Apache Kafka 0.9 is Released
I am pleased to announce the availability of the 0.9 release of Apache Kafka. This release has been in the works for several months with contributions from the community and has many new features that Kafka users have long been waiting for. Around 87 contributors provided bug fixes, improvements, and new features such that in total 523 JIRA issues could be resolved.
Here is a quick overview of the notable work in this release.
Security
This release includes three key security features built directly within Kafka itself. First we now authenticate users using either Kerberos or TLS client certificates, so we now know who is making each request to Kafka. Second we have added a unix-like permissions system to control which users can access which data. Third, we support encryption on the wire to protect sensitive data on an untrusted network.
Encryption over the wire is available via SSL. For performance reasons encryption is optional and not enabled by default. This release addresses only encryption on the wire, not data on the filesystem. At-rest encryption can still be achieved either by encrypting individual fields in the message or via filesystem security features.
Kafka 0.9’s support for authorization can be based on different available session attributes or context, like user, IP, common name in certificate etc. For ultimate flexibility this authorizer logic is pluggable, though Kafka 0.9 ships with an out of the box implementation that is self-contained and requires no external dependencies.
Only the new producer and consumer APIs and the 0.9 consumer implementations have been augmented with the above capabilities, and not the older implementations. The purpose of doing so is two-fold: to drive adoption of the new implementations and to mitigate risk.
The above security features have been implemented in a backwards-compatible manner and without performance degradation for users that don’t enable security. These are only the first of many security features to come, and we look forward to adding further security capabilities to Kafka in future releases.
Kafka Connect
Kafka has become a tremendously popular system to enable streaming data flow between external systems to unlock data siloes and to exchange data in real-time. And indeed the open source community has written numerous connectors, such as Camus, to integrate Kafka with other systems. But unfortunately for users every such integration tool looks very different, and most don’t attempt to solve all the problems that need to be addressed for reliable large-scale data ingestion. Users have been forced to understand and operate many different one-off integration tools as their data infrastructure and systems proliferate. Furthermore, many of these one-off tools do not offer high availability or adequate scalability. This presents difficulties for the adoption of Kafka for data integration purposes. To address this situation, Kafka 0.9 adds support for a new feature called Kafka Connect (those who follow the open source discussions closely might have heard it by it’s working name “Copycat”).
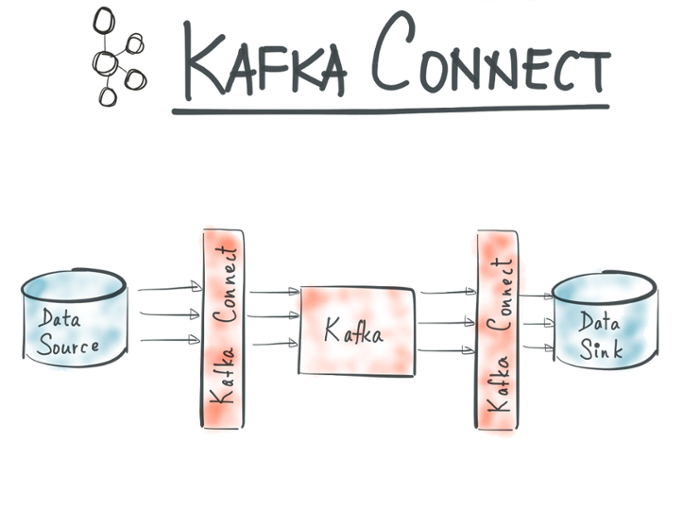 Kafka Connect facilitates large-scale, real-time data import and export for Kafka. It abstracts away common problems that each such data integration tool needs to solve to be viable for 24×7 production environments: fault tolerance, partitioning, offset management and delivery semantics, operations, and monitoring. It offers the capability to run a pool of processes that host a bunch of Kafka connectors while handling load balancing and fault tolerance.
Kafka Connect facilitates large-scale, real-time data import and export for Kafka. It abstracts away common problems that each such data integration tool needs to solve to be viable for 24×7 production environments: fault tolerance, partitioning, offset management and delivery semantics, operations, and monitoring. It offers the capability to run a pool of processes that host a bunch of Kafka connectors while handling load balancing and fault tolerance.
In this release, a file Kafka connector is available that demonstrates the use of the Kafka Connect APIs. We anticipate the development of the actual connectors to take place in a federated manner. A forthcoming release of the Confluent Platform will offer Kafka connectors for databases and Hadoop.
The goal of Kafka Connect is to encourage the growth of a rich ecosystem of open source connectors that share the same APIs, behavior, and that can be monitored, deployed, and administered in a consistent manner.
User defined quota
Multi-tenancy is a broad area and the ultimate end goal is to allow the user to deploy a single large Kafka cluster that hosts a variety of workloads while still supporting custom SLAs. However, a humble first step in that direction is the ability to rate limit traffic from a client to a Kafka cluster. Prior to 0.9, it was possible for a consumer to consume data extremely quickly and thus monopolize broker resources as well as cause network saturation. It was also possible for a producer to push extremely large amounts of data, thus causing memory pressure and large I/O on broker instances. Such situations could cause collateral damage within clusters and impact SLAs. Kafka 0.9 now supports user-defined quotas. Users have the ability to enforce quotas on a per-client basis. Producer-side quotas are defined in terms of bytes written per second per client id while consumer quotas are defined in terms of bytes read per second per client id.
Each client receives a default quota (e.g. 10MBps read, 5MBps write) which can be overridden dynamically on a per-client basis. The per-client quota is enforced on a per-broker basis. For instance, each client can publish/fetch a maximum of X MBps per broker before it gets throttled.
If clients violate their quota, Kafka throttles fetch/produce requests and slows down the client. The slowdown does not return an error to the client but is visible through metrics. It should have no negative effect on any other clients of the cluster that are within their defined quotas; on the contrary other clients will rather have the benefit of potentially higher available network bandwidth and cluster resources.
In essence, the quotas support in Kafka offers the user the ability to prevent a rogue application from making the cluster unavailable for other clients.
New consumer
At the time of the 0.8.2 release of Apache Kafka, which released the redesigned producer client, we had promised to redesign the consumer client as well. And we kept our promise: the 0.9 release introduces beta support for the newly redesigned consumer client. At a high level, the primary difference in the new consumer is that it removes the distinction between the “high-level” ZooKeeper-based consumer and the “low-level” SimpleConsumer APIs, and instead offers a unified consumer API.
This new consumer is implemented using a powerful new server-side facility that makes group management a first-class part of Kafka’s protocols. This has several advantages. First it allows for a much more scalable group facility, which allows the consumer clients to be much simpler and thinner and allows for larger groups with far faster rebalancing. This facility is available to all clients; work is already nearing completion to use it in the C client, librdkafka. This same facility turns out to be broadly useful for managing distributed producing and consuming of data in Kafka; it is the basis for Kafka Connect as well as several upcoming projects. Finally this completes a series of projects done in the last few years to fully decouple Kafka clients from Zookeeper, thus entirely removing the consumer client’s dependency on ZooKeeper. Zookeeper is still used by Kafka, but it is an implementation detail of the broker–clients that use this new facility have no need to connect to Zookeeper at all. This has a number of operational benefits since clients are now always working through the security and quota mechanisms the broker provides. This significantly simplifies the consumer and opens the door for first-class non-Java implementations of the consumer API to emerge over time.
The new consumer allows the use of the group management facility (like the older high-level consumer) while still offering better control over offset commits at the partition level (like the older low-level consumer). It offers pluggable partition assignment amongst the members of a consumer group and ships with several assignment strategies. The new consumer also offers pluggable offset management support that allows the user to choose between the default Kafka backed offset management or offset management through an external data store.
The new consumer offers your application complete control over consumption semantics while still having the option of relying on convenient fault tolerant group management semantics. To ensure a smooth upgrade paths for our users, the 0.8 producer and consumer clients will continue to work on an 0.9 Kafka cluster.
If you’d like to start playing with the new Kafka 0.9 consumer, please take a look through its API docs.
Notice
Kafka 0.9 no longer supports Java 6 or Scala 2.9. If you are still on Java 6, consider upgrading to a supported version.
More improvements and fixes
In addition to the above features, there are several operational improvements in this release.
- KAFKA-1546: Replica lag tuning is now fully automated
- KAFKA-1989: New purgatory design leading to low memory overhead on brokers
- KAFKA-1070: Auto-assign node ids
- KAFKA-1646: Ability to preallocate log segments, critical for better performance on Windows
- KAFKA-1650: No data loss in MirrorMaker on unclean shutdown
- KAFKA-1865: Add flush() API to the Kafka producer
- KAFKA-1374: Log compaction now supports compressed topics
- KAFKA-1877: Expose version via jmx on the Kafka producer
- KAFKA-2012: Broker automatically handles corrupt index files
Contributors
According to git shortlog 87 people contributed to this release: Aditya Auradkar, Alexander Pakulov, Alexey Ozeritskiy, Alexis Midon, Allen Wang, Anatoly Fayngelerin, Andrew Otto, Andrii Biletskyi, Anna Povzner, Anton Karamanov, Ashish Singh, Balaji Seshadri, Ben Stopford, Chris Black, Chris Cope, Chris Pinola, Daniel Compton, Dave Beech, Dave Cromberge, Dave Parfitt, David Jacot, Dmytro Kostiuchenko, Dong Lin, Edward Ribeiro, Eno Thereska, Eric Olander, Ewen Cheslack-Postava, Fangmin Lv, Flavio Junqueira, Flutra Osmani, Gabriel Nicolas Avellaneda, Geoff Anderson, Grant Henke, Guozhang Wang, Gwen Shapira, Honghai Chen, Ismael Juma, Ivan Lyutov, Ivan Simoneko, Jaikiran Pai, James Oliver, Jarek Jarcec Cecho, Jason Gustafson, Jay Kreps, Jean-Francois Im, Jeff Holoman, Jeff Maxwell, Jiangjie Qin, Joe Crobak, Joe Stein, Joel Koshy, Jon Riehl, Joshi, Jun Rao, Kostya Golikov, Liquan Pei, Magnus Reftel, Manikumar Reddy, Marc Chung, Martin Lemanski, Matthew Bruce, Mayuresh Gharat, Michael G. Noll, Muneyuki Noguchi, Neha Narkhede, Onur Karaman, Parth Brahmbhatt, Paul Mackles, Pierre-Yves Ritschard, Proneet Verma, Rajini Sivaram, Raman Gupta, Randall Hauch, Sasaki Toru, Sriharsha Chintalapani, Steven Wu, Stevo Slavić, Tao Xiao, Ted Malaska, Tim Brooks, Todd Palino, Tong Li, Vivek Madani, Vladimir Tretyakov, Yaguo Zhou, Yasuhiro Matsuda, Zhiqiang He.
Looking ahead
Even after all of this work, there is still a lot to be done. In the forthcoming releases, the Apache Kafka community plans to focus on operational simplicity and stronger delivery guarantees. This work includes automated data balancing, more security enhancements, and support for exactly-once delivery in Kafka.
Also, now is a great time to get involved. You can start by running through the Kafka quick start, signing up on the mailing list, and grabbing some newbie JIRAs. If you enjoy working on Kafka and would like to do so full time, we are hiring at Confluent!
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録





