New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Announcing the Confluent Platform 1.0
We are very excited to announce general availability of Confluent Platform 1.0, a stream data platform powered by Apache Kafka, that enables high-throughput, scalable, reliable and low latency stream data management.
The Confluent Platform
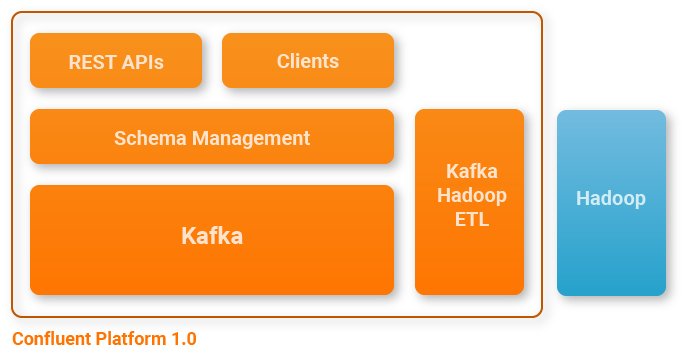
This platform enables you to manage the barrage of data generated by your systems and makes it all available in realtime, throughout your organization. At its core lies Apache Kafka, as well as additional components and tools that help you put Kafka to use effectively in your organization.
Confluent Platform 1.0 includes:
- Apache Kafka: The Confluent Platform has Apache Kafka at its core and ships with a Kafka distribution that is completely compatible with the latest release of Kafka – 0.8.2.0 in open source, and has a few critical patches applied on top of 0.8.2.0.
- Schema Management Layer: All Confluent Platform components use a schema management layer that ensures data compatibility across applications and over time as data evolves.
- Improved Client Experience: Confluent Platform provides Java as well as REST clients that integrate with our schema management layer. The Java clients use a serializer that ships with the Confluent Platform to integrate with the schema management layer. Non-java clients can use the REST APIs to send either Avro or binary data to Kafka.
- Kafka to Hadoop ETL: Confluent Platform also includes Camus, which provides a simple, automatic and reliable way of loading data into Hadoop.
How Do I Get It?
Today, we are also posting a two-part guide that walks you through the motivation and steps for using such a stream data platform in your organization. You can also learn more about the details of the Confluent Platform or give it a spin.
We have a public mailing list and forum to discuss these tools and answer any questions, and we’d love to hear feedback from you.
What’s Next?
Before founding Confluent, we spent five years at LinkedIn turning all data they had into realtime streams. Every click, search, recommendation, profile view, machine metric, error and log entry was available centrally in realtime. Part of that process was building a powerful set of in-house tools around our open source efforts in Apache Kafka that comprised LinkedIn’s stream data platform. We got to witness the impact of this transition and want to make this possible for every company in the world. We think the rise of real-time streams represents a huge paradigm shift for how companies can use their data. Kafka’s impressive adoption is evidence for this, but there is a lot left to do.
Today’s announcement is just the first step towards realizing this stream data platform vision. We look forward to building the rest of it in the months and years ahead. Stay tuned for more announcements from us.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.