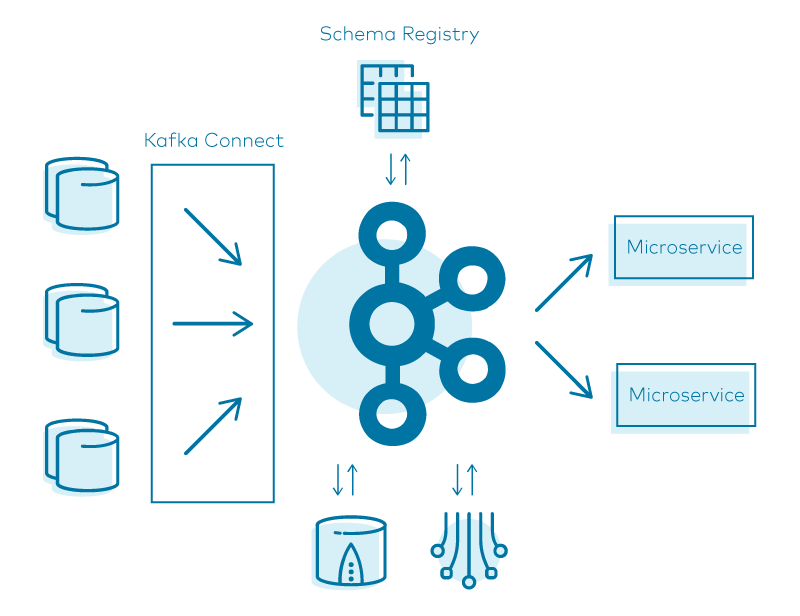
Having all of the pipeline’s components running in high-availability mode makes it extremely fault-tolerant and reliable.
In addition to achieving its main goal of scalable and reliable data replication, this system allows us to unleash all the benefits of event streaming, including reliable cross-service communication, migration away from batch data processing workloads to real-time stream processing, and the ability to capture an event once and process it many times.
If you’d like to know more, you can listen to Streaming Audio or download the Confluent Platform to get started with a complete event streaming platform built by the original creators of Apache Kafka.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.