[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Apache Kafka Needs No Keeper: Removing the Apache ZooKeeper Dependency
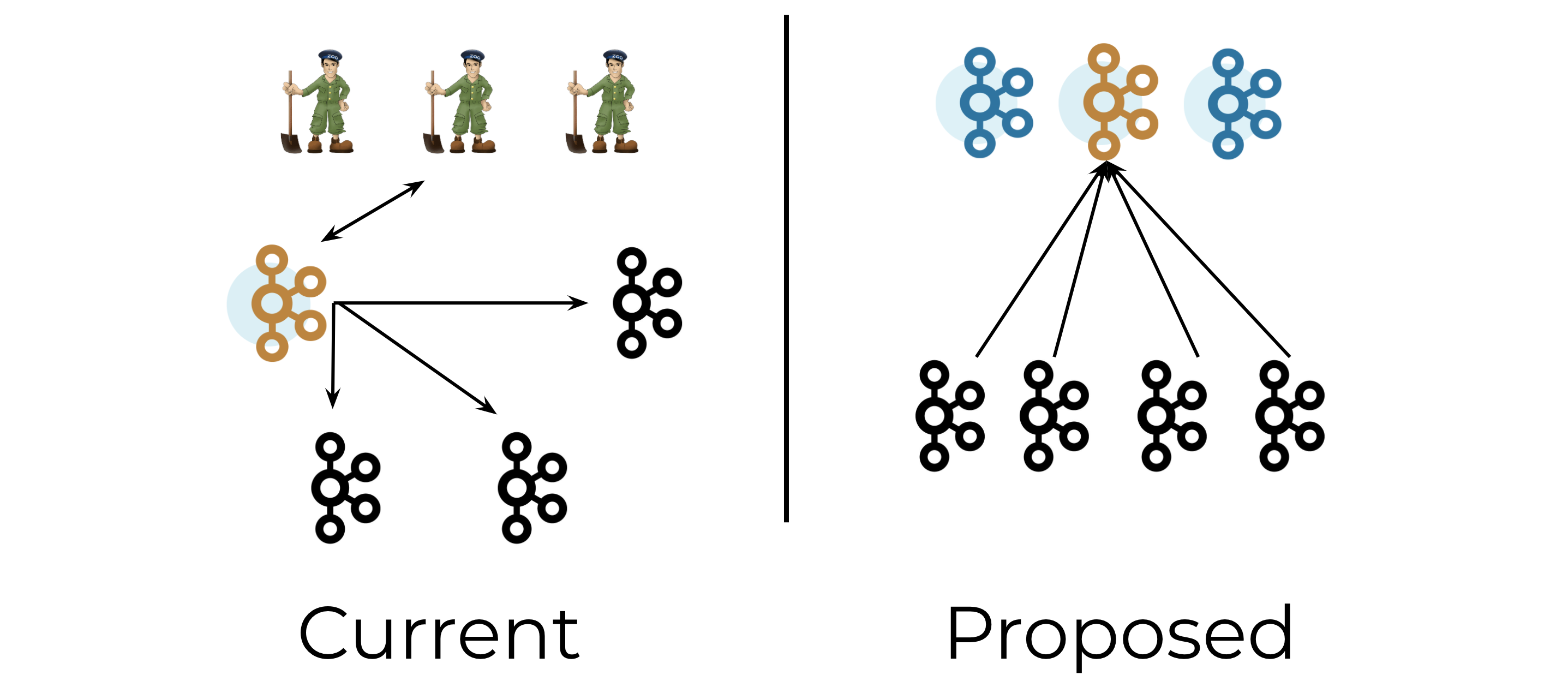
Currently, Apache Kafka® uses Apache ZooKeeper™ to store its metadata. Data such as the location of partitions and the configuration of topics are stored outside of Kafka itself, in a separate ZooKeeper cluster. In 2019, we outlined a plan to break this dependency and bring metadata management into Kafka itself.
So what is the problem with ZooKeeper? Actually, the problem is not with ZooKeeper itself but with the concept of external metadata management.
Having two systems leads to a lot of duplication. Kafka, after all, is a replicated distributed log with a pub/sub API on top. ZooKeeper is a replicated distributed log with a filesystem API on top. Each has its own way of doing network communication, security, monitoring, and configuration. Having two systems roughly doubles the total complexity of the result for the operator. This leads to an unnecessarily steep learning curve and increases the risk of some misconfiguration causing a security breach.
Storing metadata externally is not very efficient. We run at least three additional Java processes, and sometimes more. In fact, we often see Kafka clusters with just as many ZooKeeper nodes as Kafka nodes! Additionally, the data in ZooKeeper also needs to be reflected on the Kafka controller, which leads to double caching.
Worse still, storing metadata externally limits Kafka’s scalability. When a Kafka cluster is starting up, or a new controller is being elected, the controller must load the full state of the cluster from ZooKeeper. As the amount of metadata grows, so does the length of this loading process. This limits the number of partitions that Kafka can store.
Finally, storing metadata externally opens up the possibility of the controller’s in-memory state becoming de-synchronized from the external state. The controller’s view of liveness—which is in the cluster—can also diverge from ZooKeeper’s view.
KIP-500
Handling metadata
KIP-500 outlines a better way of handling metadata in Kafka. You can think of this as “Kafka on Kafka,” since it involves storing Kafka’s metadata in Kafka itself rather than in an external system such as ZooKeeper.
In the post-KIP-500 world, metadata will be stored in a partition inside Kafka rather than in ZooKeeper. The controller will be the leader of this partition. There will be no external metadata system to configure and manage, just Kafka itself.
We will treat metadata as a log. Brokers that need the latest updates can read only the tail of the log. This is similar to how consumers that need the latest log entries only need to read the very end of the log, not the entire log. Brokers will also be able to persist their metadata caches across process restarts.
Controller architecture
A Kafka cluster elects a controller node to manage partition leaders and cluster metadata. The more partitions and metadata we have, the more important controller scalability becomes. We would like to minimize the number of operations that require a time linearly proportional to the number of topics or partitions.
One such operation is controller failover. Currently, when Kafka elects a new controller, it needs to load the full cluster state before proceeding. As the amount of cluster metadata grows, this process takes longer and longer.
In contrast, in the post-KIP-500 world, there will be several standby controllers that are ready to take over whenever the active controller goes away. These standby controllers are simply the other nodes in the Raft quorum of the metadata partition. This design ensures that we never need to go through a lengthy loading process when a new controller is elected.
KIP-500 will speed up topic creation and deletion. Currently, when a topic is created or deleted, the controller must reload the full list of all topic names in the cluster from ZooKeeper. This is necessary because while ZooKeeper notifies us when the set of topics in the cluster has changed, it doesn’t tell us exactly which topics were added or removed. In contrast, creating or deleting a topic in the post-KIP-500 world will simply involve creating a new entry in the metadata partition, which is an O(1) operation.
Metadata scalability is a key part of scaling Kafka in the future. We expect that a single Kafka cluster will eventually be able to support a million partitions or more.
Roadmap
Removing ZooKeeper from Kafka’s administrative tools
Several administrative tools shipped as part of the Kafka release still allow direct communication with ZooKeeper. Worse still, there are still one or two operations that can’t be done except through this direct ZooKeeper communication.
We have been working hard to close these gaps. Soon, there will be a public Kafka API for every operation that previously required direct ZooKeeper access. We will also disable or remove the unnecessary --zookeeper flags in the next major release of Kafka.
Self-managed metadata quorums
In the post-KIP-500 world, the Kafka controller will store its metadata in a Kafka partition rather than in ZooKeeper. However, because the controller depends on this partition, the partition itself cannot depend on the controller for things like leader election. Instead, the nodes that manage this partition must implement a self-managed Raft quorum.
KIP-595: A Raft Protocol for the Metadata Quorum outlines how we will adapt the Raft protocol to Kafka so that it really feels like a native part of the system. This will involve changing the push-based model described in the Raft paper to a pull-based model, which is consistent with traditional Kafka replication. Rather than pushing out data to other nodes, the other nodes will connect to them. Similarly, we will use terminology consistent with Kafka rather than the original Raft paper—”epochs” instead of “terms,” and so forth.
The initial implementation will be focused on supporting the metadata partition. It will not support the full range of operations that would be needed to convert regular partitions over to Raft. However, this is a topic we may return to in the future.
KIP-500 mode
The most exciting part of this project, of course, is the ability to run without ZooKeeper, in “KIP-500 mode.” When Kafka is run in this mode, we will use a Raft quorum to store our metadata rather than ZooKeeper.
Initially, KIP-500 mode will be experimental. Most users will continue to use “legacy mode,” in which ZooKeeper is still in use. Partly, this is because KIP-500 mode will not support all possible features at first. Another reason is because we want to gain confidence in KIP-500 mode before making it the default. Finally, we will need time to perfect the upgrade process from legacy mode to KIP-500 mode.
Much of the work to enable KIP-500 mode will be in the controller. We must separate out the part of the controller that interacts with ZooKeeper from the part that implements more general-purpose logic such as replica set management.
We need to define and implement more controller APIs to replace the communication mechanisms that currently involve ZooKeeper. One example of this is the new AlterIsr API. This API allows a replica to notify the controller of a change in the in-sync replica set without using ZooKeeper.
Upgrades
KIP-500 introduced the concept of a bridge release that can coexist with both pre- and post-KIP-500 versions of Kafka. Bridge releases are important because they enable zero-downtime upgrades to the post-ZooKeeper world. Users on an older version of Kafka simply upgrade to a bridge release. Then, they can perform a second upgrade to a release that lacks ZooKeeper. As its name suggests, the bridge release acts as a bridge into the new world.
So how does this work? Consider a cluster that is in a partially upgraded state, with several brokers on the bridge release and several brokers on a post-KIP-500 release. The controller will always be a post-KIP-500 broker. In this cluster, brokers cannot rely on directly modifying ZooKeeper to announce changes they are making (such as a configuration change or an ACL change). The post-KIP-500 brokers would not receive such notifications because they are not listening on ZooKeeper. Only the controller is still interacting with ZooKeeper, by mirroring its changes to ZooKeeper.
Therefore, in the bridge release, all the brokers except the controller must treat ZooKeeper as read only (with some very limited exceptions).
For RPCs like IncrementalAlterConfigs, we simply need to ensure that the call is processed by the active controller. This is easy for new clients—they can simply send the calls there directly. For older clients, we need a redirection system that will run on the brokers that send the RPCs to the active controller, no matter which broker they initially end up on.
For RPCs that involve a complex interaction between the broker and the controller, we will need to create new controller APIs. One example is KIP-497, which specifies a new AlterIsrRequest API that allows brokers to request changes to partition in-sync replicas (ISRs).
Replacing ad hoc ZooKeeper APIs with well-documented and supported RPCs has many of the same benefits as removing client-side ZooKeeper access did. Maintaining cross-version compatibility will be easier. For the special case of AlterIsrRequest, there will also be benefits to reducing the number of writes to ZooKeeper that a common operation requires.
Conclusion
Kafka is one of the most active Apache projects. It has been amazing to see the evolution in its architecture over the last few years. That evolution is not done yet, as projects like KIP-500 show. What I like most about KIP-500 is that it’s a simplification to the overall architecture—for administrators and developers alike. It will let us use the powerful abstraction of the event log for metadata handling. And it will finally prove that…Kafka needs no keeper.
To learn about other work that is happening to make Kafka elastically scalable, check out the following:
Did you like this blog post? Share it now
Subscribe to the Confluent blog



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...