Use Cases and Architectures for HTTP and REST APIs with Apache Kafka
This blog post presents the use cases and architectures of REST APIs and Confluent REST Proxy, and explores a new management API and improved integrations into Confluent Server and Confluent Cloud.
The Confluent REST Proxy provides a RESTful interface to an Apache Kafka® cluster, making it easy to produce and consume messages, view the metadata of the cluster, and perform administrative actions using standard HTTP(S) instead of the native TCP-based Kafka protocol or clients.
Request-response (HTTP) vs. event streaming (Kafka)
Prior to discussing the relation between HTTP/REST and Kafka, let’s explore the concepts behind both. Traditionally, request-response and event streaming are two different paradigms:
Request-response (HTTP)
- Low latency
- Typically synchronous
- Point to point
- Pre-defined API
Event streaming (Kafka)
- Continuous processing
- Often asynchronous
- Event-driven
- General-purpose events
Most architectures need request-response for point-to-point communication (e.g., between a server and mobile app) and event streaming for continuous data processing. With this in mind, let’s look at use cases where HTTP is used in conjunction with Kafka.
Use cases for HTTP and REST APIs with Kafka
Each use case differs significantly in their purpose—some are implemented out of convenience while others are required due to technical specifications. There are three main categories of use cases: management plane, data plane, and ubiquitous.
Management plane
The management and administration of a Kafka cluster involves various tasks, such as:
- Cluster configuration: Management of Kafka topics, consumer groups, ACLs, etc.
- CI/CD and DevOps integration: HTTP APIs are the most popular way to build delivery pipelines and to automate administration, instead of using Python or other alternative scripting options.
Data plane
Various scenarios require or prefer the usage of REST APIs for producing and consuming messages to/from Kafka, such as:
- Natural request-response applications such as mobile apps: These applications and the frameworks almost always require integration via HTTP and request-response. WebSockets, Server-Sent Events (SSE), and similar concepts are a better fit for event streaming with Kafka. They are in the client framework, though often not supported.
- Legacy application and third-party tool integration: Legacy applications, standard software, and traditional middleware are often proprietary. The only integration capabilities are HTTP/REST. Nevertheless, extract, transform, load (ETL), enterprise service bus (ESB), and other third-party tools are complementary to event streaming with Kafka. Mainframe integration using REST APIs from COBOL to Kafka is another example.
- API gateway: Most API management tools do not provide native support for event streaming and Kafka today and only work on top of REST interfaces. Kafka (via the REST interface) and API management are still very complementary for some use cases, such as service monetization or integration with partner systems.
- Other programming languages: Kafka provides Java and Scala clients. Confluent provides and supports additional clients, including Python, .NET, C, C++, and Go. More Kafka clients exist from the community, including Erlang, Kotlin, Node.js, PHP, Ruby, and Rust. Many of these community clients are not battle tested or supported. Therefore, calling the REST API from your favorite programming language is sometimes the better and easier option. Others, such as COBOL, on the mainframe don’t even provide a Kafka client at all. Hence, the REST Proxy is the only viable solution.
REST APIs are ubiquitous
Most developers and administrators are familiar with REST APIs. They are the natural option for many best practices and security guidelines for the following reasons:
- Avoiding technology lock-in: In some cases, you want to embed the communication or proxy it with a more agnostic API.
- Familiarity with a known technology: You are familiar with REST endpoints and, if they are under pressure or need a quick result, it’s quicker than learning how to use a new API.
- Security: HTTP ports are much easier to open by security teams compared to the TCP ports of the Kafka-native protocol used by the clients from programming languages such as Java, Go, C++, or Python. For instance, in DMZ pass-through requirements, InfoSec owns the F5 proxies in the DMZ. REST Proxy makes the integration easier.
- Domain-driven design (DDD): Often, HTTP/REST and Kafka are combined to leverage the best of both worlds: Kafka for decoupling and HTTP for synchronous client-server communication. A service mesh using Kafka in conjunction with REST APIs is a common architecture.
Kafka REST APIs – Management plane vs. data plane
The Confluent REST Proxy and REST APIs are separated into both a data plane and management plane:
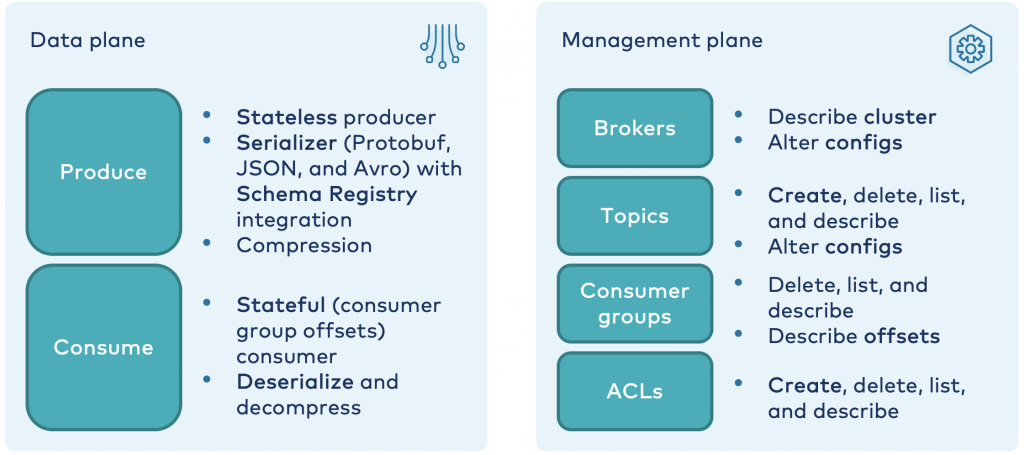
While some applications require both, in many scenarios, only one or the other is used.
The management plane is typically used for very low throughout and a limited number of API calls. The data plane, on the other hand, varies. Many applications produce and consume data continuously. The biggest limitation of the REST Proxy data plane is that it is a synchronous request-response protocol. However, don’t underestimate the power of the REST Proxy as a data plane because Kafka provides batch capabilities to scale up to tens of parallel REST Proxy instances. There are deployments where four REST Proxy instances can handle ~20,000 events per second, which is sufficient for many use cases.
HTTP will offer support for event streaming as an alternative to request-response in the future, but there will still be overhead as a result of having REST Proxy in the middle of the communication.
Architecture of Confluent REST Proxy and REST APIs in Confluent Platform and Cloud
The Confluent REST Proxy has been around for a long time and is available under the Confluent Community License. It is used in production as a data plane by many companies as a self-managed component in conjunction with Kafka, Confluent Platform, or Confluent Cloud. In 2020, additional architectural options were added:
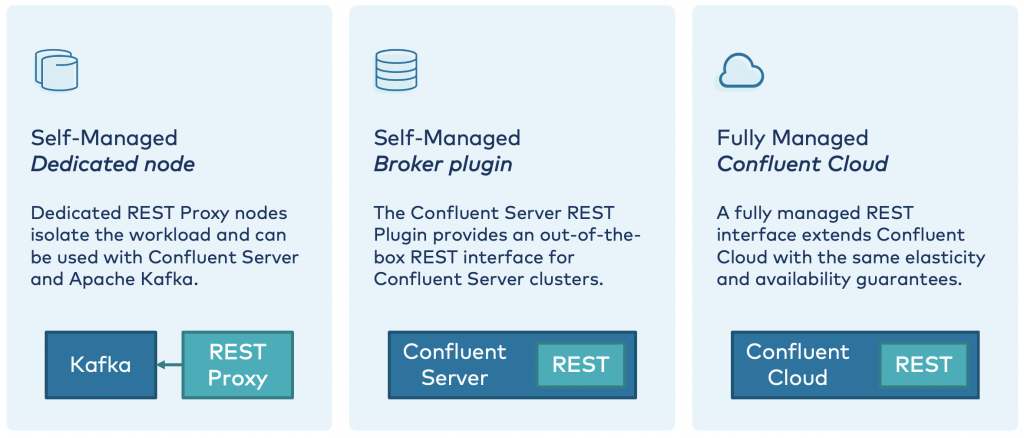
The self-managed REST Proxy instance or cluster of instances (as a “dedicated node”) is still decoupled from the Kafka broker and Confluent Server. This is the ideal option for a data plane to produce and consume messages.
The management plane is also embedded as a unified REST API into Confluent Server (as a “broker plugin”) and Confluent Cloud for administrative operations. This simplifies the architecture because no additional nodes are required for using the administration APIs.
In some deployments, both approaches may be combined: The management plane is used via the embedded REST APIs in Confluent Server or in Confluent Cloud. Meanwhile, data plane use cases are decoupled into their own REST Proxy instances to easily handle scalability and be independent of the server side.
The REST APIs of the self-managed REST Proxy and Confluent Cloud are compatible. Hybrid architectures and cloud migration are possible without implementing any breaking changes.
Confluent Schema Registry for data governance of HTTP services
Data governance is an important part of most event streaming projects. Kafka deployments usually include various decoupled producers and consumers, often following the DDD principle for microservice architectures. Hence, Confluent Schema Registry is used in most projects for schema enforcement and versioning.
Any Kafka client built by Confluent can leverage the Schema Registry using Avro, Protobuf, or JSON Schema. This includes programming APIs like Java, Python, Go, or Python, but also Kafka Connect sources and sink, Kafka Streams, ksqlDB, and the Confluent REST Proxy.
Like the REST Proxy, Schema Registry is available under the Confluent Community License and is part of Confluent Platform and Confluent Cloud.
Schema Registry lives separately from your Kafka brokers. Confluent REST Proxy still talks to Kafka to publish and read data (messages) to topics. Concurrently, the REST Proxy can also talk to Schema Registry to send and retrieve schemas that describe the data models for the messages.
Schema Registry provides a serving layer for your metadata and enables data governance and schema enforcement for all events. It provides a RESTful interface for storing and retrieving your Avro, JSON Schema, and Protobuf schemas. It stores a versioned history of all schemas based on a specified subject name strategy, provides multiple compatibility settings, and allows the evolution of schemas according to the configured compatibility settings and expanded support for these schema types. It provides serializers that plug into Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in any of the supported formats:
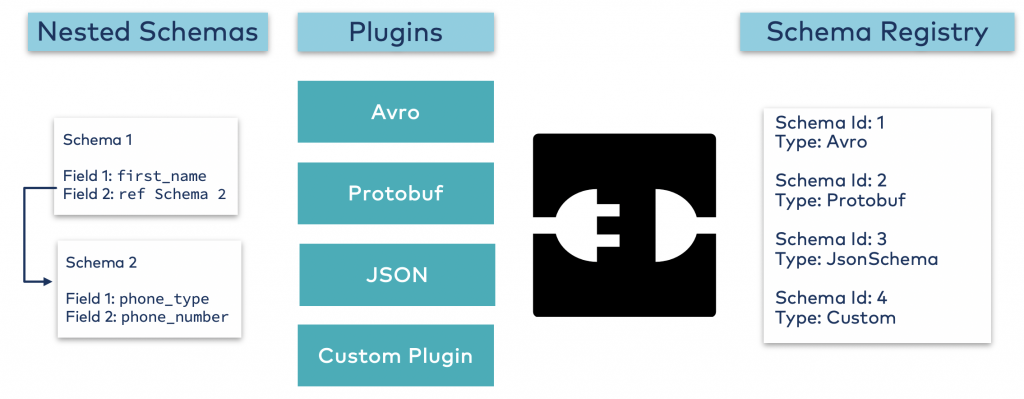
Schema enforcement happens on the client side. Additionally, Confluent Platform and Confluent Cloud provide server-side schema validation. The latter is helpful if incorrect or malicious client applications send messages to Kafka without using the client-side Schema Registry integration.
Getting started with Kafka and HTTP/REST
Various use cases employ HTTP/REST in conjunction with Apache Kafka as a management plane or data plane.
If you run Kafka, Confluent Platform, or Confluent Cloud, the REST Proxy can be used for HTTP(S) communication with your favorite client interface. To learn more, check out this REST Proxy tutorial.
A full demo using Confluent Platform for stream processing can also be found in the Confluent Platform Demo (cp-demo). It includes a section that uses the REST Proxy.
If you’d like to share about your experiences with the Confluent REST APIs and what use cases you use it for, we invite you to join the Confluent Community Slack. We hope to hear from you!





