New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Data Reprocessing with the Streams API in Kafka: Resetting a Streams Application
This blog post is the third in a series about the Streams API of Apache Kafka, the new stream processing library of the Apache Kafka project, which was introduced in Kafka v0.10.
Current blog posts in the Kafka Streams series:
- Elastic Scaling in the Streams API
- Secure Stream Processing with the Streams API in Kafka
- Data Reprocessing with the Streams API in Kafka: Resetting a Streams Application (this post)
In this blog post we describe how to tell a Streams API in Kafka application to reprocess its input data from scratch. This is actually a very common situation when you are implementing stream processing applications in practice, and it might be required for a number of reasons, including but not limited to: during development and testing, when addressing bugs in production, when doing A/B testing of algorithms and campaigns, when giving demos to customers or internal stakeholders, and so on.
The quick answer is you can do this either manually (cumbersome and error-prone) or you can use the new application reset tool for the Streams API, which is an easy-to-use solution for the problem. The application reset tool is available starting with upcoming Confluent Platform 3.0.1 and Apache Kafka 0.10.0.1.
In the first part of this post we explain how to use the new application reset tool. In the second part we discuss what is required for a proper (manual) reset of a Streams API application. This parts includes a deep dive into relevant Streams API internals, namely internal topics, operator state, and offset commits. As you will see, these details make manually resetting an application a bit complex, hence the motivation to create an easy to use application reset tool.
Using the Application Reset Tool
Example application
As a running example we assume you have the following Streams API in Kafka application, and we subsequently demonstrate (1) how to make this application “reset ready” and (2) how to perform an actual application reset.
This application reads data from the input topic “my-input-topic”, then selects a new record key, and then writes the result into the intermediate topic “rekeyed-topic” for the purpose of data re-partitioning. Subsequently, the re-partitioned data is aggregated by a count operator, and the final result is written to the output topic “my-output-topic”. Note that in this blog post we don’t put the focus on what this topology is actually doing — the point is to have a running example of a typical topology that has input topics, intermediate topics, and output topics.
Step 1: Prepare your application for resets
The first step is to make your application “reset ready”. For this, the only thing you need to do is to include a call to KafkaStreams#cleanUp() in your application code (for details about cleanUp() see Section ”Application Reset Tool Details”).
Calling cleanUp() is required because resetting a Streams applications consists of two parts: global reset and local reset. The global reset is covered by the new application reset tool (see “Step 2”), and the local reset is performed through the Kafka Streams API. Because it is a local reset, it must be performed locally for each instance of your application. Thus, embedding it in your application code is the most convenient way for a developer to perform a local reset of an application (instance).
At this point the application is ready for being reset (when needed), and you’d start one or multiple instances of your application as usual, possibly on different hosts.
Step 2: Reset the application
So what would we need to do to restart this application from scratch, i.e., not resume the processing from the point the application was stopped before, but rather to reprocess all its input data again?
First you must stop all running application instances and make sure the whole consumer group is not active anymore (you can use bin/kafka-consumer-groups to list active consumer groups). Typically, the consumer group should become inactive one minute after you stopped all the application instances.This is important because the reset behavior is undefined if you use the reset tool while some application instances are still running — the running instances might produce wrong results or even crash.
Once all application instances are stopped you can call the application reset tool as follows:
As you can see, you only need to provide the application ID(“my-streams-app”) as specified in your application configuration, and the names of all input and intermediate topics. Furthermore, you might need to specify Kafka connection information (bootstrap servers) and Zookeeper connection information. Both parameters have default values localhost:9092 and localhost:2181, respectively. Those are convenient to use during development with a local single Zookeeper/single broker setup. For production/remote usage you need to provide appropriate host:port values.
Once the application reset tool has completed its run (and its internal consumer is not active anymore), you can restart your application as usual, and it will now reprocess its input data from scratch again. We’re done!
It’s important to highlight that, to prevent possible collateral damage, the application reset tool does not reset the output topics of an application. If any output (or intermediate) topics are consumed by downstream applications, it is your responsibility to adjust those downstream applications as appropriate when you reset the upstream application.
Use application reset tool with care and double-check its parameters:If you provide wrong parameter values (e.g. typos in application.id) or specify parameters inconsistently (e.g. specifying the wrong input topics for the application), this tool might invalidate the application’s state or even impact other applications, consumer groups, or Kafka topics of your Kafka cluster.
As we have shown above, using the new application reset tool you can easily reprocess data from scratch with the Streams API. Perhaps somewhat surprisingly, there’s actually a lot going on behind the scenes to make application resets work as easily. The following sections are a deep dive on these internals for the curious reader.
Behind the Scenes of the Streams API in Kafka
In this second part of the blog post we discuss those Kafka Streams internals that are required to understand the details of a proper application reset. Figure 1 shows a Kafka Streams application before its first run. The topology has as single input topic with two partitions. The current offset of each partition is zero (or there is no committed offsets and parameter auto.offset.reset = earliest is used). Also the topology writes into a single output topic with two partitions which are both empty. No offsets are shown as output topics are not consumed by the application itself. Furthermore, the topology contains a call to through(), thus, it writes/reads into/from an additional (intermediate) topic with two empty partitions and it contains a stateful operator.
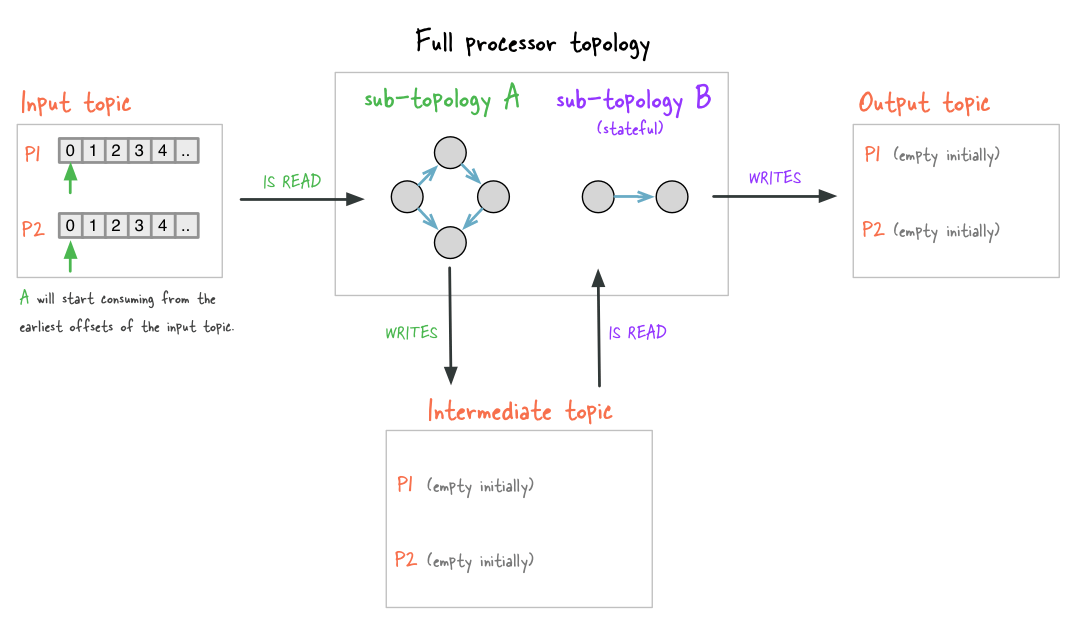
Figure 1: An example application before its first run (input offsets are zero, empty intermediate and output topic, no state).
After the Streams API in Kafka application was executed and stopped, the application state changed as shown in Figure 2. In the following we discuss the relevant parts of Figure 2 with regard to reprocessing.
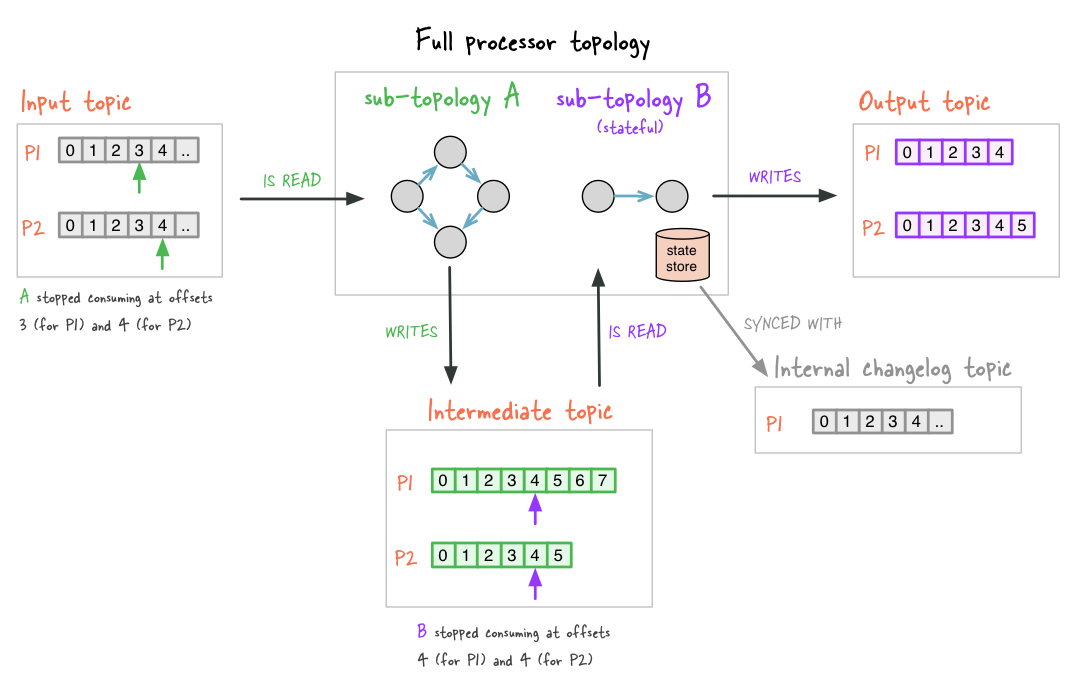
Figure 2: The application after it was stopped. The small vertical arrows denote committed consumer offsets for the input and intermediate topics (colors denote the corresponding sub-topology). You can see, for example, that sub-topology A has so far written more data to the intermediate topic than sub-topology B has been able to consume (e.g. the last message written to partition 1 has offset 7, but B has only consumed messages up to offset 4). Also, sub-topology performs stateful operations and thus has created a local state store and an accompanying internal changelog topic for this state stores.
Reprocessing Input Topics
The Streams API in Kafka builds upon existing Kafka functionality to provide scalability and elasticity, security, fault-tolerance, and more. For reprocessing input topics from scratch, one important concern is Kafka Streams’ fault-tolerance mechanism. If an application is stopped and restarted, per default it does not reread previously processed data again, but it resumes processing where it left off when it was stopped (cf. committed input topic offsets in Figure 2). Internally, the Streams API leverages Kafka’s consumer client to read input topics and to commit offsets of processed messages in regular intervals (see commit.interval.ms). Thus, on restart an application does not reprocess the data from its previous run. In case that a topic was already processed completely, the application will start up but then be idle and wait until new data is available for processing. So one of the steps we need to take care of when manually resetting an application is to ensure that input topics are reread from scratch. However, this step alone is not sufficient to get a correct reprocessing result.
Sub-Topologies and Internal State in the Streams API in Kafka
First, an application can consist of multiple sub-topologies that are connected via intermediate or internal topics (cf. Figure 2 with two sub-topologies A and B). In the Streams API, intermediate topics are user-specified topics that are used as both an input and an output topic within a single application (e.g., a topic that is used in a call to through()). Internal topics are those topics that are created by the Streams API “under the hood” (e.g., internal repartitioning topics which are basically internal intermediate topics).
If there are multiple sub-topologies, it might happen that an upstream sub-topology produces records faster into intermediate topics than a downstream sub-topology can consume (cf. committed intermediate topic offsets in Figure 2). Such a consumption delta (cf. the notion of consumer lag in Kafka) within an application would cause problems in the context of an application reset because, after an application restart, the downstream sub-topology would resume reading from intermediate topics from the point where it stopped before the restart. While this behavior is very much desired during normal operations of your application, it would lead to data inconsistencies when resetting an application. For a proper application reset we must therefore tell the application to skip to the very end of any intermediate topics.
Second, for any stateful operation like aggregations or joins, the internal state of these operations is written to a local state store that is backed by an internal changelog topic (cf. sub-topology B in Figure 2). On application restart, the Streams API “detects” these changelog topics and any existing local state data, and it ensures that the internal state is fully built up and ready before the actual processing starts. To reset an application we must therefore also reset the application’s internal state, which means we must delete all its local state stores and their corresponding internal changelog topics.
If you are interested in more details than we could cover in this blog post, please take a look atThe Streams API in Kafka: Internal Data Managementin the Apache Kafka wiki.
Resetting a Streams API in Kafka Application Manually
In order to reprocess topics from scratch, it is required to reset the application state that consists of multiple parts as described above:
- committed offsets of input topics
- committed offsets of intermediate topics
- content and committed offsets of internal topics
- local state store
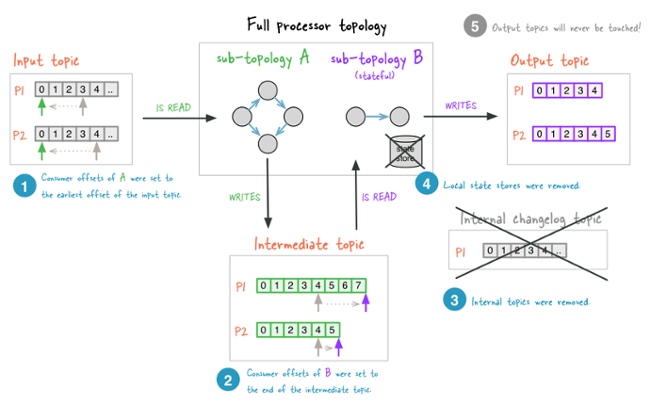
Figure 3: The application after reset: (1) input topic offsets were reset to zero (2) intermediate topic offsets were advanced to end (3) internal topics were deleted (4) any local state stores were deleted (5) the output topic was not modified.
Committed offsets of input topics: Internally, Kafka Streams leverages Kafka’s consumer client to read a topic and to commit offsets of processed messages in regular intervals (see commit.interval.ms). Thus, as a first step to reprocess data, the committed offsets need to be reset. This can be accomplished as follows: Write a special Kafka client application (e.g., leveraging Kafka’s Java consumer client or any other available language) that uses the application.id of your Kafka Streams application as its consumer group ID. The only thing this special client application does is to seek to offset zero for all partitions of all input topics and commit the offset (you should disable auto commit for this application). As this special application uses the same group ID as your Kafka Streams application (the application ID is used a consumer group ID internally), committing all offsets to zero allows your Streams application to consume its input topics from scratch when it is started again (cf. #1 in Figure 3).
Intermediate topics: For intermediate topics we must ensure to not consume any data from previous application runs. The simplest and recommended way is to delete and recreate those intermediate topics (recall that it is recommended to create user-specified topics manually before you run a Kafka Streams application). Additionally, it is required to reset the offsets to zero for the recreated topics (same as for input topics). Resetting the offsets is important because the application would otherwise pick up those invalid offsets on restart.
As an alternative, it is also possible to only modify the committed offsets for intermediate topics. You should consider this less invasive approach when there are other consumers for intermediate topics and thus deleting the topics is not possible. However, in contrast to modifying the offsets of input topics or deleted intermediate topic, the offsets for kept intermediate topics must be set to the largest value (i.e., to the current log-size) instead of zero, thus skipping over any not-yet consumed data. This ensure that, on restart, only data from the new run will be consumed by the application (cf. #2 in Figure 3). This alternative approach is used by the application reset tool.
Internal topics: Internal topics can simply be deleted (cf. #3 in Figure 3). As those are created automatically by Kafka Streams, the library can recreate them in the reprocessing case. Similar to deleting intermediate user topics, make sure that committed offsets are either deleted or set to zero.
In order to delete those topics, you need to identify them. Kafka Streams creates two types of internal topics (repartitioning and state-backup) and uses the following naming convention (this naming convention could change in future releases however, which is one of the reasons we recommend the use of the application reset tool rather than manually resetting your applications):
- <applicationID>-<operatorName>-repartition
- <applicationID>-<operatorName>-changelog
For example, our demo application from the beginning (with application ID “my-streams-app”)
creates the internal topic my-streams-app-global-count-changelog because the countByKey() operator’s name is specified as “global-count”.
Local State Stores: Similar to internal topics, local state stores can just be deleted (cf. #4 in Figure 3). They will be recreated automatically by Kafka Streams. All state of an application (instance) is stored in the application’s state directory (cf. parameter state.dir, with default value /var/lib/kafka-streams in Confluent Platform releases and /tmp/kafka-streams for Apache Kafka releases). Within the state store directory, each application has its own directory tree within a sub-folder that is named after the application ID. The simplest way to delete the state store for an application is therefore rm -rf <state.dir>/<application.id> (e.g., rm -rf /var/lib/kafka-streams/my-streams-app).
After this discussion, we see that manually resetting a Stream application is cumbersome and error-prone. Thus, we developed the new “Application Reset Tool” to simplify this process.
Application Reset Tool Details
In more detail, the application reset tool (bin/kafka-streams-application-reset) performs the following actions (cf. Figure 3):
- for any specified input topic, it resets all offsets to zero
- for any specified intermediate topic, seeks to the end for all partitions
- for all internal topic
- resets all offsets to zero
- deletes the topic
To use the script, as a minimum you need to specify the application ID. For this case, only internal topics will be deleted. Additionally, you can specify input topics and/or intermediate topics. More details about resetting a Streams application, can be found in the Confluent documentation.
Pay attention, that the application reset tool only covers the “global reset” part. Additionally, to the global reset, for each application instance a local reset of the application state directory is required, too. (cf. #4 in Figure 3) This can be done directly within your application using the method KafkaStreams#cleanUp(). Calling cleanUp() is only valid as long as the application instance is not running (i.e., before start() or after close()).
Because resetting the local state store is embedded in your code, there is no additional work to do for local reset — local reset is included in restarting an application instance. For global reset, a single run of the application reset tool is sufficient.
What About Resetting an Application by Giving it a New application.id?
Before we close we want to discuss what happens when you configure your Kafka Streams application to use a new application ID. Until now this has been a common workaround for resetting an application manually.
On the positive side, renaming the application ID does cause your application to reprocess its input data from scratch. Why? When a new application ID is used, the application does not have any committed offsets, internal topics, or local state associated with itself, because all of those use the application ID in some way to get linked to a Kafka Streams application. Of course, you also need to delete and recreate all intermediate user topics.
So why all the fuss about resetting a Kafka Streams application if we could use this workaround?
First, resetting an application is more than just enabling it to reprocess its input data. An important part of the reset is to also clean-up all internal data that is created by a running application in the background. For example, all the internal topics (that are no longer used) consume storage space in your Kafka cluster if nobody deletes them. Second, the same clean-up must be performed for data written to the local state directories. If not explicitly deleted, disk storage is wasted on those machines that hosted an application instance. Last but not least there is all kind of metadata like topic names, consumer groups, committed offsets that are not used any more and linger around. For those reasons, using a new application ID is considered nothing more than a crude workaround to reset a Kafka Streams application, and we wouldn’t recommend its use for production scenarios.
One more hint at the end: if you do not use a Kafka Streams application anymore (e.g., it gets replaced by a new version of the application or is just not longer needed), we recommend to run the reset tool once to clean-up all the left-overs of the retired application.
Summary
In this post, we introduced the new and easy-to-use application reset tool for the Streams API in Kafka. We discussed how to use the tool to reset your Kafka Streams application for reprocessing its input data from scratch. In the second part we dived into the Streams API in Kafka internals to explain why resetting a Streams application manually is cumbersome and how the application reset tools actually works.
So please try it out and enjoy the new tool! We appreciate any feedback of yours, e.g., via the CP mailing list or the Apache Kafka mailing lists (user@kafka.apache.org, dev@kafka.apache.org).
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.