New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Atomic Tessellator: Revolutionizing Computational Chemistry with Data Streaming
Computational chemistry relies on large volumes of complex data in order to provide insights into new applications, whether it’s for electric vehicles or new battery development. With the emergence of generative AI (GenAI), the rapid, scalable processing of this data has become possible and critical to investigate previously unexplored areas in catalysis and materials science. One company that’s applying GenAI to computational chemistry is Atomic Tessellator, a New Zealand-based startup and finalist in Confluent’s inaugural Data Streaming Startup Challenge. With Confluent sitting at the core of their data infrastructure, Atomic Tessellator provides a powerful platform for molecular research backed by computational methods, focusing on catalyst discovery. Read on to learn how data streaming plays a central role in their technology.
The problem: huge, siloed databases and legacy messaging
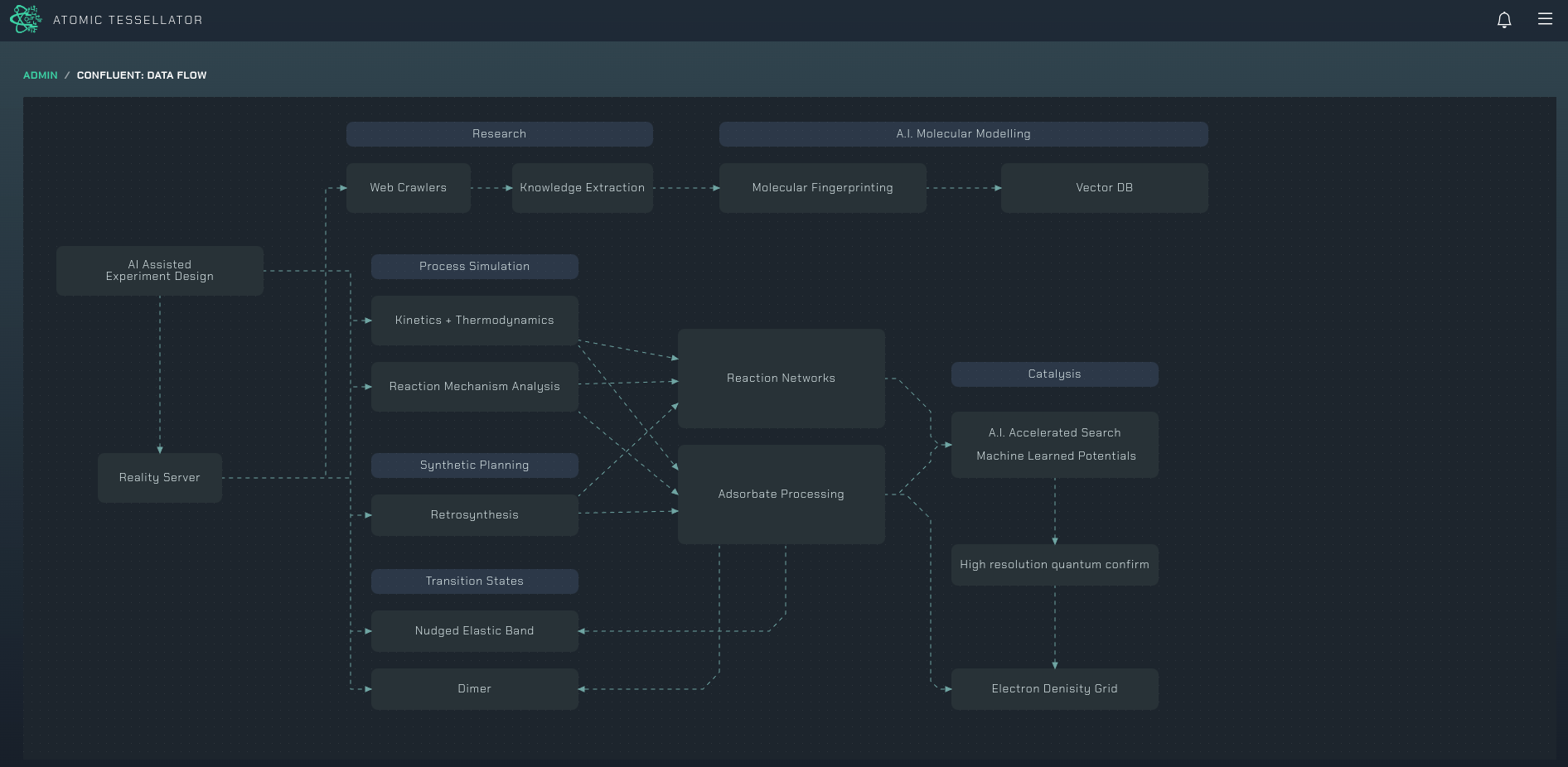
Molecular research consists of two processes: search and evaluation. The search element involves exploring huge databases of molecular structures or configurations and identifying candidates (i.e., for a specific aim, such as testing the performance characteristics of a material for a relevant application). The evaluation step then applies filtering methods and quantum chemistry calculations to these candidates and surfacing results.
The traditional data infrastructure and tooling underpinning these processes is slow, siloed, incompatible, and fragile. The source databases are large (i.e., billions of records) and contain multitudes of file types (e.g., HD5 and SDF), often with 10,000s of dimensions which is orders of magnitude more challenging than the requirements of most industries. Atomic Tessellator has possibly the largest collection of theoretical and experimental catalyst datasets in the world.
Prior to adopting data streaming, Atomic Tessellator relied on batch-based ETL using RabbitMQ, Celery, and a Django app to retrieve molecular data from its databases. While the setup was functional, it was far from ideal; the team had to spend a significant amount of time on state maintenance and manually provisioning compute resources to deal with variable workloads. If there was a failure, it took a long time to figure out what had caused it. Ultimately, this resulted in a data infrastructure that was slow and cumbersome to maintain—a barrier to the rapid processing of huge volumes of the data that was needed.
The solution: GenAI and data streaming
In order to create a more flexible, scalable platform, Atomic Tessellator turned to Confluent and Apache Kafka®.
Atomic Tessellator uses AI to push volumes of complex molecular data from various databases and generative models into Confluent, and from there streams the data to a downstream “evaluation” application to quickly and reliably replicate chemical reactions in order to discover new catalysts with high commercial value. Experiments are also augmented with LLMs so that the vast amount of the experiment design, execution, and debugging is done automatically.
Business benefits
With a data streaming architecture built on Kafka, Atomic Tessellator is able to scale their pipelines to meet the temporary demands of experiments, avoiding the need to over-provision compute resources. They’re also able to tweak components of their pipelines midway through a workload, rather than disrupt or redeploy it; if generative components are emitting too many similar results, for instance, they can alter the “entropy injection rate” in order to increase candidate diversity (i.e., improving the quality of the experiment) in the moment.
What’s more, the team has clear visibility over the status of their production pipelines. The ability to inspect data streams in real time via JMX (e.g., throughputs, latencies, durability, and availability) allows them to develop faster and shorten the time to market for new applications.
As the team innovates further, they plan to utilize the full capabilities of Confluent’s data streaming platform. Over the next year, for instance, they’re exploring the use of Apache Flink® in building out a new “pipeline templates” system, which functions as a turnkey set of common simulation configurations.
Summary: Blazing a trail in computational chemistry, powered by Confluent
By moving away from legacy messaging technologies and toward data streaming with Confluent, Atomic Tessellator has been able to build a computational chemistry platform that is fast, reliable, and flexible. They can deploy streaming data pipelines in minutes (rather than days or weeks), sync complex molecular data into downstream evaluation applications, and rapidly integrate new, innovative services into their platform (e.g., Fig. 2. – a custom LLM-powered electron density simulation, which generates quantum chemistry input files into an interactive 3D image). With Confluent as the backbone of their data infrastructure, Atomic Tessellator has developed a powerful platform to facilitate the rapid discovery of new catalysts for a wide range of industries.
Further resources
Webpage: Generative Artificial Intelligence (GenAI) | Confluent
Website: Atomic Tessellator
Did you like this blog post? Share it now
Subscribe to the Confluent blog


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


{kind=link}
Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.