New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
How Storyblocks Enabled a New Class of Event-Driven Microservices with Confluent
In many ways, Storyblocks’ technical journey has mirrored that of most other startups and disruptors:
- Start small and as simple as possible (i.e., with a PHP monolith)
- Watch the company grow rapidly
- Experience serious growing pains that you try to patch up as best as you can by moving to microservices and REST APIs for interservice communication
- Finally realize that you need another way of doing things but want to avoid a complete rip and replace
For us, the other “way of doing things” for modernizing our monolith by fully decoupling our microservices was Apache Kafka® and Confluent Cloud.
Before we get there, though, let me tell you a little about Storyblocks. Founded in 2009, Storyblocks is now the fourth-fastest growing media company in the U.S. (ranked by Inc. Magazine). We’re the first unlimited download subscription-based provider of stock video and audio, claiming over 100,000 customers in the television and video production industry, including NBC and MTV, plus tens of thousands of hobbyists looking to enhance their video projects and productions.
It was in late 2016 when we had our “aha” moment (i.e., step 4 above) around needing a major architectural change. We were experiencing scaling challenges with our original monolithic application and so decided to split it into microservices. This choice led to mounting technical debt and massive entropy related to the synchronous REST API calls between the services.
Here’s the story of how Confluent allowed us to modernize our monolithic architecture; significantly reduce technical debt and TCO from REST APIs; and vastly improve data visibility, collection, and time needed to address production bugs, as well as create an event pipeline to power new use cases around machine learning and AI.
Our pre-Kafka microservices journey
In 2016, as part of our move from the PHP monolith to microservices, we decided to move our user accounts from their original MySQL databases to a centralized microservice.
At that time, all user account data for our three core websites (audioblocks.com, videoblocks.com, and storyblocks.com) lived in separate databases. So, if you signed up with your@email.com on VideoBlocks you’d have to sign up again to use AudioBlocks, and if you had accounts on both sites and updated your password on one of them, you’d have to deal with two different passwords. Not a great user experience.
Our solution was to consolidate all user accounts into a single microservice so that we could:
- Pay down technical debt caused by old code and hacked-together features
- Unlock in-product capabilities such as targeted upgrade offers
- Simplify the overall user experience
- Scale our infrastructure
- Shift to a unified representation of the user
![]()
The transition from separate databases to a single microservice.
The simplest approach to a microservice migration like this is to just build the service, temporarily shut down the production sites, import the data from the old databases to the microservice, and then turn the sites back on (what we called the “Big Bang” approach). However, we couldn’t do this for a couple of reasons:
- This refactor touched extremely high-risk business logic
- Though this was our first stateful microservice, we wanted to use a phased approach with zero downtime
And so we implemented a phased approach that consisted of the following phases:
- Refactor: Rewrite the monolith code so that all reads and writes to the data “domain” of the service have clean boundaries. This encapsulates all read/write logic in a single place and makes it easier to manage the hand-off between the original database and microservice.
- Write only: Write user data to the original database and also send it to the new service. Meanwhile, the original database remains the source of record for reading user data.
- Backfill: Import the data from the old service to the new microservice. While users created since phase 2 will have their information in the new service, pre-existing users will not. We’ll need their data before switching the source of record to the new service, and thus need to retroactively backfill older users.
- Attempt read: In the monolith, start attempting to read from the service. Log any data inconsistencies between the monolith and the service to help troubleshoot any bugs that pop up. Writes are still going to the monolith and it is still the source of record at this point, allowing you to fall back to the monolith database if need be.
- Read and write: Turn off writes and reads to the old database, completing the transition to the new service. The microservice is finally the source of record.
By activating writes and backfilling old records in the background, we achieved zero downtime for our production applications. Also, by creating an attempt-read phase, we could get a live preview of how the production sites are reading from the service. Response times, failed writes or reads, data integrity issues, etc., can all be troubleshot on the fly and in a low-risk environment.
However, this transition created new problems that eventually led us to the adoption of Kafka as a fully managed cloud-native service in Confluent Cloud.
Decoupling our microservices
For the first version of our re-architected stack, we used an AWS Kinesis data pipeline that dumped raw data into Amazon S3. This was our first use case to enable machine learning features and analysis of clickstream data. As a second use case, we also tried to use Kinesis for interservice communication between our microservices.
However, when we started trying to use this pipeline to add additional features, it quickly broke down. Schemas were not stored in a central location and registering a schema was an error-prone process that required manually running a custom Python script. Versioning was unenforced and unclear, custom infrastructure and code led to bugs and outages, schema validation was incomplete, backward-incompatible schemas changes broke downstream scripts, schema files were large and not human friendly, and invalid events were not discoverable until code was deployed to staging.
Developers found the system fragile and difficult to use, which created friction when creating new events or updating existing ones. Also, the system did not allow easy asynchronous communication between services. As a result, we were slow to track new data, slow to enhance existing data, and stuck in synchronous REST calls between our services. We could clearly see how this would lead to increasing technical debt over time.
We needed a better way to keep our microservices decoupled while avoiding the massive entropy incurred with REST API calls while using an event-driven architecture to feed data to S3. That’s when we started looking at Kafka.
We did a proof of concept using Kafka in conjunction with a schema registry from Aiven. After about six months, though, while we were in the process of filing multiple support tickets we realized Aiven wasn’t giving us the quality of support for Kafka that we needed. That’s when we switched over to Confluent Cloud, a fully managed cloud-native service for Kafka.
Simultaneously, we began trying to evangelize the use of Kafka as an event broker to build streaming applications and to serve our machine learning use case for clickstream data, and especially for this part of the architecture Confluent Cloud very quickly made a difference.
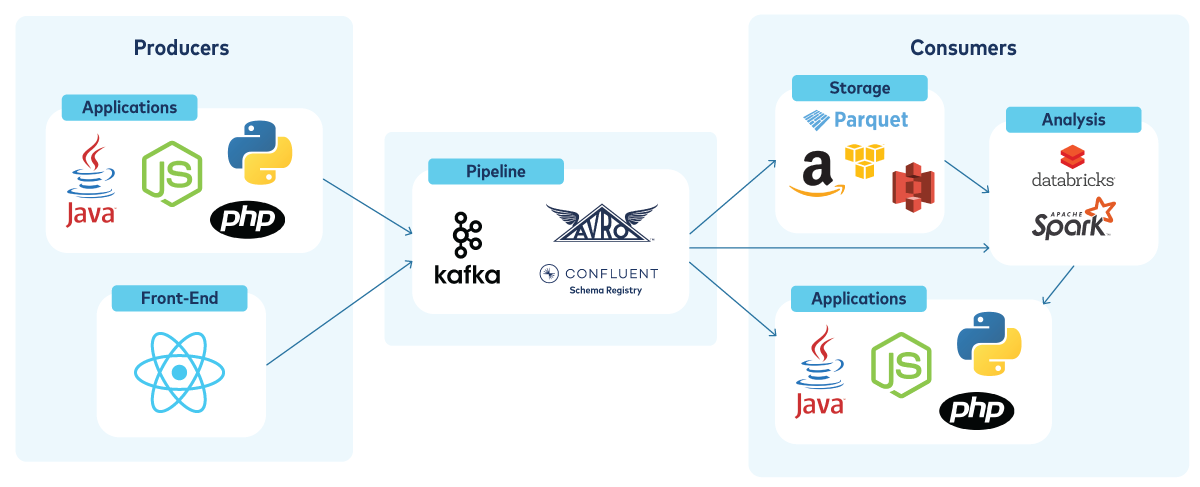
A high-level overview of our current data pipeline.
Just having one way of communicating was game-changing for us. We now had a single event pipeline that was flexible for every use case that we could use to absorb data and for microservices to communicate.
Confluent Cloud’s model lets us:
- Offload data collection to fully managed Kafka connectors.
- Offload the interservice communication between our microservices and fully decouple them. Without it, our teams would still be building REST API endpoints left and right.
- Use Infinite Storage, which allows data engineers the ability to “replay” old events into consumers while completely doing away with the time and effort needed to wrangle the original data.
Confluent Cloud also offers many cloud-native features that other hosted Kafka services lack, such as automated Kafka patching with zero downtime, capacity planning and sizing, load balancing, and elastic scaling without the overhead of dealing with ZooKeeper, partitions, and JVMs. All of these features significantly reduce our operational burdens so that our engineers can focus on what really matters to the business.
Powering our modernization journey from REST APIs to event-driven microservices with Confluent
Confluent is now the central pillar of our data infrastructure. Most of the data across our organization is being streamed on a central pipeline through Confluent. We have about 200 topics including everything from operational data (billing, user accounts) to analytical data (clickstream). Our engineers and data scientists use it as the means to communicate important business data, as well as a source of historical data for new use cases.
Take, for example, our billing event-driven microservice, which is responsible for billing our customers quickly and accurately. It is 100% Confluent-built and communicates with other microservices across our organization using events on our main event pipeline. Using Confluent Cloud’s fully managed Kafka service is great because we don’t need to hire additional data engineers or have the internal expertise to manage Kafka clusters.
Instead of implementing a message queue for interservice communication, the team can publish events into a Kafka topic where they can be stored forever, or until we decide we no longer need them. This sort of Infinite Storage, which comes built into Confluent Cloud, is powerful for two reasons:
- Events can be replayed on demand with powerful in-built schema validation. An anecdote that comes to mind is when our team found a bug that impacted users in our billing microservice after we implemented Confluent. With our old, pre-Kafka setup, it would have taken us a week to identify and resolve the issue with custom SQL queries to our production database. With Infinite Storage, it took our teams only a couple of days to not only resolve the issue in one of our consumer applications by changing the business logic in a safe and protected way, but also to validate the fix by replaying the same events where the original bug had been reported. The fact that all of this was possible without custom SQL queries or accessing our production database was an eye-opening experience that showed us the true potential of Confluent.
- Analysts sometimes look at historical data when answering various questions for the business. Its likely that at some point in the next six months some team in the business will have new questions about our content contributors’ historical behavior, and an analyst will ask to dig into our content service events. Before Confluent, that data would only have been accessible through random S3 buckets or with batch-based processes with significant effort.
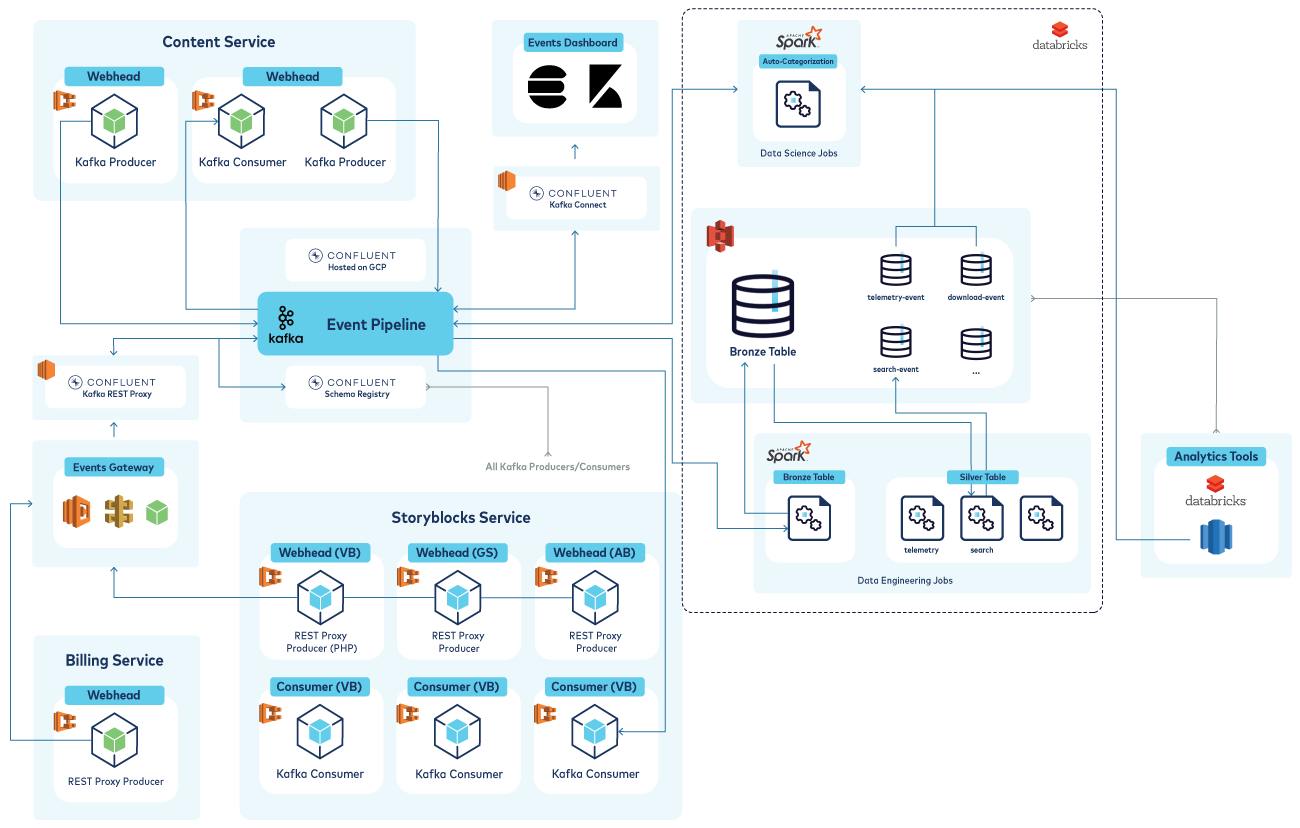
A more detailed diagram of our current pipelines, showing our current microservices (content, billing, and the original monolith) with their producers/consumers, our “events dashboard” (which is driven by Kafka Connect and Elasticsearch), and our data lake/data jobs infrastructure.
For example, we offer videos, and if our models analyze a video for specific features, that analysis is communicated on the pipeline. Engineers can then subscribe to it, and data scientists can forever see that this model predicted the features specified in the video within our data lake.
Tips for building event-driven microservices
Thanks to our technical journey with Storyblocks, we have some wisdom to share regarding transitioning to and building an event-driven microservices architecture. Here are some things to keep in mind if you’re starting out on a microservices journey.
1. Define your boundaries
You have to start by defining your data boundaries. There may not be a clear candidate for an event-driven microservice at first, so it’s good to pick one which may have incremental unlocks (for example, pull authentication into its own service while introducing SSO if your platform did not have it before, or, as in our case, the billing microservice) to keep it relevant to the business and get stakeholder buy-in.
2. Refactor (carefully)
Once you know the conceptual boundary, you likely have to refactor the original application to have clear service boundaries. It can really help to abstract the “service” into its own class/API which the rest of the code calls. From there, you can refactor the innards of that “service” without touching the rest of the monolith, and you can frequently merge/deploy your code to avoid long-running branches.
3. Use Kafka as an event bus for asynchronous inter-service communication
Kafka provides the means for services to asynchronously communicate with each other through topics. This architectural style pairs very well with microservice communication needs, where a single service can broadcast data for any number of consumers to use. This reduces the number of point-to-point connections, including technical debt and management overhead.
4. Be sure to save your data
Our last piece of advice here is to save all of your data! Pipe all service-to-service communication in Confluent so that your analysts have access to data on the inner-workings of your platform, historical data your analysts can leverage, your engineers can more easily hunt down production bugs, and you can fix bugs by simply replaying messages into consumers. You can also store data in a data lake but typically this data is’nt stored in a structured schema in a lake and requires additional steps to access and format the data into a usable format.
Bottom line: If we could go back in time, we would use Confluent instead of REST APIs while modernizing our PHP monolith to eliminate a step in our modernization journey.
Learn more about using Confluent to enable an event-driven microservices architecture, or get started with a free trial of Confluent Cloud and use the code CL60BLOG for an additional $60 of free usage.*





