New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Putting Apache Kafka To Use: A Practical Guide to Building an Event Streaming Platform (Part 2)
This is the second part of our guide on streaming data and Apache Kafka. In part one I talked about the uses for real-time data streams and explained the concept of an event streaming platform. The remainder of this guide will contain specific advice on how to go about building an event streaming platform in your organization.
This advice is drawn from our experience building and implementing Kafka at LinkedIn and rolling it out across all the data types and systems there. It also comes from many years working with companies to build Kafka-based event streaming platforms in their organizations.
This is meant to be a living document. As we learn new techniques or new tools become available, I’ll update it.
Getting Started
Much of the advice in this guide covers techniques that will scale to hundreds or thousands of well-formed data streams. No one starts with that, of course. Usually you start with one or two trial applications, often ones that have scalability requirements that make other systems less suitable. Even in this kind of limited deployment, though, the techniques described in this guide will help you to start off with good practices, which is critical as your usage expands.
Starting with something more limited is good, it lets you get a hands on feel for what works and what doesn’t, so that, when broader adoption comes, you are well prepared for it.
Recommendations
I’ll give a set of general recommendations for streaming data and Kafka and then discuss some specifics of different types of event streams.
1. Limit The Number of Clusters
In early experimentation phases, it’s normal to end up with a few different Kafka clusters as adoption occurs organically in different parts of the organization. However part of the promise of this approach to data management is having a central repository with the full set of data streams your organization generates.
This is similar to the recommendations given in data warehousing where the goal is to concentrate data in a central warehouse for simplicity and to enable uses that join together multiple data sources.
Likewise we have seen that storing streaming data in the fewest number of Kafka clusters feasible has a great deal of value in simplifying system architecture. This means fewer integration points for data consumers, fewer things to operate, lower incremental cost for adding new applications, and makes it easier to reason about data flow.
The fewest number of clusters may not be one cluster. There are several reasons to end up with multiple clusters:
- To keep activity local to a datacenter. As described later we recommend that all applications connect to a cluster in their local datacenter with mirroring between data centers done between these local data centers.
- For security reasons. Kafka has robust security capabilities, but sometimes you may find a need to physically segregate some data.
- For SLA control. Kafka has strong support for isolating applications using quotas, however physically separating clusters will still limit the “blast radius” from any kind of operational incident.
Earlier Kafka versions lacked strong security or quotas which tended to encourage creating multiple clusters for isolation. These days, using the built in features is generally a better solution.
2. Pick A Single Data Format
Apache Kafka does not enforce any particular format for event data beyond a simple key/value model. It will work equally well with XML, JSON, or Avro. Our general philosophy is that it is not the role of data infrastructure systems to enforce this kind of policy, that is really an organizational choice.
However, though your infrastructure shouldn’t make this choice for you, you should make a choice! Having a single, company-wide data format for events is critical. The overall simplicity of integration comes not only from having streaming data in a single system—Kafka!—but also by making all data look similar and follow similar conventions. If each individual or application chooses a representation of their own preference—say some use JSON, others XML, and others CSV—the result is that any system or process which uses multiple data streams has to munge and understand each of these. Local optimization—choosing your favorite format for data you produce—leads to huge global sub-optimization since now each system needs to write N adaptors, one for each format it wants to ingest.
An analogy borrowed from a friend can help to explain why such a mundane thing as data format is worth fussing about. One of the few great successes in the integration of applications is the Unix command line tools. The Unix toolset all works together reasonably well despite the fact that the individual commands were written by different people over a long period of time. The standard for integrating these tools is newline delimited ASCII text, these can be strung together with a ‘|’ which transmits a record stream using standard input and standard output. The event streaming platform is actually not that far removed from this itself. It is a kind of modern Unix pipe implemented at the data center level and designed to support our new world of distributed, continually running programs.
Though surely newline delimited text is an inadequate format to standardize on these days, imagine how useless the Unix toolchain would be if each tool invented its own format: you would have to translate between formats every time you wanted to pipe one command to another.
Picking a single format, making sure that all tools and integrations use it, and holding firm on the use of this format across the board, is likely the single most important thing to do in the early implementation of your event streaming platform. This stuff is fairly new, so if you are adopting it now sticking to the simplicity of a uniform data format should be easy.
The Mathematics of Simplicity
Together these two recommendations—limiting the number of clusters and standardizing on a single data format—bring a very real kind of simplicity to data flow in an organization.
By centralizing on a single infrastructure platform for data exchange which provides a single abstraction—the real-time stream—we dramatically simplify the data flow picture. Connecting all systems directly would look something like this:
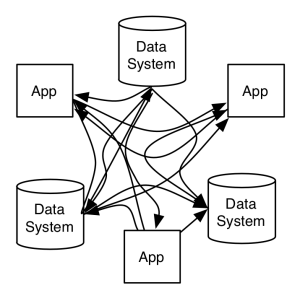
Whereas having this central event streaming platform looks something like this:
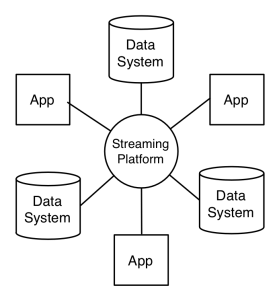
This doesn’t just look simpler. In the first picture we are on a path to build two pipelines for data flow for each pair of systems or applications, whereas in the second we are just building an input and output connector for each system to the event streaming platform. If we have 10 systems and applications to fully integrate this is the difference between 200 pipelines and 20 (if each system did both input and output).
But this is not just about systems and pipelines. Data also has to be adapted between systems. Relational databases have one data model, Hadoop another, and things like document stores still others. Providing a pipeline for raw bytes between systems would not really reduce complexity if each system produced and consumed in its own format. We would be left with a Tower of Babel where the RDBMS needs a different format plug-in for each possible source system. Instead by having a single data format in our event streaming platform we need only adapt each system to this data format and we limit the format conversions in the same way we did the number of systems.
This is not to imply that we will never want to process or transform data as it flows between systems—that, after all, is exactly what stream processing is all about—but we want to eliminate low-value syntactic conversions. Semantic changes, enrichment, and filtering, to produce derived data streams will still be quite important.
3. Consider Avro as Your Data Format
Any format, be it XML, JSON, or ASN.1, provided it is used consistently across the board, is better than a mishmash of ad hoc choices.
But if you are starting fresh with Kafka, you should pick the best format to standardize on. There are many criteria here: efficiency, ease of use, support in different programming languages, what you know and use elsewhere, and so on. In our own use, and in working with a few dozen companies, we have found Apache Avro to be easily the most successful format for streaming data.
Avro has a number of advantages around compatibility and tooling described at greater length here.
4. Choose Your Clients Carefully
Kafka has a rich ecosystem of clients for different languages. Kafka clients are non-trivial pieces of software and the quality of the client will in large part determine the performance and correctness of applications that use Kafka. Apache Kafka ships with Java clients that are developed as part of the Apache project. Find a good client for other languages can be a bit more challenging.
We recommend that for non-Java clients, you chose a client based on the C library librdkafka. This is one of the best clients in any language, has phenomenal performance, and has been battle-tested in production in thousands of real applications.
We ship a version of librdkafka, as well as clients for Python, Go, and C# as part of Confluent Platform. These clients all go through a rigorous testing process to ensure their correctness and their compatibility with Kafka. More details on the Confluent clients can be found here.
5. Model Events Not Commands
All streams in Kafka are naturally publish/subscribe and can have any number of consumers. As a result the best data model tends to structure messages as events rather than commands.
What’s the difference? An event says that something has happened. It is a simple fact, and one that is not necessarily addressed to any particular system or application. A command, on the other hand, tells a particular system to do some particular work.
Let’s consider a specific example. Let’s say we are building a web application and when a new user registers for our application we want to send a welcome email. Let’s say we will have a dedicated service that sends welcome emails based on characteristics of the user. There are two possible ways of modeling this in Kafka:
- We could have the application write a “SendEmail” command to a topic and have the service that sends the emails read from this and send out the email.
- We could have the application write a more general “UserJoinedEvent” event to the “user-joins” Topic and have the service subscribe to this and send the email.
Both of these two solutions accomplish the same thing, and for the initial use case there isn’t much difference. However the later will turn out to be preferable over time. The reason is that the “SendEmail” command is of use only to the service that will do the email sending whereas the “UserJoinedEvent” is actually a very general-purpose stream of activity about our application. It might be useful for analytics purposes as well as triggering other activity in other services.
A good principle to try to follow is this: if you were to look at the names of topics in your Kafka cluster they should mirror what most people would recognize as the events that take place in your business.
6. Use Kafka Connect for Connecting Existing Systems and Applications
The producer and consumer apis in Kafka are designed for applications that want to actively push data into or pull data out of Kafka topics. However many pre-existing applications and data systems exist which have read or write apis but are not aware of Kafka. For example you might want to capture the stream of updates being made on a relational database, or load a continuous stream into ElasticSearch. Likewise you might want to connect to pre-existing applications that have REST or other APIs to either poll for updates or insert new records.
Prior to the 0.9 release of Kafka the only way to accomplish this was to write custom integration, using the producer or consumer apis, for each system you wanted to integrate. However this lead to lots of duplication: virtually every Silicon Valley startup put effort into integrating MySQL with Kafka to stream updates from their databases. Why not make these integrations reusable?
Starting with the 0.9 release Kafka comes with a framework for managing streaming connectors. This framework is called Kafka Connect. Connect provides a simple plug-in API for reading from source systems or writing to destination systems. By implementing this plug-in API you can create a reusable connector for that system or application that anyone can use.
Kafka Connect attempts to solve a number of the hard problems we saw people struggling with as they attempted to create one-off integrations:
- The connectors have a built-in scale-out model so you can easily connect very large scale systems like Hadoop or Cassandra without the integration itself becoming a bottleneck. You can do this dynamically without stopping your running connectors.
- The connectors are fault-tolerant: if one instance of a connector fails data won’t stop flowing, the other instances will detect this and pick up the work.
- Connect allows you to manage many such connections simply with an easy-to-use REST api. For example if you have connectors running for many database instances you can do this without having to manually run processes for each of these.
- Connect helps you to capture whatever metadata is present about data format. If your data is unstructured strings or bytes that is fine, but if you have richer structure such as you might find with a relational database this will be preserved by the connect framework.
A Connect instance connecting to a set of data systems might look like this:
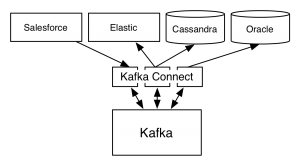
There are a few things to note in this diagram. The first is that the connectors scale over a collection of connect processes for fault-tolerance and scalability. The second is that connections to multiple systems, managing data flow both into and out of Kafka, can be managed in a single set of connect instances.
If you want to learn more about Connect you can read about it here.
7. Grokking the Stream Processing Landscape
There are a wide variety of technologies, frameworks, and libraries for building applications that process streams of data. Frameworks such as Flink, Storm, and Spark all have their pros and cons.
In the 0.10 release of Kafka we added the streams api which brings native stream processing capabilities to Kafka. This is a bit different from the existing frameworks. Rather than being a MapReduce-like framework for distributing and executing stream processing jobs, it is instead a simple library that brings state-of-the-art stream processing capabilities to normal Java applications. Applications that use this library can do simple transformations on data streams that are automatically made fault-tolerant and are transparently and elastically distributed over the instances of the application.
A streams application looks like this:
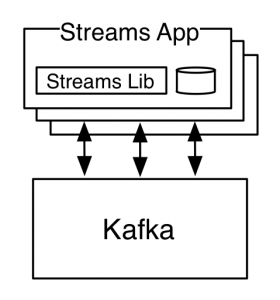
Note that the processes labelled “Streams App” are just instances of a normal Java application. They can be deployed and run just like any application would. What the streams library enables is maintaining the state and processing logic in a way that scales dynamically as instances of this application are added or instances die or are shut down.
Our goal with this API is to make stream processing simple enough that it can be a natural way of building asynchronous microservices that react to events, not just a heavy-weight “big data” thing.
Have Any Streaming Experiences to Share?
That is it for my current list of data stream do’s and don’ts. If you have additional recommendations to add to this, pass them on.
Meanwhile we’re working on trying to put a lot of these best practices into software as part of the Confluent Platform which you can find out more about here.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.