Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Stream Processing vs. Batch Processing: What to Know
With more data being produced in real time by many systems and devices than ever before, it is critical to be able to process it in real time and get actionable insights while the data is still relevant. This is possible with stream processing, which enables businesses to meet real-time requirements and to stay competitive by future-proofing their architecture.
For example, financial services firms are using stream processing for real-time fraud detection, retailers are using it to achieve 360° views on customer activity, and cloud-native companies use it to detect outages before customers experience any downtime.
Where the old batch-processed data model is like waiting for the daily paper to get printed and hand-delivered to your door, stream processing is akin to real-time news feeds, where information is delivered instantly. A loose metaphor, of course, but the point is this: The expectation now from consumers, the workforce, and across enterprises, is that information will be available instantly.
If you’re looking to transition from batch processing to stream processing for a particular use case, or modernize your data architecture in general, here’s an introduction to the key concepts of batch vs. streams to get you up to speed.
What is batch processing?
Originally, most data processing systems relied on batch processing, with traditional batch systems running nightly to process the data accumulated throughout the day. This creates large discrepancies between the actual state of the world and what is being reported by the system, preventing timely action on insights. While more modern batch or job systems reduce the duration between batches, it can require hours to get a large dataset processed, and that dataset still won’t represent the latest version of the system. Additionally, different systems relying on different batch schedules can produce inconsistent results.
What is stream processing?
Also known as event stream processing, stream processing allows data to be processed as it arrives, leading to real-time insights. Since today’s data is typically generated as a continuous, real-time stream (think social media feeds or real-time GPS data), stream processing is the key to leveraging this data in motion.
For this, stream processing relies on three main characteristics:
- Continuous processing: stream processing runs constantly to process the incoming flow of data. In a sense, the processing logic is waiting for the data and processes as it arrives.
- Low latency: in order to produce real-time insight, stream processing needs to operate with very low latency, as low as sub-second latency.
- Support for event-time processing: when making a decision on a sequence of events, it is important to consider the correct order of events even if they didn’t reach the stream processor in the right order due to network delays, for example.
Within the stream processing model, a data processing platform collects, stores, and manages continuous streams of data as they are produced and consumed. In this way, stream processing can support and capture the processing of every data event, in real time, at any scale. Events can also be captured and stored for historical viewing within a system that has the ability to persistently store events for a period of time—be it a short period, a long period, or forever.
Stream processing is sometimes applied to a single business use case, but modern digital organizations use it as a single platform that sits at the heart of an event-driven architecture, connected to every single system throughout the company. Different teams and organizations can share data, creating a cohesive structure where the entire business takes advantage of data in real time.
What is stream processing used for? Top 5 common use cases
To get a sense of tangible ways in which different kinds of companies are using stream processing, consider a few examples:
1. Streaming ETL
ETL (extract, transform, load) process is one of the main processes that was traditionally using batch processing, powering business intelligence applications. With streaming ETL, transformations are done as soon as the data arrives and can be used to power real-time insights and dashboards. Streaming ETL is very transformative for businesses as the data is always up to date.
2. Automotive industry
Connected cars take advantage of modern automotive technologies such as sensors, onboard computational power, and wireless connections to enable features like autonomous driving, automated traffic alerts, anomaly detection to request service calls, and personalization based on patterns of usage and driving habits.
3. Anomaly and fraud detection
Fraud detection is a very canonical use case for stream processing and financial institutions can check abnormal activity on a credit card transaction history to detect fraudulent activities. Doing this in real time, even before the transaction is accepted, allows financial institutions to prevent fraud in real-time instead of reacting after the fact.
4. Predictive analytics
Predictive analytics is a natural fit for stream processing as the outcome of a situation can be predicted based on the current sequence of events. For example, the manufacturing industry uses streaming data to pull key metrics from machine sensors for real-time analytics to predict failure before it happens, preventing product loss and reducing maintenance costs.
5. Real-time multiplayer gaming
Hundreds of thousands of concurrent global players get a rich online gaming experience with all of their activity and actions captured in real time. The gaming experience is driven by in-game location data, analysis of player behavior, analysis of server performance, and data processed at scale at a high volume and velocity.
In all of these cases, stream processing enables systems to take advantage of data in motion to provide real-time insight and drive better experiences.
Using Apache Kafka® for efficient stream processing
To talk about stream processing, we have to talk about Apache Kafka. As a technology that enables stream processing on a global scale, Kafka has emerged as the de facto standard for streaming architecture. Here are a few of the important functionalities of Kafka that enable stream processing.
Duality Stream Tables
With Kafka stream processing, data can be manipulated as either a stream or a table, creating a functional duality. Here’s a simple visual of what this looks like: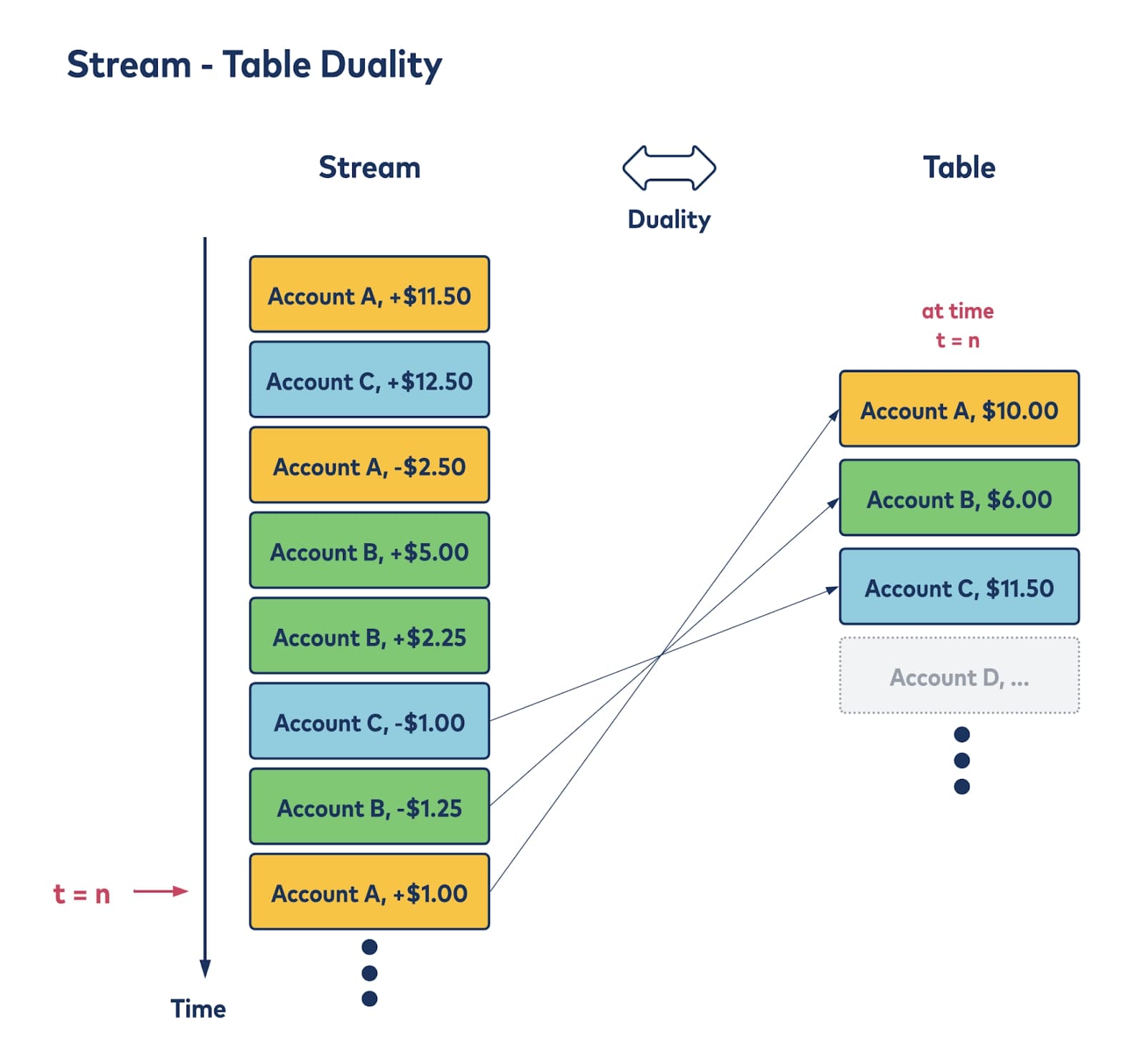
Imagine the stream at left as financial transaction activity happening within a system. This is the event stream, with each box representing a data “event.” The stream includes the most recent events as well as all historical events for accounts A, B, and C—multiple transactions over time.
For interpretation or processing, it’s useful to be able to see a current snapshot of the state of the accounts in a table (the figure on the right). In this abstraction, the current state of each account is captured at a moment in time with an aggregate (here’s the sum of all transactions) defining how to interpret the stream of events.
This duality enables great flexibility in the construction of application logic. You can learn more about how streams and tables work in Kafka in the blog post Streams and Tables in Apache Kafka: A Primer.
Streaming data pipelines
Real-time data pipelines are at the core of stream processing. They’re enabled by a data architecture that moves data from a source—or, more often, multiple sources—to a destination, while making it possible to perform analytics and business intelligence on that data while it’s in motion. When using multiple sources, temporal joins enable to combine events from multiple streams together.
A real-time data pipeline looks something like this: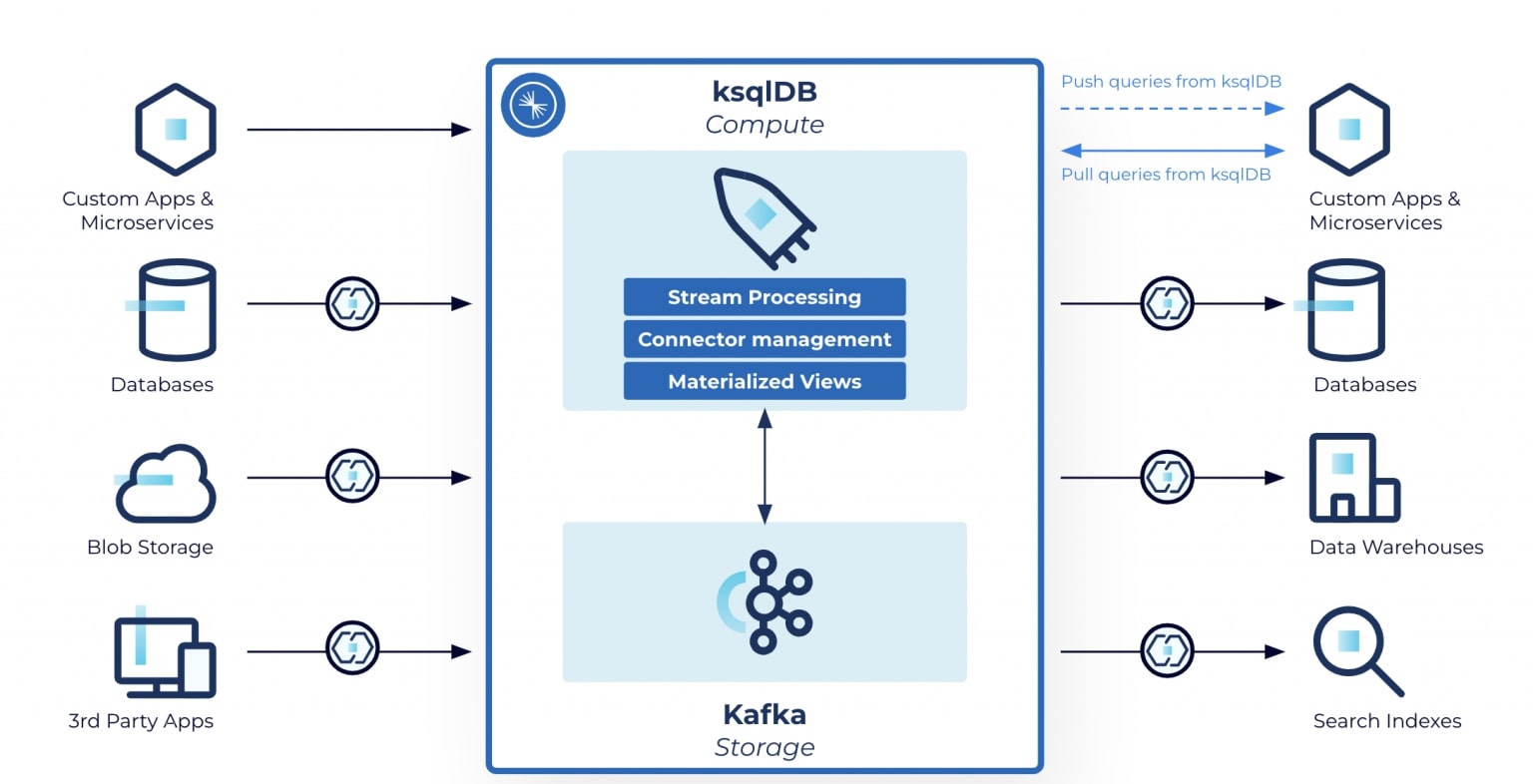
On the left side are systems producing data in real time, or conventional relational database management systems that can stream events with CDC (change data capture). The data can be filtered, transformed, combined, and enriched in the stream processing layer, before being sent to the external destinations, or sinks, on the right. Typical sinks can be databases, data warehouses, or simply real-time applications leveraging the data processed.
With more than 120 pre-built connectors and the ability to build custom connectors, it is easy to get some data in Kafka from existing systems and quickly start to apply stream processing to existing data.
Multiple options to run stream processing with Confluent
While Kafka is at the heart of stream processing, there are two paths you can take to put your data in motion with stream processing:
- Kafka Streams, enabling developers to build streaming applications using one of the two APIs, in Java or Scala:
- Declarative, Functional DSL, which is the recommended way for most users since the business logic can be expressed in just a few lines of code.
- Imperative, lower-level Processor API, which enables more flexibility but requires more coding work.
- ksqlDB, enabling users to create streaming applications using a SQL language. This path significantly reduces the complexity of creating streaming applications while keeping the underlying performance of Kafka Streams, since ksqlDB generates Kafka Streams applications under the hood.
We know getting started with stream processing is not always easy since it is a relatively new paradigm, so Confluent created data streaming recipes to help users to start with common stream processing use cases. In a few minutes, you can get started with the most common scenarios we mentioned earlier: fraud detection, predictive maintenance, and more. Explore the top data streaming use cases.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.