New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Data Mesh: Introduction, Architectural Basics, and Implementation
Data mesh is a data architecture framework designed to enhance data management and scalability within organizations. By distributing data ownership and capabilities across autonomous and self-contained domains, data mesh optimizes the efficiency, agility, and scalability of data management within complex, distributed data ecosystems.
In this introduction, learn data mesh principles, use cases, and examples, as well as how to implement this pattern in your organization with distributed systems like Apache Kafka®.
Data Mesh Architecture
In data mesh architectures, data is treated as a product, and individual domain teams are responsible for their own data products. This decentralized approach promotes domain-driven ownership and accountability, enabling teams to manage and evolve their data independently.
This type of architecture differs from traditional data fabric and data lake approaches by providing a decentralized and domain-oriented model for data governance and access.

Start with Module 1: What Is Data Mesh? from the Data Mesh 101 course or take the full course on Confluent Developer.
Data Mesh vs Data Lake
When comparing data mesh vs a data lake, the key distinction lies in their respective approaches to data management. A data lake is a centralized repository that stores raw, unprocessed data from various sources. In contrast, data mesh emphasizes the distribution of data ownership, where domain teams manage their data products independently. This decentralization empowers teams to define their own data schemas, quality standards, and access mechanisms, promoting greater autonomy and flexibility.
Data Mesh vs Data Fabric
Similarly, data mesh differs from data fabric by prioritizing domain-oriented data governance and access. Data fabric focuses on providing a centralized integration layer that abstracts data sources and enables seamless access. Data mesh, on the other hand, delegates data ownership and data governance to individual domain teams, allowing them to define their own data APIs and access policies. This decentralized approach in data mesh enhances scalability and promotes a more adaptive and agile data management ecosystem.
Unlike data fabric, which focuses on creating a centralized data integration layer, data mesh emphasizes the distribution of data ownership and governance to foster agility and scalability.
Core Data Mesh Principles
Implementing a data mesh architecture enables scalable and efficient data sharing across organizations by decentralizing data ownership to domain teams, treating data as a product, and supporting self-serve access. This pattern focuses on four key principles that help modern organizations address common data challenges like bottlenecks from centralized teams, lack of domain understanding, brittle point-to-point integrations, poor data quality, and the creation of new data silos.
Learn more about the how to solve these challenges with Apache Kafka® in Practical Data Mesh: Building Decentralized Data Architectures with Event Streams.
1. Domain Ownership of Data
In much the same way that microservices each own a specific business function, in data mesh, data is broken down around and owned by a specific business domain. Access to that data is decentralized; there's not a central data bureau, data team, analytics team, or admin team. Rather, there's a place where that data lives, probably next to its functionality, e.g., the microservices that produce the data. Access to the data is granted at that point.
→ Responsibility over modeling and providing important data is distributed to the people closest to it, providing access to the exact data they need, when they need it.
2. Data as a Product
In data mesh, data for consumption is considered a product—a first-class product, rather than a byproduct—by each team that publishes it. A team owns data just like a team would own the set of services that implement the slice of the business that they support. That team has to engage in product thinking about the data: They're wholly responsible for the data, including its quality, its representation, and its cohesiveness.
→ Data is treated as a product like any other, complete with a data product owner, consumer consultations, release cycles, and quality and SLAs. Make shared data discoverable, addressable, trustworthy, secure so other teams can make good use of it.
3. Self-Serve Data Platform
All data is available everywhere in the company by self-serve in data mesh. Data governance is still an issue, but in principle, data products are published and they are available everywhere. If you're producing a sales forecast for Japan, for example, you could find all of the data that you need to drive that report—ideally in a few minutes. You'd be able to quickly get all of the data you need from all of the places it lives into a database or reporting system that you control.
→ Empower consumers to independently search, discover, and consume data products. Data product owners are provided standardized tools for populating and publishing their data product.
4. Data Is Governed
Data is governed wherever it is. As things always evolve and grow, no data architecture is ever perfect or perfectly static. Governance allows you to ring fence this, allowing you to trust and more quickly navigate data in the mesh, and believe—subject to governance restraints—that you can use data that you find.
→ A cross-organization team provides global standards for the formats, modes, and requirements of publishing and using data products. This team maintains the balance between centralized standards for compatibility and decentralized autonomy for true domain ownership.
Data Mesh Benefits With Examples
There are numerous challenges that a data mesh can solve. At a smaller scale, it addresses issues seen with point-to-point data pipelines, which are brittle and rigid with data fidelity and governance challenges. It also addresses larger organizational issues, such as different departments in a company disagreeing on core facts of the business. A data mesh can bring much-needed order to a system, resulting in a more mature, manageable, and evolvable data architecture that:
Meets Modern Data Requirements
The unprecedented volumes of data constantly being produced and consumed by every kind of team and app are overwhelming to centralized data storage models and the teams responsible for them.
Increases Agility and Gives Teams Autonomy Over Data
Data mesh gives individual teams more control over data. This model also takes the onus of “digital transformation” of a central platform and its small governing team. With more autonomy over their data, teams also have more flexibility, which leads to more data experimentation and ultimately, a faster rate of innovation.
Enables the Use of Real-Time Data at Scale
Within the domain-driven data mesh, it’s possible to unlock real-time analytical data at scale, which in turn facilitates advanced capabilities such as AI and machine learning. The distributed architecture of the data mesh enables an accessible layer of connectivity for engineering teams across the organization. Real-time data combined with historical context, power modern applications, customer experiences, and operational efficiencies that make a company more competitive.
Eliminates the Bottlenecks with Legacy Centralized Data Warehouses
A typical implementation of a data warehouse has many data sources spread across the organization, with vastly different levels of quality. ETL jobs pull data sets back to the central data warehouse and data warehouse teams are often required to clean up and fix a lot of that data, even though they don’t really understand the data sets that well. Data mesh eliminates time and process bottlenecks by allowing for decentralization, having data ownership reside where the data originates.



Data mesh: Instacart’s initial success with data streaming informed their larger strategy–building a central data mesh so teams can get what they need.
Common Use Cases
In practice, a data mesh processes and integrates real-time, historical, and telemetry data from operational systems, systems of record, and IoT devices. The result is unlimited use cases from data products, which may range from personalized customer experiences to AI/ML modeling to clickstream analytics. To learn more, watch this webinar.
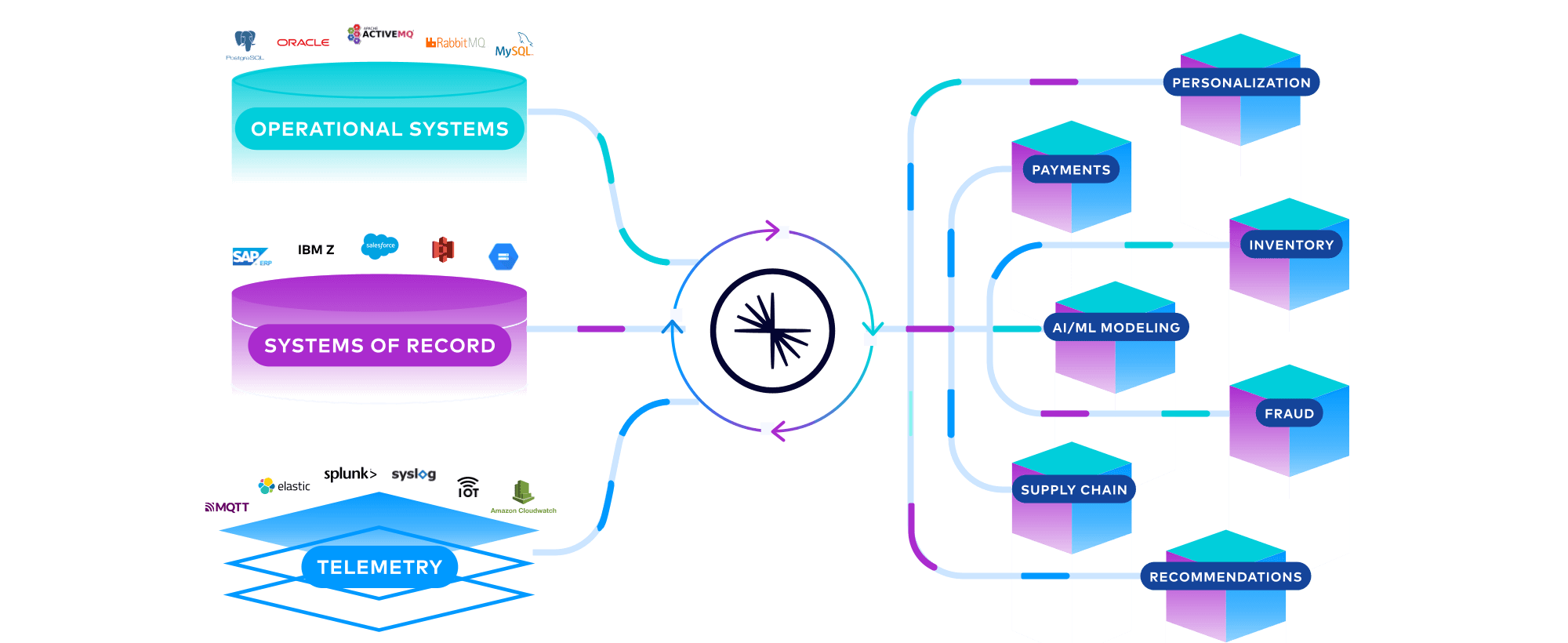
How to Build a Data Mesh
A data mesh is about making data connectivity fast and efficient. Connectivity within the data mesh naturally lends itself to event streaming with Apache Kafka, where high-quality data streams of data products can be consumed in real time, at scale:
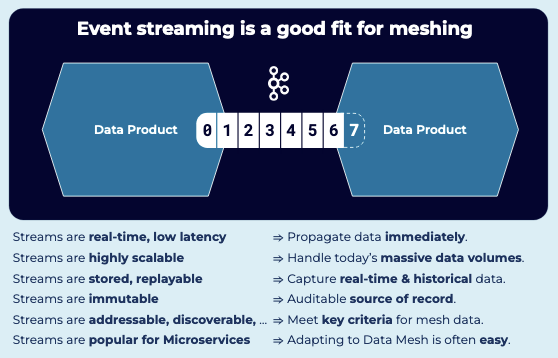
The Confluent data streaming platform delivers a complete, enterprise-grade capabilites you need across clouds and on-premises. Here’s how our fully managed cloud, BYOC, and self-managed deployments make it possible to build an enterprise data mesh wherever your data lives:
Connect
The data that needs to be exposed as a data product can, and often is, coming from existing databases. To expose a data product, a quick and easy way to onboard data from those existing on-prem, hybrid, and multicloud systems is through connectors that stream data from these sources into the mesh in real time. Non-streaming systems within a data product—like relational databases—can be streamified via connectors.
For example, you can feed real-time updates from upstream data products into a database like MySQL to keep the database current with the latest business information. Then, any existing database applications inside the product can continue to work as usual. Similarly, any changes to the database itself—e.g., inserts, updates, deletes that impact a customer profile—can be captured via change data capture and shared as event streams with the outside world in the data mesh. The resulting streaming data pipelines can bridge the operational and analytical data divide, decentralize data strategy, and democratize data.
Process
With data flowing into the data product, stream processing is used to join, transform, and enrich to produce the public data. An important step towards building reusable data products is to increase the value of that single event or that single data point by combining it with other data and other event streams. This means combining and processing any stream from anywhere and continuously enriching the data, so that any downstream system or application consuming that data can get the most enriched view of the data, making the same data reusable, over and over again.
Govern
Organizations need to strike a balance between delivering data access for developers–so they can innovate faster and accelerate the onboarding of use cases–and data security, protecting the data to meet enterprise compliance and regulatory standards. When distributed teams are able to discover, understand, and trust their data, they can accelerate development of the real-time experiences that drive differentiation and increase customer satisfaction while upholding strict compliance requirements. Stream Governance is the key to fostering the collaboration and knowledge sharing necessary to become a data-centric business while remaining compliant within an ever-evolving landscape of data regulations.
Schema Registry allows teams to define and enforce universal data standards while Stream Lineage provides a GUI of data streams and data relationships, showing how data is transformed from source to destination. Finally, once data products are created, they need to be discoverable. Stream Catalog publishes data streams, its specifications, who made it, etc. in a place where people can discover and use it.
Share
Stream sharing provides greater data reuse and fan-out, where data is shared with other LOBs and even to other companies, pushing those data products to other systems. In lieu of flat file sharing, polling API calls, or proprietary sharing solutions with vendor lock-in, stream sharing shares real-time data in a few clicks directly from Confluent to any Kafka client. Safely share and protect data, verify the quality and source of shared data, and enforce consistent schemas across users, teams, and organizations. Within their data mesh, companies can securely and easily share data with other internal data owners without having to move or copy the data from various, disparate sources.
Get Started
A great place to start is the Confluent Developer tutorial series with Data Mesh 101. To explore building a cloud-native data mesh using Confluent’s fully managed, serverless Kafka service – get started for free in minutes on any cloud.
Get Started
New users get $400 free to spend.