New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Confluent at a Fully Disconnected Edge
Internet connectivity is something we sometimes take for granted. For many, most places we visit, work, or reside have some form of connectivity whether it be cellular, Wi-Fi, fiber, etc. So it’s not everyday we have to think about designing for a system that needs to be deployed in a remote area. To be fair, not every system needs internet connectivity. There are many networks today that operate locally in the environment in which they are deployed, such as mining sites in the mountains, oil rigs far from the coasts, and isolated farm fields. Up until recently, organizations that collect terabytes or even petabytes of data in secluded sites have had to simply accept that, due to the lack of connectivity, they are unable to move large volumes of data from partially or fully disconnected remote locations consistently, reliably, and at petabyte scale.
By leveraging Confluent Platform and AWS Snowball, data once stranded at the edge can now be uploaded to the cloud, democratized across departments and other lines of business, and used for better informed decision making and optimized operations. To help you get started, this blog will walk you through the steps required to set up Apache Kafka® at the edge using Confluent and AWS Snowball Edge.
Why AWS Snowball Edge?
There are many options with which one can run Confluent Platform: an on-prem bare metal server, a Raspberry Pi, a Docker container in the cloud, an EC2 instance, to name a few. That’s what makes Confluent a solution that is truly everywhere. Among these options is Snowball Edge—AWS’ edge device with on-board storage, compute power for select AWS capabilities, and the ability to transfer data between your local environment and the AWS Cloud. On top of having a rugged design and ideal specifications for hosting Apache Kafka, AWS completely handles logistics such as imaging, shipping, and syncing locally stored data to the cloud. With all of these aspects managed on your behalf, you get to focus on what matters most to you: Apache Kafka at the edge.
Implementation
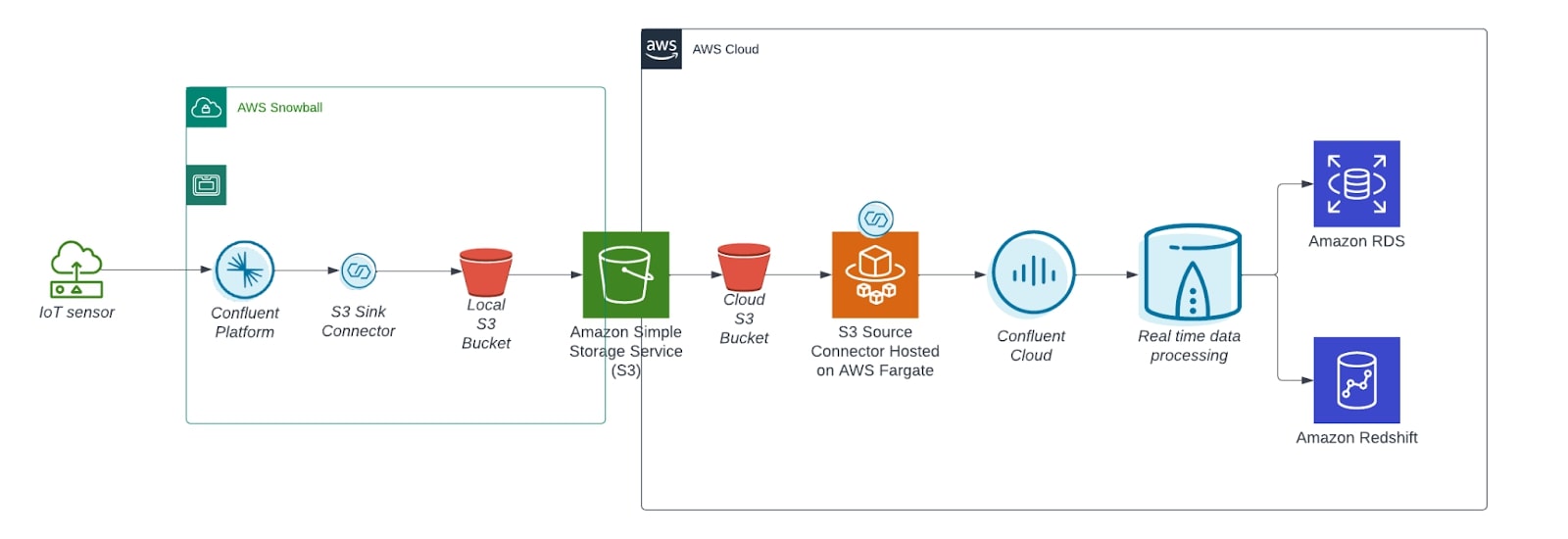
Sample architecture for rescuing data at the edge using AWS Snowball and Confluent
Preparation
Deploy the S3 connector
AWS gets your data from Snowball and into the cloud (specifically into the S3 bucket you designate) for you. However, there is some setup required to get your S3 data into your Confluent Cloud cluster. Luckily, Confluent has a pre-built connector that you can deploy before ordering a Snowball Edge Device so that the connector is ready to instantly read data as it is uploaded to your bucket in AWS. For this example, we chose to leverage AWS Fargate to deploy the S3 source connector. AWS Fargate is a technology that provides on-demand, right-sized compute capacity for containers. You don’t have to provision, configure, or scale groups of virtual machines on your own to run containers. You also don’t need to choose server types, decide when to scale your node groups, or optimize cluster packing. In other words, a self-managed connector on EKS Fargate makes for a serverless connector experience. To do this, follow the full walk-through to set up self-managed connectors on EKS Fargate. Alternatively, you can use the fully managed S3 Source connector for a further abstracted experience.
Prepare an image
Since AWS handles imaging using AMIs, you need to create the image to be provided and installed on the device. This step only needs to be performed during initial setup or when you want to update the Confluent Platform version. Otherwise, the same image can be used repeatedly across each Snowball deployment.
- Spin up an EC2 instance in your AWS environment.
- When the instance is ready, follow the Quick Start guide for installing and running Confluent Platform.
- Set up the S3 Sink connector so that Confluent Platform can move data from topics into the local S3 bucket on the Snowball.
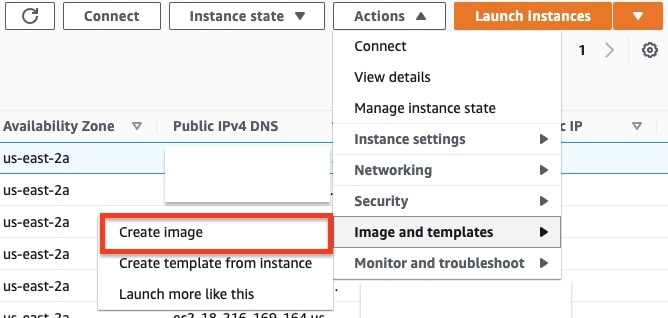
- After installing the necessary components and packages, navigate to the EC2 dashboard. Select the EC2 instance and click the “Actions” button. Click “Image and templates” and then “Create Image.” It should take anywhere between five and 15 minutes for your image to complete. Once the image is ready, you may move on to the next step.
Deploy Confluent on Snowball Edge
Order the Snowball Device
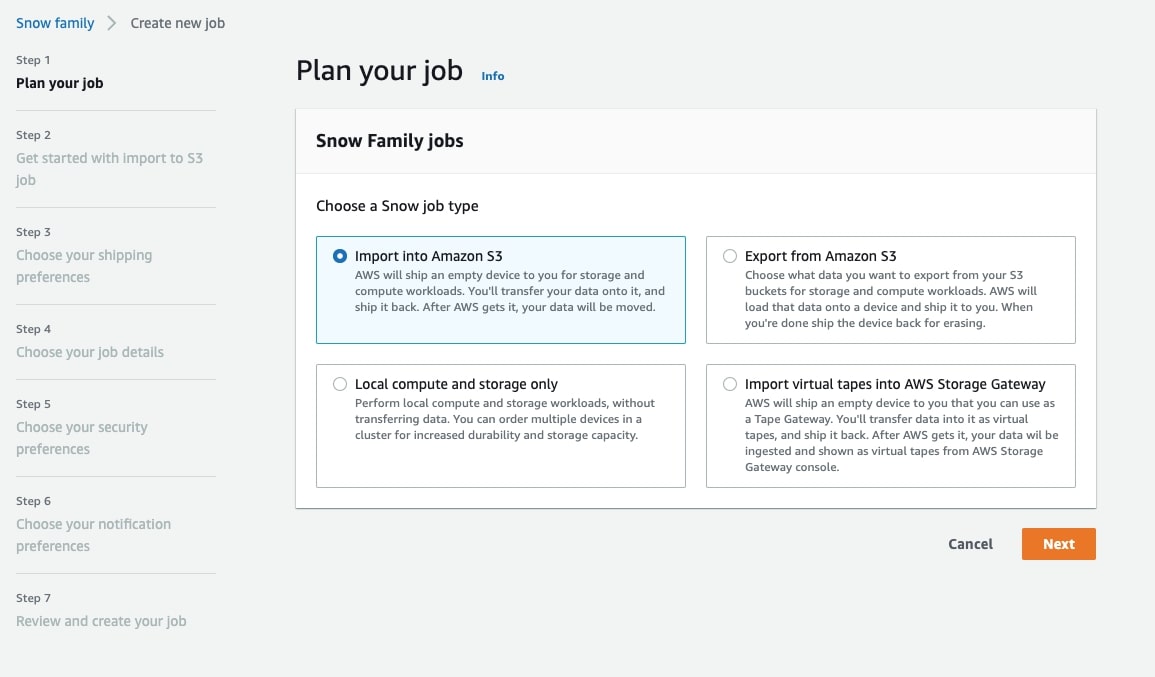
With the image prepared and your connector set up, you are ready to order a Snowball Edge device. In the AWS console, search for “AWS Snow Family.” For the Snow job type, select “Import into Amazon S3.” This lets AWS know to upload data stored in your topics into the cloud.
From there, complete the rest of the form according to your requirements such as selecting an appropriate device type, choosing your encryption, providing the prepared image with Confluent Platform already installed, and an address to which the device can be sent. Here are some things to consider as you complete the form:
- Review the AWS guidelines and limitations for Snowball shipping to ensure your location is covered
- For most use cases, compute optimized will be the best device type, but if you are going to use more than 39.5 TB data between swapping out devices you might consider storage optimized
Field deployment
The moment your device arrives, it can be deployed into the field without further configuration: no installs or updates, assuming you provided an up-to-date image with appropriate libraries and Confluent Platform. The Snowball Edge device can be brought to the oil rig, a mining area, or any other possible worksite location to serve an asynchronous gateway collecting data from various sources. You simply need to point far-edge devices (sensors, thermometers, video streams, etc.) to the appropriate topics on your Snowball Edge device.
For further ease, it might be more prudent to create EC2 instances to retain up-to-date images of the entire cluster to be deployed in your field. For example, you could set up multiple instances of ZooKeeper and brokers that have components and setup relevant to your cluster setup. This way, when you deploy the cluster, you can easily run a few test messages the same way you would in the cloud, and ensure everything is set up correctly.
Rotation scheduling
As devices send their data to the topics on the Snowball Edge device, Confluent Platform will dump all events to its local S3 bucket using the S3 Sink connector. By setting a rotation schedule, a fresh device can be ordered, delivered, and deployed while the filled device is brought back to base camp and returned to AWS. Stored data is transferred to the designated S3 bucket by AWS and then securely removed from the device while the newly uploaded data is imported into your Confluent Cloud instance by the S3 Source connector deployed in the previous section. With proper timing, your disconnected Kafka cluster data can be connected and uploaded to the cloud in batches without missing a packet.
Data processing
With ksqlDB, developers can create stream processing applications on top of Kafka on Confluent Platform, Confluent Cloud, or a combination of both. If you know beforehand how you want your data processed, you can have the processing occur at the edge before it is synced into the local S3 bucket (given you have spare compute on your Snowball instance). This will ultimately reduce costs since such processing won’t have to be done in the cloud. The beauty of this hybrid approach is that even if you don’t know what your data processing needs are at first, or those needs change, or at a later point in time you have additional uses for that data, you can use ksqlDB in Confluent Cloud to discover and explore how your data can be transformed. Then, once you figure out the new ksqlDB queries, you can decide to keep them in the cloud or move them to the edge on the Snowball device to handle such processing. This flexibility allows you to find your preferred balance of cost optimization and data availability.
Provide your new data to your existing or new applications
From the faraway fields and distant mountains to your Confluent Cloud cluster on AWS, your data has traveled a long way. You rescued and prepared the data, now all that remains is to share it with your existing and new applications while keeping the Confluent cluster as the single source of truth. At this point, you should be familiar with Confluent’s connectors as they are used both on Snowball Edge to get data into the local S3 bucket and in AWS as you source from the synced S3 bucket. As your applications need data, you can similarly sync data into other AWS services such as RDS, RedShift, and DynamoDB, many of which are fully managed and can be deployed with a few clicks. For a full list, please visit the connectors portfolio.
Other considerations
Here are a few other final considerations for this approach:
- Review the AWS policy on where the Snowball Edge device can be dropped off or picked up. This information should be taken into consideration when planning out your Snowball Edge rotation schedule.
- For larger operations that produce extensive amounts of data, more than one Snowball Edge device can be ordered. In such scenarios, each Snowball device can collect specific device data, e.g., all temperature and humidity sensors will deliver data to topics on Snowball A while all motion sensors and air quality sensors deliver their data to topics on Snowball B.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.