Announcing ksqlDB 0.19.0
We’re pleased to announce ksqlDB 0.19.0! This release includes a new NULLIF function and a major upgrade to ksqlDB’s data modeling capabilities—foreign-key joins. We’re excited to share this highly requested feature with you and will cover the most notable changes in this blog post, but check out the changelog for a complete list of features and fixes.
Foreign-key table-table joins: The new kid on the block
ksqlDB 0.19.0 adds support for foreign-key joins between tables. Data decomposition into multiple tables (i.e., schema normalization) is a key strength of the relational data model and often requires joining tables based on a foreign key. So far, we have been able to provide tools for normalizing data, provided the rows in each of the tables followed a one-to-one relationship (i.e., have the same primary key).
Providing built-in support for foreign-key joins, which was previously only possible to do through workarounds, unlocks many new use cases where you’d like to have a many-to-one relationship between your tables. This is a highly demanded feature, and we are excited to finally make it available.
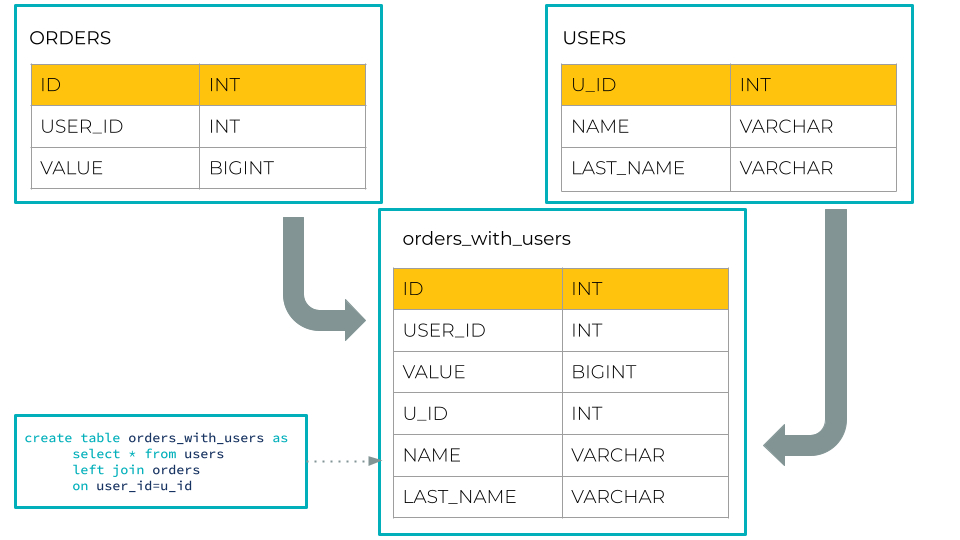
How does it work? Well, there is no new syntax required. You can specify any left-hand table column in the join condition to express a match against the primary key of the right-hand table. You can think of the left table as a fact table and the right table as a dimension table:
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
value INT
) WITH (
KAFKA_TOPIC = 'my-orders-topic',
VALUE_FORMAT = 'JSON',
PARTITIONS = 2
);
CREATE TABLE users (
u_id INT PRIMARY KEY,
name VARCHAR,
last_name VARCHAR
) WITH (
KAFKA_TOPIC = 'my-users-topic',
VALUE_FORMAT = 'JSON',
PARTITIONS = 3
);
CREATE TABLE orders_with_users AS
SELECT * FROM orders JOIN users ON user_id = u_id
EMIT CHANGES;
INSERT INTO orders (id, user_id, value) VALUES (1, 1, 100);
INSERT INTO users (u_id, name, last_name) VALUES (1, 'John', 'Smith');
Note that the ON clause uses a non-key column on the left-hand side instead of the primary key of the left input table. The result table will inherit the primary key of the left input table:
ORDERS_WITH_USERS <ID INT PRIMARY KEY, USER_ID INT, VALUE BIGINT, U_ID INT, NAME VARCHAR, LAST_NAME VARCHAR>
Similar to primary-key table-table joins, each time the left or right input table is updated, the result table will be updated accordingly. Because a foreign-key join is a many-to-one join, an update to the right input table may result in an update to multiple rows in the result table; an update to the left input table will trigger a single row update to the result table similar to primary-key table-table joins.
Unlike primary-key table-table joins, foreign-key joins do not have a co-partitioning requirement—tables joined based on a foreign key can each have a different number of partitions. The result table will inherit the number of partitions of the left input table. The only restriction is that the left side of the join condition must be a column, rather than an expression involving a column.
Foreign-key joins can apply INNER or LEFT OUTER semantics, while primary-key joins continue to offer INNER, LEFT OUTER, and FULL OUTER behavior. Foreign-key joins cannot be used as part of a n-way join.
Curious about how foreign-key joins work under the hood? Check out the blog post on their Kafka Streams internals.
Treating special values as NULL
Thanks to a community contribution from Francisco Jose Becerra, ksqlDB now ships with a NULLIF function. This utility compares its arguments, returning NULL when they are equal.
Consider using it to translate values like an empty string, a sentinel value, or zero into NULL.
-- Treat values of zero as NULL SELECT NULLIF(cost, 0) FROM costs EMIT CHANGES;
Get started with ksqlDB
Get started with ksqlDB today, via the standalone distribution or with Confluent, and join the community to ask a question and find new resources.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.