Diagnose and Debug Apache Kafka Issues: Understanding Increased Consumer Rebalance Time
When you encounter a problem with Apache Kafka®—for example, an exploding number of connections to your brokers or perhaps some wonky record batching—it’s easy to consider these issues as something to be solved in and of themselves. But, as you’ll soon see, more often than not, these issues are merely symptoms of a wider problem. Rather than treat individual symptoms, wouldn’t it be better to get to the root of the problem with a proper diagnosis?
If you're looking to level-up your Kafka debugging game and understand common problems as well as the ailments that an individual symptom could be pointing to, then this blog series is for you.
Symptoms in the Series
Throughout this blog series, we’ll cover a number of common symptoms you may encounter while using Kafka, including:
- Reduced Message Throughput
- Increased Request Rate, Request Response Time, and/or Broker Load
- Increased Consumer Rebalance Time (this post)
- Increased Connections
These issues are common enough that, depending on how badly they’re affecting your normal operations, they might not even draw much attention to themselves. Let’s dive into each of these symptoms individually, learn more about what they are and how they make an impact, and then explore questions to ask yourself to determine the root cause.
In this particular post, we’ll cover…
Increased Consumer Rebalance Time
Rebalancing comes into play in Kafka when consumers join or leave a consumer group. In either case, there is a different number of consumers over which to distribute the partitions from the topic(s), and, so, they must be redistributed and rebalanced.
Types of Rebalancing
At the surface, rebalancing seems simple. The number of consumers in the consumer group is changing, so the subscribed topic-partitions must be redistributed, right? Yes, but there’s a bit more going on under the hood and this changes depending on what kind of rebalancing is taking place.
Stop-the-World
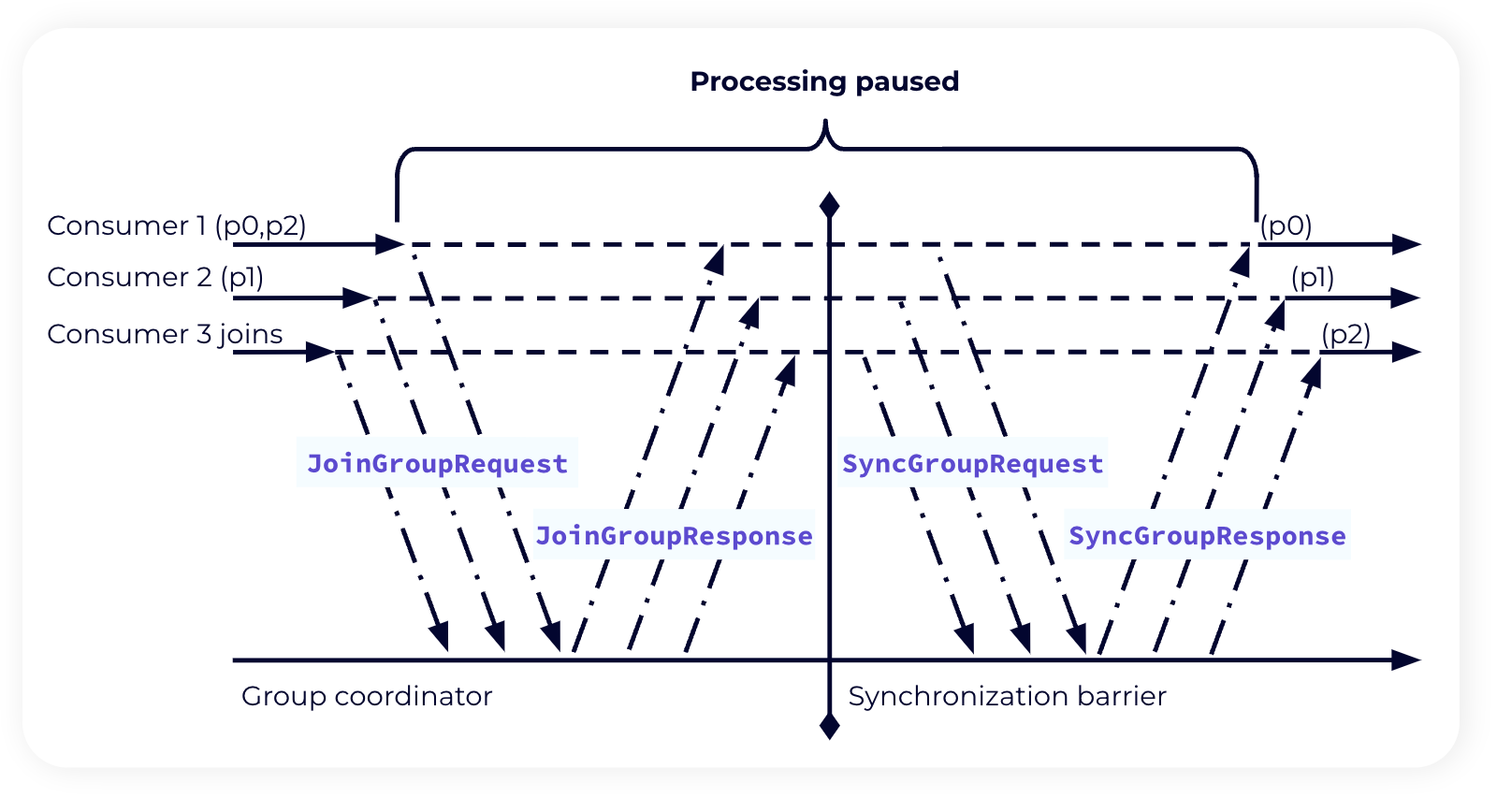
The first and most common type of consumer rebalancing is called Stop-the-World.
-
Suppose we have an existing consumer group with a set assignment of topic-partitions to consumers. This consumer group consists of a number of consumers, each with a member id as well as a group leader (usually the consumer that was first to join the group). A new consumer comes along and requests to join the consumer group by sending a request of JoinGroup to the Group Coordinator along with the topics it would like to subscribe to.
-
The Group Coordinator kicks off the rebalance by telling all current members to issue their own JoinGroup requests. This is done as part of the response to the heartbeat that consumers send to the Group Coordinator to tell it they’re still alive and well.
-
Each consumer in the group has max.poll.interval.ms to wrap up their current processing and send their JoinGroup request, at which point the world is stopped. With all of the JoinGroup requests, the Group Coordinator knows all of the consumers in the group and which topics should be part of the consumer group. It sends JoinResponses to the members, chooses a leader from amongst the members, and leaves the leader to compute the partition assignments.
-
All group members respond with a SyncGroup request. The group leader sends its partition assignments along with its request.
-
At this point, the Group Coordinator can send its SyncResponse to each consumer confirming their assigned topic-partitions.
-
Finally, consumers acknowledge their assignments and processing can resume. The world is no longer stopped.
In the case that a single consumer is being added or removed from a consumer group, this process is a bit easier to follow. However, when entire applications, e.g. applications with multiple Kafka Streams instances, are deployed as part of an upgrade, all of the consumers are likely being upgraded and bounced at once or within a short amount of time. This can lead to a domino effect, where multiple JoinGroup requests cause the rebalance to occur multiple times, thus causing the rebalance time to take significantly longer than usual.
The longer a rebalance takes, the greater the consumer lag could be when all of the consumers eventually come online. To minimize this lag, it’s important that the rebalancing process takes as little time as possible so as to not disrupt the current flow of consumption and processing by the existing consumers. Thankfully, there are other options available to help reduce the impact that rebalancing has.
Incremental Cooperative
With Incremental Cooperative rebalancing, consumers are less likely to be impacted by changes to the group, and they can continue their processing in the meantime.
Steps 0 through 2 are the same between the Stop-the-World rebalancing and Incremental Cooperative rebalancing.
-
From there, each consumer in the group has max.poll.interval.ms to wrap up their current processing and send their JoinGroup request. This time, they also send along their current topic-partition assignment. And rather than stop the world to wait for new assignments, the consumers are free to continue processing their assigned topic-partitions until further notice.
-
The Group Coordinator again uses the JoinGroup requests to know all of the consumers and which topics should be part of the consumer group. It sends JoinResponses to the members, chooses a leader, and leaves the leader to compute the partition assignments.
-
All group members respond with a SyncGroup request. The group leader sends the updated partition assignments along with its request.
-
The Group Coordinator looks at the new partition assignments, compares them to the old assignment, and only sends SyncResponses to consumers whose partition assignments are changing. Thus, only impacted consumers must stop to rebalance.
-
Finally, updated consumers acknowledge their new assignments and processing resumes across the board.
Static Group Assignment
In some use cases, users have the ability to further reduce the impact of rebalancing by utilizing a Static Group Assignment. In this scenario, individual consumers within the consumer group are given a group.instance.id and a static assignment of partitions that they individually own. In the event that a consumer goes down for any reason, no rebalance occurs so long as the consumer with that group.instance.id comes back online within the configurable session.timeout.ms.
Consumer Metrics to Know
Understanding the health of your consumers is the first step to mitigating an increased rebalance time and getting to the bottom of what could be causing it. It should come as no surprise that consumer metrics are here to do just that.
-
kafka.consumer:type=consumer-coordinator-metrics,client-id=([-.w]+),name=join-rate: This is a consumer group metric that defines the number of joins per second. When rebalance is occurring, joining is the first step of the process, so it’s a good thing to monitor. For a healthy consumer group, the join-rate should be relatively low; a high number of joins per second could indicate that the consumer group isn’t very stable.
-
kafka.consumer:type=consumer-fetch-manager-metrics,client-id=”{client-id}”,name=records-lag-max and kafka.consumer:type=consumer-fetch-manager-metrics,partition=”{partition}”,topic=”{topic}”,client-id=”{client-id},name=records-lag-max: This metric is offered at both the consumer group-level and the partition-level. It specifies the maximum record lag across all partitions for a consumer group or the max lag per partition. Join rate is one thing, but to understand the effect that rebalancing has on processing, consumer lag is the next best thing to check. A high or increasing records-lag-max means that the consumer group isn’t able to keep up with the records that are being produced or that a particular partition is being impacted. By itself, this metric doesn’t state what causes the lag, but it is a good metric to keep in mind, especially if you believe that your rebalances are taking too long.
Continuing the Diagnosis
In addition to noticing increased time to rebalance…
… are you witnessing higher than usual memory consumption, increased consumer group size, and an increased number of connections? It may be the case that you created one consumer per thread within a single service instance. The use case typically at the bottom of this might sound innocent enough: trying to increase and parallelize consumption within a single instance. Naturally, to do so, you multithread your application and start a consumer instance within each of those threads. However, the cost you pay for increased numbers of consumers is exactly what we saw in the above section.
To move to a multi-threaded model, what you’ll likely want to do is maintain one consumer, thread it off, and place all records coming out of that consumer into a separate thread pool for processing. There are ways to do this successfully, but keep in mind that consumers aren’t necessarily thread-safe out of the box, so you’ll have to be careful about your implementation.
… are your consumer groups large and you see an increase in the number of connections? This is similar to the issue described in the final part of the reduced batching symptom. If your Kafka clusters are cloud-based, your KafkaConsumer instances might be sized too small. It might be time to check into your KafkaConsumer workloads to see if they’re sized appropriately.
… have you hit a dead end? Admittedly, most of the above metrics and explanations on rebalancing related to the clients and how they function. That’s not to say that there isn’t a bit of parameter tuning that can be done from the server side, specifically from the group coordinator. You might see rebalances taking longer if, say, a group coordinator has too many groups to handle or if any one partition is too large (meaning it takes longer to load). If you hit a dead end in tracking down your rebalancing woes from the client side, it might be time to check into your group coordinator.
Conclusion
Exploding consumer rebalancing can be a cryptic occurrence if you don’t know what to look for when it happens. Thankfully, being familiar with these metrics and knowing what followup questions to ask yourself should make the process less daunting the next time around.
To continue on in your Kafka diagnostic practice, check out these other great resources to help you along the way:
- Check out the previous symptom in our Diagnose and Debug series: Understanding Increased Request Rate, Response Time, and/or Broker Load
- Avoid potential problems entirely by diving into common Apache Kafka mistakes and pitfalls that everyone is likely to encounter.
- Give Confluent Cloud a try and see what fully-managed, cloud-based Kafka has to offer you.
- Plug into a community: Check out the Confluent Community Slack and Confluent Forum.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Diagnose and Debug Apache Kafka Issues: Understanding Increased Request Rate, Response Time, and/or Broker Load
It can be easy to go about life without thinking about them, but requests are an important part of Apache Kafka; they form the basis of how clients interact with data as it moves into and out of Kafka topics, and, in certain cases, too many requests can have a negative impact on your brokers...

Helpful Tools for Apache Kafka Developers
Apache Kafka® is at the core of a large ecosystem that includes powerful components, such as Kafka Connect and Kafka Streams. This ecosystem also includes many tools and utilities that […]